
前言 見解有限,如有描述不當之處,請幫忙指出,如有錯誤,會及時修正。 為什麼要梳理這篇文章? 最近恰好被問到這方面的問題,嘗試整理後發現,這道題的覆蓋面可以非常廣,很適合作為一道承載知識體系的題目。 關於這道題目的吐槽暫且不提(這是一道被提到無數次的題,得到不少人的贊同,也被很多人反感),本文的目的 ...
前言
見解有限,如有描述不當之處,請幫忙指出,如有錯誤,會及時修正。
為什麼要梳理這篇文章?
最近恰好被問到這方面的問題,嘗試整理後發現,這道題的覆蓋面可以非常廣,很適合作為一道承載知識體系的題目。
關於這道題目的吐槽暫且不提(這是一道被提到無數次的題,得到不少人的贊同,也被很多人反感),本文的目的是如何藉助這道題梳理自己的前端知識體系!
竊認為,每一個前端人員,如果要往更高階發展,必然會將自己的知識體系梳理一遍,
沒有牢固的知識體系,無法往更高處走!
展現形式:本文並不是將所有的知識點列一遍,而是偏向於分析+梳理
內容:在本文中只會梳理一些比較重要的前端向知識點,其它的可能會被省略
目標:本文的目標是梳理一個較為完整的前端向知識體系
本文是個人階段性梳理知識體系的成果,然後加以修繕後發佈成文章,因此並不確保適用於所有人員,但是,個人認為本文還是有一定參考價值的
另外,如有不同見解,可以一起討論
----------超長文預警,需要花費大量時間。----------
本文適合有一定經驗的前端人員,新手請規避。
本文內容超多,建議先瞭解主幹,然後分成多批次閱讀。
本文是前端向,以前端領域的知識為重點
大綱
對知識體系進行一次預評級
為什麼說知識體系如此重要?
梳理主幹流程
從瀏覽器接收url到開啟網路請求線程
多進程的瀏覽器
多線程的瀏覽器內核
解析URL
網路請求都是單獨的線程
更多
開啟網路線程到發出一個完整的http請求
DNS查詢得到IP
tcp/ip請求
五層網際網路協議棧
從伺服器接收到請求到對應後臺接收到請求
負載均衡
後臺的處理
後臺和前臺的http交互
http報文結構
cookie以及優化
gzip壓縮
http 2.0
https
單獨拎出來的緩存問題,http的緩存
強緩存與弱緩存
緩存頭部簡述
頭部的區別
解析頁面流程
流程簡述
HTML解析,構建DOM
生成CSS規則
構建渲染樹
渲染
簡單層與複合層
Chrome中的調試
資源外鏈的下載
loaded和domcontentloaded
CSS的可視化格式模型
包含塊(Containing Block)
控制框(Controlling Box)
BFC(Block Formatting Context)
IFC(Inline Formatting Context)
其它
JS引擎解析過程
JS的解釋階段
JS的預處理階段
JS的執行階段
回收機制
其它
總結
對知識體系進行一次預評級
看到這道題目,不藉助搜索引擎,自己的心裡是否有一個答案?
這裡,以目前的經驗(瞭解過一些處於不同階段的相關前端人員的情況),大概有以下幾種情況:(以下都是以點見面,實際上不同階段人員一般都會有其它的隱藏知識點的)
level1:
完全沒什麼概念的,支支吾吾的回答,一般就是這種水平(大致形象點描述):
- 瀏覽器發起請求,服務端返回數據,然後前端解析成網頁,執行腳本。。。
這類人員一般都是:
萌新(剛接觸前端的,包括0-6個月都有可能有這種回答)
沉澱人員(就是那種可能已經接觸了前端幾年,但是仍然處於初級階段的那種。。。)
當然了,後者一般還會偶爾提下http、後臺、瀏覽器渲染,js引擎等等關鍵字,
但基本都是一詳細的問就不知道了。。。
level2:
已經有初步概念,但是可能沒有完整梳理過,導致無法形成一個完整的體系,或者是很多細節都不會展開,大概是這樣子的:(可能符合若幹條)
知道瀏覽器輸入url後會有http請求這個概念
有後臺這個概念,大致知道前後端的交互,知道前後端只要靠http報文通信
知道瀏覽器接收到數據後會進行解析,有一定概念,但是具體流程不熟悉(如render樹構建流程,layout、paint,複合層與簡單層,常用優化方案等不是很熟悉)
對於js引擎的解析流程有一定概念,但是細節不熟悉(如具體的形參,函數,變數提升,執行上下文以及VO、AO、作用域鏈,回收機制等概念不是很熟悉)
如可能知道一些http規範初步概念,但是不熟悉(如http報文結構,常用頭部,緩存機制,http2.0,https等特性,跨域與web安全等不是很熟悉)
到這裡,看到這上面一大堆的概念後,心裡應該也會有點底了。。。
實際上,大部分的前端人員可能都處於level2,但是,跳出這個階段並不容易,一般需要積累,不斷學習,才能水到渠成
這類人員一般都是:
工作1-3年左右的普通人員(占大多數,而且大多數人員工作3年左右並沒有實質上的提升)
工作3年以上的老人(這部分人大多都業務十分嫻熟,一個當好幾個用,但是,基礎比較薄弱,可能沒有嘗試寫過框架、組件、腳手架等)
大部分的初中級都陷在這個階段,如果要突破,不斷學習,積累,自然能水到渠成,打通任督二脈
level3:
基本能到這一步的,不是高階就是接近高階,因為很多概念並不是靠背就能理解的,而要理解這麼多,需形成體系,一般都需要積累,非一日之功。
一般包括什麼樣的回答呢?(這裡就以自己的簡略回答進行舉例),一般這個階段的人員都會符合若幹條(不一定全部,當然可能還有些是這裡遺漏的)
首先略去那些鍵盤輸入、和操作系統交互、以及屏幕顯示原理、網卡等硬體交互之類的(前端向中,很多硬體原理暫時略去。。。)
對瀏覽器模型有整體概念,知道瀏覽器是多進程的,瀏覽器內核是多線程的,清楚進程與線程之間得區別,以及輸入url後會開一個新的網路線程
對從開啟網路線程到發出一個完整的http請求中間的過程有所瞭解(如dns查詢,tcp/ip鏈接,五層因特爾協議棧等等,以及一些優化方案,如
dns-prefetch)對從伺服器接收到請求到對應後臺接收到請求有一定瞭解(如負載均衡,安全攔截以及後臺代碼處理等)
對後臺和前臺的http交互熟悉(包括http報文結構,場景頭部,cookie,跨域,web安全,http緩存,http2.0,https等)
對瀏覽器接收到http數據包後的解析流程熟悉(包括解析html,詞法分析然後解析成dom樹、解析css生成css規則樹、合併成render樹,然後layout、painting渲染、裡面可能還包括複合圖層的合成、GPU繪製、外鏈處理、載入順序等)
對JS引擎解析過程熟悉(包括JS的解釋,預處理,執行上下文,VO,作用域鏈,this,回收機制等)
可以看到,上述包括了一大堆的概念,僅僅是偏前端向,而且沒有詳細展開,就已經如此之多的概念了,所以,個人認為如果沒有自己的見解,沒有形成自己的知識體系,僅僅是看看,背背是沒用的,過一段時間就會忘光了。
再說下一般這個階段的都可能是什麼樣的人吧。(不一定准確,這裡主要是靠少部分現實以及大部分推測得出)
工作2年以上的前端(基本上如果按正常進度的話,至少接觸前端兩年左右才會開始走向高階,當然,現在很多都是上學時就開始學了的,還有部分是天賦異稟,不好預估。。。)
或者是已經十分熟悉其它某門語言,再轉前端的人(基本上是很快就可以將前端水準提升上去)
一般符合這個條件的都會有各種隱藏屬性(如看過各大框架、組件的源碼,寫過自己的組件、框架、腳手架,做過大型項目,整理過若幹精品博文等)
level4:
由於本人層次尚未達到,所以大致說下自己的見解吧。
一般這個層次,很多大佬都並不僅僅是某個技術棧了,而是成為了技術專家,技術leader之類的角色。所以僅僅是回答某個技術問題已經無法看出水準了,
可能更多的要看架構,整體把控,大型工程構建能力等等
不過,對於某些執著於技術的大佬,大概會有一些回答吧:(猜的)
- 從鍵盤談起到系統交互,從瀏覽器到CPU,從調度機制到系統內核,從數據請求到二進位、彙編,從GPU繪圖到LCD顯示,然後再分析系統底層的進程、記憶體等等
總之,從軟體到硬體,到材料,到分子,原子,量子,薛定諤的貓,人類起源,宇宙大爆炸,平行宇宙?感覺都毫無違和感。。。
這點可以參考下本題的原始出處:
http://fex.baidu.com/blog/2014/05/what-happen/
為什麼說知識體系如此重要?
為什麼說知識體系如此重要呢?這裡舉幾個例子
假設有被問到這樣一道題目(隨意想到的一個):
- 如何理解getComputedStyle
在尚未梳理知識體系前,大概會這樣回答:
1.普通版本:
getComputedStyle會獲取當前元素所有最終使用的CSS屬性值(最終計算後的結果),
通過window.getComputedStyle等價於document.defaultView.getComputedStyle調用
2.詳細版本:
window.getComputedStyle(elem, null).getPropertyValue("height")可能的值為100px
而且,就算是css上寫的是inherit,getComputedStyle也會把它最終計算出來的
不過註意,如果元素的背景色透明,那麼getComputedStyle獲取出來的就是透明的這個背景(因為透明本身也是有效的),而不會是父節點的背景。
所以它不一定是最終顯示的顏色。就這個API來說,上述的回答已經比較全面了,
但是,其實它是可以繼續延伸的。
譬如現在會這樣回答:
1. getComputedStyle會獲取當前元素所有最終使用的CSS屬性值,window.和document.defaultView.等價...
2. getComputedStyle會引起迴流,因為它需要獲取祖先節點的一些信息進行計算(譬如寬高等),所以用的時候慎用,迴流會引起性能問題。
然後合適的話會將話題引導迴流,重繪,瀏覽器渲染原理等等。
當然也可以列舉一些其它會引發迴流的操作,如offsetXXX,scrollXXX,clientXXX,currentStyle等等再舉一個例子:
- visibility: hidden和display: none的區別
1. 普通回答,一個隱藏,但占據位置,一個隱藏,不占據位置
2. 進一步,display由於隱藏後不占據位置,所以造成了dom樹的改變,會引發迴流,代價較大
3. 再進一步,當一個頁面某個元素經常需要切換display時如何優化,一般會用複合層優化,
或者要求低一點用absolute讓其脫離普通文檔流也行。
然後可以將話題引到普通文檔流,absolute文檔流,複合圖層的區別,
再進一步可以描述下瀏覽器渲染原理以及複合圖層和普通圖層的繪製區別(複合圖層單獨分配資源,獨立繪製,性能提升,但是不能過多,還有隱式合成等等)上面這些大概就是知識系統化後的回答,會更全面,容易由淺入深,而且一有機會就可以往更底層挖
前端向知識的重點
此部分的內容是站在個人視角分析的,並不是說就一定是正確答案
首先明確,電腦方面的知識是可以無窮無盡的挖的,而本文的重點是梳理前端向的重點知識
對於前端向(這裡可能沒有提到node.js之類的,更多的是指客戶端前端),這裡將知識點按重要程度劃分成以下幾大類:
核心知識,必須掌握的,也是最基礎的,譬如瀏覽器模型,渲染原理,JS解析過程,JS運行機制等,作為骨架來承載知識體系
重點知識,往往每一塊都是一個知識點,而且這些知識點都很重要,譬如http相關,web安全相關,跨域處理等
拓展知識,這一塊可能更多的是瞭解,稍微實踐過,但是認識上可能沒有上面那麼深刻,譬如五層因特爾協議棧,hybrid模式,移動原生開發,後臺相關等等(當然,在不同領域,可能有某些知識就上升到重點知識層次了,譬如hybrid開發時,懂原生開發是很重要的)
為什麼要按上面這種方式劃分?
這大概與個人的技術成長有關,記得最開始學前端知識時,是一點一點的積累,一個知識點一個知識點的攻剋。
就這樣,雖然在很長一段時間內積累了不少的知識,但是,總是無法將它串聯到一起。每次梳理時都是很分散的,無法保持思路連貫性。
直到後來,在將瀏覽器渲染原理、JS運行機制、JS引擎解析流程梳理一遍後,感覺就跟打通了任督二脈一樣,有了一個整體的架構,以前的知識點都連貫起來了
梳理出了一個知識體系,以後就算再學新的知識,也會儘量往這個體繫上靠攏,環環相扣,更容易理解,也更不容易遺忘
梳理主幹流程
回到這道題上,如何回答呢?先梳理一個骨架
知識體系中,最重要的是骨架,脈絡。有了骨架後,才方便填充細節。所以,先梳理下主幹流程:
1. 從瀏覽器接收url到開啟網路請求線程
(這一部分可以展開瀏覽器的機制以及進程與線程之間的關係)
2. 開啟網路線程到發出一個完整的http請求
(這一部分涉及到dns查詢,tcp/ip請求,五層網際網路協議棧等知識)
3. 從伺服器接收到請求到對應後臺接收到請求
(這一部分可能涉及到負載均衡,安全攔截以及後臺內部的處理等等)
4. 後臺和前臺的http交互
(這一部分包括http頭部、響應碼、報文結構、cookie等知識,可以提下靜態資源的cookie優化,以及編碼解碼,如gzip壓縮等)
5. 單獨拎出來的緩存問題,http的緩存
(這部分包括http緩存頭部,etag,catch-control等)
6. 瀏覽器接收到http數據包後的解析流程
(解析html-詞法分析然後解析成dom樹、解析css生成css規則樹、合併成render樹,
然後layout、painting渲染、複合圖層的合成、GPU繪製、
外鏈資源的處理、loaded和domcontentloaded等)
7. CSS的可視化格式模型
(元素的渲染規則,如包含塊,控制框,BFC,IFC等概念)
8. JS引擎解析過程
(JS的解釋階段,預處理階段,執行階段生成執行上下文,VO,作用域鏈、回收機制等等)
9.其它
(可以拓展不同的知識模塊,如跨域,web安全,hybrid模式等等內容)梳理出主幹骨架,然後就需要往骨架上填充細節內容
從瀏覽器接收url到開啟網路請求線程
這一部分展開的內容是:瀏覽器進程/線程模型,JS的運行機制
多進程的瀏覽器
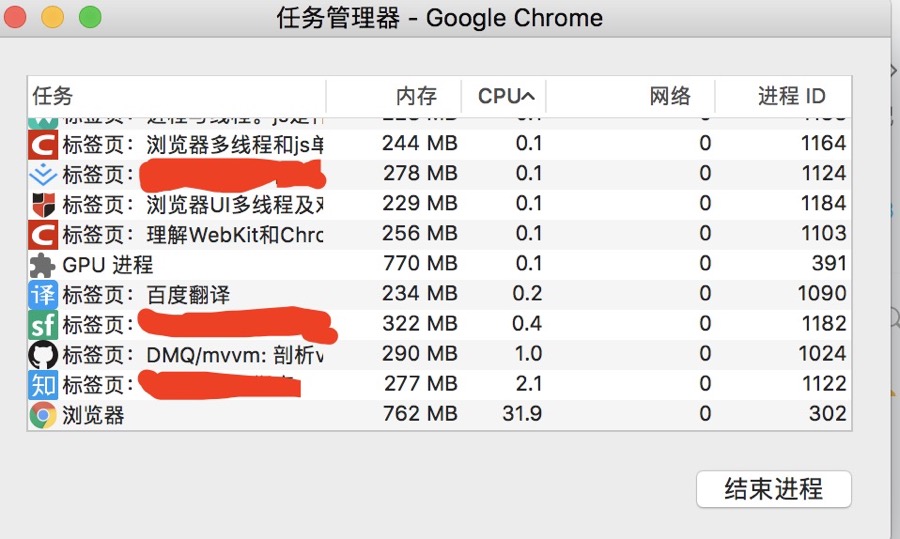
瀏覽器是多進程的,有一個主控進程,以及每一個tab頁面都會新開一個進程(某些情況下多個tab會合併進程)
進程可能包括主控進程,插件進程,GPU,tab頁(瀏覽器內核)等等
Browser進程:瀏覽器的主進程(負責協調、主控),只有一個
第三方插件進程:每種類型的插件對應一個進程,僅當使用該插件時才創建
GPU進程:最多一個,用於3D繪製
瀏覽器渲染進程(內核):預設每個Tab頁面一個進程,互不影響,控制頁面渲染,腳本執行,事件處理等(有時候會優化,如多個空白tab會合併成一個進程)
如下圖:
多線程的瀏覽器內核
每一個tab頁面可以看作是瀏覽器內核進程,然後這個進程是多線程的,它有幾大類子線程
GUI線程
JS引擎線程
事件觸發線程
定時器線程
網路請求線程
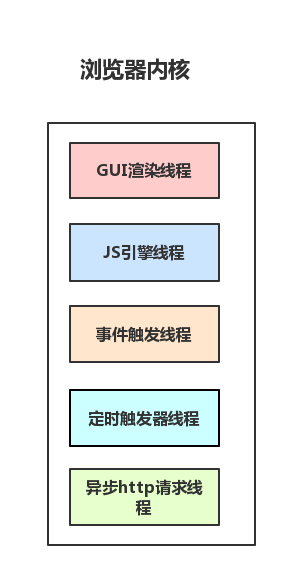
可以看到,裡面的JS引擎是內核進程中的一個線程,這也是為什麼常說JS引擎是單線程的
解析URL
輸入URL後,會進行解析(URL的本質就是統一資源定位符)
URL一般包括幾大部分:
protocol,協議頭,譬如有http,ftp等
host,主機功能變數名稱或IP地址
port,埠號
path,目錄路徑
query,即查詢參數
fragment,即#後的hash值,一般用來定位到某個位置
網路請求都是單獨的線程
每次網路請求時都需要開闢單獨的線程進行,譬如如果URL解析到http協議,就會新建一個網路線程去處理資源下載
因此瀏覽器會根據解析出得協議,開闢一個網路線程,前往請求資源(這裡,暫時理解為是瀏覽器內核開闢的,如有錯誤,後續修複)
更多
由於篇幅關係,這裡就大概介紹一個主幹流程,關於瀏覽器的進程機制,更多可以參考以前總結的一篇文章(因為內容實在過多,裡面包括JS運行機制,進程線程的詳解)
開啟網路線程到發出一個完整的http請求
這一部分主要內容包括:dns查詢,tcp/ip請求構建,五層網際網路協議棧等等
仍然是先梳理主幹,有些詳細的過程不展開(因為展開的話內容過多)
DNS查詢得到IP
如果輸入的是功能變數名稱,需要進行dns解析成IP,大致流程:
如果瀏覽器有緩存,直接使用瀏覽器緩存,否則使用本機緩存,再沒有的話就是用host
如果本地沒有,就向dns功能變數名稱伺服器查詢(當然,中間可能還會經過路由,也有緩存等),查詢到對應的IP
註意,功能變數名稱查詢時有可能是經過了CDN調度器的(如果有cdn存儲功能的話)
而且,需要知道dns解析是很耗時的,因此如果解析功能變數名稱過多,會讓首屏載入變得過慢,可以考慮dns-prefetch優化
這一塊可以深入展開,具體請去網上搜索,這裡就不占篇幅了(網上可以看到很詳細的解答)
tcp/ip請求
http的本質就是tcp/ip請求
需要瞭解3次握手規則建立連接以及斷開連接時的四次揮手
tcp將http長報文劃分為短報文,通過三次握手與服務端建立連接,進行可靠傳輸
三次握手的步驟:(抽象派)
客戶端:hello,你是server麽?
服務端:hello,我是server,你是client麽
客戶端:yes,我是client建立連接成功後,接下來就正式傳輸數據
然後,待到斷開連接時,需要進行四次揮手
(因為是全雙工的,所以需要四次揮手)
四次揮手的步驟:(抽象派)
主動方:我已經關閉了向你那邊的主動通道了,只能被動接收了
被動方:收到通道關閉的信息
被動方:那我也告訴你,我這邊向你的主動通道也關閉了
主動方:最後收到數據,之後雙方無法通信tcp/ip的併發限制
瀏覽器對同一功能變數名稱下併發的tcp連接是有限制的(2-10個不等),
而且在http1.0中往往一個資源下載就需要對應一個tcp/ip請求,
所以針對這個瓶頸,又出現了很多的資源優化方案
get和post的區別
get和post雖然本質都是tcp/ip,但兩者除了在http層面外,在tcp/ip層面也有區別。
get會產生一個tcp數據包,post兩個
具體就是:
get請求時,瀏覽器會把headers和data一起發送出去,伺服器響應200(返回數據),
post請求時,瀏覽器先發送headers,伺服器響應100 continue,
瀏覽器再發送data,伺服器響應200(返回數據)。
再說一點,這裡的區別是specification(規範)層面,而不是implementation(對規範的實現)
五層網際網路協議棧
其實這個概念挺難記全的,記不全沒關係,但是要有一個整體概念
其實就是一個概念:
從客戶端發出http請求到伺服器接收,中間會經過一系列的流程。
簡括就是:
從應用層的發送http請求,到傳輸層通過三次握手建立tcp/ip連接,
再到網路層的ip定址,再到數據鏈路層的封裝成幀,
最後到物理層的利用物理介質傳輸。當然,服務端的接收就是反過來的步驟
五層因特爾協議棧其實就是:
1.應用層(dns,http) DNS解析成IP併發送http請求
2.傳輸層(tcp,udp) 建立tcp連接(三次握手)
3.網路層(IP,ARP) IP定址
4.數據鏈路層(PPP) 封裝成幀
5.物理層(利用物理介質傳輸比特流) 物理傳輸(然後傳輸的時候通過雙絞線,電磁波等各種介質)當然,其實也有一個完整的OSI七層框架,與之相比,多了會話層、表示層。
OSI七層框架:物理層、數據鏈路層、網路層、傳輸層、會話層、表示層、應用層
表示層:主要處理兩個通信系統中交換信息的表示方式,包括數據格式交換,數據加密與解密,數據壓縮與終端類型轉換等
會話層:它具體管理不同用戶和進程之間的對話,如控制登陸和註銷過程從伺服器接收到請求到對應後臺接收到請求
服務端在接收到請求時,內部會進行很多的處理,
這裡由於不是專業的後端分析,所以只是簡單的介紹下,不深入
負載均衡
對於大型的項目,由於併發訪問量很大,所以往往一臺伺服器是吃不消的,
所以一般會有若幹台伺服器組成一個集群,然後配合反向代理實現負載均衡
(當然了,負載均衡不止這一種實現方式,這裡不深入)
簡單的說:
用戶發起的請求都指向調度伺服器(反向代理伺服器,譬如安裝了nginx控制負載均衡),
然後調度伺服器根據實際的調度演算法,分配不同的請求給對應集群中的伺服器執行,
然後調度器等待實際伺服器的HTTP響應,並將它反饋給用戶
後臺的處理
一般後臺都是部署到容器中的,所以一般會先是容器接受到請求(如tomcat容器),
然後對應容器中的後臺程式接收到請求(如java程式),
然後就是後臺會有自己的統一處理,處理完後響應響應結果
概括下:
一般有的後端是有統一的驗證的,如安全攔截,跨域驗證,
如果這一步不符合規則,就直接返回了相應的http報文(如拒絕請求等),
然後當驗證通過後,才會進入實際的後臺代碼,
此時是程式接收到請求,然後執行(譬如查詢資料庫,大量計算等等),
等程式執行完畢後,就會返回一個http響應包(一般這一步也會經過多層封裝),
然後就是將這個包從後端發送到前端,完成交互
後臺和前臺的http交互
前後端交互時,http報文作為信息的載體,
所以http是一塊很重要的內容,這一部分重點介紹它
http報文結構
報文一般包括了:
通用頭部,請求/響應頭部,請求/響應體
通用頭部
這也是開發人員見過的最多的信息,包括如下:
Request Url: 請求的web伺服器地址
Request Method: 請求方式
(Get、POST、OPTIONS、PUT、HEAD、DELETE、CONNECT、TRACE)
Status Code: 請求的返回狀態碼,如200代表成功
Remote Address: 請求的遠程伺服器地址(會轉為IP)譬如,在跨域拒絕時,可能是method為options,狀態碼為404/405等
(當然,實際上可能的組合有很多)
其中,Method的話一般分為兩批次:
HTTP1.0定義了三種請求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五種請求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。這裡面最常用到的就是狀態碼,很多時候都是通過狀態碼來判斷,如(列舉幾個最常見的):
200——表明該請求被成功地完成,所請求的資源發送回客戶端
304——自從上次請求後,請求的網頁未修改過,請客戶端使用本地緩存
400——客戶端請求有錯(譬如可以是安全模塊攔截)
401——請求未經授權
403——禁止訪問(譬如可以是未登錄時禁止)
404——資源未找到
500——伺服器內部錯誤
503——服務不可用
...再列舉下大致不同範圍狀態的意義
1xx——指示信息,表示請求已接收,繼續處理
2xx——成功,表示請求已被成功接收、理解、接受
3xx——重定向,要完成請求必須進行更進一步的操作
4xx——客戶端錯誤,請求有語法錯誤或請求無法實現
5xx——伺服器端錯誤,伺服器未能實現合法的請求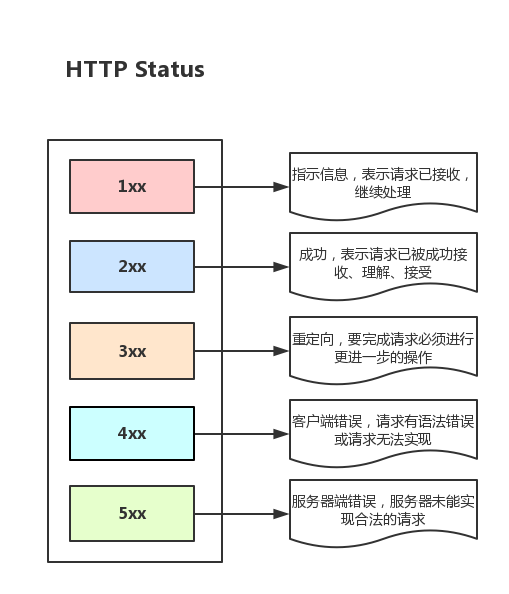
總之,當請求出錯時,狀態碼能幫助快速定位問題,完整版本的狀態可以自行去互聯網搜索
請求/響應頭部
請求和響應頭部也是分析時常用到的
常用的請求頭部(部分):
Accept: 接收類型,表示瀏覽器支持的MIME類型
(對標服務端返回的Content-Type)
Accept-Encoding:瀏覽器支持的壓縮類型,如gzip等,超出類型不能接收
Content-Type:客戶端發送出去實體內容的類型
Cache-Control: 指定請求和響應遵循的緩存機制,如no-cache
If-Modified-Since:對應服務端的Last-Modified,用來匹配看文件是否變動,只能精確到1s之內,http1.0中
Expires:緩存控制,在這個時間內不會請求,直接使用緩存,http1.0,而且是服務端時間
Max-age:代表資源在本地緩存多少秒,有效時間內不會請求,而是使用緩存,http1.1中
If-None-Match:對應服務端的ETag,用來匹配文件內容是否改變(非常精確),http1.1中
Cookie: 有cookie並且同域訪問時會自動帶上
Connection: 當瀏覽器與伺服器通信時對於長連接如何進行處理,如keep-alive
Host:請求的伺服器URL
Origin:最初的請求是從哪裡發起的(只會精確到埠),Origin比Referer更尊重隱私
Referer:該頁面的來源URL(適用於所有類型的請求,會精確到詳細頁面地址,csrf攔截常用到這個欄位)
User-Agent:用戶客戶端的一些必要信息,如UA頭部等常用的響應頭部(部分):
Access-Control-Allow-Headers: 伺服器端允許的請求Headers
Access-Control-Allow-Methods: 伺服器端允許的請求方法
Access-Control-Allow-Origin: 伺服器端允許的請求Origin頭部(譬如為*)
Content-Type:服務端返回的實體內容的類型
Date:數據從伺服器發送的時間
Cache-Control:告訴瀏覽器或其他客戶,什麼環境可以安全的緩存文檔
Last-Modified:請求資源的最後修改時間
Expires:應該在什麼時候認為文檔已經過期,從而不再緩存它
Max-age:客戶端的本地資源應該緩存多少秒,開啟了Cache-Control後有效
ETag:請求變數的實體標簽的當前值
Set-Cookie:設置和頁面關聯的cookie,伺服器通過這個頭部把cookie傳給客戶端
Keep-Alive:如果客戶端有keep-alive,服務端也會有響應(如timeout=38)
Server:伺服器的一些相關信息一般來說,請求頭部和響應頭部是匹配分析的。
譬如,請求頭部的Accept要和響應頭部的Content-Type匹配,否則會報錯
譬如,跨域請求時,請求頭部的Origin要匹配響應頭部的Access-Control-Allow-Origin,否則會報跨域錯誤
譬如,在使用緩存時,請求頭部的If-Modified-Since、If-None-Match分別和響應頭部的Last-Modified、ETag對應
還有很多的分析方法,這裡不一一贅述
請求/響應實體
http請求時,除了頭部,還有消息實體,一般來說
請求實體中會將一些需要的參數都放入進入(用於post請求)。
譬如實體中可以放參數的序列化形式(a=1&b=2這種),
或者直接放表單對象(Form Data對象,上傳時可以夾雜參數以及文件),
等等
而一般響應實體中,就是放服務端需要傳給客戶端的內容,
一般現在的介面請求時,實體中就是對於的信息的json格式,
而像頁面請求這種,裡面就是直接放了一個html字元串,
然後瀏覽器自己解析並渲染。
CRLF
CRLF(Carriage-Return Line-Feed),意思是回車換行,一般作為分隔符存在
請求頭和實體消息之間有一個CRLF分隔,
響應頭部和響應實體之間用一個CRLF分隔
一般來說(分隔符類別):
CRLF->Windows-style
LF->Unix Style
CR->Mac Style如下圖是對某請求的http報文結構的簡要分析

cookie以及優化
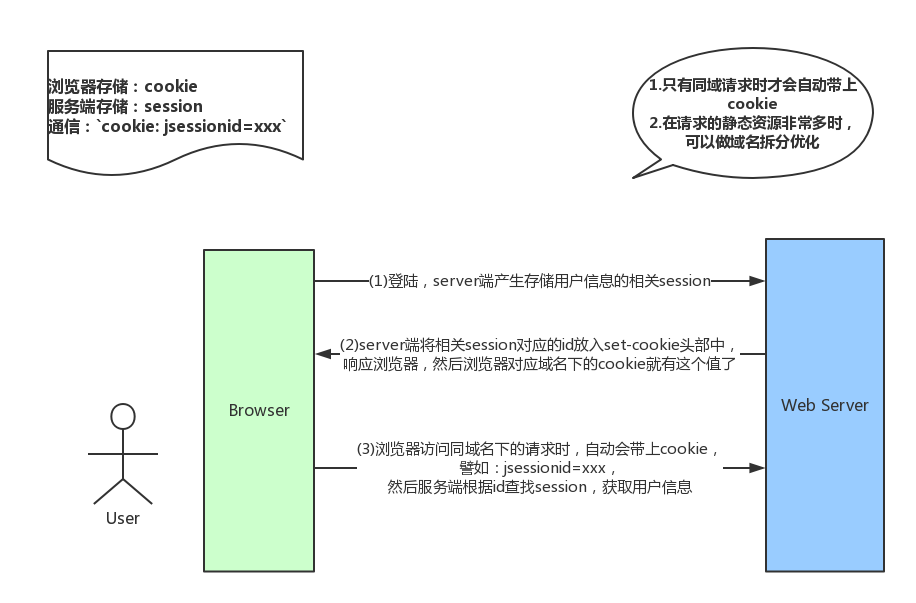
cookie是瀏覽器的一種本地存儲方式,一般用來幫助客戶端和服務端通信的,常用來進行身份校驗,結合服務端的session使用。
場景如下(簡述):
在登陸頁面,用戶登陸了,此時,服務端會生成一個session,session中有對於用戶的信息(如用戶名、密碼等),
然後會有一個sessionid(相當於是服務端的這個session對應的key),
然後服務端在登錄頁面中寫入cookie,值就是`jsessionid=xxx`,
然後瀏覽器本地就有這個cookie了,以後訪問同功能變數名稱下的頁面時,
自動帶上cookie,自動檢驗,在有效時間內無需二次登陸。上述就是cookie的常用場景簡述(當然了,實際情況下得考慮更多因素)
一般來說,cookie是不允許存放敏感信息的(千萬不要明文存儲用戶名、密碼),
因為非常不安全,如果一定要強行存儲,首先,一定要在cookie中設置httponly
(這樣就無法通過js操作了),另外可以考慮rsa等非對稱加密
(因為實際上,瀏覽器本地也是容易被攻剋的,並不安全)
另外,由於在同功能變數名稱的資源請求時,瀏覽器會預設帶上本地的cookie,
針對這種情況,在某些場景下是需要優化的。
譬如以下場景:
客戶端在功能變數名稱A下有cookie(這個可以是登陸時由服務端寫入的),
然後在功能變數名稱A下有一個頁面,頁面中有很多依賴的靜態資源(都是功能變數名稱A的,譬如有20個靜態資源),
此時就有一個問題,頁面載入,請求這些靜態資源時,瀏覽器會預設帶上cookie,
也就是說,這20個靜態資源的http請求,每一個都得帶上cookie,而實際上靜態資源並不需要cookie驗證,
此時就造成了較為嚴重的浪費,而且也降低了訪問速度(因為內容更多了)當然了,針對這種場景,是有優化方案的(多功能變數名稱拆分)。
具體做法就是,將靜態資源分組,分別放到不同的子功能變數名稱下,
而子功能變數名稱請求時,是不會帶上父級功能變數名稱的cookie的,所以就避免了浪費
說到了多功能變數名稱拆分,這裡再提一個問題,那就是在移動端,如果請求的功能變數名稱數過多,
會降低請求速度(因為功能變數名稱整套解析流程是很耗費時間的,而且移動端一般帶寬都比不上pc)。
此時就需要用到一種優化方案:dns-prefetch(讓瀏覽器空閑時提前解析dns功能變數名稱,不過也請合理使用,勿濫用)
關於cookie的交互,可以看下圖總結
gzip壓縮
首先,明確gzip是一種壓縮格式,需要瀏覽器支持才有效(不過一般現在瀏覽器都支持),
而且gzip壓縮效率很好(高達70%左右),
然後gzip一般是由apache、tomcat等web伺服器開啟,
當然伺服器除了gzip外,也還會有其它壓縮格式(如deflate,沒有gzip高效,且不流行),
所以一般只需要在伺服器上開啟了gzip壓縮,然後之後的請求就都是基於gzip壓縮格式的,
非常方便。
http 2.0
http2.0不是https,它相當於是http的下一代規範(譬如https的請求可以是http2.0規範的)
然後簡述下http2.0與http1.1的顯著不同點:
http1.1中,每請求一個資源,都是需要開啟一個tcp/ip連接的,所以對應的結果是,每一個資源對應一個tcp/ip請求,由於tcp/ip本身有併發數限制,所以當資源一多,速度就顯著慢下來
http2.0中,一個tcp/ip請求可以請求多個資源,也就是說,只要一次tcp/ip請求,就可以請求若幹個資源,分割成更小的幀請求,速度明顯提升
所以,如果http2.0全面應用,很多http1.1中的優化方案就無需用到了
(譬如打包成精靈圖,靜態資源多功能變數名稱拆分等)
然後簡述下http2.0的一些特性:
多路復用
(即一個tcp/ip連接可以請求多個資源)首部壓縮
(http頭部壓縮,減少體積)二進位分幀
(在應用層跟傳送層之間增加了一個二進位分幀層,改進傳輸性能,實現低延遲和高吞吐量)伺服器端推送
(服務端可以對客戶端的一個請求發出多個響應,可以主動通知客戶端)請求優先順序
(如果流被賦予了優先順序,它就會基於這個優先順序來處理,由伺服器決定需要多少資源來處理該請求。)
https
https就是安全版本的http,譬如一些支付等操作基本都是基於https的,因為http請求的安全繫數太低了。
簡單來看,https與http的區別就是:在請求前,會建立ssl鏈接,確保接下來的通信都是加密的,無法被輕易截取分析
一般來說,如果要將網站升級成https,需要後端支持(後端需要申請證書等),然後https的開銷也比http要大(因為需要額外建立安全鏈接以及加密等),所以一般來說http2.0配合https的體驗更佳(因為http2.0更快了)
一般來說,主要關註的就是SSL/TLS的握手流程,如下(簡述):
1. 瀏覽器請求建立SSL鏈接,並向服務端發送一個隨機數–Client random和客戶端支持的加密方法,比如RSA加密,此時是明文傳輸。
2. 服務端從中選出一組加密演算法與Hash演算法,回覆一個隨機數–Server random,並將自己的身份信息以證書的形式發回給瀏覽器
(證書里包含了網站地址,非對稱加密的公鑰,以及證書頒發機構等信息)
3. 瀏覽器收到服務端的證書後
- 驗證證書的合法性(頒發機構是否合法,證書中包含的網址是否和正在訪問的一樣),如果證書信任,則瀏覽器會顯示一個小鎖頭,否則會有提示
- 用戶接收證書後(不管信不信任),瀏覽會生產新的隨機數–Premaster secret,然後證書中的公鑰以及指定的加密方法加密`Premaster secret`,發送給伺服器。
- 利用Client random、Server random和Premaster secret通過一定的演算法生成HTTP鏈接數據傳輸的對稱加密key-`session key`
- 使用約定好的HASH演算法計算握手消息,並使用生成的`session key`對消息進行加密,最後將之前生成的所有信息發送給服務端。
4. 服務端收到瀏覽器的回覆
- 利用已知的加解密方式與自己的私鑰進行解密,獲取`Premaster secret`
- 和瀏覽器相同規則生成`session key`
- 使用`session key`解密瀏覽器發來的握手消息,並驗證Hash是否與瀏覽器發來的一致
- 使用`session key`加密一段握手消息,發送給瀏覽器
5. 瀏覽器解密並計算握手消息的HASH,如果與服務端發來的HASH一致,此時握手過程結束,之後所有的https通信數據將由之前瀏覽器生成的session key並利用對稱加密演算法進行加密
這裡放一張圖(來源:阮一峰-圖解SSL/TLS協議)

單獨拎出來的緩存問題,http的緩存
前後端的http交互中,使用緩存能很大程度上的提升效率,
而且基本上對性能有要求的前端項目都是必用緩存的
強緩存與弱緩存
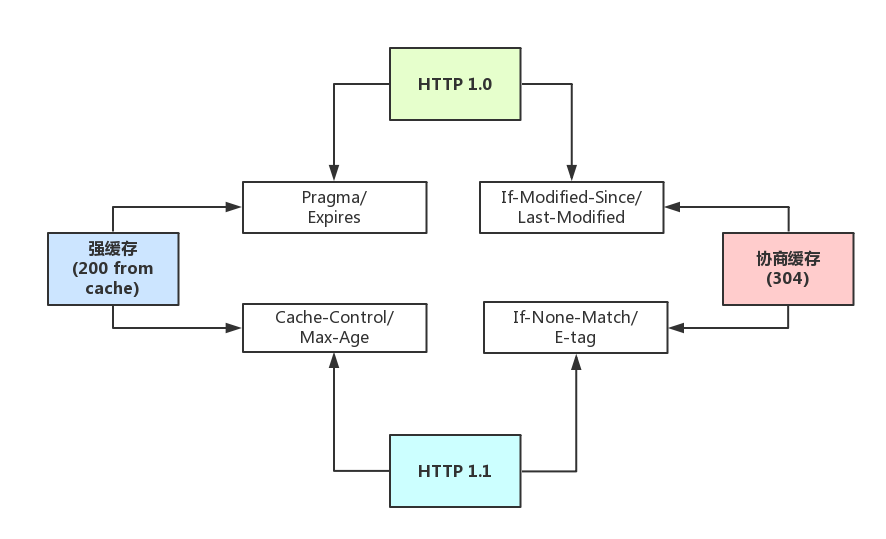
緩存可以簡單的劃分成兩種類型:強緩存(200 from cache)與協商緩存(304)
區別簡述如下:
強緩存(200 from cache)時,瀏覽器如果判斷本地緩存未過期,就直接使用,無需發起http請求
協商緩存(304)時,瀏覽器會向服務端發起http請求,然後服務端告訴瀏覽器文件未改變,讓瀏覽器使用本地緩存
對於協商緩存,使用Ctrl + F5強制刷新可以使得緩存無效,
但是對於強緩存,在未過期時,必須更新資源路徑才能發起新的請求
(更改了路徑相當於是另一個資源了,這也是前端工程化中常用到的技巧)
緩存頭部簡述
上述提到了強緩存和協商緩存,那它們是怎麼區分的呢?
答案是通過不同的http頭部控制
先看下這幾個頭部:
If-None-Match/E-tag、If-Modified-Since/Last-Modified、Cache-Control/Max-Age、Pragma/Expires這些就是緩存中常用到的頭部,這裡不展開。僅列舉下大致使用。
屬於強緩存控制的:
(http1.1)Cache-Control/Max-Age
(http1.0)Pragma/Expires註意:Max-Age不是一個頭部,它是Cache-Control頭部的值
屬於協商緩存控制的:
(http1.1)If-None-Match/E-tag
(http1.0)If-Modified-Since/Last-Modified可以看到,上述有提到http1.1和http1.0,
這些不同的頭部是屬於不同http時期的
再提一點,其實HTML頁面中也有一個meta標簽可以控制緩存方案-Pragma
<META HTTP-EQUIV="Pragma" CONTENT="no-cache">不過,這種方案還是比較少用到,因為支持情況不佳,譬如緩存代理伺服器肯定不支持,所以不推薦
頭部的區別
首先明確,http的發展是從http1.0到http1.1,
而在http1.1中,出了一些新內容,彌補了http1.0的不足。
http1.0中的緩存控制:
Pragma:嚴格來說,它不屬於專門的緩存控制頭部,但是它設置no-cache時可以讓本地強緩存失效
(屬於編譯控制,來實現特定的指令,主要是因為相容http1.0,所以以前又被大量應用)Expires:服務端配置的,屬於強緩存,用來控制在規定的時間之前,瀏覽器不會發出請求,而是直接使用本地緩存,
註意,Expires一般對應伺服器端時間,如Expires:Fri, 30 Oct 1998 14:19:41If-Modified-Since/Last-Modified:這兩個是成對出現的,屬於協商緩存的內容,其中瀏覽器的頭部是If-Modified-Since,而服務端的是Last-Modified,
它的作用是,在發起請求時,如果If-Modified-Since和Last-Modified匹配,那麼代表伺服器資源並未改變,
因此服務端不會返回資源實體,而是只返回頭部,通知瀏覽器可以使用本地緩存。
Last-Modified,顧名思義,指的是文件最後的修改時間,而且只能精確到1s以內
http1.1中的緩存控制:
Cache-Control:緩存控制頭部,有no-cache、max-age等多種取值Max-Age:服務端配置的,用來控制強緩存,在規定的時間之內,瀏覽器無需發出請求,直接使用本地緩存,註意,Max-Age是Cache-Control頭部的值,不是獨立的頭部,譬如Cache-Control: max-age=3600,而且它值得是絕對時間,由瀏覽器自己計算If-None-Match/E-tag:這兩個是成對出現的,屬於協商緩存的內容,其中瀏覽器的頭部是If-None-Match,而服務端的是E-tag,同樣,發出請求後,如果If-None-Match和E-tag匹配,則代表內容未變,通知瀏覽器使用本地緩存,和Last-Modified不同,E-tag更精確,它是類似於指紋一樣的東西,基於FileEtag INode Mtime Size生成,也就是說,只要文件變,指紋就會變,而且沒有1s精確度的限制。
Max-Age相比Expires?
Expires使用的是伺服器端的時間,
但是有時候會有這樣一種情況-客戶端時間和服務端不同步,
那這樣,可能就會出問題了,造成了瀏覽器本地的緩存無用或者一直無法過期,
所以一般http1.1後不推薦使用Expires。
Max-Age使用的是客戶端本地時間的計算,因此不會有這個問題,
這個是推薦使用的。
如果同時啟用了Cache-Control與Expires,Cache-Control優先順序高。
E-tag相比Last-Modified?
Last-Modified指的是服務端的文件最後何時改變的,
首先它有一個缺陷就是只能精確到1s,
然後還有一個問題就是有的服務端的文件會周期性的改變,
導致緩存失效
而E-tag是一直指紋機制,只有文件變才會變,也只要文件變就會變,
也沒有精確時間的限制,只要文件一遍,立馬E-tag就不一樣了
如果同時帶有E-tag和Last-Modified,服務端會優先檢查E-tag
各大緩存頭部的整體關係如下圖
解析頁面流程
前面有提到http交互,那麼接下來就是瀏覽器獲取到html,然後解析,渲染
這部分很多都參考了網上資源,特別是圖片,參考了來源中的文章
流程簡述
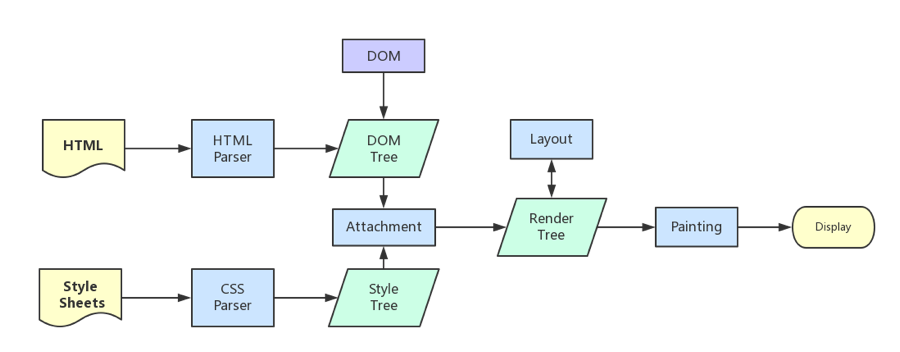
瀏覽器內核拿到內容後,渲染步驟大致可以分為以下幾步:
1. 解析HTML,構建DOM樹
2. 解析CSS,生成CSS規則樹
3. 合併DOM樹和CSS規則,生成render樹
4. 佈局render樹(Layout/reflow),負責各元素尺寸、位置的計算
5. 繪製render樹(paint),繪製頁面像素信息
6. 瀏覽器會將各層的信息發送給GPU,GPU會將各層合成(composite),顯示在屏幕上如下圖:
HTML解析,構建DOM
整個渲染步驟中,HTML解析是第一步。
簡單的理解,這一步的流程是這樣的:瀏覽器解析HTML,構建DOM樹。
但實際上,在分析整體構建時,卻不能一筆帶過,得稍微展開。
解析HTML到構建出DOM當然過程可以簡述如下:
Bytes → characters → tokens → nodes → DOM譬如假設有這樣一個HTML頁面:(以下部分的內容出自參考來源,修改了下格式)
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
<title>Critical Path</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>瀏覽器的處理如下:
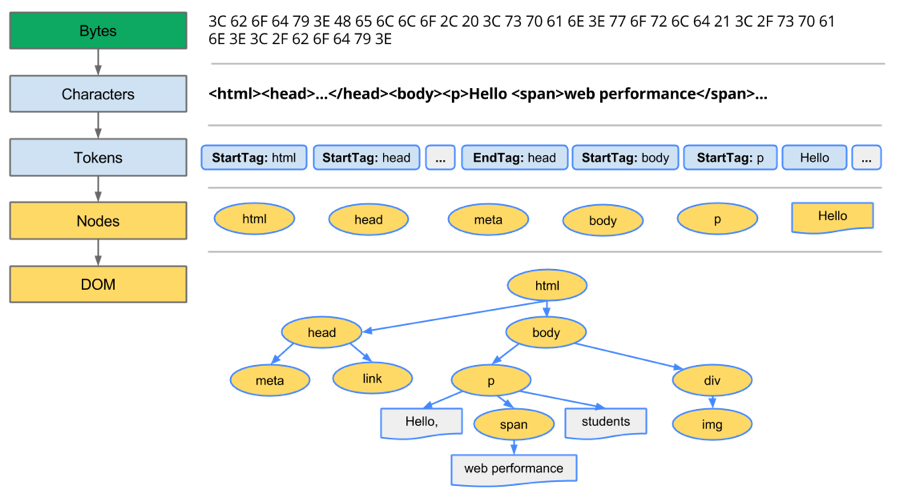
列舉其中的一些重點過程:
1. Conversion轉換:瀏覽器將獲得的HTML內容(Bytes)基於他的編碼轉換為單個字元
2. Tokenizing分詞:瀏覽器按照HTML規範標准將這些字元轉換為不同的標記token。每個token都有自己獨特的含義以及規則集
3. Lexing詞法分析:分詞的結果是得到一堆的token,此時把他們轉換為對象,這些對象分別定義他們的屬性和規則
4. DOM構建:因為HTML標記定義的就是不同標簽之間的關係,這個關係就像是一個樹形結構一樣,
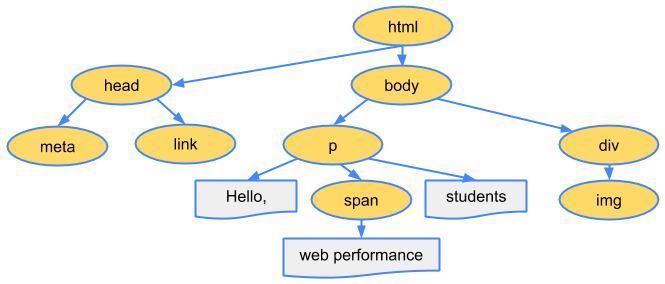
例如:body對象的父節點就是HTML對象,然後段略p對象的父節點就是body對象最後的DOM樹如下:
生成CSS規則
同理,CSS規則樹的生成也是類似。簡述為:
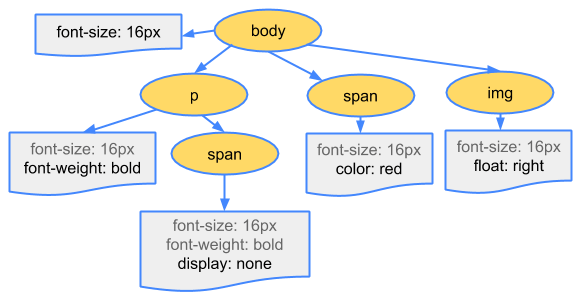
Bytes → characters → tokens → nodes → CSSOM譬如style.css內容如下:
body { font-size: 16px }
p { font-weight: bold }
span { color: red }
p span { display: none }
img { float: right }那麼最終的CSSOM樹就是:
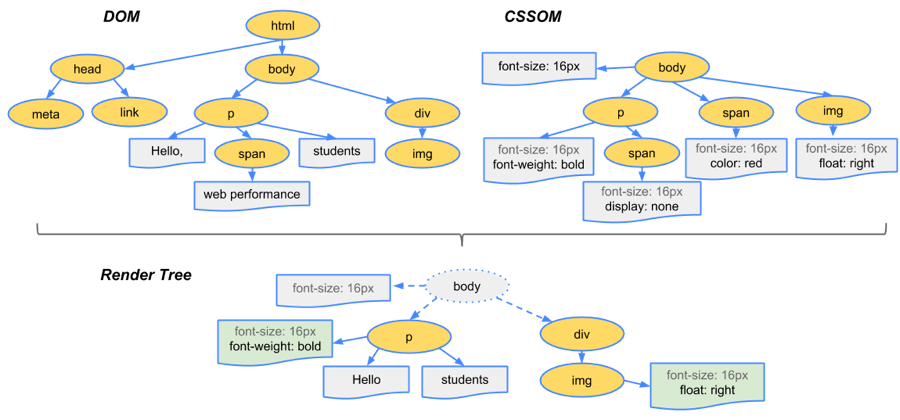
構建渲染樹
當DOM樹和CSSOM都有了後,就要開始構建渲染樹了
一般來說,渲染樹和DOM樹相對應的,但不是嚴格意義上的一一對應,
因為有一些不可見的DOM元素不會插入到渲染樹中,
如head這種不可見的標簽或者display為none等
整體來說可以看圖:
渲染
有了render樹,接下來就是開始渲染,基本流程如下:
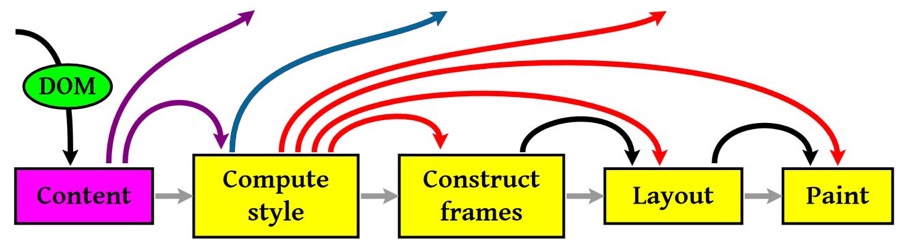
圖中重要的四個步驟就是:
1. 計算CSS樣式
2. 構建渲染樹
3. 佈局,主要定位坐標和大小,是否換行,各種position overflow z-index屬性
4. 繪製,將圖像繪製出來然後,圖中的線與箭頭代表通過js動態修改了DOM或CSS,
導致了重新佈局(Layout)或渲染(Repaint)
這裡Layout和Repaint的概念是有區別的:
Layout,也稱為Reflow,即迴流。一般意味著元素的內容、結構、位置或尺寸發生了變化,需要重新計算樣式和渲染樹
Repaint,即重繪。意味著元素髮生的改變只是影響了元素的一些外觀之類的時候(例如,背景色,邊框顏色,文字顏色等),此時只需要應用新樣式繪製這個元素就可以了
迴流的成本開銷要高於重繪,而且一個節點的迴流往往回導致子節點以及同級節點的迴流,
所以優化方案中一般都包括,儘量避免迴流。
什麼會引起迴流?
1.頁面渲染初始化
2.DOM結構改變,比如刪除了某個節點
3.render樹變化,比如減少了padding
4.視窗resize
5.最複雜的一種:獲取某些屬性,引發迴流
很多瀏覽器會對迴流做優化,會等到數量足夠時做一次批處理迴流
但是除了render樹的直接變化,當獲取一些屬性時,瀏覽器為了獲得正確的值也會觸發迴流,這樣使得瀏覽器優化無效,包括
(1)offset(Top/Left/Width/Height)
(2) scroll(Top/Left/Width/Height)
(3) cilent(Top/Left/Width/Height)
(4) width,height
(5) 調用了getComputedStyle()或者IE的currentStyle迴流一定伴隨著重繪,重繪卻可以單獨出現
所以一般會有一些優化方案,如:
減少逐項更改樣式,最好一次性更改style,或者將樣式定義為class並一次性更新
避免迴圈操作dom,創建一個documentFragment或div,在它上面應用所有DOM操作,最後再把它添加到window.document。
避免多次讀取offset等屬性。無法避免則將它們緩存到變數
將複雜的元素絕對定位或固定定位,使得它脫離文檔流,否則迴流代價會很高註意:改變字體大小會引發迴流
再來看一個示例:
var s = document.body.style;
s.padding = "2px"; // 迴流+重繪
s.border = "1px solid red"; // 再一次 迴流+重繪
s.color = "blue"; // 再一次重繪
s.backgroundColor = "#ccc"; // 再一次 重繪
s.fontSize = "14px"; // 再一次 迴流+重繪
// 添加node,再一次 迴流+重繪
document.body.appendChild(document.createTextNode('abc!'));簡單層與複合層
上述中的渲染中止步於繪製,但實際上繪製這一步也沒有這麼簡單,它可以結合複合層和簡單層的概念來講。
這裡不展開,進簡單介紹下:
可以認為預設只有一個複合圖層,所有的DOM節點都是在這個複合圖層下的
如果開啟了硬體加速功能,可以將某個節點變成複合圖層
複合圖層之間的繪製互不幹擾,由GPU直接控制
而簡單圖層中,就算是absolute等佈局,變化時不影響整體的迴流,
但是由於在同一個


