
之前寫了一篇C#裝飾模式的文章提到了.NET Core的Stream, 所以這裡儘量把Stream介紹全點. (都是書上的內容) .NET Core/.NET的Streams 首先需要知道, System.IO命名空間是低級I/O功能的大本營. Stream的結構 .NET Core裡面的Strea ...
之前寫了一篇C#裝飾模式的文章提到了.NET Core的Stream, 所以這裡儘量把Stream介紹全點. (都是書上的內容)
.NET Core/.NET的Streams
首先需要知道, System.IO命名空間是低級I/O功能的大本營.
Stream的結構
.NET Core裡面的Stream主要是三個概念: 存儲(backing stores 我不知道怎麼翻譯比較好), 裝飾器, 適配器.
backing stores是讓輸入和輸出發揮作用的端點, 例如文件或者網路連接. 就是下麵任意一點或兩點:
- 一個源, 從它這裡位元組可以被順序的讀取
- 一個目的地, 位元組可以被連續的寫入.
程式員可以通過Stream類來發揮backing store的作用. Stream類有一套方法, 可以進行讀取, 寫入, 定位等操作. 個數組不同的是, 數組是把所有的數據都一同放在了記憶體里, 而stream則是順序的/連續的處理數據, 要麼是一次處理一個位元組, 要麼是一次處理特定大小(不能太大, 可管理的範圍內)的數據.
於是, stream可以用比較小的固定大小的記憶體來處理無論多大的backing store.
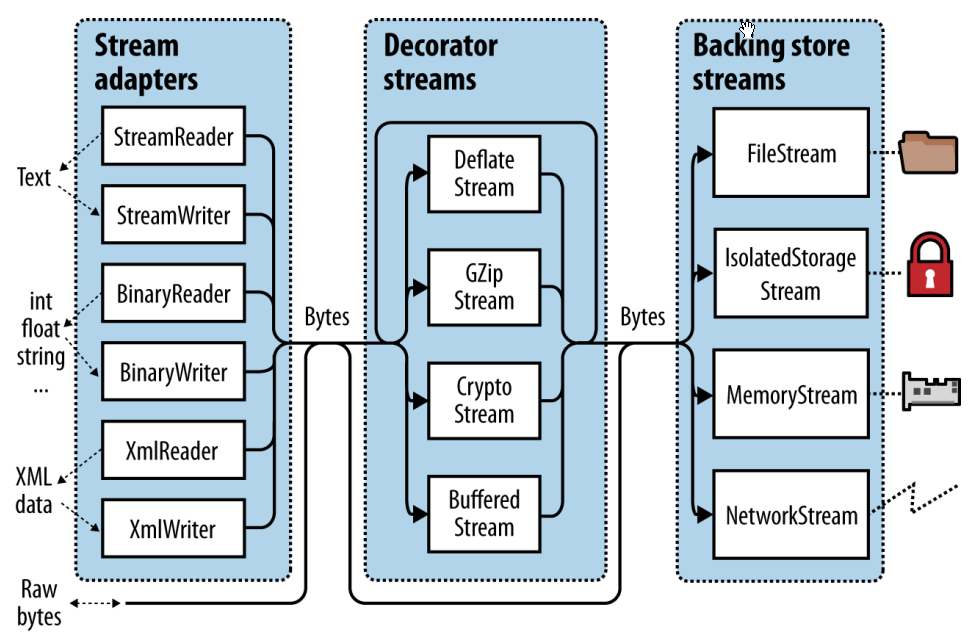
中間的那部分就是裝飾器Stream. 它符合裝飾模式.
從圖中可以看到, Stream又分為兩部分:
- Backing Store Streams: 硬連接到特定類型的backing store, 例如FileStream和NetworkStream
- Decorator Streams 裝飾器Stream: 使用某種方式把數據進行了轉化, 例如DeflateStream和CryptoStream.
裝飾器Stream有如下結構性的優點(參考裝飾模式):
- 無需讓backing store stream去實現例如壓縮, 加密等功能.
- 裝飾的時候介面(interface)並沒有變化
- 可以在運行時進行裝飾
- 可以串聯裝飾(先後進行多個裝飾)
backing store和裝飾器stream都是按位元組進行處理的. 儘管這很靈活和高效, 但是程式一般還是採用更高級別的處理方式例如文字或者xml.
適配器通過使用特殊化的方法把類裡面的stream進行包裝成特殊的格式. 這就彌合了上述的間隔.
例如 text reader有一個ReadLine方法, XML writer又WriteAttributes方法.
註意: 適配器包裝了stream, 這點和裝飾器一樣, 但是不一樣的是, 適配器本身並不是stream, 它一般會把所有針對位元組的方法都隱藏起來. 所以本文就不介紹適配器了.
總結一下:
backing store stream 提供原始數據, 裝飾器stream提供透明的轉換(例如加密); 適配器提供方法來處理高級別的類型例如字元串和xml.
想要連成串的話, 秩序把對象傳遞到另一個對象的構造函數里.
使用Stream
Stream抽象類是所有Stream的基類.
它的方法和屬性主要分三類基本操作: 讀, 寫, 定址(Seek); 和管理操作: 關閉(close), 沖(flush)和設定超時:
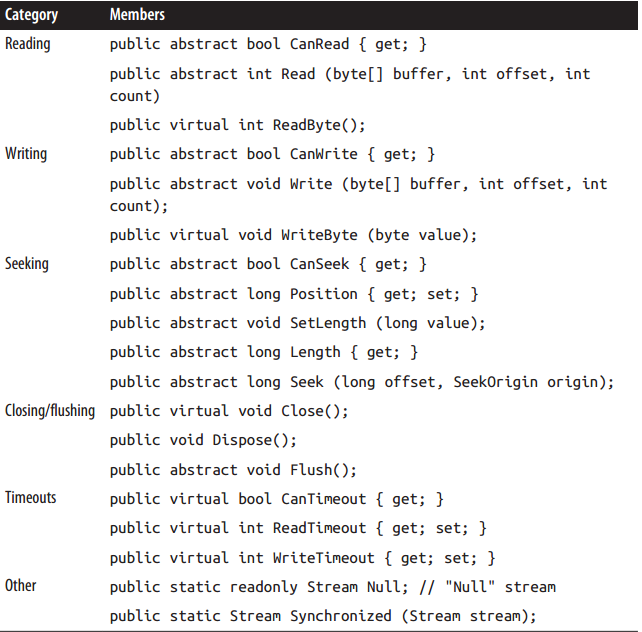
這些方法都有非同步的版本, 加async, 返回Task即可.
一個例子:

using System;
using System.IO;
namespace Test
{
class Program
{
static void Main(string[] args)
{
// 在當前目錄創建按一個 test.txt 文件
using (Stream s = new FileStream("test.txt", FileMode.Create))
{
Console.WriteLine(s.CanRead); // True
Console.WriteLine(s.CanWrite); // True
Console.WriteLine(s.CanSeek); // True
s.WriteByte(101);
s.WriteByte(102);
byte[] block = { 1, 2, 3, 4, 5 };
s.Write(block, 0, block.Length); // 寫 5 位元組
Console.WriteLine(s.Length); // 7
Console.WriteLine(s.Position); // 7
s.Position = 0; // 回到開頭位置
Console.WriteLine(s.ReadByte()); // 101
Console.WriteLine(s.ReadByte()); // 102
// 從block數組開始的地方開始read:
Console.WriteLine(s.Read(block, 0, block.Length)); // 5
// 假設最後一次read返回 5, 那就是在文件結尾, 所以read會返回0:
Console.WriteLine(s.Read(block, 0, block.Length)); // 0
}
}
}
}
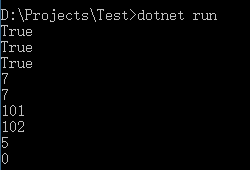
運行結果:
非同步例子:
using System;
using System.IO;
using System.Threading.Tasks;
namespace Test
{
class Program
{
static void Main(string[] args)
{
Task.Run(AsyncDemo).GetAwaiter().GetResult();
}
async static Task AsyncDemo()
{
using (Stream s = new FileStream("test.txt", FileMode.Create))
{
byte[] block = { 1, 2, 3, 4, 5 };
await s.WriteAsync(block, 0, block.Length);
s.Position = 0;
Console.WriteLine(await s.ReadAsync(block, 0, block.Length));
}
}
}
}

非同步版本比較適合慢的stream, 例如網路的stream.
讀和寫
CanRead和CanWrite屬性可以判斷Stream是否可以讀寫.
Read方法把stream的一塊數據寫入到數組, 返回接受到的位元組數, 它總是小於等於count這個參數. 如果它小於count, 就說明要麼是已經讀取到stream的結尾了, 要麼stream給的數據塊太小了(網路stream經常這樣).
一個讀取1000位元組stream的例子:
// 假設s是某個stream
byte[] data = new byte[1000];
// bytesRead 的結束位置肯定是1000, 除非stream的長度不足1000
int bytesRead = 0;
int chunkSize = 1;
while (bytesRead < data.Length && chunkSize > 0)
bytesRead +=
chunkSize = s.Read(data, bytesRead, data.Length - bytesRead);
ReadByte方法更簡單一些, 一次就讀一個位元組, 如果返回-1表示讀取到stream的結尾了. 返回類型是int.
Write和WriteByte就是相應的寫入方法了. 如果無法寫入某個位元組, 那就會拋出異常.
上面方法簽名里的offset參數, 表示的是緩衝數組開始讀取或寫入的位置, 而不是指stream裡面的位置.
定址 Seek
CanSeek為true的話, Stream就可以被定址. 可以查詢和修改可定址的stream(例如文件stream)的長度, 也可以隨時修改讀取和寫入的位置.
Position屬性就是所需要的, 它是相對於stream開始位置的.
Seek方法就允許你移動到當前位置或者stream的尾部.
註意改變FileStream的Position會花去幾微秒. 如果是在大規模迴圈裡面做這個操作的話, 建議使用MemoryMappedFile類.
對於不可定址的Stream(例如加密Stream), 想知道它的長度只能是把它讀完. 而且你要是想讀取前一部分的話必須關閉stream, 然後再開始一個全新的stream才可以.
關閉和Flush
Stream用完之後必須被處理掉(dispose)來釋放底層資源例如文件和socket處理. 通常使用using來實現.
- Dispose和Close方法功能上是一樣的.
- 重覆close和flush一個stream不會報錯.
關閉裝飾器stream的時候會同時關閉裝飾器和它的backing store stream.
針對一連串的裝飾器裝飾的stream, 關閉最外層的裝飾器就會關閉所有.
有些stream從backing store讀取/寫入的時候有一個緩存機制, 這就減少了實際到backing store的往返次數以達到提高性能的目的(例如FileStream).
這就意味著你寫入數據到stream的時候可能不會立即寫入到backing store; 它會有延遲, 直到緩衝被填滿.
Flush方法會強制內部緩衝的數據被立即的寫入. Flush會在stream關閉的時候自動被調用. 所以你不需要這樣寫: s.Flush(); s.Close();
超時
如果CanTimeout屬性為true的話, 那麼該stream就可以設定讀或寫的超時.
網路stream支持超時, 而文件和記憶體stream則不支持.
支持超時的stream, 通過ReadTimeout和WriteTimeout屬性可以設定超時, 單位毫秒. 0表示無超時.
Read和Write方法通過拋出異常的方式來表示超時已經發生了.
線程安全
stream並不是線程安全的, 也就是說兩個線程同時讀或寫一個stream的時候就會報錯.
Stream通過Synchronized方法來解決這個問題. 該方法接受stream為參數, 返回一個線程安全的包裝結果.
這個包裝結果在每次讀, 寫, 定址的時候會獲得一個獨立鎖/排他鎖, 所以同一時刻只有一個線程可以執行操作.
實際上, 這允許多個線程同時為同一個數據追加數據, 而其他類型的操作(例如同讀)則需要額外的鎖來保證每個線程可以訪問到stream相應的部分.
Backing Store Stream
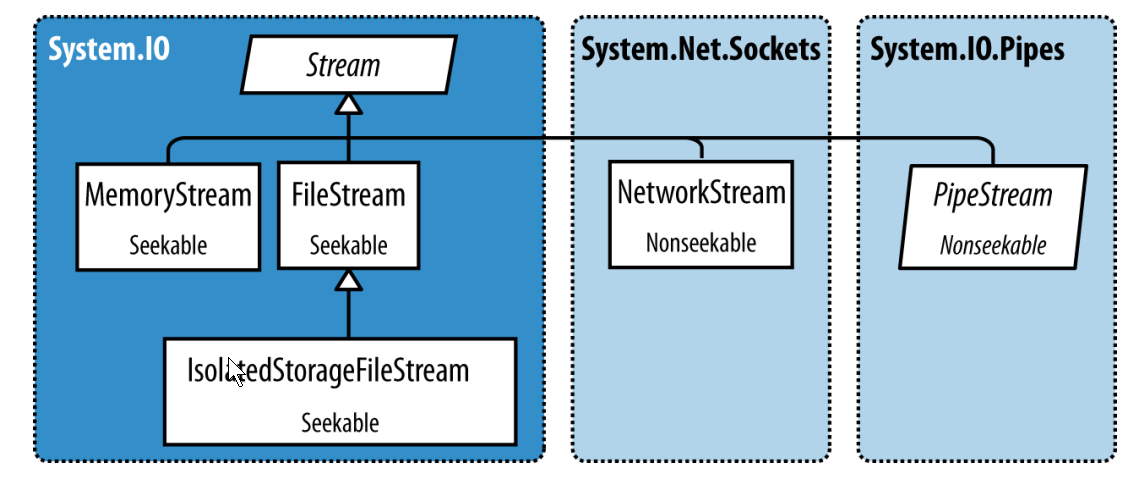
FileStream
文件流
構建一個FileStream:
FileStream fs1 = File.OpenRead("readme.bin"); // Read-only
FileStream fs2 = File.OpenWrite(@"c:\temp\writeme.tmp"); // Write-only
FileStream fs3 = File.Create(@"c:\temp\writeme.tmp"); // Read/write
OpenWrite和Create對於已經存在的文件來說, 它的行為是不同的.
Create會把現有文件的內容清理掉, 寫入的時候從頭開寫.
OpenWrite則是完整的保存著現有的內容, 而stream的位置定位在0. 如果寫入的內容比原來的內容少, 那麼OpenWrite打開並寫完之後的內容是原內容和新寫入內容的混合體.
直接構建FileStream:
var fs = new FileStream ("readwrite.tmp", FileMode.Open); // Read/write
其構造函數裡面還可以傳入其他參數, 具體請看文檔.
File類的快捷方法:
下麵這些靜態方法會一次性把整個文件讀進記憶體:
- File.ReadAllText(返回string)
- File.ReadAllLines(返回string數組)
- File.ReadAllBytes(返回byte數組)
下麵的方法直接寫入整個文件:
- File.WriteAllText
- File.WriteAllLines
- File.WriteAllBytes
- File.AppendAllText (很適合附加log文件)
還有一個靜態方法叫File.ReadLines: 它有點想ReadAllLines, 但是它返回的是一個懶載入的IEnumerable<string>. 這個實際上效率更高一些, 因為不必一次性把整個文件都載入到記憶體里. LINQ非常適合處理這個結果. 例如:
int longLines = File.ReadLines ("filePath").Count (l => l.Length > 80);
指定的文件名:
可以是絕對路徑也可以是相對路徑.
可已修改靜態屬性Environment.CurrentDirectory的值來改變當前的路徑. (註意: 預設的當前路徑不一定是exe所在的目錄)
AppDomain.CurrentDomain.BaseDirectory會返回應用的基目錄, 它通常是包含exe的目錄.
指定相對於這個目錄的地址最好使用Path.Combine方法:
string baseFolder = AppDomain.CurrentDomain.BaseDirectory;
string logoPath = Path.Combine(baseFolder, "logo.jpg");
Console.WriteLine(File.Exists(logoPath));
通過網路對文件讀寫要使用UNC路徑:
例如: \\JoesPC\PicShare \pic.jpg 或者 \\10.1.1.2\PicShare\pic.jpg.
FileMode:
所有的FileStream的構造器都會接收一個文件名和一個FileMode枚舉作為參數. 如果選擇FileMode請看下圖:
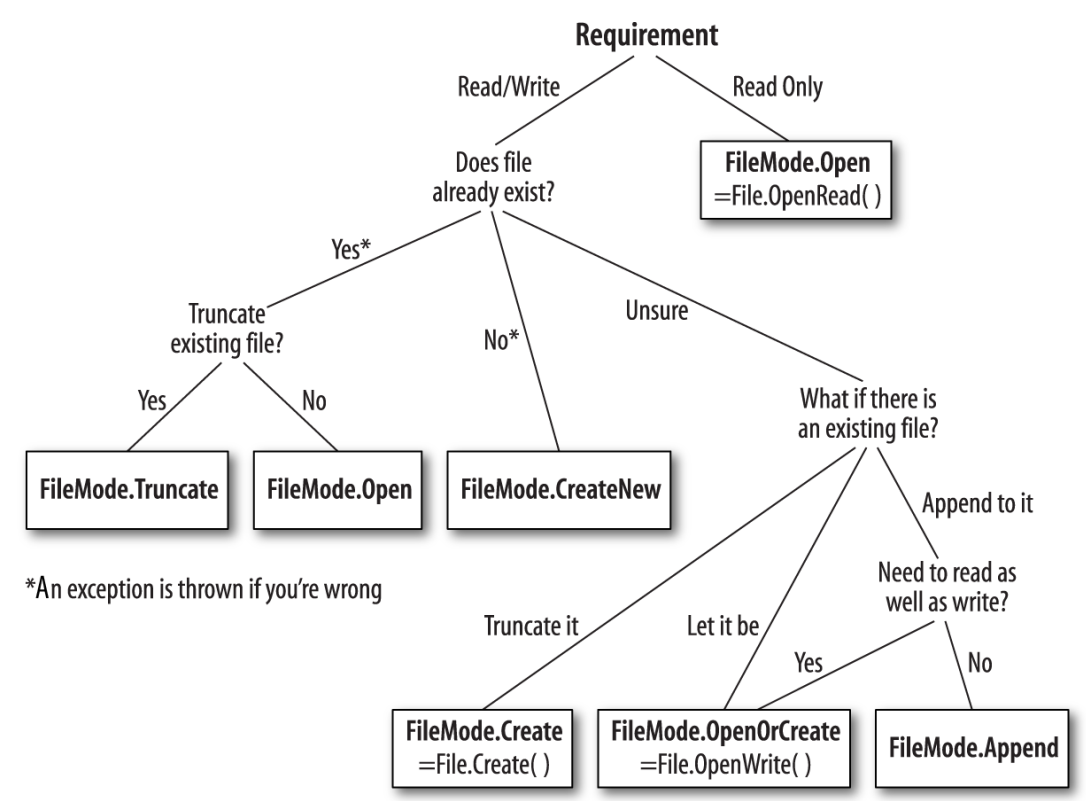
其他特性還是需要看文檔.
MemoryStream
MemoryStream在隨機訪問不可定址的stream時就有用了.
如果你知道源stream的大小可以接受, 你就可以直接把它複製到MemoryStream里:
var ms = new MemoryStream();
sourceStream.CopyTo(ms);
可以通過ToArray方法把MemoryStream轉化成數組.
GetBuffer方法也是同樣的功能, 但是因為它是直接把底層的存儲數組的引用直接返回了, 所以會更有效率. 不過不幸的是, 這個數組通常比stream的真實長度要長.
註意: Close和Flush 一個MemoryStream是可選的. 如果關閉了MemoryStream, 你就再也不能對它讀寫了, 但是仍然可以調用ToArray方法來獲取其底層的數據.
Flush則對MemoryStream毫無用處.
PipeStream
PipeStream通過Windows Pipe 協議, 允許一個進程(process)和另一個進程通信.
分兩種:
- 匿名進程(快一點), 允許同一個電腦內的父子進程單向通信.
- 命名進程(更靈活), 允許同一個電腦內或者同一個windows網路內的不同電腦間的任意兩個進程間進行雙向通信
pipe很適合一個電腦上的進程間交互(IPC), 它並不依賴於網路傳輸, 這也意味著沒有網路開銷, 也不在乎防火牆.
註意: pipe是基於Stream的, 一個進程等待接受一串字元的同時另一個進程發送它們.
PipeStream是抽象類.
具體的實現類有4個:
匿名pipe:
- AnonymousePipeServerStream
- AnonymousePipeClientStream
命名Pipe:
- NamedPipeServerStream
- NamePipeClientStream
命名Pipe
命名pipe的雙方通過同名的pipe進行通信. 協議規定了兩個角色: 伺服器和客戶端. 按照下述方式進行通信:
- 伺服器實例化一個NamedPipeServerStream然後調用WaitForConnection方法.
- 客戶端實例化一個NamedPipeClientStream然後調用Connect方法(可以設定超時).
然後雙方就可以讀寫stream來進行通信了.
例子:
using System;
using System.IO;
using System.IO.Pipes;
using System.Threading.Tasks;
namespace Test
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine(DateTime.Now.ToString());
using (var s = new NamedPipeServerStream("pipedream"))
{
s.WaitForConnection();
s.WriteByte(100); // Send the value 100.
Console.WriteLine(s.ReadByte());
}
Console.WriteLine(DateTime.Now.ToString());
}
}
}
using System;
using System.IO.Pipes;
namespace Test2
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine(DateTime.Now.ToString());
using (var s = new NamedPipeClientStream("pipedream"))
{
s.Connect();
Console.WriteLine(s.ReadByte());
s.WriteByte(200); // Send the value 200 back.
}
Console.WriteLine(DateTime.Now.ToString());
}
}
}

命名的PipeStream預設情況下是雙向的, 所以任意一方都可以進行讀寫操作, 這也意味著伺服器和客戶端必須達成某種協議來協調它們的操作, 避免同時進行發送和接收.
還需要協定好每次傳輸的長度.
在處理長度大於一位元組的信息的時候, pipe提供了一個信息傳輸的模式, 如果這個啟用了, 一方在調用read的時候可以通過檢查IsMessageComplete屬性來知道消息什麼時候結束.
例子:
static byte[] ReadMessage(PipeStream s)
{
MemoryStream ms = new MemoryStream();
byte[] buffer = new byte[0x1000]; // Read in 4 KB blocks
do { ms.Write(buffer, 0, s.Read(buffer, 0, buffer.Length)); }
while (!s.IsMessageComplete); return ms.ToArray();
}
註意: 針對PipeStream不可以通過Read返回值是0的方式來它是否已經完成讀取消息了. 這是因為它和其他的Stream不同, pipe stream和network stream沒有確定的終點. 在兩個信息傳送動作之間, 它們就乾等著.
這樣啟用信息傳輸模式, 伺服器端 :
using (var s = new NamedPipeServerStream("pipedream", PipeDirection.InOut, 1, PipeTransmissionMode.Message))
{
s.WaitForConnection();
byte[] msg = Encoding.UTF8.GetBytes("Hello");
s.Write(msg, 0, msg.Length);
Console.WriteLine(Encoding.UTF8.GetString(ReadMessage(s)));
}
客戶端:
using (var s = new NamedPipeClientStream("pipedream"))
{
s.Connect();
s.ReadMode = PipeTransmissionMode.Message;
Console.WriteLine(Encoding.UTF8.GetString(ReadMessage(s)));
byte[] msg = Encoding.UTF8.GetBytes("Hello right back!");
s.Write(msg, 0, msg.Length);
}
匿名pipe:
匿名pipe提供父子進程間的單向通信. 流程如下:
- 伺服器實例化一個AnonymousPipeServerStream, 並指定PipeDirection是In還是Out
- 伺服器調用GetClientHandleAsString方法來獲取一個pipe的標識, 然後會把它傳遞給客戶端(通常是啟動子進程的參數 argument)
- 子進程實例化一個AnonymousePipeClientStream, 指定相反的PipeDirection
- 伺服器通過調用DisposeLocalCopyOfClientHandle釋放步驟2的本地處理,
- 父子進程間通過讀寫stream進行通信
因為匿名pipe是單向的, 所以伺服器必須創建兩份pipe來進行雙向通信
例子:
server:
using System;
using System.Diagnostics;
using System.IO;
using System.IO.Pipes;
using System.Text;
using System.Threading.Tasks;
namespace Test
{
class Program
{
static void Main(string[] args)
{
string clientExe = @"D:\Projects\Test2\bin\Debug\netcoreapp2.0\win10-x64\publish\Test2.exe";
HandleInheritability inherit = HandleInheritability.Inheritable;
using (var tx = new AnonymousPipeServerStream(PipeDirection.Out, inherit))
using (var rx = new AnonymousPipeServerStream(PipeDirection.In, inherit))
{
string txID = tx.GetClientHandleAsString();
string rxID = rx.GetClientHandleAsString();
var startInfo = new ProcessStartInfo(clientExe, txID + " " + rxID);
startInfo.UseShellExecute = false; // Required for child process
Process p = Process.Start(startInfo);
tx.DisposeLocalCopyOfClientHandle(); // Release unmanaged
rx.DisposeLocalCopyOfClientHandle(); // handle resources.
tx.WriteByte(100);
Console.WriteLine("Server received: " + rx.ReadByte());
p.WaitForExit();
}
}
}
}
client:
using System;
using System.IO.Pipes;
namespace Test2
{
class Program
{
static void Main(string[] args)
{
string rxID = args[0]; // Note we're reversing the
string txID = args[1]; // receive and transmit roles.
using (var rx = new AnonymousPipeClientStream(PipeDirection.In, rxID))
using (var tx = new AnonymousPipeClientStream(PipeDirection.Out, txID))
{
Console.WriteLine("Client received: " + rx.ReadByte());
tx.WriteByte(200);
}
}
}
}
最好發佈一下client成為獨立運行的exe:
dotnet publish --self-contained --runtime win10-x64
運行結果:
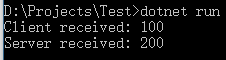
匿名pipe不支持消息模式, 所以你必須自己來為傳輸的長度制定協議. 有一種做法是: 在每次傳輸的前4個位元組里存放一個整數表示消息的長度, 可以使用BitConverter類來對整型和長度為4的位元組數組進行轉換.
BufferedStream
BufferedStream對另一個stream進行裝飾或者說包裝, 讓它擁有緩衝的能力.它也是眾多裝飾stream類型中的一個.
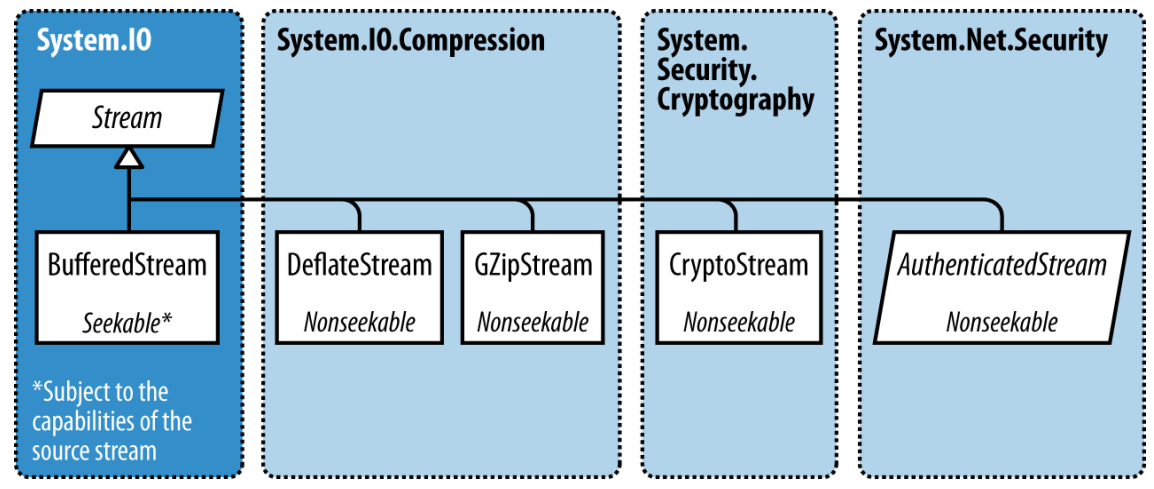
緩衝肯定會通過減少往返backing store的次數來提升性能.
下麵這個例子是把一個FileStream裝飾成20k的緩衝stream:
// Write 100K to a file:
File.WriteAllBytes("myFile.bin", new byte[100000]);
using (FileStream fs = File.OpenRead("myFile.bin"))
using (BufferedStream bs = new BufferedStream(fs, 20000)) //20K buffer
{
bs.ReadByte();
Console.WriteLine(fs.Position); // 20000
}
}
通過預讀緩衝, 底層的stream會在讀取1位元組後, 直接預讀了20000位元組, 這樣我們在另外調用ReadByte 19999次之後, 才會再次訪問到FileStream.
這個例子是把BufferedStream和FileStream耦合到一起, 實際上這個例子裡面的緩衝作用有限, 因為FileStream有一個內置的緩衝. 這個例子也只能擴大一下緩衝而已.
關閉BufferedStream就會關閉底層的backing store stream..
Stream適配器
Stream只按位元組處理, 對string, 整型, xml等都是通過位元組進行讀寫的, 所以必須插入一個適配器.
.NET Core提供了這些文字適配器:
- TextReader, TextWriter
- StreamReader, StreamWriter
- StringReader, StringWriter
二進位適配器(適用於原始類型例如int bool string float等):
- BinaryReader, BinaryWriter
XML適配器:
- XmlReader, XmlWiter
這些適配器的關係圖:

文字適配器
TextReader 和 TextWriter是文字適配器的基類. 它倆分別對應兩套實現:
- StreamReader/StreamWriter: 使用Stream作為原始數據存儲, 把stream的位元組轉化成字元或字元串
- StringReader/StringWriter: 使用的是記憶體中的字元串
TextReader:

Peek方法會返回下一個字元而不改變當前(可以看作是索引)的位置.
在Stream讀取到結束點的時候Peek和無參數的Read方法都會返回-1, 否則它們會返回一個可以被轉換成字元的整型.
Read的重載方法(接受char[]緩衝參數)在功能上和ReadBlock方法是一樣的.
ReadLine方法會一直讀取直到遇到了CR或LF或CR+LF對(以後再介紹), 然後會放回字元串, 但是不包含CR/LF等字元.
註意: C#應該使用"\r\n"來還行, 順序寫反了可能會不換行患者換兩行.
TextWriter:

方法與TextReader類似.
Write和WriteLine有幾個重載方法可以接受所有的原始類型, 還有object類型. 這些方法會調用被傳入參數的ToString方法. 另外也可以在構造函數或者調用方法的時候通過IFormatProvider進行指定.
WriteLine會在給定的文字後邊加上CR+LF, 您可以通過修改NewLine屬性來改變這個行為(尤其是與UNIX文件格式交互的時候).
上面講的這些方法, 都有非同步版本的
StreamReader和StreamWriter
直接看例子即可:
using (FileStream fs = File.Create("test.txt")) using (TextWriter writer = new StreamWriter(fs)) { writer.WriteLine("Line 1"); writer.WriteLine("Line 2"); } using (FileStream fs = File.OpenRead("test.txt")) using (TextReader reader = new StreamReader(fs)) { Console.WriteLine(reader.ReadLine()); Console.WriteLine(reader.ReadLine()); }

由於文字適配器經常要處理文件, 所以File類提供了一些靜態方法例如: CreateText, AppendText, OpenText來做快捷操作:
上面的例子可以寫成:
using (TextWriter writer = File.CreateText("test.txt")) { writer.WriteLine("Line1"); writer.WriteLine("Line2"); } using (TextWriter writer = File.AppendText("test.txt")) writer.WriteLine("Line3"); using (TextReader reader = File.OpenText("test.txt")) while (reader.Peek() > -1) Console.WriteLine(reader.ReadLine());
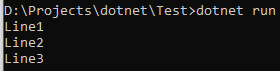
代碼中可以看到, 如何知道是否讀取到了文件的結尾(通過reader.Peek()). 另一個方法是使用reader.ReadLine方法讀取直到返回null.
也可以讀取其他的類型, 例如int(因為TextWriter會調用ToString方法), 但是讀取的時候想要變成原來的類型就得進行解析字元串操作了.
字元串編碼
TextReader和TextWriter是抽象類, 跟sream或者backing store沒有連接. StreamReader和StreamWriter則連接著一個底層的位元組流, 所以它們必須對字元串和位元組進行轉換. 它們通過System.Text.Encoding類來做這些工作, 也就是構建StreamReader或StreamWriter的時候選擇一個Encoding. 如果你沒選那麼就是UTF-8了.
註意: 如果你明確指定了一個編碼, 那麼StreamWriter預設會在流的前邊加一個首碼, 這個首碼是用來識別編碼的. 如果你不想這樣做的話, 那麼可以這樣做:
var encoding = new UTF8Encoding( encoderShouldEmitUTF8Identifier: false, throwOnInvalidBytes: true );
第二個參數是告訴StreamWriter, 如果遇到了本編碼下的非法字元串, 那就拋出一個異常. 如果不指定編碼的情況下, 也是這樣的.
最簡單的編碼是ASCII, 每一個字元通過一個位元組來表示. ASCII對Unicode的前127個字元進行了映射, 包含了US鍵盤上面所有的鍵. 而其他的字元, 例如特殊字元和非英語字元等無法被表達的字元則會顯示成□. 預設的UTF-8編碼影射了所有的Unicode字元, 但是它更複雜. 前127個位元組使用單位元組, 這是為了和ASCII相容; 而剩下的位元組編碼成了不定長的位元組數(通常是2或者3位元組).
UTF-8處理西方語言的文字還不錯, 但是在stream裡面搜索/定址就會遇到麻煩了, 這時可以使用UTF-16這個候選(Encoding類裡面叫Unicode).
UTF-16針對每個字元使用2個或4個位元組, 但是由於C#的char類型是16bit的, 所以針對.NET的char, UTF-16正好使用兩個位元組. 這樣在stream裡面找到特定字元的索引就方便多了.
UTF-16會使用一個2位元組長的首碼, 來識別位元組對是按little-endian還是big-endian的順序存儲的. windows系統預設使用little-endian.
StringReader和StringWriter
這兩個適配器根本不包裝stream; 它們使用String或StringBuilder作為數據源, 所以不需要位元組轉換.
實際上這兩個類存在的主要優勢就是: 它們和StreamReader/StreamWriter具有同一個父類.
例如有一個含有xml的字元串, 我想把它用XmlReader進行解析, XmlReader.Create方法可以接受下列參數:
- URI
- Stream
- TextReader
因為StringReader是TextReader的子類, 所以我就可以這樣做:
XmlReader reader = XmlReader.Create(new StringReader("...xml string..."));
二進位適配器
BinaryReader和BinaryWriter可以讀取/寫入下列類型: bool, byte, char, decimal, float, double, short, int, long, sbyte, ushort, uint, ulong 以及string和由原始類型組成的數組.
和StreamReader/StreamWriter不同的是, 二進位適配器對原始數據類型的存儲效率是非常高的, 因為都是在記憶體里.
int使用4個位元組, double 8個位元組......
string則是通過文字編碼(就像StreamReader和StreamWriter), 但是長度是固定的, 以便可以對string回讀, 而不需要使用分隔符.
舉個例子:
public class Person { public string Name; public int Age; public double Height; public void SaveData(Stream s) { var w = new BinaryWriter(s); w.Write(Name); w.Write(Age); w.Write(Height); w.Flush(); } public void LoadData(Stream s) { var r = new BinaryReader(s); Name = r.ReadString(); Age = r.ReadInt32(); Height = r.ReadDouble(); } }
這個例子里, Person類使用SaveData和LoadData兩個方法把它的數據寫入到Stream/從Stream讀取出來, 裡面用的是二進位適配器.
由於BinaryReader可以讀取到位元組數組, 所以可以把要讀取的內容轉化成可定址的stream:
byte[] data = new BinaryReader(s).ReadBytes((int)sbyte.Length);
關閉和清理Stream適配器
有四種做法可以把stream適配器清理掉:
- 只關閉適配器
- 關閉適配器, 然後關閉stream
- (對於Writers), Flush適配器, 然後關閉Stream.
- (對於Readers), 關閉Stream.
註意: Close和Dispose對於適配器來說功能是一樣的, 這點對Stream也一樣.
上面的前兩種寫法實際上是一樣的, 因為關閉適配器的話會自動關閉底層的Stream. 當嵌套使用using的時候, 就是隱式的使用方法2:
using (FileStream fs = File.Create("test.txt")) using (TextWriter writer = new StreamWriter(fs)) { writer.WriteLine("Line"); }
這是因為嵌套的dispose是從內而外的, 適配器先關閉, 然後是Stream. 此外, 如果在適配器的構造函數里發生異常了, 這個Stream仍然會關閉, 嵌套使用using是很難出錯的.
註意: 不要在關閉或flush stream的適配器writer之前去關閉stream, 那會截斷在適配器緩衝的數據.
第3, 4中方法之所以可行, 是因為適配器是比較另類的, 它們是可選disposable的對象. 看下麵的例子:
using (FileStream fs = new FileStream("test.txt", FileMode.Create)) { StreamWriter writer = new StreamWriter(fs); writer.WriteLine("Hello"); writer.Flush(); fs.Position = 0; Console.WriteLine(fs.ReadByte()); }
這裡, 我對一個文件進行了寫入動作, 然後重定位stream, 讀取第一個位元組. 我想把Stream開著, 因為以後還要用到.
這時, 如果我dispose了StreamWriter, 那麼FileStream就被關閉了, 以後就無法操作它了. 所以沒有調用writer的dispose或close方法.
但是這裡需要flush一下, 以確保StreamWriter的緩存的內容都寫入到了底層的stream里.
註意: 鑒於適配器的dispose是可選的, 所以不再使用的適配器就可以躲開GC的清理操作.
.net 4.5以後, StreamReader/StreamWriter有了一個新的構造函數, 它可以接受一個參數, 來指定在dispose之後是否讓Stream保持開放:
using (var fs = new FileStream("test.txt", FileMode.Create)) { using (var writer = new StreamWriter(fs, new UTF8Encoding(false, true), 0x400, true)) writer.WriteLine("Hello"); fs.Position = 0; Console.WriteLine(fs.ReadByte()); Console.WriteLine(fs.Length); }
壓縮Stream
在System.IO.Compression下有兩個壓縮Stream: DeflateStream和GZipStream. 它們都使用了一個類似於ZIP格式的壓縮演算法. 不同的是GZipStream會在開頭和結尾寫入額外的協議--包括CRC錯誤校驗.GZipStream也符合其他軟體的標準.
這兩種Stream在讀寫的時候有這兩個條件:
- 寫入Stream的時候是壓縮
- 讀取Stream的時候是解壓縮
DeflateStream和GZipStream都是裝飾器(參考裝飾設計模式); 它們會壓縮/解壓縮從構造函數傳遞進來的Stream. 例如:
using (Stream s = File.Create("compressed.bin")) using (Stream ds = new DeflateStream(s, CompressionMode.Compress)) for (byte i = 0; i < 100; i++) ds.WriteByte(i); using (Stream s = File.OpenRead("compressed.bin")) using (Stream ds = new DeflateStream(s, CompressionMode.Decompress)) for (byte i = 0; i < 100; i++) Console.WriteLine(ds.ReadByte()); // Writes 0 to 99
上面這個例子里, 即使是壓縮的比較小的, 文件在壓縮後也有241位元組長, 比原來的兩倍還多....這是因為, 壓縮演算法對於這種"稠密"的非重覆的二進位數據處理的很不好(加密的數據更完), 但是它對文本類的文件還是處理的很好的.
Task.Run(async () => { string[] words = "The quick brown fox jumps over the lazy dog".Split(); Random rand = new Random(); using (Stream s = File.Create("compressed.bin")) using (Stream ds = new DeflateStream(s, CompressionMode.Compress)) using (TextWriter w = new StreamWriter(ds)) for (int i = 0; i < 1000; i++) await w.WriteAsync(words[rand.Next(words.Length)] + " "); Console.WriteLine(new FileInfo("compressed.bin").Length); using (Stream s = File.OpenRead("compressed.bin")) using (Stream ds = new DeflateStream(s, CompressionMode.Decompress)) using (TextReader r = new StreamReader(ds)) Console.Write(await r.ReadToEndAsync()); }).GetAwaiter().GetResult();

壓縮後的長度是856!
在記憶體中壓縮
有時候需要把整個壓縮都放在記憶體里, 這就要用到MemoryStream:
byte[] data = new byte[1000]; // 對於空數組, 我們可以期待一個很好的壓縮比率! var ms = new MemoryStream(); using (Stream ds = new DeflateStream(ms, CompressionMode.Compress)) ds.Write(data, 0, data.Length); byte[] compressed = ms.ToArray(); Console.WriteLine(compressed.Length); // 14 // 解壓回數組: ms = new MemoryStream(compressed); using (Stream ds = new DeflateStream(ms, CompressionMode.Decompress)) for (int i = 0; i < 1000; i += ds.Read(data, i, 1000 - i)) ;

這裡第一個using走完的時候MemoryStream會被關閉, 所以只能使用ToArray方法來提取它的數據.
下麵是另外一種非同步的做法, 可以避免關閉MemoryStream:
Task.Run(async () => { byte[] data = new byte[1000]; MemoryStream ms = new MemoryStream(); using (Stream ds = new DeflateStream(ms, CompressionMode.Compress, true)) await ds.WriteAsync(data, 0, data.Length); Console.WriteLine(ms.Length); ms.Position = 0; using (Stream ds = new DeflateStream(ms, CompressionMode.Decompress)) for (int i = 0; i < 1000; i += await ds.ReadAsync(data, i, 1000 - i)) ; }).GetAwaiter().GetResult();
註意DeflateStream的最後一個參數.
ZIP文件操作
.NET 4.5之後, 通過新引入的ZpiArchive和ZipFile類(System.IO.Compression下, Assembly是System.IO.Compression.FileSytem.dll), 我們就可以直接操作zip文件了.
zip格式相對於DelfateStream和GZipStream的優勢是, 它可以作為多個文件的容器.
ZipArchive配合Stream進行工作, 而ZipFile則是更多的和文件打交道.(ZipFile是ZipArchive的一個Helper類).
ZipFIle的CreateFromDirectory方法會把指定目錄下的所有文件打包成zip文件:
ZipFile.CreateFromDirectory (@"d:\MyFolder", @"d:\compressed.zip");
而ExtractToDirectory則是做相反的工作:
ZipFile.ExtractToDirectory (@"d:\compressed.zip", @"d:\MyFolder");
壓縮的時候, 可以指定是否對文件的大小, 壓縮速度進行優化, 也可以指定壓縮後是否包含源目錄.
ZipFile的Open方法可以用來讀寫單獨的條目, 它會返回一個ZipArchive對象(你也可以通過使用Stream對象初始化ZipArchive對象得到). 調用Open方法的時候, 你可以指定文件名和指定想要進行的動作: 讀, 寫, 更新. 你可以通過Entries屬性遍歷所有的條目, 想找到特定的條目可以使用GetEntry方法:
using (ZipArchive zip = ZipFile.Open (@"d:\zz.zip", ZipArchiveMode.Read)) foreach (ZipArchiveEntry entry in zip.Entries) Console.WriteLine (entry.FullName + " " + entry.Length);
ZipArchiveEntry還有一個Delete方法和一個ExtractToFile(這個其實是ZipFIleExtensions裡面的extension方法)方法, 還有個Open方法返回可讀寫的Stream. 你可以通過調用CreateEntry方法(或者CreateEntryFromFile這個extension方法)在ZipArchive上創建新的條目.
例子:
byte[] data = File.ReadAllBytes (@"d:\foo.dll"); using (ZipArchive zip = ZipFile.Open (@"d:\zz.zip", ZipArchiveMode.Update)) zip.CreateEntry (@"bin\X64\foo.dll").Open().Write (data, 0, data.Length);
上面例子里的操作完全可以在記憶體中實現, 使用MemoryStream即可.


