
本文目錄: 1.1 視窗和開窗函數簡介 1.2 OVER()語法和執行位置 1.3 row_number()對分區排名 1.4 rank()和dense_rank() 1.5 percent_rank()和cume_dist() 1.6 ntile()數據分組 1.7 取相鄰行數據:lag()函數和 ...
本文目錄:
1.1 視窗和開窗函數簡介
1.2 OVER()語法和執行位置
1.3 row_number()對分區排名
1.4 rank()和dense_rank()
1.5 percent_rank()和cume_dist()
1.6 ntile()數據分組
1.7 取相鄰行數據:lag()函數和lead()函數
1.8 視窗聚合函數
1.9 開窗函數的性能
在使用GROUP BY子句時,總是需要將篩選的所有數據進行分組操作,它的分組作用域是整張表。分組以後,為每個組只返回一行。而使用基於視窗的操作,類似於分組,但卻可以對這些"組"(即視窗)中的每一行進行計算,所以可以為每"組"返回多行。
視窗函數也稱為分區函數,在Oracle中稱為分析函數,因為開窗函數是對分區中的數據進行個各種分析、計算。
MySQL不支持視窗函數。MariaDB 10.2之後才開始支持window function。
本文將簡單介紹開窗函數的使用方法,並給出一些經典示例,同時還會給出使用子查詢實現開窗函數的功能。由此來說明開窗函數相比子查詢的簡潔、高效率。
MariaDB開窗函數官方手冊:https://mariadb.com/kb/en/library/window-functions/
我翻譯的window functions overview:https://mariadb.com/kb/zh-cn/window-functions-overview/
1.1 視窗和開窗函數簡介
在如圖所示的成績表中,包含了6名學生的3科成績,共18行記錄。按照學號sid進行劃分,每名學生都可以被看成是一個視窗(或稱為分區),18行成績共有6個視窗。可以基於每個視窗中的數據進行排序和聚合操作,如在 sid=1 的視窗進行一次升序排序,編號從1開始。當到其他視窗時,編號又重新從1開始。當然也可以按課程定義視窗,有3門課程,因此可以分為3個視窗。

視窗函數的特征是使用OVER()關鍵字。"開窗函數"這一名詞描述了視窗變化後重新打開其它視窗進行計算的動作。視窗計算主要是對每組數據進行排序或聚合計算,因此開窗函數可以分為排名開窗函數和聚合開窗函數。
之所以提出視窗的概念,是因為這種基於視窗或分區的重新計算能簡化很多問題。在不支持該技術時,很多情況下處理基於視窗重新計算的問題時,語句的編寫相對複雜許多。視窗的提出,提供了一種簡單而又高效的問題解決方式。在本文中也會演示不使用這些基於視窗計算的替代語句,熟悉這些替代語句後,才能更好的體會這種技術的簡單和高效。
1.2 OVER()語法和執行位置
在邏輯執行順序上,OVER()子句的執行位置在WHERE、GROUP BY和HAVING子句之後,在ORDER BY子句之前。如下:
SELECT (11)<DISTINCT> (5)select_list (9)<OVER()> ( 1)FROM ( 3) JOIN ( 2) ON ( 4)WHERE ( 6)GROUP BY ( 7)WITH ROLLUP ( 8)HAVING (10)ORDER BY (12)LIMIT
因此,where子句無法篩選來自開窗計算得到的結果集。
OVER()子句的使用語法如下:
function (expression) OVER ( [ PARTITION BY expression_list ] [ ORDER BY order_list ] ) function: A valid window function expression_list: expression | column_name [, expr_list ] order_list: expression | column_name [ ASC | DESC ] [, ... ]
MariaDB支持以下window function:
- 排名函數:ROW_NUMBER(),RANK(),DENSE_RANK(),PERCENT_RANK(),CUME_DIST(),NTILE()
- 聚合函數:COUNT(),SUM(),AVG(),BIT_OR(),BIT_AND(),BIT_XOR()
- 不支持帶有DISTINCT的聚合函數,例如COUNT(DISTINCT X)
- 其他一些視窗分析函數,例如lag(),lead()。具體見官方手冊。
PARTITION BY子句用於劃分視窗(分區),也就是另類的GROUP BY。如果不指定PARTITION BY子句,則預設整張表是一個分區,即對所有行進行視窗函數的計算。這裡的所有行不是FROM後面表的所有行,而是經過WHERE、GROUP BY、和HAVING運行之後的所有行。
ORDER BY子句用於對分區內的行進行排序。在MariaDB中可以省略該子句,表示不對分區內數據做任何排序。
在SQL Server中ORDER BY不可省略,SQL Server認為無順序的區內數據由於不知道順序而無法使用開窗函數。實際上,SQL Server通過特殊的ORDER BY子句,也能實現不對分區做任何排序,例如 over(order by (select 1)) ,其中1可以替換為任意其他常量。
無論如何,over()中不使用order by子句的結果中,順序是不可預測的,因此在涉及任何排名的時候,都建議使用order by進行排序,除非你知道自己在做什麼。
之所以不支持帶有DISTINCT的聚合函數,是因為DISTINCT的執行過程在OVER()之後。開窗之後再DISTINCT沒有意義,且消耗額外的資源。如果想先去重再OVER(),可以使用GROUP BY替代DISTINCT的功能。
1.3 row_number()對分區排名
row_number()函數用於給每個視窗內的行排名,且排名連續不斷開的。例如,2個學生90分,一個學生89分,那麼兩個90分的學生將給定排名1和2,89分的學生給定排名3。至於誰是1誰是2,由物理存儲順序決定,也就是說當排名依據大小重覆時,row_number()的排名將是不可預測的。
給定tscore表和相關數據:每個sid有3門課程以及對應的成績,共6個sid
create or replace table tscore(sid int,subject char(10),score int); insert into tscore values (1,'Java',74),(1,'Linux',67),(1,'SQL',57), (2,'Java',67),(2,'Linux',63),(2,'SQL',68), (3,'Java',90),(3,'Linux',79),(3,'SQL',82), (4,'Java',50),(4,'Linux',68),(4,'SQL',59), (5,'Java',98),(5,'Linux',65),(5,'SQL',67), (6,'Java',66),(6,'Linux',96),(6,'SQL',95); select * from tscore; +------+---------+-------+ | sid | subject | score | +------+---------+-------+ | 1 | Java | 74 | | 1 | Linux | 67 | | 1 | SQL | 57 | | 2 | Java | 67 | | 2 | Linux | 63 | | 2 | SQL | 68 | | 3 | Java | 90 | | 3 | Linux | 79 | | 3 | SQL | 82 | | 4 | Java | 50 | | 4 | Linux | 68 | | 4 | SQL | 59 | | 5 | Java | 98 | | 5 | Linux | 65 | | 5 | SQL | 67 | | 6 | Java | 66 | | 6 | Linux | 96 | | 6 | SQL | 95 | +------+---------+-------+
按照sid分區,計算出每個sid 3科成績的分數排名。例如sid=1的學生,Java課程分數最高,Linux課程次之,SQL分數最低,所以給定排名Java:1、Linux:2、SQL:3。sid=2的學生分數從高到低依次是SQL、Java、Linux,給定排名SQL:1、Java:2、Linux:3。依次類推。
由於是按照sid分區,所以over()子句中使用 partition by sid ,由於每個分區內部按照score降序排序,因此over()子句中使用 order by score desc 。所以,完整的SQL語句如下:
select row_number() over(partition by sid order by score desc) as rnum, sid, subject, score from tscore;
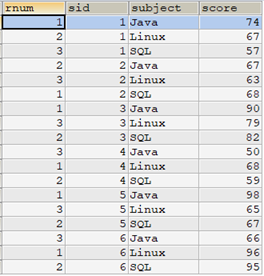
從查詢結果中,可以看到每個sid都按照score的高低為相關課程給定了排名號。但是,最後返回的結果卻不那麼易讀,每個sid對應的rnum的順序是亂的。因此,如果為了易讀性,可以考慮在select語句中使用order by子句,對sid和rnum進行排序。如下:
select row_number() over(partition by sid order by score desc) as rnum, tscore.* from tscore order by sid,rnum;
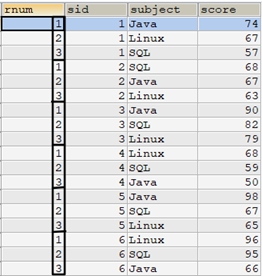
如何使用子查詢的方式實現以上row_number()的排名效果?參考如下語句:
select /* 使用row_number() */ row_number() over(partition by t1.sid order by t1.score desc) as rnum1, /* 使用子查詢 */ (select count(*)+1 from tscore t2 where t2.sid=t1.sid and t2.score>t1.score) as rnum2, t1.* from tscore t1 order by sid,rnum1;
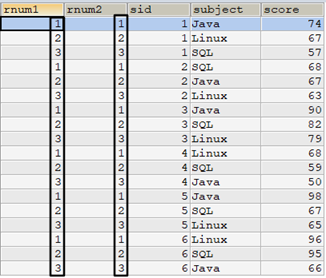
如果視窗中排序依據score的值有重覆呢?row_number()如何為它們排名?如何使用子查詢實現row_number()相同的效果?
/* 給定score重覆的值 */ create table tscore_tmp like tscore; insert into tscore_tmp select * from tscore; update tscore_tmp set score=67 where sid=1 and subject='Java';
此時sid=1的學生Java和Linux兩課程的分數都是67。
select /* 使用row_number() */ row_number() over(partition by t1.sid order by t1.score desc) as rnum1, /* 使用子查詢 */ (select count(*)+1 from tscore_tmp t2 where t2.sid=t1.sid and t2.score>t1.score) as rnum2, t1.* from tscore_tmp t1 order by sid,rnum1;
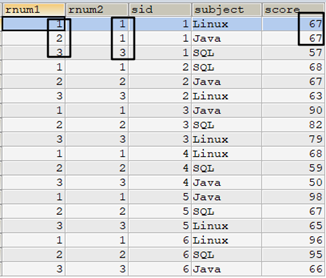
從結果中可看出row_number()對重覆值會繼續向後排名。但上面的子查詢卻並非如此,其實讀一讀子查詢語句就能明白為何如此。
那麼如何使用子查詢實現row_number()相同的結果呢?也簡單,只需添加一個決勝條件即可。
select /* 使用row_number() */ row_number() over(partition by t1.sid order by t1.score desc) as rnum1, /* 使用子查詢 */ (select count(*)+1 from tscore_tmp t2 where t2.sid=t1.sid and (t2.score>t1.score or (t2.score=t1.score and t2.subject>t1.subject))) as rnum2, t1.* from tscore_tmp t1 order by sid,rnum1;
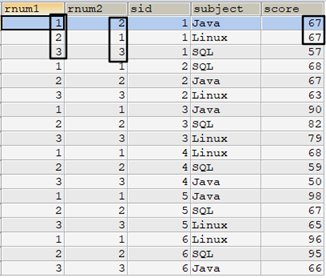
儘管rnum1和rnum2的排名結果不一樣,但這無所謂,只要能為重覆值排名實現row_number()函數的效果即可。
1.4 rank()和dense_rank()
前面介紹了ROW_NUMBER(),ROW_NUMBER()的作用更像是用於編號而不是排名。例如,前面將sid=1的學生的Java課程的score改為67後,由於Java和Linux兩門課程分數都是67,使用ROW_NUMBER()時得到的結果就有兩種方案可供選擇:一種是Java排第一位,Linux排第二位,另一種是Java第二位而Linux第一位。這兩種方案都是可能的,但是正因為如此,它具有不確定性。
相比於編號,排名則具有確定性,相同的值總是被分配相同的排名值。Java和Linux都是67分,它們應當都排在第一位,也就是併列第一位。但是它們接下來的SQL課程的排名值呢?是2還是3?SQL課程前面已經有兩門課程排在前面,那麼SQL應該排在第3位,但是從Java和Linux併列排第一位的角度來看,它們之後的SQL應當是第二位。
MariaDB中使用RANK()和DENSE_RANK()來對應這兩種排名方式,RANK()的排名方式是SQL課程的排序值是第3位,DENSE_RANK()則是第2位。DENSE_RANK()的排名方式稱之為密集排名,因為它的名次之間沒有間隔。
例如,下麵的語句中使用ROW_NUMBER()、RANK()和DENSE_RANK()三種排名函數作比較。可以看到ROW_NUMBER()、RANK()和DENSE_RANK()三者的區別。
select t.*, /* 使用ROW_NUMBER()的方式排名 */ row_number() over(partition by sid order by score desc) as rnum, /* 使用RANK()的方式排名 */ rank() over(partition by sid order by score desc) as rank, /* 使用DENSE_RANK()的方式排名 */ dense_rank() over(partition by sid order by score desc) as dense_rank from tscore_tmp t order by t.sid,rnum;
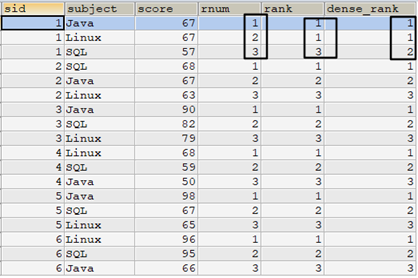
如果使用子查詢實現rank()和dense_rank()的排名效果,參考如下語句:
也可以使用子查詢的方式實現排名計算。參考下麵的語句。ROW_NUMBER()的子查詢實現方式前文已經介紹過。相比ROW_NUMBER(),RANK()的實現只需要比較內外兩表t1和t2的score大小即可,而DENSE_RANK()則需要去除重覆的score值,使用 COUNT(DISTINCT score) 實現。
select t1.*, /* 使用ROW_NUMBER()的方式排名 */ (select count(*) + 1 from tscore_tmp AS t2 where t2.sid = t1.sid and (t2.score > t1.score or (t2.score = t1.score and t2.subject > t1.subject))) as rnum, /* 使用RANK()方式排名 */ (select count(*) + 1 from tscore_tmp t2 where t2.sid = t1.sid and t2.score > t1.score) as rank, /* 使用DENSE_RANK()方式排名 */ (select count(distinct score) + 1 from tscore_tmp t2 where t2.sid = t1.sid and t2.score > t1.score) as dense_rank from tscore_tmp t1 order by sid,rnum;
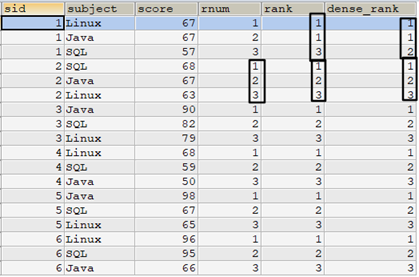
1.5 percent_rank()和cume_dist()
percent_rank()函數用於計算分組中某行的相對排名。
cume_dist()函數用於計算分組中某排名的相對比重。
percent_rank()的計算方式:(視窗中rank排名-1)/(視窗行數-1) cume_dist()的計算方式:(視窗中小於或等於當前行的行數)/視窗行數,即(<=當前rank值的行數)/視窗行數
通過這樣的相對位置計算,我們可以獲取分區中最前、中間和最後的排名。
仍然使用上面的tscore_tmp表的數據做測試。
select t1.*, row_number() over(partition by sid order by score desc) as rnum, rank() over(partition by sid order by score desc) as rank, percent_rank() over(partition by sid order by score desc) as pct_rank, cume_dist() over(partition by sid order by score desc) as cume_dist from tscore_tmp t1 order by sid,rnum;
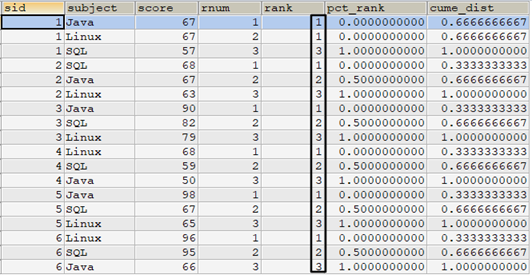
其中:
- pct_rank列是根據每個視窗中,rank列的值計算的。例如sid=1,score=67的兩行記錄,它們的rank值都是1,視窗中的行數位3,所以計算方式為(1-1)/(3-1)=0。
- cume_dist列計算的是每個視窗中某個rank值所占排名比重。例如sid=1,score=67的兩行記錄,這兩行的rank值都為1,視窗中3行,所以計算方式為2/3=0.67。
如果不進行分區。
select t1.*, row_number() over(order by score desc) as rnum, rank() over(order by score desc) as rank, percent_rank() over(order by score desc) as pct_rank, cume_dist() over(order by score desc) as cume_dist from tscore_tmp t1 order by rnum;
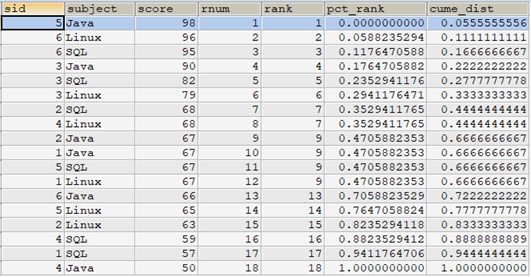
以rnum=10那一行記錄為例。該行rank=9,所以:
- pct_rank=(9-1)/(18-1)=8/17=0.47
- cume_dist=12/18=0.67
即使我們所取的行為rnum=10,但rnum=11和rnum=12的rank值也都為9,所以cume_dist的分子為12。即分區中(所有行)小於或等於rank=9的行共有12行。
因此,percent_rank()函數計算的是分區中某個rank排名的相對位置,cume_dist()函數計算的是分區中某個rank排名在分區中的比重。
1.6 ntile()數據分組
NTILE()的功能是進行"均分"分組,括弧內接受一個代表要分組組數量的參數,然後以組為單位進行編號,對於組內每一行數據,NTILE都返回此行所在組的組編號。簡單的說就是NTILE函數將每一行數據關聯到組,併為每一行分配一個所屬組的編號。
假設一個表的某列值為1到10的整數,要將這10行分成兩組,則每個組都有5行,表示方式為NTILE(2)。如果表某列是1到11的整數,這11行要分成3組的表示方式為NTILE(3),但是這時候無法"均分",它的分配方式是先分成3組,每組3行數據,剩下的兩行數據從前向後均分,即第一組和第二組都有4行數據,第三組只有3行數據。
可以使用上述方法計算每組中記錄的數量,但是要註意分組的時候是按指定順序分組的。例如1到11的整數分3組時,三個組的值分別是(1、2、3、4)、(5、6、7、8)和(9、10、11),而不是真的將均分後剩下的兩個值10、11插會前兩組,即(1、2、3、10)、(4、5、6、11)、(7、8、9)是錯誤的分組。
下麵的語句指定將tscore表按score的升序排列分成4組,mark值從最低到最高共18個值,NTILE(4)的結果是前2組有5行數據,後2組只有4行數據。
SELECT tscore.*, row_number() over (ORDER BY score) AS rnum, ntile(4) over (ORDER BY score) AS ntile FROM tscore ORDER BY rnum;
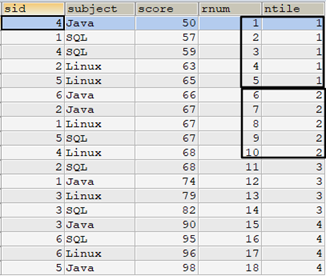
在進行NTILE()函數分組時,邏輯上會依賴ROW_NUMBER()函數。例如上面的示例,邏輯上先進行ROW_NUMBER()編號,要查詢的共有18行,請求分成4組,那麼編號1到5的行分配到第一組,6到10分配到第二組,依此類推,直到最後的4行被分配結束。
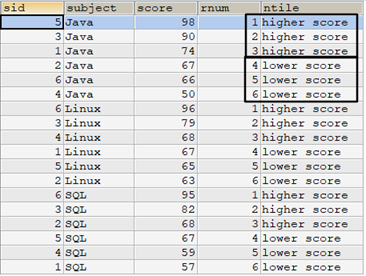
上面的示例是對整張表進行NTILE()操作,也可以先分區,再在每個分區中進行NTILE()。例如,對tscore表,按subject分成3個區,然後按每門課程分成高低兩組。可以看出,每個區有6個學生的成績,分成2組,每組3行數據。
select t.*, row_number() over(partition by subject order by score desc) as rnum, case ntile(2) over(partition by subject order by score desc) when 1 then 'higher score' when 2 then 'lower score' end as ntile from tscore t order by subject,rnum;
1.7 取相鄰行數據:lag()函數和lead()函數
lag()和lead()函數可以在同一次查詢中取出同一欄位的前N行的數據(lag)和後N行的數據(lead)作為獨立的列。
這種操作可以代替表的自聯接,並且lag()和lead()有更高的效率。
語法:
LAG (expr[, offset]) OVER ( [ PARTITION BY partition_expression ] < ORDER BY order_list > ) LEAD (expr[, offset]) OVER ( [ PARTITION BY partition_expression ] [ ORDER BY order_list ] )
其中offset是偏移量,表示取出當前行向前或向後偏移N行後的行,預設值為1。
例如某個分區中order by排序後,當前行是第3行,lag(id,2)表示取出當前分區中的第1行(3-2),所取內容為id欄位。
如以下示例:對subject分區,分區中按照score降序排序
select t.subject,t.score, row_number() over(partition by subject order by score desc) as rnum, lag(sid,1) over(partition by subject order by score desc) as lag, t.sid, lead(sid,1) over(partition by subject order by score desc) as lead from tscore t order by subject,rnum;
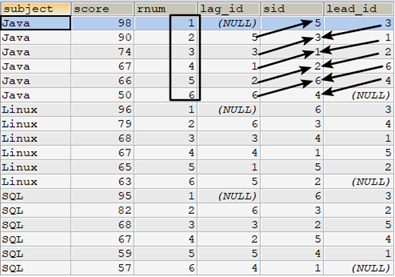
以subject='Java'分區為例:
- 對於rnum=1的行,它表示score最高,lag(sid,1)表示取該行前一行的sid欄位,由於沒有前一行,所以lag_id的值為NULL,lead(sid,1)表示取該行後一行的sid欄位,該行後一行為rnum=2的行,對應sid=3,所以lead_id的值為3。
- 對於rnum=2的行,按照score排序,它的前一行為rnum=1的行,對應sid=5,所以lag_id的值為5。它的後一行為rnum=3的行,對應sid=1,所以lead_id的值為1。
依次類推。
1.8 視窗聚合函數
聚合函數的要點就是對一組值進行聚合,聚合函數傳統上一直以GROUP BY查詢作為操作的上下文。對數據進行分組以後,查詢為每個組只返回一行。而使用視窗聚合函數,以視窗作為操作對象,不再使用GROUP BY分組後的組作為操作對象。
由於開窗函數運行在邏輯上比較後執行的SELECT階段,不像GROUP BY的邏輯執行階段比較靠前,因此很多操作比GROUP BY方便的多。比如可以在SELECT選擇列表中隨意選擇返回列,這樣就能夠同時返回某一行的數據列和聚合列,也就是說可以為非分組數據進行聚合計算。甚至如果沒有分組後的HAVING篩選子句時,可以使用聚合視窗函數替代GROUP BY分組,所做的僅僅是將GROUP BY替換為PARTITION BY分組。
在進行視窗聚合計算時,OVER()子句中不再要求ORDER BY子句,因此,使用方法簡化為如下:
OVER([PARTITION BY expression])
OVER()括弧內的內容省略時表示對所有篩選後的行數據進行聚合。
下麵的語句進行了不分區(整張表作為輸入數據)和分區的平均分計算。
select t.*, avg(score) over() as sum_avg, avg(score) over(partition by sid) as sid_avg from tscore t;
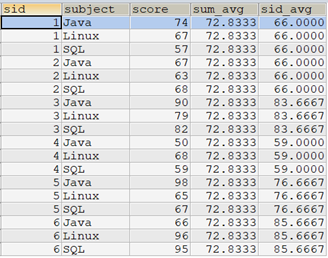
如果需要使用子查詢的方式達到和示例一樣的結果,則需要使用聯接的方式。
要計算sum_avg這一列,參考下麵的語句:
select t1.*,t2.sum_avg from tscore t1 cross join (select avg(score) as sum_avg from tscore) as t2;
由於"sum_avg"是全部學生所有課程分數的聚合計算,它不需要先分組,因此可以將 AVG(score) OVER() 理解成子查詢 SELECT AVG(score) FROM tscore ,但是它們在性能上是有差距的。
要計算"sid_avg"這一列,參考下麵的語句:
select t1.*,t3.sid_avg from tscore t1 left join (select sid,avg(score) as sid_avg from tscore group by sid) as t3 on t3.sid=t1.sid;
將上述兩個子查詢聯接,就得到與使用OVER()子句相同的返回結果。參考下麵的語句。
select t1.*,t2.sum_avg,t3.sid_avg from tscore t1 cross join (select avg(score) as sum_avg from tscore) t2 left join (select sid,avg(score) as sid_avg from tscore group by sid) as t3 on t1.sid=t3.sid;
可以看出,使用OVER()子句比使用聯接的方式簡潔了許多,並且當語句中包含多個分區聚合時(示例中包含兩個分區聚合操作),使用OVER()子句擁有更大的優勢,因為使用聯接的方式會涉及到多個聯接,將會多次掃描需要聯接的表。
使用OVER()子句另一個優點在於可以在表達式中混合使用基本列和聚合列值,而使用group by分組聚合時這是不允許的。下麵兩條語句在返回結果上等價的,第一條語句使用OVER()子句,第二條語句則使用聯接的方式。
select t1.*, avg(score) over() as sum_avg, score - avg(score) over() as diff_avg from tscore t1; /* 使用聯接的方式 */ select t1.*,sum_avg,score - t2.sum_avg as diff_avg from tscore t1 cross join (select avg(score) as sum_avg from tscore) as t2;
對於在相同的分區進行的多種聚合計算,不會影響性能。例如,下麵第一條語句僅包含一個OVER()子句,而第二條語句包含4個OVER()子句,但是它們的性能幾乎是一樣的。
SELECT t1.*, AVG(score) OVER(PARTITION BY sid) FROM tscore t1 /* 下麵的查詢和上面的查詢性能一樣 */ SELECT t1.*, AVG(score) OVER(PARTITION BY sid) AS Avgscore, SUM(score) OVER(PARTITION BY sid) AS Sumscore, MAX(score) OVER(PARTITION BY sid) AS Maxscore, MIN(score) OVER(PARTITION BY sid) AS Minscore FROM tscore t1;
第二條語句使用子查詢的替代語句如下。
select t1.*,Avgscore,Sumscore,Maxscore,Minscore from tscore t1 left join (select sid, AVG(score) Avgscore, SUM(score) Sumscore, MAX(score) Maxscore, MIN(score) Minscore from tscore group by sid) as t2 on t1.sid=t2.sid;
1.9 開窗函數的性能
使用視窗函數往往效率會比一般的SQL語句高的多的多,特別是數據較大時。以下是一個性能差異比較統計結果:其中regularSQL指的是使用了一個相關子查詢實現需求的SQL語句。(僅為說明性能差距,不具有代表性)
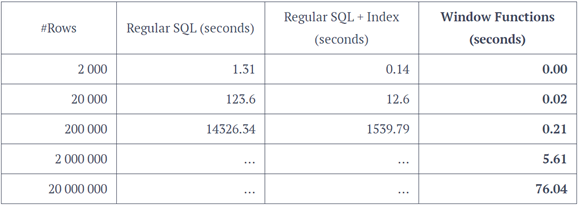
從表中可以看出,隨著行數每增大10倍,regularSQL和regularSQL+index的時間都成100倍增加,而開窗函數計算的時間相比它們則少的多。
此外,一個SQL語句中如果使用了多個OVER()子句,這些OVER()子句的內容完全一致,那麼很多時候只會做一次分區,這一個分區可以提供給多個開窗函數計算分析。正如上視窗聚合函數中所說:對於在相同的分區進行的多種聚合計算,不會影響性能。
總而言之,視窗函數為編寫SQL語句帶來了極大的便利性,且性能優越。如果能使用視窗函數解決問題,應儘量使用視窗函數。
回到Linux系列文章大綱:http://www.cnblogs.com/f-ck-need-u/p/7048359.html
回到網站架構系列文章大綱:http://www.cnblogs.com/f-ck-need-u/p/7576137.html


