
一、簡介 作為集成學習中非常著名的方法,隨機森林被譽為“代表集成學習技術水平的方法”,由於其簡單、容易實現、計算開銷小,使得它在現實任務中得到廣泛使用,因為其來源於決策樹和bagging,決策樹我在前面的一篇博客中已經詳細介紹,下麵就來簡單介紹一下集成學習與Bagging; 二、集成學習 集成學習( ...
一、簡介
作為集成學習中非常著名的方法,隨機森林被譽為“代表集成學習技術水平的方法”,由於其簡單、容易實現、計算開銷小,使得它在現實任務中得到廣泛使用,因為其來源於決策樹和bagging,決策樹我在前面的一篇博客中已經詳細介紹,下麵就來簡單介紹一下集成學習與Bagging;
二、集成學習
集成學習(ensemble learning)是指通過構建並結合多個學習器來完成學習任務,有時也被稱為多分類器系統(multi-classifier system)等;
集成學習的一般結構如下:
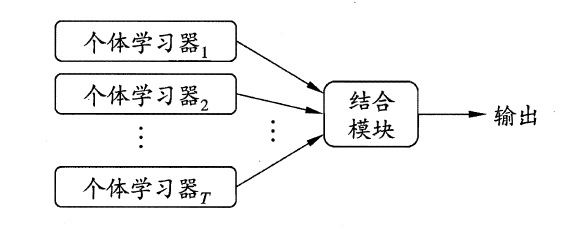
可以看出,集成學習的一般過程就是先產生一組“個體學習器”(individual learner),再使用某種策略將這些學習器結合起來。個體學習器通常由一個現有的學習演算法從訓練數據產生,例如C4.5決策樹演算法,BP神經網路演算法等,此時集成中只包含同種類型的個體學習器,譬如“決策樹集成”純由若幹個決策樹學習器組成,這樣的集成是“同質”(homogeneous),同質集成中的個體學習器又稱作“基學習器”(base learner),相應的學習演算法稱為“基學習演算法”(base learning algorithm)。集成也可以包含不同類型的個體學習器,例如可以同時包含決策樹與神經網路,這樣的集成就是“異質”的(heterogenous),異質集成中的個體學習器由不同的學習演算法組成,這時不再有基學習演算法;對應的,個體學習器也不再稱作基學習器,而是改稱為“組件學習器”(component learner)或直接成為個體學習器;
集成學習通過將多個學習器進行結合,常可獲得比單一學習器更加顯著優越的泛化性能,尤其是對“弱學習器”(weak learner),因此集成學習的很多理論研究都是針對弱學習器來的,通過分別訓練各個個體學習器,預測時將待預測樣本輸入每個個體學習器中產出結果,最後使用加權和、最大投票法等方法將所有個體學習器的預測結果處理之後得到整個集成的最終結果,這就是集成學習的基本思想;
三、Bagging
通過集成學習的思想,我們可以看出,想要得到泛化性能強的集成,則集成中的個體學習器應當儘可能相互獨立,但這在現實任務中幾乎無法實現,所以我們可以通過儘可能增大基學習器間的差異來達到類似的效果;一方面,我們希望儘可能增大基學習器間的差異:給定一個數據集,一種可能的做法是對訓練樣本進行採樣,分離出若幹個子集,再從每個子集中訓練出一個基學習器,這樣我們訓練出的各個基學習器因為各自訓練集不同的原因就有希望取得比較大的差異;另一方面,為了獲得好的集成,我們希望個體學習器的性能不要太差,因為如果非要使得採樣出的每個自己彼此不相交,則由於每個子集樣本數量不足而無法進行有效學習,從而無法確保產生性能較好的個體學習器,為瞭解決這矛盾的問題,Bagging應運而生;
Bagging是並行式集成學習方法最著名的代表,它基於自助採樣法(bootstrap sampling),對給定包含m個樣本的數據集,我們先隨機取出一個樣本放入採樣集中,再把該樣本放回初始數據集,即一次有放回的簡單隨機抽樣,這樣重覆指定次數的抽樣,得到一個滿足要求的採樣集合,且樣本數據集中的樣本有的在該採樣集中多次出現,有的則從未出現過,我們可以將那些沒有在該採樣集出現過的樣本作為該採樣集對應訓練出的學習器的驗證集,來近似估計該個體學習器的泛化能力,這被稱作“包外估計”(out-of-bag estimate),令Dt表示第t個個體學習器對應的採樣集,令Hoob(x)表示該集成學習器對樣本x的包外預測,即僅考慮那些未使用x訓練的學習器在x上的預測表現,有:
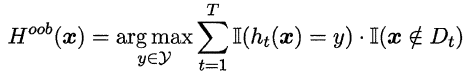
則Bagging泛化誤差的包外估計為:

而且包外樣本還可以在一些特定的演算法上實現較為實用的功能,例如當基學習器是決策樹時,可使用保外樣本來輔助剪枝,或用於估計決策樹中各結點的後驗概率以輔助對零訓練樣本節點的處理;當基學習器是神經網路時,可以用包外樣本來輔助進行早停操作;
四、隨機森林
隨機森林(Random Forest)是Bagging的一個擴展變體。其在以決策樹為基學習器構建Bagging集成的基礎上,進一步在決策樹的訓練過程中引入了隨機屬性選擇,即:傳統決策樹在選擇劃分屬性時是在當前結點的屬性集合中(假設共有d個結點)基於信息純度準則等選擇一個最優屬性,而在隨機森林中,對基決策樹的每個結點,先從該結點的屬性集合中隨機選擇一個包含k個屬性的子集,再對該子集進行基於信息準則的劃分屬性選擇;這裡的k控制了隨機性的引入程度;若令k=d,則基決策樹的構建與傳統決策樹相同;若令k=1,則每次的屬性選擇純屬隨機,與信息準則無關;一般情況下,推薦k=log2d。
隨機森林對Bagging只做了小小的改動,但是與Bagging中基學習器的“多樣性”僅通過樣本擾動(即改變採樣規則)不同,隨機森林中基學習器的多樣性不僅來自樣本擾動,還來自屬性擾動,這就使得最終集成的泛化性能可通過個體學習器之間差異度的增加而進一步提升;
隨機森林的收斂性與Bagging類似,但隨機森林在基學習器數量較為可觀時性能會明顯提升,即隨著基學習器數量的增加,隨機森林會收斂到更低的泛化誤差;
五、Python實現
我們使用sklearn.ensemble中的RandomForestClassifier()來進行隨機森林分類,其細節如下:
常用參數:
n_estimator:整數型,控制隨機森林演算法中基決策樹的數量,預設為10,我建議取一個100-1000之間的奇數;
criterion:字元型,用來指定做屬性劃分時使用的評價準則,'gini'表示基尼繫數,也就是CART樹,'entropy'表示信息增益;
max_features:用來控制每個結點劃分時從當前樣本的屬性集合中隨機抽取的屬性個數,即控制了隨機性的引入程度,預設為'auto',有以下幾種選擇:
1.int型時,則該傳入參數即作為max_features;
2.float型時,將 傳入數值*n_features 作為max_features;
3.字元串時,若為'auto',max_features=sqrt(n_features);'sqrt'時, 同'auto';'log2'時,max_features=log2(n_features);
4.None時,max_features=n_features;
max_depth:控制每棵樹所有預測路徑的長度上限(即從根結點出發經歷的劃分屬性的個數),建議訓練時該參數從小逐漸調大;預設為None,此時每棵樹只有等到所有的葉結點中都只存在一種類別的樣本或結點中樣本數小於min_samples_split時化成葉結點時該預測路徑才停止生長;
min_samples_split:該參數控制當結點中樣本數量小於某個整數k時將某個結點標記為葉結點(即停止該預測路徑的生長),傳入參數即控制k,當傳入參數為整數時,該參數即為k;當傳入參數屬於0.0~1.0之間時,k=傳入參數*n_samples;預設值為2;
max_leaf_nodes:控制每棵樹的最大葉結點數量,預設為None,即無限制;
min_impurity_decrease:控制過擬合的一種措施,傳入一個浮點型的數,則在每棵樹的生長過程中,若下一個節點中的信息純度與上一個結點中的節點純度差距小於這個值,則這一次劃分被剪去;
booststrap:bool型變數,控制是否採取自助法來劃分每棵樹的訓練數據(即每棵樹的訓練數據間是否存在相交的可能),預設為True;
oob_score:bool型變數,控制是否用包外誤差來近似學習器的泛化誤差;
n_jobs:控制並行運算時的核心數,預設為單核即1,特別的,設置為-1時開啟所有核心;
random_rate:設置隨機數種子,目的是控制演算法中隨機的部分,預設為None,即每次運行都是隨機地(偽隨機);
class_weight:用於處理類別不平衡問題,即為每一個類別賦權,預設為None,即每個類別權重都為1;'balanced'則自動根據樣本集中的類別比例為演算法賦權;
函數輸出項:
estimators_:包含所有訓練好的基決策樹細節的列表;
classes:顯示所有類別;
n_classes_:顯示類別總數;
n_features_:顯示特征數量(訓練之後才有這個輸出項);
feature_importances_:顯示訓練中所有特征的重要程度,越大越重要;
oob_score_:學習器的包外估計得分;
下麵我們以sklearn.datasets自帶的威斯康辛州乳腺癌數據作為演示數據,具體過程如下:
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score as f1 from sklearn.metrics import confusion_matrix as con from sklearn import datasets ###載入威斯康辛州乳腺癌數據 X,y = datasets.load_breast_cancer(return_X_y=True) ###分割訓練集與測試集 X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3) ###初始化隨機森林分類器,這裡為類別做平衡處理 clf = RandomForestClassifier(class_weight='balanced',random_state=1) ###返回由訓練集訓練成的模型對驗證集預測的結果 result = clf.fit(X_train,y_train).predict(X_test) ###列印混淆矩陣 print('\n'+'混淆矩陣:') print(con(y_test,result)) ###列印F1得分 print('\n'+'F1 Score:') print(f1(y_test,result)) ###列印測試準確率 print('\n'+'Accuracy:') print(clf.score(X_test,y_test))
運行結果如下:

可以看出,隨機森林的性能十分優越。
六、R實現
在R語言中我們使用randomForest包中的randomForest()函數來進行隨機森林模型的訓練,其主要參數如下:
formula:一種 因變數~自變數 的公式格式;
data:用於指定訓練數據所在的數據框;
xtest:randomForest提供了一種很舒服的(我竊認為)將訓練與驗證一步到位的體制,這裡xtest傳入的就是驗證集中的自變數;
ytest:對應xtest的驗證集的label列,預設時則xtest視為無標簽的待預測數據,這時可以使用test$predicted來調出對應的預測值(實在是太舒服了);
ntree:基決策樹的數量,預設是500(R相當實在),我建議設定為一個大小比較適合的奇數;
classwt:用於處理類別不平衡問題,即傳入一個包含因變數各類別比例的向量;
nodesize:生成葉結點的最小樣本數,即當某個結點中樣本數量小於這個值時自動將該結點標記為葉結點並計算輸出概率,好處是可以儘量避免生長出太過於龐大的樹,也就減少了過擬合的可能,也在一定程度上縮短了訓練時間;
maxnodes:每顆基決策樹允許產生的最大的葉結點數量,預設時則每棵樹無限制生長;
importance:邏輯型變數,控制是否計算每個變數的重要程度;
proxi:邏輯型變數,控制是否計算每顆基決策樹的複雜度;
函數輸出項:
call:訓練好的隨機森林模型的預設參數情況;
type:輸出模型對應的問題類型,有'regression','classification','unsupervised';
importance:輸出所有特征在模型中的貢獻程度;
ntree:輸出基決策樹的顆數;
test$predicted:輸出在ytest預設,xtest給出的情況下,其對應的預測值;
test$confusion:輸出在xtest,ytest均給出的條件下,xtest的預測值與ytest代表的正確標記之間的混淆矩陣;
test$votes:輸出隨機森林模型中每一棵樹對xtest每一個樣本的投票情況;
下麵我們以鳶尾花數據為例,進行演示,具體過程如下:
> rm(list=ls()) > library(randomForest) > > #load data > data(iris) > > #split data > sam = sample(1:150,120) > train = iris[sam,] > test = iris[-sam,] > > #訓練隨機森林分類器 > rf = randomForest(Species~.,data=train, + classwt=table(train$Species)/dim(train)[1], + ntree=11, + xtest=test[,1:4], + importance=T, + proximity=T) > > #列印混淆矩陣 > rf$test$confusion NULL > > #列印正確率 > sum(diag(prop.table(table(test$Species,rf$test$predicted)))) [1] 1 > > #列印特征的重要性程度 > importance(rf,type=2) MeanDecreaseGini Sepal.Length 8.149513 Sepal.Width 1.485798 Petal.Length 38.623601 Petal.Width 31.085027 > > #可視化特征的重要性程度 > varImpPlot(rf)
特征重要程度可視化:

上圖每個點表示將對應的特征移除後平均減少了正確率,所以點在圖中位置越高就越重要;
輸出每個樣本接受基決策樹投票的具體情況:
> #vote results of base decision tree > rf$test$votes setosa versicolor virginica 2 1.0000000 0.00000000 0.0000000 8 1.0000000 0.00000000 0.0000000 13 1.0000000 0.00000000 0.0000000 14 1.0000000 0.00000000 0.0000000 15 0.9090909 0.09090909 0.0000000 18 1.0000000 0.00000000 0.0000000 20 1.0000000 0.00000000 0.0000000 25 1.0000000 0.00000000 0.0000000 26 1.0000000 0.00000000 0.0000000 27 1.0000000 0.00000000 0.0000000 32 1.0000000 0.00000000 0.0000000 36 1.0000000 0.00000000 0.0000000 37 1.0000000 0.00000000 0.0000000 39 1.0000000 0.00000000 0.0000000 61 0.0000000 1.00000000 0.0000000 62 0.0000000 1.00000000 0.0000000 87 0.0000000 1.00000000 0.0000000 91 0.0000000 1.00000000 0.0000000 96 0.0000000 1.00000000 0.0000000 97 0.0000000 1.00000000 0.0000000 104 0.0000000 0.00000000 1.0000000 108 0.0000000 0.00000000 1.0000000 110 0.0000000 0.00000000 1.0000000 111 0.0000000 0.00000000 1.0000000 113 0.0000000 0.00000000 1.0000000 122 0.0000000 0.09090909 0.9090909 126 0.0000000 0.00000000 1.0000000 128 0.0000000 0.00000000 1.0000000 140 0.0000000 0.00000000 1.0000000 143 0.0000000 0.09090909 0.9090909 attr(,"class") [1] "matrix" "votes"
以上就是關於隨機森林的基本內容,本篇今後會陸續補充更深層次的知識,如有筆誤,望指出。

