
文件組的基本知識點介紹完畢後,根據場景引入中的內容,我們將利用SQL Server文件組技術來實現冷熱數據隔離備份的方案設計介紹如下。 設計分析 由於payment資料庫過大,超過10TB,單次全量備份超過20小時,如果按照常規的完全備份,會導致備份文件過大、耗時過長、甚至會因為備份操作對I/O能力 ...
文件組的基本知識點介紹完畢後,根據場景引入中的內容,我們將利用SQL Server文件組技術來實現冷熱數據隔離備份的方案設計介紹如下。
設計分析
由於payment資料庫過大,超過10TB,單次全量備份超過20小時,如果按照常規的完全備份,會導致備份文件過大、耗時過長、甚至會因為備份操作對I/O能力的消耗影響到正常業務。我們仔細想想會發現,雖然資料庫本身很大,但是,由於只有當前年表數據會不斷變化(熱數據),歷史年表數據不會修改(冷數據),因此正真有數據變化操作的數據量相對整個庫來看並不大。那麼,我們將資料庫設計為歷史年表數據放到Read only的文件組上,把當前年表數據放到Read write的文件組上,備份系統僅僅需要備份Primary和當前年表所在的文件組即可(當然首次還是需要對資料庫做一次性完整備份的)。這樣既可以大大節約備份對I/O能力的消耗,又實現了冷熱數據的隔離備份操作,還達到了分散了文件的I/O壓力,最終達到資料庫設計和備份系統優化的目的,可謂一箭多雕。
以上文字分析,畫一個漂亮的設計圖出來,直觀展示如下: 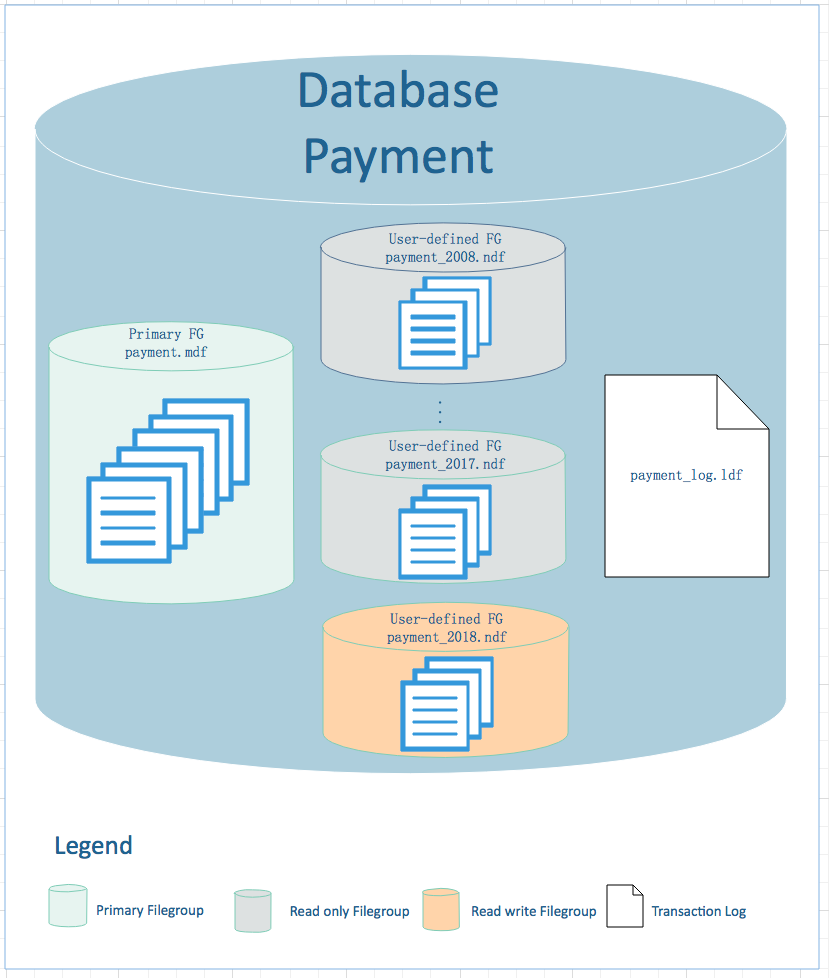
設計圖說明
以下對設計圖做詳細說明,以便對設計方案有更加直觀和深入理解。 整個資料庫包含13個文件,包括:
1個主文件組(Primary File Group):用戶存放資料庫系統表、視圖等對象信息,文件組可讀可寫。
10個用戶自定義只讀文件組(User-defined Read Only File Group):用於存放歷史年表的數據及相應索引數據,每一年的數據存放到一個文件組中。
1個用戶自定義可讀寫文件組(User-defined Read Write File Group):用於存放當前年表數據和相應索引數據,該表數據必須可讀可寫,所以文件組必須可讀可寫。
1個資料庫事務日誌文件:用於資料庫事務日誌,我們需要定期備份資料庫事務日誌。
方案實現
設計方案完成以後,接下來就是方案的集體實現了,具體實現包括:
創建資料庫
創建年表
文件組設置
冷熱備份實現
創建資料庫
創建資料庫的同時,我們創建了Primary文件組和2008 ~ 2017的文件組,這裡需要特別提醒,請務必保證所有文件組中文件的初始大小和增長量相同,代碼如下:
USE master
GO
EXEC sys.xp_create_subdir 'C:\DATA\Payment\Data\'
EXEC sys.xp_create_subdir 'C:\DATA\Payment\Log\'
CREATE DATABASE [Payment]
ON PRIMARY
( NAME = N'Payment', FILENAME = N'C:\DATA\Payment\Data\Payment.mdf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2008]
( NAME = N'FGPayment2008', FILENAME = N'C:\DATA\Payment\Data\Payment_2008.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2009]
( NAME = N'FGPayment2009', FILENAME = N'C:\DATA\Payment\Data\Payment_2009.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2010]
( NAME = N'FGPayment2010', FILENAME = N'C:\DATA\Payment\Data\Payment_2010.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2011]
( NAME = N'FGPayment2011', FILENAME = N'C:\DATA\Payment\Data\Payment_2011.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2012]
( NAME = N'FGPayment2012', FILENAME = N'C:\DATA\Payment\Data\Payment_2012.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2013]
( NAME = N'FGPayment2013', FILENAME = N'C:\DATA\Payment\Data\Payment_2013.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2014]
( NAME = N'FGPayment2014', FILENAME = N'C:\DATA\Payment\Data\Payment_2014.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2015]
( NAME = N'FGPayment2015', FILENAME = N'C:\DATA\Payment\Data\Payment_2015.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2016]
( NAME = N'FGPayment2016', FILENAME = N'C:\DATA\Payment\Data\Payment_2016.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2017]
( NAME = N'FGPayment2017', FILENAME = N'C:\DATA\Payment\Data\Payment_2017.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB )
LOG ON
( NAME = N'Payment_log', FILENAME = N'C:\DATA\Payment\Log\Payment_log.ldf' , SIZE = 5MB , FILEGROWTH = 50MB)
GO
考慮到每年我們都要添加新的文件組到資料庫中,因此2018年的文件組單獨創建如下:
--Add filegroup FGPayment2018
USE master
GO
ALTER DATABASE [Payment] ADD FILEGROUP [FGPayment2018];
-- Add data file to FGPayment2018
ALTER DATABASE [Payment]
ADD FILE (NAME = FGPayment2018, SIZE = 5MB , FILEGROWTH = 50MB ,FILENAME = N'C:\DATA\Payment\Data\Payment_2018.ndf')
TO FILEGROUP [FGPayment2018]
GO
最終再次確認資料庫文件組信息,代碼如下:
USE [Payment]
GO
SELECT file_name = mf.name, filegroup_name = fg.name, mf.physical_name,mf.size,mf.growth
FROM sys.master_files AS mf
INNER JOIN sys.filegroups as fg
ON mf.data_space_id = fg.data_space_id
WHERE mf.database_id = db_id('Payment')
ORDER BY mf.type;
結果展示如下圖所示: 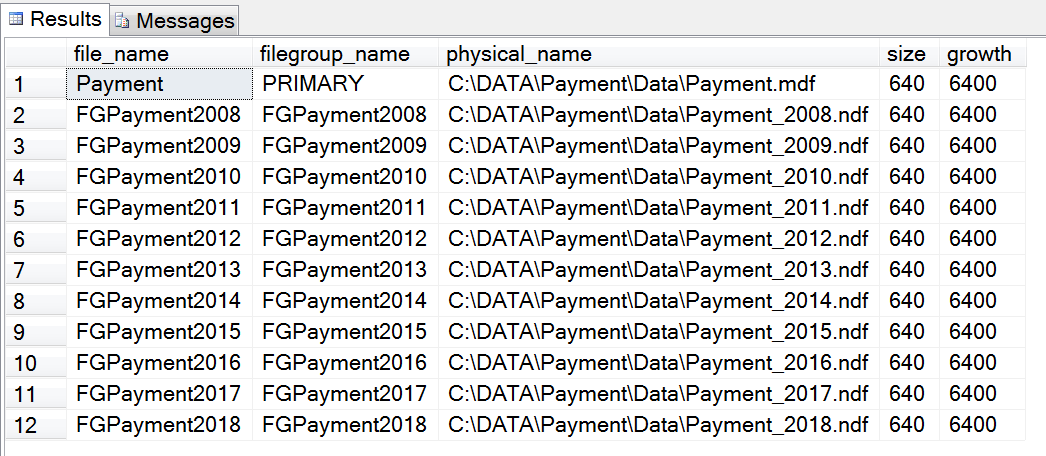
創建年表
資料庫以及相應文件組創建完畢後,接下來我們創建對應的年表並插入一些測試數據,如下:
USE [Payment]
GO
CREATE TABLE [dbo].[Payment_2008](
[Payment_ID] [bigint] IDENTITY(12008,100) NOT NULL,
[OrderID] [bigint] NOT NULL,
CONSTRAINT [PK_Payment_2008] PRIMARY KEY CLUSTERED
(
[Payment_ID] ASC
) ON [FGPayment2008]
) ON [FGPayment2008]
GO
CREATE NONCLUSTERED INDEX IX_OrderID
ON [dbo].[Payment_2008] ([OrderID])
ON [FGPayment2008];
CREATE TABLE [dbo].[Payment_2009](
[Payment_ID] [bigint] IDENTITY(12009,100) NOT NULL,
[OrderID] [bigint] NOT NULL,
CONSTRAINT [PK_Payment_2009] PRIMARY KEY CLUSTERED
(
[Payment_ID] ASC
) ON [FGPayment2009]
) ON [FGPayment2009]
GO
CREATE NONCLUSTERED INDEX IX_OrderID
ON [dbo].[Payment_2009] ([OrderID])
ON [FGPayment2009];
--這裡省略了2010-2017的表創建,請參照以上建表和索引代碼,自行補充
CREATE TABLE [dbo].[Payment_2018](
[Payment_ID] [bigint] IDENTITY(12018,100) NOT NULL,
[OrderID] [bigint] NOT NULL,
CONSTRAINT [PK_Payment_2018] PRIMARY KEY CLUSTERED
(
[Payment_ID] ASC
) ON [FGPayment2018]
) ON [FGPayment2018]
GO
CREATE NONCLUSTERED INDEX IX_OrderID
ON [dbo].[Payment_2018] ([OrderID])
ON [FGPayment2018];
這裡需要特別提醒兩點:
限於篇幅,建表代碼中省略了2010 - 2017表創建,請自行補充
每個年表的Payment_ID欄位初始值是不一樣的,以免查詢所有payment信息該欄位值存在重覆的情況
其次,我們檢查所有年表的文件組分佈情況如下:
USE [Payment]
GO
SELECT table_name = tb.[name], index_name = ix.[name], located_filegroup_name = fg.[name]
FROM sys.indexes ix
INNER JOIN sys.filegroups fg
ON ix.data_space_id = fg.data_space_id
INNER JOIN sys.tables tb
ON ix.[object_id] = tb.[object_id]
WHERE ix.data_space_id = fg.data_space_id
GO
查詢結果截取其中部分如下,我們看到所有年表及索引都按照我們的預期分佈到對應的文件組上去了。 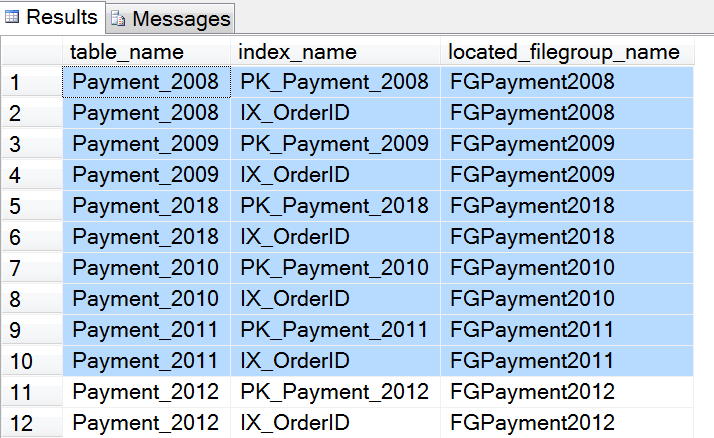
最後,為了測試,我們在對應年表中放入一些數據:
USE [Payment]
GO
SET NOCOUNT ON
INSERT INTO [Payment_2008] SELECT 2008;
INSERT INTO [Payment_2009] SELECT 2009;
--省略掉2010 - 2017,自行補充
INSERT INTO [Payment_2018] SELECT 2018;
文件組設置
年表創建完完畢、測試數據初始化完成後,接下來,我們做文件組讀寫屬性的設置,代碼如下:
USE master
GO
ALTER DATABASE [Payment] MODIFY FILEGROUP [FGPayment2008] READ_ONLY;
ALTER DATABASE [Payment] MODIFY FILEGROUP [FGPayment2009] READ_ONLY;
--這裡省略了2010 - 2017文件組read only屬性的設置,請自行補充
ALTER DATABASE [Payment] MODIFY FILEGROUP [FGPayment2018] READ_WRITE;
最終我們的文件組讀寫屬性如下:
USE [Payment]
GO
SELECT name, is_default, is_read_only FROM sys.filegroups
GO
截圖如下:
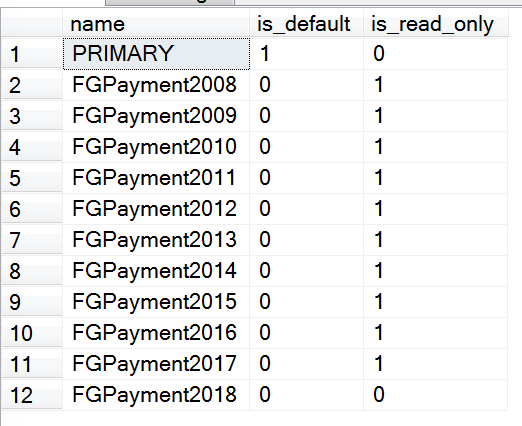
冷熱備份實現
所有文件組創建成功,並且讀寫屬性配置完畢後,我們需要對資料庫可讀寫文件組進行全量備份、差異備份和資料庫級別的日誌備份,為了方便測試,我們會在兩次備份之間插入一條數據。備份操作的大體思路是:
首先,對整個資料庫進行一次性全量備份
其次,對可讀寫文件組進行周期性全量備份
接下來,對可讀寫文件組進行周期性差異備份
最後,對整個資料庫進行周期性事務日誌備份
--Take a one time full backup of payment database
USE [master];
GO
BACKUP DATABASE [Payment]
TO DISK = N'C:\DATA\Payment\BACKUP\Payment_20180316_full.bak'
WITH COMPRESSION, Stats=5
;
GO
-- for testing, init one record
USE [Payment];
GO
INSERT INTO [dbo].[Payment_2018] SELECT 201801;
GO
--Take a full backup for each writable filegoup (just backup FGPayment2018 as an example)
BACKUP DATABASE [Payment]
FILEGROUP = 'FGPayment2018'
TO DISK = 'C:\DATA\Payment\BACKUP\Payment_FGPayment2018_20180316_full.bak'
WITH COMPRESSION, Stats=5
;
GO
-- for testing, insert one record
INSERT INTO [dbo].[Payment_2018] SELECT 201802;
GO
--Take a differential backup for each writable filegoup (just backup FGPayment2018 as an example)
BACKUP DATABASE [Payment]
FILEGROUP = N'FGPayment2018'
TO DISK = N'C:\DATA\Payment\BACKUP\Payment_FGPayment2018_20180316_diff.bak'
WITH DIFFERENTIAL, COMPRESSION, Stats=5
;
GO
-- for testing, insert one record
INSERT INTO [dbo].[Payment_2018] SELECT 201803;
GO
-- Take a transaction log backup of database payment
BACKUP LOG [Payment]
TO DISK = 'C:\DATA\Payment\BACKUP\Payment_20180316_log.trn';
GO
這樣備份的好處是,我們只需要對可讀寫的文件組(FGPayment2018)進行完整和差異備份(Primary中包含系統對象,變化很小,實際場景中,Primary文件組也需要備份),而其他的9個只讀文件組無需備份,因為數據不會再變化。如此,我們就實現了冷熱數據隔離備份的方案。 接下來的一個問題是,萬一Payment數據發生災難,導致數據損失,我們如何從備份集中將資料庫恢復出來呢?我們可以按照如下思路來恢復備份集:
首先,還原整個資料庫的一次性全量備份
其次,還原所有可讀寫文件組最後一個全量備份
接下來,還原可讀寫文件組最後一個差異備份
最後,還原整個資料庫的所有事務日誌備份
-- We restore full backup
USE master
GO
RESTORE DATABASE [Payment_Dev]
FROM DISK=N'C:\DATA\Payment\BACKUP\Payment_20180316_full.bak' WITH
MOVE 'Payment' TO 'C:\DATA\Payment_Dev\Data\Payment_dev.mdf',
MOVE 'FGPayment2008' TO 'C:\DATA\Payment_Dev\Data\FGPayment2008_dev.ndf',
MOVE 'FGPayment2009' TO 'C:\DATA\Payment_Dev\Data\FGPayment2009_dev.ndf',
MOVE 'FGPayment2010' TO 'C:\DATA\Payment_Dev\Data\FGPayment2010_dev.ndf',
MOVE 'FGPayment2011' TO 'C:\DATA\Payment_Dev\Data\FGPayment2011_dev.ndf',
MOVE 'FGPayment2012' TO 'C:\DATA\Payment_Dev\Data\FGPayment2012_dev.ndf',
MOVE 'FGPayment2013' TO 'C:\DATA\Payment_Dev\Data\FGPayment2013_dev.ndf',
MOVE 'FGPayment2014' TO 'C:\DATA\Payment_Dev\Data\FGPayment2014_dev.ndf',
MOVE 'FGPayment2015' TO 'C:\DATA\Payment_Dev\Data\FGPayment2015_dev.ndf',
MOVE 'FGPayment2016' TO 'C:\DATA\Payment_Dev\Data\FGPayment2016_dev.ndf',
MOVE 'FGPayment2017' TO 'C:\DATA\Payment_Dev\Data\FGPayment2017_dev.ndf',
MOVE 'FGPayment2018' TO 'C:\DATA\Payment_Dev\Data\FGPayment2018_dev.ndf',
MOVE 'Payment_log' TO 'C:\DATA\Payment_Dev\Log\Payment_dev_log.ldf',
NORECOVERY,STATS=5;
GO
-- restore writable filegroup full backup
RESTORE DATABASE [Payment_Dev]
FILEGROUP = N'FGPayment2018'
FROM DISK = N'C:\DATA\Payment\BACKUP\Payment_FGPayment2018_20180316_full.bak'
WITH NORECOVERY,STATS=5;
GO
-- restore writable filegroup differential backup
RESTORE DATABASE [Payment_Dev]
FILEGROUP = N'FGPayment2018'
FROM DISK = N'C:\DATA\Payment\BACKUP\Payment_FGPayment2018_20180316_diff.bak'
WITH NORECOVERY,STATS=5;
GO
-- restore payment database transaction log backup
RESTORE LOG [Payment_Dev]
FROM DISK = N'C:\DATA\Payment\BACKUP\\Payment_20180316_log.trn'
WITH NORECOVERY;
GO
-- Take database oneline to check
RESTORE DATABASE [Payment_Dev] WITH RECOVERY;
GO
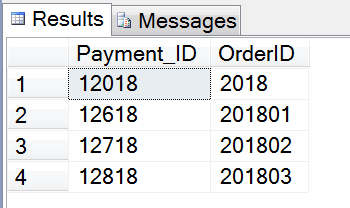
最後檢查數據還原的結果,按照我們插入的測試數據,應該會有四條記錄。
USE [Payment_Dev]
GO
SELECT * FROM [dbo].[Payment_2018] WITH(NOLOCK)
展示執行結果,有四條結果集,符合我們的預期,截圖如下:
最後總結
本篇月報分享瞭如何利用SQL Server文件組技術來實現和優化冷熱數據隔離備份的方案,在大大提升資料庫備份還原效率的同時,還提供了I/O資源的負載均衡,提升和優化了整個資料庫的性能。

