
K近鄰演算法(KNN)是指一個樣本如果在特征空間中的K個最相鄰的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別,並具有這個類別上樣本的特性。即每個樣本都可以用它最接近的k個鄰居來代表。KNN演算法適合分類,也適合回歸。KNN演算法廣泛應用在推薦系統、語義搜索、異常檢測。 KNN演算法分類原理圖: 圖中 ...
K近鄰演算法(KNN)是指一個樣本如果在特征空間中的K個最相鄰的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別,並具有這個類別上樣本的特性。即每個樣本都可以用它最接近的k個鄰居來代表。KNN演算法適合分類,也適合回歸。KNN演算法廣泛應用在推薦系統、語義搜索、異常檢測。
KNN演算法分類原理圖:
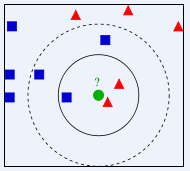
圖中綠色的圓點是歸屬在紅色三角還是藍色方塊一類?如果K=5(離綠色圓點最近的5個鄰居,虛線圈內),則有3個藍色方塊是綠色圓點的“最近鄰居”,比例為3/5,因此綠色圓點應當劃歸到藍色方塊一類;如果K=3(離綠色圓點最近的3個鄰居,實線圈內),則有兩個紅色三角是綠色圓點的“最近鄰居”,比例為2/3,那麼綠色圓點應當劃歸到紅色三角一類。
由上看出,該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
KNN演算法實現步驟:
1. 數據預處理
2. 構建訓練集與測試集數據
3. 設定參數,如K值(K一般選取樣本數據量的平方根即可,3~10)
4. 維護一個大小為K的的按距離(歐氏距離)由大到小的優先順序隊列,用於存儲最近鄰訓練元組。隨機從訓練元組中選取K個元組作為初始的最近鄰元組,分別計算測試元組到這K個元組的距離將訓練元組標號和距離存入優先順序隊列
5. 遍歷訓練元組集,計算當前訓練元組與測試元組的距離L,將所得距離L與優先順序隊列中的最大距離Lmax
6. 進行比較。若L>=Lmax,則捨棄該元組,遍歷下一個元組。若L < Lmax,刪除優先順序隊列中最大距離的元組,將當前訓練元組存入優先順序隊列
7. 遍歷完畢,計算優先順序隊列中K個元組的多數類,並將其作為測試元組的類別
8. 測試元組集測試完畢後計算誤差率,繼續設定不同的K值重新進行訓練,最後取誤差率最小的K值。
R語言實現過程:
R語言中進行K近鄰演算法分析的函數包有class包中的knn函數、caret包中的train函數和kknn包中的kknn函數
knn(train, test, cl, k = 1, l = 0, prob = FALSE, use.all = TRUE)
參數含義:
train:含有訓練集的矩陣或數據框
test:含有測試集的矩陣或數據框
cl:對訓練集進行分類的因數變數
k:鄰居個數
l:有限決策的最小投票數
prob:是否計算預測組別的概率
use.all:控制節點的處理辦法,即如果有多個第K近的點與待判樣本點的距離相等,預設情況下將這些點都作為判別樣本點;當該參數設置為FALSE時,則隨機選擇一個點作為第K近的判別點。
(樣本數據說明:文中樣本數據描述一女士根據約會對象每年獲得飛行里程數;玩視頻游戲所消耗的時間百分比;每周消費的冰淇淋公升數,將自己約會對象劃分為三種喜好類型)
代碼:
#導入分析數據
mydata <- read.table("C:/Users/Cindy/Desktop/婚戀/datingTestSet.txt")
str(mydata)
colnames(mydata) <- c('飛行里程','視頻游戲時間占比','食用冰淇淋數','喜好分類')
head(mydata)
#數據預處理,歸一化
norfun <- function(x){
z <- (x-min(x))/(max(x)-min(x))
return(z)
}
data <- as.data.frame(apply(mydata[,1:3],2,norfun))
data$喜好分類<-mydata[,4]
#建立測試集與訓練集樣本
library(caret)
set.seed(123)
ind <- createDataPartition(y=data$喜好分類,times = 1,p=0.5,list = F)
testdata <- data[-ind,]
traindata <- data[ind,]
#KNN演算法
library(class)
kresult <- knn(train = traindata[,1:3],test=testdata[,1:3],cl=traindata$喜好分類,k=3)
#生成實際與預判交叉表和預判準確率
table(testdata$喜好分類,kresult)
sum(diag(table(testdata$喜好分類,kresult)))/sum(table(testdata$喜好分類,kresult))
運行結果:

根據結果可知該分類的正確率為95%。
KNN演算法優缺點:
優點:
1.易於理解和實現
2. 適合對稀有事件進行分類
3.特別適合於多分類問題(multi-modal,對象具有多個類別標簽), kNN比SVM的表現要好
缺點:
計算量較大,需要計算新的數據點與樣本集中每個數據的“距離”,以判斷是否是前K個鄰居)
改進:
分類效率上,刪除對分類結果影響較小的屬性;分類效果上,採用加權K近鄰演算法,根據距離的遠近賦予樣本點不同的權重值,kknn包中的kknn函數即採用加權KNN演算法。
2018-04-30 22:31:25


