
集合的操作 集合是一個無序的,不重覆的數據組合,它的主要作用如下: 去重,把一個列表變成集合,就自動去重了 關係測試,測試兩組數據之間的交集,差集,並集等關係 集合的寫法 list_1 = set([1, 3, 4, 6, 7, 12, 5]) 集合的關係 list_1 = set([1, 3, 5 ...
集合的操作
集合是一個無序的,不重覆的數據組合,它的主要作用如下:
去重,把一個列表變成集合,就自動去重了
關係測試,測試兩組數據之間的交集,差集,並集等關係
集合的寫法
list_1 = set([1, 3, 4, 6, 7, 12, 5])
集合的關係
list_1 = set([1, 3, 5, 7, 4, 9, 10])
list_2 = set([1, 8, 10, 15, 12])
集合的交集
print(list_1.intersection(list_2)) 等價於 print(list_1 & list_2)
--->{1, 10}
集合的並集
print(list_1.union(list_2)) 等價於 print(list_1 | list_2)
-->{1, 3, 5, 7, 8, 4, 9, 10, 15, 12}
集合的差集
print(list_1.difference(list_2)) 等價於 print(list_1 - list_2)
-->{3, 5, 7, 4, 9}
集合的子集
print(list_1.issubset(list_2))
list_1是否是list_2的子集
集合的父集
print(list_1.issuprset(list_2))
list_1是否是list_2的父集
集合的對稱差集
print(list_1.symmetric_difference(list_2)) 等價於 list_1 ^ list_2
-->{3, 5, 7, 4, 9, 8, 15, 12}
集合的其他函數用法
list_2.isdisjoint(list_3) #兩個無交集返回true
list_1.add(4) #集合的添加
list_1.remove(4) #集合的刪除,註意當集合中沒有該元素會報錯所以我們更多用下這個刪除
list_1,discard(4) #刪除,沒有該元素則什麼都不操作
文件的操作
文件的操作流程
1.打開文件,得到文件句柄並賦給變數一個值
2.通過句柄對文件進行操作
3.關閉文件
f = open("guangzhou", "r", encoding = "utf-8") #文件句柄
data = f.read() #f.readline()讀取一行
f.close()
這樣就把整個文件給讀出來了,假如read()兩遍,那麼第二個read()會讀出空的內容,因為當第一個read()執行完成後,這個時候游標位置就處在文件的結束位置,再進行讀取的時候也就讀不到內容了。
文件的操作模式
r:讀模式,預設是讀模式
open("guangzhou", "r", encoding = "utf-8")
w:寫模式,打開文件時時創建一個文件,也就是原來的文件沒有了
open("guangzhou", "w", encoding = "utf-8")
a:追加模式
open("guangzhou", "a", encoding = "utf-8") 只是不覆蓋文件,在文件的後面追加內容,這個模式還不支持讀read
r+:讀寫模式,以讀和追加的方式來讀寫,不管游標位置在哪,都在最後面寫
w+:寫讀模式,只能在最後面寫,不能寫到中間,這是硬碟機制
a+:追加讀
rb:二進位讀,用途網路傳輸,讀取音頻視頻文件
wb:二進位寫
文件從一個文件讀取並改變內容保存到另外一個文件
f = open("guangzhou", "r", encoding = "utf-8")
f_new = open("guanghzou3", "w", encoding = "utf-8")
#迴圈讀取文件,且這種效率最高,比readlines()高好多
for line in f:
if "人在廣東已經漂泊十年" in line:
line = line.replace("人在廣東已經漂泊十年", "Jason在廣東已經漂泊兩年")
f_new.write(line)
f.close()
f_new.close()
文件的其他方法
f = open("guangzhou", "r", encoding = "utf-8")
f.tell() #返回游標的位置,該返回的位置是字元的位置
f.seek(0) #回到某個游標位置
flush方法
當我們在以寫文件的方式打開一個文件的時候,我們執行完一條語句write並不一定寫到了硬碟上,它是先存到了記憶體中,當記憶體達到一定大小的時候才開始往硬碟上面寫,這是因為記憶體的寫速度要比硬碟快的多,但是當某些特定條件下需要實時刷新的話,我們就要用flush進行強制刷新,比如進度條,下麵的例子:
import sys, time
for i in range(20):
sys.stdout.write("*")
sys.stdout.flush()
time.sleep(0.1)
自己可以執行下看一下
with語句
為了避免文件打開後忘記關閉,可以通過管理上下文,即:
with open("guangzhou", "r") as f:
2.7版本之後也支持同時對多個文件管理,即:
with open("guangzhou", "r") as f, open("guangzhou2", "r") as f2:
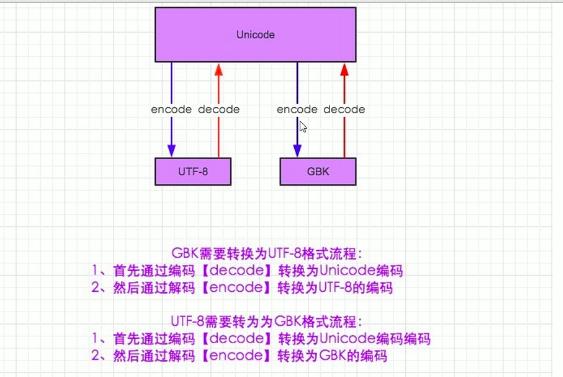
字元編碼與轉碼
字元集發展史
中國字元集發展:gb2312--->gb18030-->gbk
國際字元集發展:ascii(英文占用一個位元組,不能存中文)-->unicode(英中占用兩個位元組)-->utf-8(中文占用3個位元組,英文一個位元組)
函數與函數式編程
函數的定義方法
def text(x):
"The function definitions"
x += 1
return x
函數可以返回多個值,用元組來返回,比如return 1, 3, “hello”, ["a", "b", "c"], {”name”:"Jason"} 返回其實是(1, 3, “hello”, ["a", "b", "c"], {”name”:"Jason"})
函數增加參數
def text(x,y):
print(x,y)
調用方式:
1.text(1, 2) -->1,2 位置參數調用
2.text(x = 2,y = 1) -->2,1 關鍵字參數調用
3.text(2, y = 1) -->2 , 1
4. x = 1,
y = 2
text(x, y) -->1, 2
5.text(1, x = 2) 報錯,x得到了多個值
6.text(x = 2, 1)報錯
綜上所述,當既有位置參數又有關鍵字參數的時候,關鍵參數的後面不能有位置參數,且不能給多個參數賦值
函數的預設參數
1.參數固定
def text(x, y = 2):
print(x,y)
2.參數不固定,接受N個位置參數輸出用元組
def text(*args):
print(args)
text(1, 2, 3, 4, 6)或者text(*[1, 2, 3, 4, 6])
-->(1, 2, 3, 4, 6) 元組
3.接受N個關鍵字參數輸出字典方式
def text(**kwargs):
print(kwargs)
text(name = "Jason", age = 24) -->{‘name’:'Jason', 'age':24}
這些參數可以混合使用,比如:
def text(name, *args, **kwargs):
print(name)
print(args)
print(kwargs)
text(“Jason”, 1, 2, 5, name = "Jason", age = 24)
-->Jason
(1, 2, 5)
{'name':"Jason", 'age':24}
函數局部變數與全局變數
在子程式中定義的變數為局部變數,在程式的一開始定的變數為全局變數,全局變數作用域整個程式,局部變數作用域定義該變數的子程式,當全局變數與局部變數同名時,在定義局部變數的子程式中,局部變數起作用,在其他地方全局變數起作用。
在子程式中,變數字元串對全局變數的改變對外面沒影響,但是,當全局變數為列表字典集合的時候,這個時候改變會影響整個程式的
高階函數
變數可以指向函數,函數的參數能接受變數,那麼一個函數就可以就收另一個函數作為參數,這種函數稱之為高階函數。


