
本文由 網易雲 發佈。 作者:範欣欣 本篇文章僅限內部分享,如需轉載,請聯繫網易獲取授權。 眾所周知,HBase預設適用於寫多讀少的應用,正是依賴於它相當出色的寫入性能:一個100台RS的集群可以輕鬆地支撐每天10T 的寫入量。當然,為了支持更高吞吐量的寫入,HBase還在不斷地進行優化和修正,這篇 ...
本文由 網易雲 發佈。
作者:範欣欣
本篇文章僅限內部分享,如需轉載,請聯繫網易獲取授權。
眾所周知,HBase預設適用於寫多讀少的應用,正是依賴於它相當出色的寫入性能:一個100台RS的集群可以輕鬆地支撐每天10T 的寫入量。當然,為了支持更高吞吐量的寫入,HBase還在不斷地進行優化和修正,這篇文章結合0.98版本的源碼全面地分析HBase的寫入流程,全文分為三個部分,第一部分介紹客戶端的寫入流程,第二部分介紹伺服器端的寫入流程,最後再重點分析WAL的工作原理(註:從伺服器端的角度理解,HBase寫入分為兩個階段,第一階段數據會被寫入memstore,並且會執行WAL的寫入;第二階段會將memstore的中的數據集中flush到磁碟,本文主要集中分析第一階段的相關細節)。
客戶端流程解析
(1)用戶提交put請求後,HBase客戶端會將put請求添加到本地buffer中,符合一定條件就會通過AsyncProcess非同步批量提交。HBase預設設置autoflush=true,表示put請求直接會提交給伺服器進行處理;用戶可以設置autoflush=false,這樣的話put請求會首先放到本地buffer,等到本地buffer大小超過一定閾值(預設為2M,可以通過配置文件配置)之後才會提交。很顯然,後者採用group commit機制提交請求,可以極大地提升寫入性能,但是因為沒有保護機制,如果客戶端崩潰的話會導致提交的請求丟失。
(2)在提交之前,HBase會在元數據表.meta.中根據rowkey找到它們歸屬的region server,這個定位的過程是通過HConnection 的locateRegion方法獲得的。如果是批量請求的話還會把這些rowkey按照HRegionLocation分組,每個分組可以對應一次RPC請求。
( 3 )HBase 會為每個HRegionLocation 構造一個遠程RPC 請求MultiServerCallable<Row> , 然後通過rpcCallerFactory.<MultiResponse> newCaller()執行調用,忽略掉失敗重新提交和錯誤處理,客戶端的提交操作到此結束。伺服器端流程解析伺服器端RegionServer接收到客戶端的寫入請求後,首先會反序列化為Put對象,然後執行各種檢查操作,比如檢查region是否是只讀、memstore大小是否超過blockingMemstoreSize等。檢查完成之後,就會執行如下核心操作:
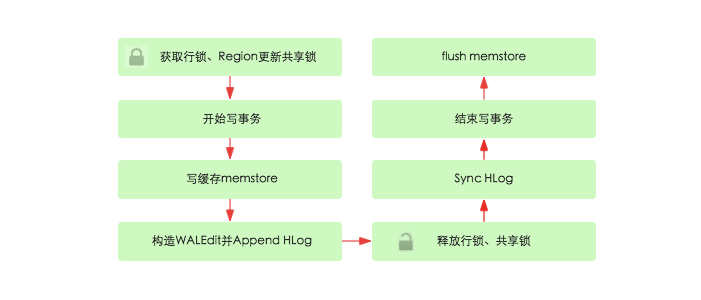
(1) 獲取行鎖、Region更新共用鎖: HBase中使用行鎖保證對同一行數據的更新都是互斥操作,用以保證更新的原子性,要麼更新成功,要麼失敗。
(2) 開始寫事務:獲取write number,用於實現MVCC,實現數據的非鎖定讀,在保證讀寫一致性的前提下提高讀取性能。
(3) 寫緩存memstore:HBase中每個列族都會對應一個store,用來存儲該列族數據。每個store都會有個寫緩存memstore,用於緩存寫入數據。HBase並不會直接將數據落盤,而是先寫入緩存,等緩存滿足一定大小之後再一起落盤。
(4) Append HLog:HBase使用WAL機制保證數據可靠性,即首先寫日誌再寫緩存,即使發生宕機,也可以通過恢復HLog還原出原始數據。該步驟就是將數據構造為WALEdit對象,然後順序寫入HLog中,此時不需要執行sync操作。0.98版本採用了新的寫線程模式實現HLog日誌的寫入,可以使得整個數據更新性能得到極大提升,具體原理見下一個章節。
(5)釋放行鎖以及共用鎖
(6)Sync HLog真正sync到HDFS,在釋放行鎖之後執行sync操作是為了儘量減少持鎖時間,提升寫性能。如果Sync失敗,執行回滾操作將memstore中已經寫入的數據移除。
(7) 結束寫事務:此時該線程的更新操作才會對其他讀請求可見,更新才實際生效。具體分析見上一篇文章《HBase - 併發控制深度解析》
(8) flush memstore:當寫緩存滿64M之後,會啟動flush線程將數據刷新到硬碟。刷新操作涉及到HFile相關結構,後面會詳細對此進行介紹。
WAL機制解析
WAL(Write-Ahead Logging)是一種高效的日誌演算法,幾乎是所有非記憶體資料庫提升寫性能的不二法門,基本原理是在數據寫入之前首先順序寫入日誌,然後再寫入緩存,等到緩存寫滿之後統一落盤。之所以能夠提升寫性能,是因為WAL將一次隨機寫轉化為了一次順序寫加一次記憶體寫。提升寫性能的同時,WAL可以保證數據的可靠性,即在任何情況下數據不丟失。假如一次寫入完成之後發生了宕機,即使所有緩存中的數據丟失,也可以通過恢復日誌還原出丟失的數據。
WAL持久化等級
HBase中可以通過設置WAL的持久化等級決定是否開啟WAL機制、以及HLog的落盤方式。WAL的持久化等級分為如下四個等級:
1. SKIP_WAL:只寫緩存,不寫HLog日誌。這種方式因為只寫記憶體,因此可以極大的提升寫入性能,但是數據有丟失的風險。在實際應用過程中並不建議設置此等級,除非確認不要求數據的可靠性。
2. ASYNC_WAL:非同步將數據寫入HLog日誌中。
3. SYNC_WAL:同步將數據寫入日誌文件中,需要註意的是數據只是被寫入文件系統中,並沒有真正落盤。
4. FSYNC_WAL:同步將數據寫入日誌文件並強制落盤。最嚴格的日誌寫入等級,可以保證數據不會丟失,但是性能相對比較差。
5. USER_DEFAULT:預設如果用戶沒有指定持久化等級,HBase使用SYNC_WAL等級持久化數據。
用戶可以通過客戶端設置WAL持久化等級,代碼:put.setDurability(Durability. SYNC_WAL );
HLog數據結構
HBase中,WAL的實現類為HLog,每個Region Server擁有一個HLog日誌,所有region的寫入都是寫到同一個HLog。下圖表示同一個Region Server中的3個 region 共用一個HLog。當數據寫入時,是將數據對<HLogKey,WALEdit>按照順序追加到HLog 中,以獲取最好的寫入性能。
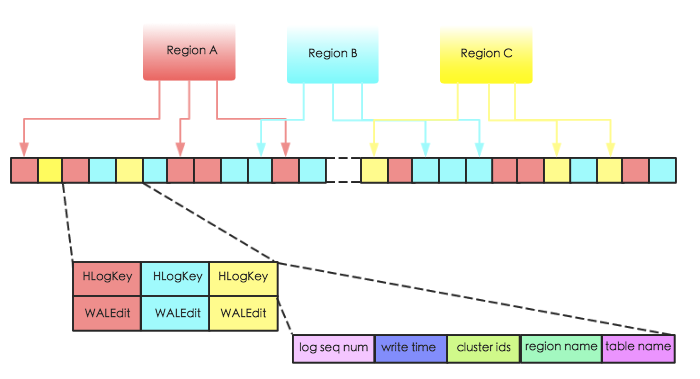
上圖中HLogKey主要存儲了log sequence number,更新時間 write time,region name,表名table name以及cluster ids。其中log sequncece number作為HFile中一個重要的元數據,和HLog的生命周期息息相關,後續章節會詳細介紹;region name和table name分別表徵該段日誌屬於哪個region以及哪張表;cluster ids用於將日誌複製到集群中其他機器上。
WALEdit用來表示一個事務中的更新集合,在之前的版本,如果一個事務中對一行row R中三列c1,c2,c3分別做了修改,那麼hlog中會有3個對應的日誌片段如下所示:
<logseq3-for-edit3>:<keyvalue-for-edit-c3>
然而,這種日誌結構無法保證行級事務的原子性,假如剛好更新到c2之後發生宕機,那麼就會產生只有部分日誌寫入成功的現象。為此,hbase將所有對同一行的更新操作都表示為一個記錄,如下:
<logseq#-for-entire-txn>:<WALEdit-for-entire-txn>
其中WALEdit會被序列化為格式<-1, # of edits, <KeyValue>, <KeyValue>, <KeyValue>>,比如<-1, 3, <keyvalue-for-edit- c1>, <keyvalue-for-edit-c2>, <keyvalue-for-edit-c3>>,其中-1作為標示符表徵這種新的日誌結構。
WAL寫入模型
瞭解了HLog 的結構之後, 我們就開始研究HLog 的寫入模型。 HLog 的寫入可以分為三個階段, 首先將數據對<HLogKey,WALEdit>寫入本地緩存,然後再將本地緩存寫入文件系統,最後執行sync操作同步到磁碟。在以前老的寫入模型中, 上述三步都由工作線程獨自完成,如下圖所示:
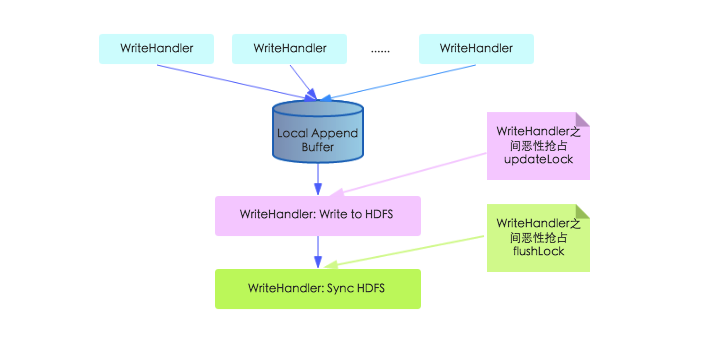
上圖中,本地緩存寫入文件系統那個步驟工作線程需要持有updateLock執行,不同工作線程之間必然會惡性競爭;不僅如此,在Sync HDFS這步中,工作線程之間需要搶占flushLock,因為Sync操作是一個耗時操作,搶占這個鎖會導致寫入性能大幅降低。
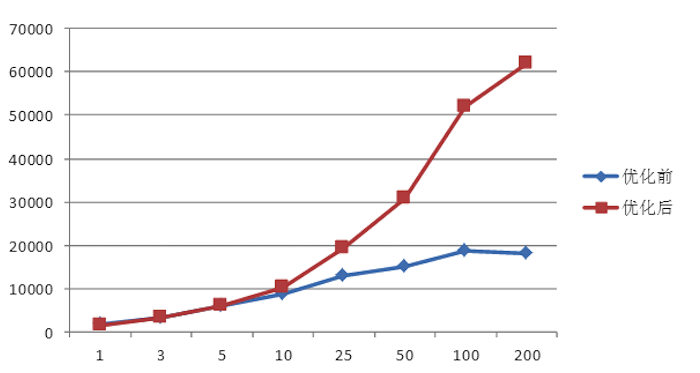
所幸的是,來自中國(準確的來說,是來自小米,鼓掌)的3位工程師意識到了這個問題,進而提出了一種新的寫入模型並被官方 採納。根據官方測試,新寫入模型的吞吐量比之前提升3倍多,單台RS寫入吞吐量介於12150~31520,5台RS組成的集群寫入吞吐量介於22000~70000(見HBASE-8755)。下圖是小米官方給出來的對比測試結果:
在新寫入模型中,本地緩存寫入文件系統以及Sync HDFS都交給了新的獨立線程完成,並引入一個Notify線程通知工作線程是否已經Sync成功,採用這種機制消除上述鎖競爭,具體如下圖所示:
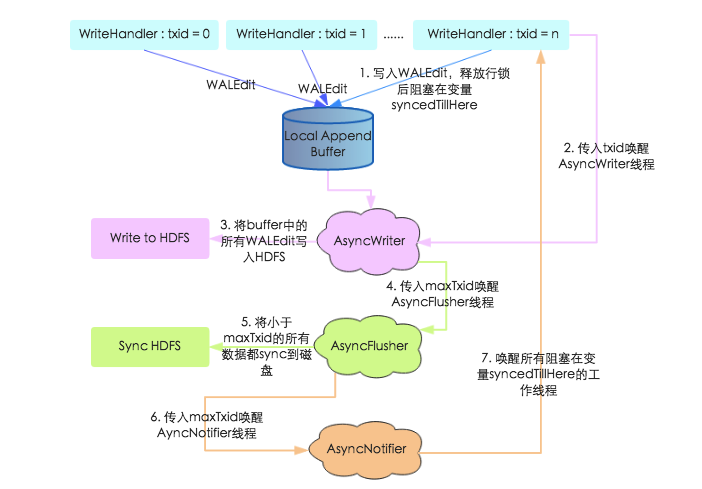
1. 上文中提到工作線程在寫入WALEdit 之後並沒有進行Sync , 而是等到釋放行鎖阻塞在syncedTillHere 變數上, 等待AsyncNotifier線程喚醒。
2. 工作線程將WALEdit寫入本地Buffer之後,會生成一個自增變數txid,攜帶此txid喚醒AsyncWriter線程
3. AsyncWriter 線程會取出本地Buffer 中的所有WALEdit , 寫入HDFS 。註意該線程會比較傳入的txid 和已經寫入的最大txid(writtenTxid),如果傳入的txid小於writteTxid,表示該txid對應的WALEdit已經寫入,直接跳過
4. AsyncWriter線程將所有WALEdit寫入HDFS之後攜帶maxTxid喚醒AsyncFlusher線程
5. AsyncFlusher線程將所有寫入文件系統的WALEdit統一Sync刷新到磁碟
6. 數據全部落盤之後調用setFlushedTxid方法喚醒AyncNotifier線程
7. AyncNotifier線程會喚醒所有阻塞在變數syncedTillHere的工作線程,工作線程被喚醒之後表示WAL寫入完成,後面再執行MVCC結束寫事務,推進全局讀取點,本次更新才會對用戶可見
通過上述過程的梳理可以知道,新寫入模型採取了多線程模式獨立完成寫文件系統、sync磁碟操作,避免了之前多工作線程惡性搶占鎖的問題。同時,工作線程在將WALEdit寫入本地Buffer之後並沒有馬上阻塞,而是釋放行鎖之後阻塞等待WALEdit落盤,這樣可以儘可能地避免行鎖競爭,提高寫入性能。
總結
文章剛開始就提到HBase寫入分為兩個階段,本文主要集中分析第一階段的相關細節,首先介紹了HBase的寫入memstore的流程,之後重點分析了WAL的寫入模型以及相關優化。後面一篇文章會接著介紹寫入到memstore的數據落盤的相關知識點,敬請期待!
網易有數:企業級大數據可視化分析平臺。面向業務人員的自助式敏捷分析平臺,採用PPT模式的報告製作,更加易學易用,具備強大的探索分析功能,真正幫助用戶洞察數據發現價值。可點擊這裡免費試用。
瞭解 網易雲 :
網易雲官網:https://www.163yun.com/
新用戶大禮包:https://www.163yun.com/gift
網易雲社區:https://sq.163yun.com/


