一提到關係型資料庫,我禁不住想:有些東西被忽視了。關係型資料庫無處不在,而且種類繁多,從小巧實用的 SQLite 到強大的 Teradata 。但很少有文章講解資料庫是如何工作的。你可以自己谷歌/百度一下『關係型資料庫原理』,看看結果多麼的稀少【譯者註:百度為您找到相關結果約1,850,000個…】 ...
一提到關係型資料庫,我禁不住想:有些東西被忽視了。關係型資料庫無處不在,而且種類繁多,從小巧實用的 SQLite 到強大的 Teradata 。但很少有文章講解資料庫是如何工作的。你可以自己谷歌/百度一下『關係型資料庫原理』,看看結果多麼的稀少【譯者註:百度為您找到相關結果約1,850,000個…】 ,而且找到的那些文章都很短。現在如果你查找最近時髦的技術(大數據、NoSQL或JavaScript),你能找到更多深入探討它們如何工作的文章。
難道關係型資料庫已經太古老太無趣,除了大學教材、研究文獻和書籍以外,沒人願意講了嗎?

作為一個開發人員,我不喜歡用我不明白的東西。而且,資料庫已經使用了40年之久,一定有理由的。多年以來,我花了成百上千個小時來真正領會這些我每天都在用的、古怪的黑盒子。關係型資料庫非常有趣,因為它們是基於實用而且可復用的概念。如果你對瞭解一個資料庫感興趣,但是從未有時間或意願來刻苦鑽研這個內容廣泛的課題,你應該喜歡這篇文章。
雖然本文標題很明確,但我的目的並不是講如何使用資料庫。因此,你應該已經掌握怎麼寫一個簡單的 join query(聯接查詢)和CRUD操作(創建讀取更新刪除),否則你可能無法理解本文。這是唯一需要你瞭解的,其他的由我來講解。
我會從一些電腦科學方面的知識談起,比如時間複雜度。我知道有些人討厭這個概念,但是沒有它你就不能理解資料庫內部的巧妙之處。由於這是個很大的話題,我將集中探討我認為必要的內容:資料庫處理SQL查詢的方式。我僅僅介紹資料庫背後的基本概念,以便在讀完本文後你會對底層到底發生了什麼有個很好的瞭解。
【譯者註:關於時間複雜度。電腦科學中,演算法的時間複雜度是一個函數,它定量描述了該演算法的運行時間。如果不瞭解這個概念建議先看看維基或百度百科,對於理解文章下麵的內容很有幫助】
由於本文是個長篇技術文章,涉及到很多演算法和數據結構知識,你盡可以慢慢讀。有些概念比較難懂,你可以跳過,不影響理解整體內容。
這篇文章大約分為3個部分:
- 底層和上層資料庫組件概況
- 查詢優化過程概況
- 事務和緩衝池管理概況
回到基礎
很久很久以前(在一個遙遠而又遙遠的星系……),開發者必須確切地知道他們的代碼需要多少次運算。他們把演算法和數據結構牢記於心,因為他們的電腦運行緩慢,無法承受對CPU和記憶體的浪費。
在這一部分,我將提醒大家一些這類的概念,因為它們對理解資料庫至關重要。我還會介紹資料庫索引的概念。
O(1) vs O(n^2)
現今很多開發者不關心時間複雜度……他們是對的。
但是當你應對大量的數據(我說的可不只是成千上萬哈)或者你要爭取毫秒級操作,那麼理解這個概念就很關鍵了。而且你猜怎麼著,資料庫要同時處理這兩種情景!我不會占用你太長時間,只要你能明白這一點就夠了。這個概念在下文會幫助我們理解什麼是基於成本的優化。
概念
時間複雜度用來檢驗某個演算法處理一定量的數據要花多長時間。為了描述這個複雜度,電腦科學家使用數學上的『簡明解釋演算法中的大O符號』。這個表示法用一個函數來描述演算法處理給定的數據需要多少次運算。
比如,當我說『這個演算法是適用 O(某函數())』,我的意思是對於某些數據,這個演算法需要 某函數(數據量) 次運算來完成。
重要的不是數據量,而是當數據量增加時運算如何增加。時間複雜度不會給出確切的運算次數,但是給出的是一種理念。

圖中可以看到不同類型的複雜度的演變過程,我用了對數尺來建這個圖。具體點兒說,數據量以很快的速度從1條增長到10億條。我們可得到如下結論:
- 綠:O(1)或者叫常數階複雜度,保持為常數(要不人家就不會叫常數階複雜度了)。
- 紅:O(log(n))對數階複雜度,即使在十億級數據量時也很低。
- 粉:最糟糕的複雜度是 O(n^2),平方階複雜度,運算數快速膨脹。
- 黑和藍:另外兩種複雜度(的運算數也是)快速增長。
例子
數據量低時,O(1) 和 O(n^2)的區別可以忽略不計。比如,你有個演算法要處理2000條元素。
- O(1) 演算法會消耗 1 次運算
- O(log(n)) 演算法會消耗 7 次運算
- O(n) 演算法會消耗 2000 次運算
- O(n*log(n)) 演算法會消耗 14,000 次運算
- O(n^2) 演算法會消耗 4,000,000 次運算
O(1) 和 O(n^2) 的區別似乎很大(4百萬),但你最多損失 2 毫秒,只是一眨眼的功夫。確實,當今處理器每秒可處理上億次的運算。這就是為什麼性能和優化在很多IT項目中不是問題。
我說過,面臨海量數據的時候,瞭解這個概念依然很重要。如果這一次演算法需要處理 1,000,000 條元素(這對資料庫來說也不算大)。
- O(1) 演算法會消耗 1 次運算
- O(log(n)) 演算法會消耗 14 次運算
- O(n) 演算法會消耗 1,000,000 次運算
- O(n*log(n)) 演算法會消耗 14,000,000 次運算
- O(n^2) 演算法會消耗 1,000,000,000,000 次運算
我沒有具體算過,但我要說,用O(n^2) 演算法的話你有時間喝杯咖啡(甚至再續一杯!)。如果在數據量後面加個0,那你就可以去睡大覺了。
繼續深入
為了讓你能明白
- 搜索一個好的哈希表會得到 O(1) 複雜度
- 搜索一個均衡的樹會得到 O(log(n)) 複雜度
- 搜索一個陣列會得到 O(n) 複雜度
- 最好的排序演算法具有 O(n*log(n)) 複雜度
- 糟糕的排序演算法具有 O(n^2) 複雜度
註:在接下來的部分,我們將會研究這些演算法和數據結構。
有多種類型的時間複雜度
- 一般情況場景
- 最佳情況場景
- 最差情況場景
時間複雜度經常處於最差情況場景。
這裡我只探討時間複雜度,但複雜度還包括:
- 演算法的記憶體消耗
- 演算法的磁碟 I/O 消耗
當然還有比 n^2 更糟糕的複雜度,比如:
- n^4:差勁!我將要提到的一些演算法具備這種複雜度。
- 3^n:更差勁!本文中間部分研究的一些演算法中有一個具備這種複雜度(而且在很多資料庫中還真的使用了)。
- 階乘 n:你永遠得不到結果,即便在少量數據的情況下。
- n^n:如果你發展到這種複雜度了,那你應該問問自己IT是不是你的菜。
註:我並沒有給出『大O表示法』的真正定義,只是利用這個概念。可以看看維基百科上的這篇文章。
合併排序
當你要對一個集合排序時你怎麼做?什麼?調用 sort() 函數……好吧,算你對了……但是對於資料庫,你需要理解這個 sort() 函數的工作原理。
優秀的排序演算法有好幾個,我側重於最重要的一種:合併排序。你現在可能還不瞭解數據排序有什麼用,但看完查詢優化部分後你就會知道了。再者,合併排序有助於我們以後理解資料庫常見的聯接操作,即合併聯接 。
合併
與很多有用的演算法類似,合併排序基於這樣一個技巧:將 2 個大小為 N/2 的已排序序列合併為一個 N 元素已排序序列僅需要 N 次操作。這個方法叫做合併。
我們用個簡單的例子來看看這是什麼意思:

通過此圖你可以看到,在 2 個 4元素序列里你只需要迭代一次,就能構建最終的8元素已排序序列,因為兩個4元素序列已經排好序了:
- 1) 在兩個序列中,比較當前元素(當前=頭一次出現的第一個)
- 2) 然後取出最小的元素放進8元素序列中
- 3) 找到(兩個)序列的下一個元素,(比較後)取出最小的
- 重覆1、2、3步驟,直到其中一個序列中的最後一個元素
- 然後取出另一個序列剩餘的元素放入8元素序列中。
這個方法之所以有效,是因為兩個4元素序列都已經排好序,你不需要再『回到』序列中查找比較。
【譯者註:合併排序詳細原理,其中一個動圖(原圖較長,我做了刪減)清晰的演示了上述合併排序的過程,而原文的敘述似乎沒有這麼清晰,不動戳大。】

既然我們明白了這個技巧,下麵就是我的合併排序偽代碼。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | array mergeSort(array a) if(length(a)==1) return a[0]; end if //recursive calls [left_array right_array] := split_into_2_equally_sized_arrays(a); array new_left_array := mergeSort(left_array); array new_right_array := mergeSort(right_array); //merging the 2 small ordered arrays into a big one array result := merge(new_left_array,new_right_array); return result; |
合併排序是把問題拆分為小問題,通過解決小問題來解決最初的問題(註:這種演算法叫分治法,即『分而治之、各個擊破』)。如果你不懂,不用擔心,我第一次接觸時也不懂。如果能幫助你理解的話,我認為這個演算法是個兩步演算法:
- 拆分階段,將序列分為更小的序列
- 排序階段,把小的序列合在一起(使用合併演算法)來構成更大的序列
拆分階段

在拆分階段過程中,使用3個步驟將序列分為一元序列。步驟數量的值是 log(N) (因為 N=8, log(N)=3)。【譯者註:底數為2,下文有說明】
我怎麼知道這個的?
我是天才!一句話:數學。道理是每一步都把原序列的長度除以2,步驟數就是你能把原序列長度除以2的次數。這正好是對數的定義(在底數為2時)。
排序階段

在排序階段,你從一元序列開始。在每一個步驟中,你應用多次合併操作,成本一共是 N=8 次運算。
- 第一步,4 次合併,每次成本是 2 次運算。
- 第二步,2 次合併,每次成本是 4 次運算。
- 第三步,1 次合併,成本是 8 次運算。
因為有 log(N) 個步驟,整體成本是 N*log(N) 次運算。
【譯者註:這個完整的動圖演示了拆分和排序的全過程,不動戳大。】

合併排序的強大之處
為什麼這個演算法如此強大?
因為:
- 你可以更改演算法,以便於節省記憶體空間,方法是不創建新的序列而是直接修改輸入序列。
註:這種演算法叫『原地演算法』(in-place algorithm)
- 你可以更改演算法,以便於同時使用磁碟空間和少量記憶體而避免巨量磁碟 I/O。方法是只向記憶體中載入當前處理的部分。在僅僅100MB的記憶體緩衝區內排序一個幾個GB的表時,這是個很重要的技巧。
註:這種演算法叫『外部排序』(external sorting)。
- 你可以更改演算法,以便於在 多處理器/多線程/多伺服器 上運行。
比如,分散式合併排序是Hadoop(那個著名的大數據框架)的關鍵組件之一。
- 這個演算法可以點石成金(事實如此!)
這個排序演算法在大多數(如果不是全部的話)資料庫中使用,但是它並不是唯一演算法。如果你想多瞭解一些,你可以看看 這篇論文,探討的是資料庫中常用排序演算法的優勢和劣勢。
陣列,樹和哈希表
既然我們已經瞭解了時間複雜度和排序背後的理念,我必須要向你介紹3種數據結構了。這個很重要,因為它們是現代資料庫的支柱。我還會介紹資料庫索引的概念。
陣列
二維陣列是最簡單的數據結構。一個表可以看作是個陣列,比如:
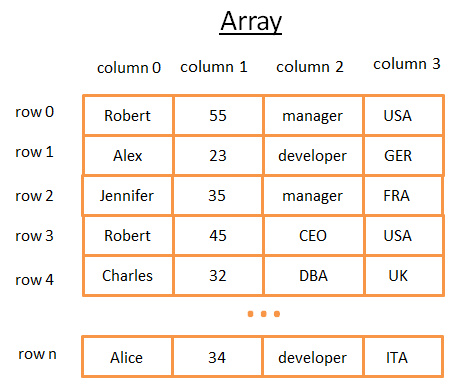
這個二維陣列是帶有行與列的表:
- 每個行代表一個主體
- 列用來描述主體的特征
- 每個列保存某一種類型對數據(整數、字元串、日期……)
雖然用這個方法保存和視覺化數據很棒,但是當你要查找特定的值它就很糟糕了。 舉個例子,如果你要找到所有在 UK 工作的人,你必須查看每一行以判斷該行是否屬於 UK 。這會造成 N 次運算的成本(N 等於行數),還不賴嘛,但是有沒有更快的方法呢?這時候樹就可以登場了(或開始起作用了)。
樹和資料庫索引
二叉查找樹是帶有特殊屬性的二叉樹,每個節點的關鍵字必須:
- 比保存在左子樹的任何鍵值都要大
- 比保存在右子樹的任何鍵值都要小
【譯者註:binary search tree,二叉查找樹/二叉搜索樹,或稱 Binary Sort Tree 二叉排序樹。見百度百科 】
概念

這個樹有 N=15 個元素。比方說我要找208:
- 我從鍵值為 136 的根開始,因為 136<208,我去找節點136的右子樹。
- 398>208,所以我去找節點398的左子樹
- 250>208,所以我去找節點250的左子樹
- 200<208,所以我去找節點200的右子樹。但是 200 沒有右子樹,值不存在(因為如果存在,它會在 200 的右子樹)
現在比方說我要找40
- 我從鍵值為136的根開始,因為 136>40,所以我去找節點136的左子樹。
- 80>40,所以我去找節點 80 的左子樹
- 40=40,節點存在。我抽取出節點內部行的ID(圖中沒有畫)再去表中查找對應的 ROW ID。
- 知道 ROW ID我就知道了數據在表中對精確位置,就可以立即獲取數據。
最後,兩次查詢的成本就是樹內部的層數。如果你仔細閱讀了合併排序的部分,你就應該明白一共有 log(N)層。所以這個查詢的成本是 log(N),不錯啊!
回到我們的問題
上文說的很抽象,我們回來看看我們的問題。這次不用傻傻的數字了,想象一下前表中代表某人的國家的字元串。假設你有個樹包含表中的列『country』:
- 如果你想知道誰在 UK 工作
- 你在樹中查找代表 UK 的節點
- 在『UK 節點』你會找到 UK 員工那些行的位置
這次搜索只需 log(N) 次運算,而如果你直接使用陣列則需要 N 次運算。你剛剛想象的就是一個資料庫索引。
B+樹索引
查找一個特定值這個樹挺好用,但是當你需要查找兩個值之間的多個元素時,就會有大麻煩了。你的成本將是 O(N),因為你必須查找樹的每一個節點,以判斷它是否處於那 2 個值之間(例如,對樹使用中序遍歷)。而且這個操作不是磁碟I/O有利的,因為你必須讀取整個樹。我們需要找到高效的範圍查詢方法。為瞭解決這個問題,現代資料庫使用了一種修訂版的樹,叫做B+樹。在一個B+樹里:
- 只有最底層的節點(葉子節點)才保存信息(相關表的行位置)
- 其它節點只是在搜索中用來指引到正確節點的。

你可以看到,節點更多了(多了兩倍)。確實,你有了額外的節點,它們就是幫助你找到正確節點的『決策節點』(正確節點保存著相關表中行的位置)。但是搜索複雜度還是在 O(log(N))(只多了一層)。一個重要的不同點是,最底層的節點是跟後續節點相連接的。
用這個 B+樹,假設你要找40到100間的值:
- 你只需要找 40(若40不存在則找40之後最貼近的值),就像你在上一個樹中所做的那樣。
- 然後用那些連接來收集40的後續節點,直到找到100。
比方說你找到了 M 個後續節點,樹總共有 N 個節點。對指定節點的搜索成本是 log(N),跟上一個樹相同。但是當你找到這個節點,你得通過後續節點的連接得到 M 個後續節點,這需要 M 次運算。那麼這次搜索只消耗了 M+log(N) 次運算,區別於上一個樹所用的 N 次運算。此外,你不需要讀取整個樹(僅需要讀 M+log(N) 個節點),這意味著更少的磁碟訪問。如果 M 很小(比如 200 行)並且 N 很大(1,000,000),那結果就是天壤之別了。
然而還有新的問題(又來了!)。如果你在資料庫中增加或刪除一行(從而在相關的 B+樹索引里):
- 你必須在B+樹中的節點之間保持順序,否則節點會變得一團糟,你無法從中找到想要的節點。
- 你必須儘可能降低B+樹的層數,否則 O(log(N)) 複雜度會變成 O(N)。
換句話說,B+樹需要自我整理和自我平衡。謝天謝地,我們有智能刪除和插入。但是這樣也帶來了成本:在B+樹中,插入和刪除操作是 O(log(N)) 複雜度。所以有些人聽到過使用太多索引不是個好主意這類說法。沒錯,你減慢了快速插入/更新/刪除表中的一個行的操作,因為資料庫需要以代價高昂的每索引 O(log(N)) 運算來更新表的索引。再者,增加索引意味著給事務管理器帶來更多的工作負荷(在本文結尾我們會探討這個管理器)。
想瞭解更多細節,你可以看看 Wikipedia 上這篇關於B+樹的文章。如果你想要資料庫中實現B+樹的例子,看看MySQL核心開發人員寫的這篇文章 和 這篇文章。兩篇文章都致力於探討 innoDB(MySQL引擎)如何處理索引。
哈希表
我們最後一個重要的數據結構是哈希表。當你想快速查找值時,哈希表是非常有用的。而且,理解哈希表會幫助我們接下來理解一個資料庫常見的聯接操作,叫做『哈希聯接』。這個數據結構也被資料庫用來保存一些內部的東西(比如鎖表或者緩衝池,我們在下文會研究這兩個概念)。
哈希表這種數據結構可以用關鍵字來快速找到一個元素。為了構建一個哈希表,你需要定義:
- 元素的關鍵字
- 關鍵字的哈希函數。關鍵字計算出來的哈希值給出了元素的位置(叫做哈希桶)。
- 關鍵字比較函數。一旦你找到正確的哈希桶,你必須用比較函數在桶內找到你要的元素。
一個簡單的例子
我們來看一個形象化的例子:

這個哈希表有10個哈希桶。因為我懶,我只給出5個桶,但是我知道你很聰明,所以我讓你想象其它的5個桶。我用的哈希函數是關鍵字對10取模,也就是我只保留元素關鍵字的最後一位,用來查找它的哈希桶:
- 如果元素最後一位是 0,則進入哈希桶0,
- 如果元素最後一位是 1,則進入哈希桶1,
- 如果元素最後一位是 2,則進入哈希桶2,
- …我用的比較函數只是判斷兩個整數是否相等。
【譯者註:取模運算】
比方說你要找元素 78:
- 哈希表計算 78 的哈希碼,等於 8。
- 查找哈希桶 8,找到的第一個元素是 78。
- 返回元素 78。
- 查詢僅耗費了 2 次運算(1次計算哈希值,另一次在哈希桶中查找元素)。
現在,比方說你要找元素 59:
- 哈希表計算 59 的哈希碼,等於9。
- 查找哈希桶 9,第一個找到的元素是 99。因為 99 不等於 59, 那麼 99 不是正確的元素。
- 用同樣的邏輯,查找第二個元素(9),第三個(79),……,最後一個(29)。
- 元素不存在。
- 搜索耗費了 7 次運算。
一個好的哈希函數
你可以看到,根據你查找的值,成本並不相同。
如果我把哈希函數改為關鍵字對 1,000,000 取模(就是說取後6位數字),第二次搜索只消耗一次運算,因為哈希桶 00059 裡面沒有元素。真正的挑戰是找到好的哈希函數,讓哈希桶里包含非常少的元素。
在我的例子里,找到一個好的哈希函數很容易,但這是個簡單的例子。當關鍵字是下列形式時,好的哈希函數就更難找了:
- 1 個字元串(比如一個人的姓)
- 2 個字元串(比如一個人的姓和名)
- 2 個字元串和一個日期(比如一個人的姓、名和出生年月日)
- …
如果有了好的哈希函數,在哈希表裡搜索的時間複雜度是 O(1)。
陣列 vs 哈希表
為什麼不用陣列呢?
嗯,你問得好。
- 一個哈希表可以只裝載一半到記憶體,剩下的哈希桶可以留在硬碟上。
- 用陣列的話,你需要一個連續記憶體空間。如果你載入一個大表,很難分配足夠的連續記憶體空間。
- 用哈希表的話,你可以選擇你要的關鍵字(比如,一個人的國家和姓氏)。
想要更詳細的信息,你可以閱讀我在Java HashMap 上的文章,是關於高效哈希表實現的。你不需要瞭解Java就能理解文章里的概念。
全局概覽
我們已經瞭解了資料庫內部的基本組件,現在我們需要回來看看資料庫的全貌了。
資料庫是一個易於訪問和修改的信息集合。不過簡單的一堆文件也能達到這個效果。事實上,像SQLite這樣最簡單的資料庫也只是一堆文件而已,但SQLite是精心設計的一堆文件,因為它允許你:
- 使用事務來確保數據的安全和一致性
- 快速處理百萬條以上的數據
資料庫一般可以用如下圖形來理解:

撰寫這部分之前,我讀過很多書/論文,它們都以自己的方式描述資料庫。所以,我不會特別關註如何組織資料庫或者如何命名各種進程,因為我選擇了自己的方式來描述這些概念以適應本文。區別就是不同的組件,總體思路為:資料庫是由多種互相交互的組件構成的。
核心組件:
- 進程管理器(process manager):很多資料庫具備一個需要妥善管理的進程/線程池。再者,為了實現納秒級操作,一些現代資料庫使用自己的線程而不是操作系統線程。
- 網路管理器(network manager):網路I/O是個大問題,尤其是對於分散式資料庫。所以一些資料庫具備自己的網路管理器。
- 文件系統管理器(File system manager):磁碟I/O是資料庫的首要瓶頸。具備一個文件系統管理器來完美地處理OS文件系統甚至取代OS文件系統,是非常重要的。
- 記憶體管理器(memory manager):為了避免磁碟I/O帶來的性能損失,需要大量的記憶體。但是如果你要處理大容量記憶體你需要高效的記憶體管理器,尤其是你有很多查詢同時使用記憶體的時候。
- 安全管理器(Security Manager):用於對用戶的驗證和授權。
- 客戶端管理器(Client manager):用於管理客戶端連接。
- ……
工具:
- 備份管理器(Backup manager):用於保存和恢複數據。
- 複原管理器(Recovery manager):用於崩潰後重啟資料庫到一個一致狀態。
- 監控管理器(Monitor manager):用於記錄資料庫活動信息和提供監控資料庫的工具。
- Administration管理器(Administration manager):用於保存元數據(比如表的名稱和結構),提供管理資料庫、模式、表空間的工具。【譯者註:好吧,我真的不知道Administration manager該翻譯成什麼,有知道的麻煩告知,不勝感激……】
- ……
查詢管理器:
- 查詢解析器(Query parser):用於檢查查詢是否合法
- 查詢重寫器(Query rewriter):用於預優化查詢
- 查詢優化器(Query optimizer):用於優化查詢
- 查詢執行器(Query executor):用於編譯和執行查詢
數據管理器:
- 事務管理器(Transaction manager):用於處理事務
- 緩存管理器(Cache manager):數據被使用之前置於記憶體,或者數據寫入磁碟之前置於記憶體
- 數據訪問管理器(Data access manager):訪問磁碟中的數據
在本文剩餘部分,我會集中探討資料庫如何通過如下進程管理SQL查詢的:
- 客戶端管理器
- 查詢管理器
- 數據管理器(含複原管理器)
客戶端管理器

客戶端管理器是處理客戶端通信的。客戶端可以是一個(網站)伺服器或者一個最終用戶或最終應用。客戶端管理器通過一系列知名的API(JDBC, ODBC, OLE-DB …)提供不同的方式來訪問資料庫。
客戶端管理器也提供專有的資料庫訪問API。
當你連接到資料庫時:
- 管理器首先檢查你的驗證信息(用戶名和密碼),然後檢查你是否有訪問資料庫的授權。這些許可權由DBA分配。
- 然後,管理器檢查是否有空閑進程(或線程)來處理你對查詢。
- 管理器還會檢查資料庫是否負載很重。
- 管理器可能會等待一會兒來獲取需要的資源。如果等待時間達到超時時間,它會關閉連接並給出一個可讀的錯誤信息。
- 然後管理器會把你的查詢送給查詢管理器來處理。
- 因為查詢處理進程不是『不全則無』的,一旦它從查詢管理器得到數據,它會把部分結果保存到一個緩衝區並且開始給你發送。
- 如果遇到問題,管理器關閉連接,向你發送可讀的解釋信息,然後釋放資源。
查詢管理器

這部分是資料庫的威力所在,在這部分里,一個寫得糟糕的查詢可以轉換成一個快速執行的代碼,代碼執行的結果被送到客戶端管理器。這個多步驟操作過程如下:
- 查詢首先被解析並判斷是否合法
- 然後被重寫,去除了無用的操作並且加入預優化部分
- 接著被優化以便提升性能,並被轉換為可執行代碼和數據訪問計劃。
- 然後計劃被編譯
- 最後,被執行
這裡我不會過多探討最後兩步,因為它們不太重要。
看完這部分後,如果你需要更深入的知識,我建議你閱讀:
- 關於成本優化的初步研究論文(1979):關係型資料庫系統存取路徑選擇。這個篇文章只有12頁,而且具備電腦一般水平就能理解。
- 非常好、非常深入的 DB2 9.X 如何優化查詢的介紹
- 非常好的PostgreSQL如何優化查詢的介紹。這是一篇最通俗易懂的文檔,因為它講的是『我們來看看在這種情況下,PostgreSQL給出了什麼樣的查詢計劃』,而不是『我們來看看PostgreSQL用的什麼演算法』。
- 官方SQLite優化文檔。『易於』閱讀,因為SQLite用的是簡單規則。再者,這是唯一真正解釋SQLite如何工作的官方文檔。
- 非常好的SQL Server 2005 如何優化查詢的介紹
- Oracle 12c 優化白皮書
- 2篇查詢優化的教程,第一篇 第二篇。教程來自《資料庫系統概念》的作者,很好的讀物,集中討論磁碟I/O,但是要求具有很好的電腦科學水平。
- 另一個原理教程,這篇教程我覺得更易懂,不過它僅關註聯接運算符(join operators)和磁碟I/O。
查詢解析器
每一條SQL語句都要送到解析器來檢查語法,如果你的查詢有錯,解析器將拒絕該查詢。比如,如果你寫成”SLECT …” 而不是 “SELECT …”,那就沒有下文了。
但這還不算完,解析器還會檢查關鍵字是否使用正確的順序,比如 WHERE 寫在 SELECT 之前會被拒絕。
然後,解析器要分析查詢中的表和欄位,使用資料庫元數據來檢查:
- 表是否存在
- 表的欄位是否存在
- 對某類型欄位的 運算 是否 可能(比如,你不能將整數和字元串進行比較,你不能對一個整數使用 substring() 函數)
接著,解析器檢查在查詢中你是否有許可權來讀取(或寫入)表。再強調一次:這些許可權由DBA分配。
在解析過程中,SQL 查詢被轉換為內部表示(通常是一個樹)。
如果一切正常,內部表示被送到查詢重寫器。
查詢重寫器
在這一步,我們已經有了查詢的內部表示,重寫器的目標是:
- 預優化查詢
- 避免不必要的運算
- 幫助優化器找到合理的最佳解決方案
- 歡迎訪問我們的技術交流群650385180
重寫器按照一系列已知的規則對查詢執行檢測。如果查詢匹配一種模式的規則,查詢就會按照這條規則來重寫。下麵是(可選)規則的非詳盡的列表:
- 視圖合併:如果你在查詢中使用視圖,視圖就會轉換為它的 SQL 代碼。
- 子查詢扁平化:子查詢是很難優化的,因此重寫器會嘗試移除子查詢
例如:
MySQL| 1 2 3 4 5 6 | SELECT PERSON.* FROM PERSON WHERE PERSON.person_key IN (SELECT MAILS.person_key FROM MAILS WHERE MAILS.mail LIKE 'christophe%'); |
會轉換為:
MySQL| 1 2 3 4 | SELECT PERSON.* FROM PERSON, MAILS WHERE PERSON.person_key = MAILS.person_key and MAILS.mail LIKE 'christophe%'; |
- 去除不必要的運算符:比如,如果你用了 DISTINCT,而其實你有 UNIQUE 約束(這本身就防止了數據出現重覆),那麼 DISTINCT 關鍵字就被去掉了。
- 排除冗餘的聯接:如果相同的 JOIN 條件出現兩次,比如隱藏在視圖中的 JOIN 條件,或者由於傳遞性產生的無用 JOIN,都會被消除。
- 常數計算賦值:如果你的查詢需要計算,那麼在重寫過程中計算會執行一次。比如 WHERE AGE > 10+2 會轉換為 WHERE AGE > 12 , TODATE(“日期字元串”) 會轉換為 datetime 格式的日期值。
- (高級)分區裁剪(Partition Pruning):如果你用了分區表,重寫器能夠找到需要使用的分區。
- (高級)物化視圖重寫(Materialized view rewrite):如果你有個物化視圖匹配查詢謂詞的一個子集,重寫器將檢查視圖是否最新並修改查詢,令查詢使用物化視圖而不是原始表。
- (高級)自定義規則:如果你有自定義規則來修改查詢(就像 Oracle policy),重寫器就會執行這些規則。
- (高級)OLAP轉換:分析/加窗 函數,星形聯接,ROLLUP 函數……都會發生轉換(但我不確定這是由重寫器還是優化器來完成,因為兩個進程聯繫很緊,必須看是什麼資料庫)。
【譯者註: 物化視圖 。謂詞,predicate,條件表達式的求值返回真或假的過程】
重寫後的查詢接著送到優化器,這時候好玩的就開始了。
統計
研究資料庫如何優化查詢之前我們需要談談統計,因為沒有統計的資料庫是愚蠢的。除非你明確指示,資料庫是不會分析自己的數據的。沒有分析會導致資料庫做出(非常)糟糕的假設。
但是,資料庫需要什麼類型的信息呢?
我必須(簡要地)談談資料庫和操作系統如何保存數據。兩者使用的最小單位叫做頁或塊(預設 4 或 8 KB)。這就是說如果你僅需要 1KB,也會占用一個頁。要是頁的大小為 8KB,你就浪費了 7KB。
回來繼續講統計! 當你要求資料庫收集統計信息,資料庫會計算下列值:
- 表中行和頁的數量
- 表中每個列中的:
唯一值
數據長度(最小,最大,平均)
數據範圍(最小,最大,平均)
- 表的索引信息
這些統計信息會幫助優化器估計查詢所需的磁碟 I/O、CPU、和記憶體使用
對每個列的統計非常重要。
比如,如果一個表 PERSON 需要聯接 2 個列: LAST_NAME, FIRST_NAME。
根據統計信息,資料庫知道FIRST_NAME只有 1,000 個不同的值,LAST_NAME 有 1,000,000 個不同的值。
因此,資料庫就會按照 LAST_NAME, FIRST_NAME 聯接。
因為 LAST_NAME 不大可能重覆,多數情況下比較 LAST_NAME 的頭 2 、 3 個字元就夠了,這將大大減少比較的次數。
不過,這些只是基本的統計。你可以讓資料庫做一種高級統計,叫直方圖。直方圖是列值分佈情況的統計信息。例如:
- 出現最頻繁的值
- 分位數 【譯者註:http://baike.baidu.com/view/1323572.htm】
- …
這些額外的統計會幫助資料庫找到更佳的查詢計劃,尤其是對於等式謂詞(例如: WHERE AGE = 18 )或範圍謂詞(例如: WHERE AGE > 10 and AGE < 40),因為資料庫可以更好的瞭解這些謂詞相關的數字類型數據行(註:這個概念的技術名稱叫選擇率)。
統計信息保存在資料庫元數據內,例如(非分區)表的統計信息位置:
- Oracle: USER / ALL / DBA_TABLES 和 USER / ALL / DBA_TAB_COLUMNS
- DB2: SYSCAT.TABLES 和 SYSCAT.COLUMNS
統計信息必須及時更新。如果一個表有 1,000,000 行而資料庫認為它只有 500 行,沒有比這更糟糕的了。統計唯一的不利之處是需要時間來計算,這就是為什麼資料庫大多預設情況下不會自動計算統計信息。數據達到百萬級時統計會變得困難,這時候,你可以選擇僅做基本統計或者在一個資料庫樣本上執行統計。
舉個例子,我參與的一個項目需要處理每表上億條數據的庫,我選擇只統計10%,結果造成了巨大的時間消耗。本例證明這是個糟糕的決定,因為有時候 Oracle 10G 從特定表的特定列中選出的 10% 跟全部 100% 有很大不同(對於擁有一億行數據的表,這種情況極少發生)。這次錯誤的統計導致了一個本應 30 秒完成的查詢最後執行了 8 個小時,查找這個現象根源的過程簡直是個噩夢。這個例子顯示了統計的重要性。
註:當然了,每個資料庫還有其特定的更高級的統計。如果你想瞭解更多信息,讀讀資料庫的文檔。話雖然這麼說,我已經儘力理解統計是如何使用的了,而且我找到的最好的官方文檔來自PostgreSQL。
查詢優化器

所有的現代資料庫都在用基於成本的優化(即CBO)來優化查詢。道理是針對每個運算設置一個成本,通過應用成本最低廉的一系列運算,來找到最佳的降低查詢成本的方法。
為了理解成本優化器的原理,我覺得最好用個例子來『感受』一下這個任務背後的複雜性。這裡我將給出聯接 2 個表的 3 個方法,我們很快就能看到即便一個簡單的聯接查詢對於優化器來說都是個噩夢。之後,我們會瞭解真正的優化器是怎麼做的。
對於這些聯接操作,我會專註於它們的時間複雜度,但是,資料庫優化器計算的是它們的 CPU 成本、磁碟 I/O 成本、和記憶體需求。時間複雜度和 CPU 成本的區別是,時間成本是個近似值(給我這樣的懶家伙準備的)。而 CPU 成本,我這裡包括了所有的運算,比如:加法、條件判斷、乘法、迭代……還有呢:
- 每一個高級代碼運算都要特定數量的低級 CPU 運算。
- 對於 Intel Core i7、Intel Pentium 4、AMD Opteron…等,(就 CPU 周期而言)CPU 的運算成本是不同的,也就是說它取決於 CPU 的架構。
使用時間複雜度就容易多了(至少對我來說),用它我也能瞭解到 CBO 的概念。由於磁碟 I/O 是個重要的概念,我偶爾也會提到它。請牢記,大多數時候瓶頸在於磁碟 I/O 而不是 CPU 使用。
索引
在研究 B+樹的時候我們談到了索引,要記住一點,索引都是已經排了序的。
僅供參考:還有其他類型的索引,比如點陣圖索引,在 CPU、磁碟I/O、和記憶體方面與B+樹索引的成本並不相同。
另外,很多現代資料庫為了改善執行計劃的成本,可以僅為當前查詢動態地生成臨時索引。
存取路徑
在應用聯接運算符(join operators)之前,你首先需要獲得數據。以下就是獲得數據的方法。
註:由於所有存取路徑的真正問題是磁碟 I/O,我不會過多探討時間複雜度。
【譯者註:四種類型的Oracle索引掃描介紹 】
全掃描
如果你讀過執行計劃,一定看到過『全掃描』(或只是『掃描』)一詞。簡單的說全掃描就是資料庫完整的讀一個表或索引。就磁碟 I/O 而言,很明顯全表掃描的成本比索引全掃描要高昂。
範圍掃描
其他類型的掃描有索引範圍掃描,比如當你使用謂詞 ” WHERE AGE > 20 AND AGE < 40 ” 的時候它就會發生。
當然,你需要在 AGE 欄位上有索引才能用到索引範圍掃描。
在第一部分我們已經知道,範圍查詢的時間成本大約是 log(N)+M,這裡 N 是索引的數據量,M 是範圍內估測的行數。多虧有了統計我們才能知道 N 和 M 的值(註: M 是謂詞 “ AGE > 20 AND AGE < 40 ” 的選擇率)。另外範圍掃描時,你不需要讀取整個索引,因此在磁碟 I/O 方面沒有全掃描那麼昂貴。
唯一掃描
如果你只需要從索引中取一個值你可以用唯一掃描。
根據 ROW ID 存取
多數情況下,如果資料庫使用索引,它就必須查找與索引相關的行,這樣就會用到根據 ROW ID 存取的方式。
例如,假如你運行:
MySQL| 1 | SELECT LASTNAME, FIRSTNAME from PERSON WHERE AGE = 28 |
如果 person 表的 age 列有索引,優化器會使用索引找到所有年齡為 28 的人,然後它會去表中讀取相關的行,這是因為索引中只有 age 的信息而你要的是姓和名。
但是,假如你換個做法:
MySQL| 1 2 | SELECT TYPE_PERSON.CATEGORY from PERSON ,TYPE_PERSON WHERE PERSON.AGE = TYPE_PERSON.AGE |
PERSON 表的索引會用來聯接 TYPE_PERSON 表,但是 PERSON 表不會根據行ID 存取,因為你並沒有要求這個表內的信息。
雖然這個方法在少量存取時表現很好,這個運算的真正問題其實是磁碟 I/O。假如需要大量的根據行ID存取,資料庫也許會選擇全掃描。
其它路徑
我沒有列舉所有的存取路徑,如果你感興趣可以讀一讀 Oracle文檔。其它資料庫里也許叫法不同但背後的概念是一樣的。
聯接運算符
那麼,我們知道如何獲取數據了,那現在就把它們聯接起來!
我要展現的是3個個常用聯接運算符:合併聯接(Merge join),哈希聯接(Hash Join)和嵌套迴圈聯接(Nested Loop Join)。但是在此之前,我需要引入新辭彙了:內關係和外關係( inner relation and outer relation) 【譯者註: “內關係和外關係” 這個說法來源不明,跟查詢的“內聯接(INNER JOIN) 、外聯接(OUTER JOIN) ” 不是一個概念 。只查到百度百科詞條:關係資料庫 里提到“每個表格(有時被稱為一個關係)……” 。 其他參考鏈接 “Merge Join” “Hash Join” “Nested Loop Join” 】 。 一個關係可以是:
- 一個表
- 一個索引
- 上一個運算的中間結果(比如上一個聯接運算的結果)
當你聯接兩個關係時,聯接演算法對兩個關係的處理是不同的。在本文剩餘部分,我將假定:
- 外關係是左側數據集
- 內關係是右側數據集
比如, A JOIN B 是 A 和 B 的聯接,這裡 A 是外關係,B 是內關係。
多數情況下, A JOIN B 的成本跟 B JOIN A 的成本是不同的。
在這一部分,我還將假定外關係有 N 個元素,內關係有 M 個元素。要記住,真實的優化器通過統計知道 N 和 M 的值。
註:N 和 M 是關係的基數。【譯者註: 基數 】
嵌套迴圈聯接
嵌套迴圈聯接是最簡單的。

道理如下:
- 針對外關係的每一行
- 查看內關係里的所有行來尋找匹配的行
下麵是偽代碼:
C
  更多相關文章
一周排行
 所有分類
|