
學習目的: 解決AJAX請求的爬蟲,網頁解析庫的學習,MongoDB的簡單應用 正式步驟 Step1:流程分析 Step2:實例分析 1. 打開今日頭條搜索頁,搜索“中超”,查看頁面的請求方法為:GET 2. 創建一個Python文件:spider_ajax.py 3.網站url信息獲取 4. 列印 ...
學習目的:
解決AJAX請求的爬蟲,網頁解析庫的學習,MongoDB的簡單應用
正式步驟
Step1:流程分析
- 抓取單頁內容:利用requests請求目標站點,得到單個頁面的html代碼,返回結果;
- 抓取頁面詳情內容:解析返回結果,得到詳情頁的鏈接,併進一步抓取詳情頁的信息;
- 下載圖片並保存資料庫:將圖片下載到本地,把頁面信息及圖片url保存至MongoDB;
- 開啟迴圈及多線程:對多頁面內容遍歷,開啟多線程並提高抓取效率。
Step2:實例分析
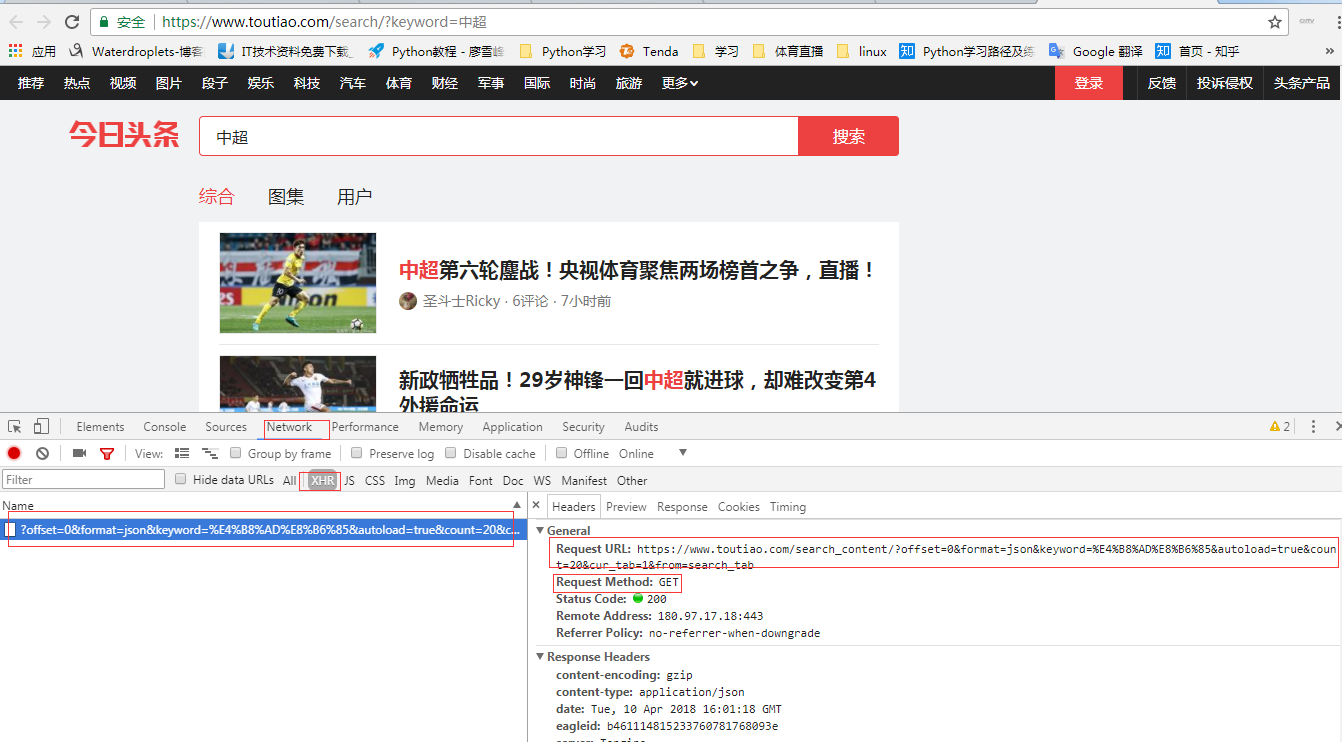
1. 打開今日頭條搜索頁,搜索“中超”,查看頁面的請求方法為:GET
2. 創建一個Python文件:spider_ajax.py
3.網站url信息獲取
4. 列印抓取的文章超鏈接和抓取的html內容
# -*- coding:utf-8 -*- import json from urllib.parse import urlencode from requests.exceptions import RequestException import requests def get_page_html(offset,keyword): data = { 'offset':offset, 'format':'json', 'keyword':keyword, 'autoload':'true', 'count':'20', 'cur_tab':1 } # urlencode把字典對象自動轉化為url參數, # 快速導入,請選中以後,按alt+enter url = 'https://www.toutiao.com/search_content/?' + urlencode(data) try: response = requests.get(url) if response.status_code == 200: return response.text return None except RequestException: print('請求索引頁失敗') return None def parse_page_index(html): #因為html列印出來是json字元串格式,json.loads作用是將已編碼的 JSON 字元串解碼為 Python 對象 # json.dumps作用是將 Python 對象編碼成 JSON 字元串 #參考http://www.runoob.com/python/python-json.html data = json.loads(html) if data and 'data' in data.keys(): for item in data.get('data'): yield item.get('article_url') def main(): html = get_page_html(0,'中超') #列印抓取的文章詳細內容的url for url in parse_page_index(html): print(url) #列印獲取頁面內容 print(html) if __name__ == '__main__': main()
後面的內容因為爬蟲被封,很多信息獲取不到,暫時不會,以後再補全這節內容
學習總結:
想爬取商業的門戶網站,感覺一臉懵逼


