
一、Android中的緩存策略 一般來說,緩存策略主要包含緩存的添加、獲取和刪除這三類操作。如何添加和獲取緩存這個比較好理解,那麼為什麼還要刪除緩存呢?這是因為不管是記憶體緩存還是硬碟緩存,它們的緩存大小都是有限的。當緩存滿了之後,再想其添加緩存,這個時候就需要刪除一些舊的緩存並添加新的緩存。 因此L ...
一、Android中的緩存策略
一般來說,緩存策略主要包含緩存的添加、獲取和刪除這三類操作。如何添加和獲取緩存這個比較好理解,那麼為什麼還要刪除緩存呢?這是因為不管是記憶體緩存還是硬碟緩存,它們的緩存大小都是有限的。當緩存滿了之後,再想其添加緩存,這個時候就需要刪除一些舊的緩存並添加新的緩存。
因此LRU(Least Recently Used)緩存演算法便應運而生,LRU是近期最少使用的演算法,它的核心思想是當緩存滿時,會優先淘汰那些近期最少使用的緩存對象。採用LRU演算法的緩存有兩種:LrhCache和DisLruCache分別用於實現記憶體緩存和硬碟緩存,其核心思想都是LRU緩存演算法。
二、LruCache的使用
LruCache是Android 3.1所提供的一個緩存類,所以在Android中可以直接使用LruCache實現記憶體緩存。而DisLruCache目前在Android 還不是Android SDK的一部分,但Android官方文檔推薦使用該演算法來實現硬碟緩存。
1.LruCache的介紹
LruCache是個泛型類,主要演算法原理是把最近使用的對象用強引用(即我們平常使用的對象引用方式)存儲在 LinkedHashMap 中。當緩存滿時,把最近最少使用的對象從記憶體中移除,並提供了get和put方法來完成緩存的獲取和添加操作。
2.LruCache的使用
LruCache的使用非常簡單,我們就已圖片緩存為例。
int maxMemory = (int) (Runtime.getRuntime().totalMemory()/1024); int cacheSize = maxMemory/8; mMemoryCache = new LruCache<String,Bitmap>(cacheSize){ @Override protected int sizeOf(String key, Bitmap value) { return value.getRowBytes()*value.getHeight()/1024 ; }
①設置LruCache緩存的大小,一般為當前進程可用容量的1/8。
②重寫sizeOf方法,計算出要緩存的每張圖片的大小。
註意:緩存的總容量和每個緩存對象的大小所用單位要一致。
三、LruCache的實現原理
LruCache的核心思想很好理解,就是要維護一個緩存對象列表,其中對象列表的排列方式是按照訪問順序實現的,即一直沒訪問的對象,將放在隊尾,即將被淘汰。而最近訪問的對象將放在隊頭,最後被淘汰。
如下圖所示:
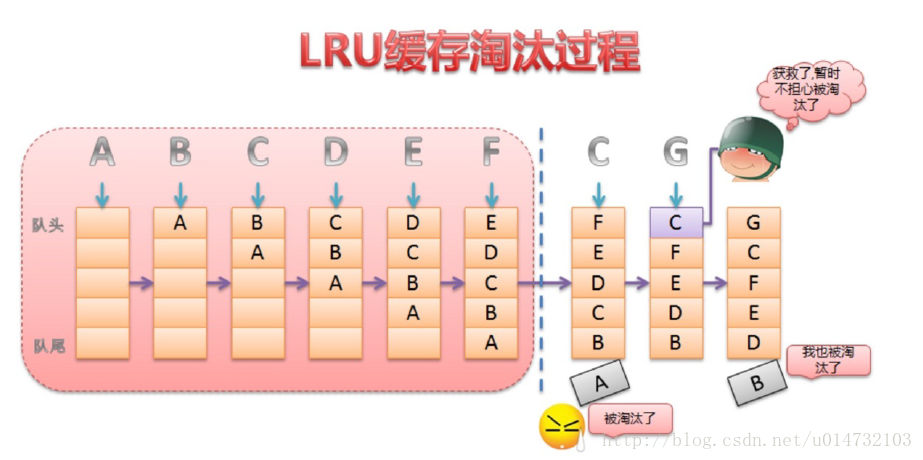
那麼這個隊列到底是由誰來維護的,前面已經介紹了是由LinkedHashMap來維護。而LinkedHashMap是由數組+雙向鏈表的數據結構來實現的。其中雙向鏈表的結構可以實現訪問順序和插入順序,使得LinkedHashMap中的對按照一定順序排列起來。
通過下麵構造函數來指定LinkedHashMap中雙向鏈表的結構是訪問順序還是插入順序。
public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }
其中accessOrder設置為true則為訪問順序,為false,則為插入順序。
以具體例子解釋: 當設置為true時
public static final void main(String[] args) { LinkedHashMap<Integer, Integer> map = new LinkedHashMap<>(0, 0.75f, true); map.put(0, 0); map.put(1, 1); map.put(2, 2); map.put(3, 3); map.put(4, 4); map.put(5, 5); map.put(6, 6); map.get(1); map.get(2); for (Map.Entry<Integer, Integer> entry : map.entrySet()) { System.out.println(entry.getKey() + ":" + entry.getValue()); } }
輸出結果:0:0 3:3 4:4 5:5 6:6 1:1 2:2
即最近訪問的最後輸出,那麼這就正好滿足的LRU緩存演算法的思想。可見LruCache巧妙實現,就是利用了LinkedHashMap的這種數據結構。
下麵我們在LruCache源碼中具體看看,怎麼應用LinkedHashMap來實現緩存的添加,獲得和刪除的。
public LruCache(int maxSize) { if (maxSize <= 0) { throw new IllegalArgumentException("maxSize <= 0"); } this.maxSize = maxSize; this.map = new LinkedHashMap<K, V>(0, 0.75f, true); }
從LruCache的構造函數中可以看到正是用了LinkedHashMap的訪問順序。
put()方法:
public final V put(K key, V value) { //不可為空,否則拋出異常 if (key == null || value == null) { throw new NullPointerException("key == null || value== null"); } V previous; synchronized (this) { //插入的緩存對象值加1 putCount++; //增加已有緩存的大小 size += safeSizeOf(key, value); //向map中加入緩存對象 previous = map.put(key, value); //如果已有緩存對象,則緩存大小恢復到之前 if (previous != null) { size -= safeSizeOf(key, previous); } } //entryRemoved()是個空方法,可以自行實現 if (previous != null) { entryRemoved(false, key, previous, value); } //調整緩存大小(關鍵方法) trimToSize(maxSize); return previous; }
可以看到put()方法並沒有什麼難點,重要的就是在添加過緩存對象後,調用trimToSize()方法,來判斷緩存是否已滿,如果滿了就要刪除近期最少使用的演算法。
trimToSize()方法:
public void trimToSize(int maxSize) { //死迴圈 while (true) { K key; V value; synchronized (this) { //如果map為空並且緩存size不等於0或者緩存size小於0,拋出異常 if (size < 0 || (map.isEmpty() && size != 0)) { throw new IllegalStateException(getClass().getName()+ ".sizeOf() is reporting inconsistent results!"); } //如果緩存大小size小於最大緩存,或者map為空,不需要再刪除緩存對象,跳出迴圈 if (size <= maxSize || map.isEmpty()) { break; } //迭代器獲取第一個對象,即隊尾的元素,近期最少訪問的元素 Map.Entry<K, V> toEvict = map.entrySet().iterator().next(); key = toEvict.getKey(); value = toEvict.getValue(); //刪除該對象,並更新緩存大小 map.remove(key); size -= safeSizeOf(key, value); evictionCount++; } entryRemoved(true, key, value, null); } }
trimToSize()方法不斷地刪除LinkedHashMap中隊尾的元素,即近期最少訪問的,直到緩存大小小於最大值。
當調用LruCache的get()方法獲取集合中的緩存對象時,就代表訪問了一次該元素,將會更新隊列,保持整個隊列是按照訪問順序排序。這個更新過程就是在LinkedHashMap中的get()方法中完成的。
先看LruCache的get()方法:
public final V get(K key) { //key為空拋出異常 if (key == null) { throw new NullPointerException("key == null"); } V mapValue; synchronized (this) { //獲取對應的緩存對象 //get()方法會實現將訪問的元素更新到隊列頭部的功能 mapValue = map.get(key); if (mapValue != null) { hitCount++; return mapValue; } missCount++; }
其中LinkedHashMap的get()方法如下:
public V get(Object key) { LinkedHashMapEntry<K,V> e = (LinkedHashMapEntry<K,V>)getEntry(key); if (e == null) return null; //實現排序的關鍵方法 e.recordAccess(this); return e.value; }
調用recordAccess()方法如下:
void recordAccess(HashMap<K,V> m) { LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m; //判斷是否是訪問排序 if (lm.accessOrder) { lm.modCount++; //刪除此元素 remove(); //將此元素移動到隊列的頭部 addBefore(lm.header); } }
由此可見LruCache中維護了一個集合LinkedHashMap,該LinkedHashMap是以訪問順序排序的。當調用put()方法時,就會在結合中添加元素,並調用trimToSize()判斷緩存是否已滿,如果滿了就用LinkedHashMap的迭代器刪除隊尾元素,即近期最少訪問的元素。當調用get()方法訪問緩存對象時,就會調用LinkedHashMap的get()方法獲得對應集合元素,同時會更新該元素到隊頭。


