
(一)、Spark讀取HBase中的數據 hbase中的數據 (二)、Spark寫HBase 1.第一種方式: 2.第二種方式: ...
(一)、Spark讀取HBase中的數據
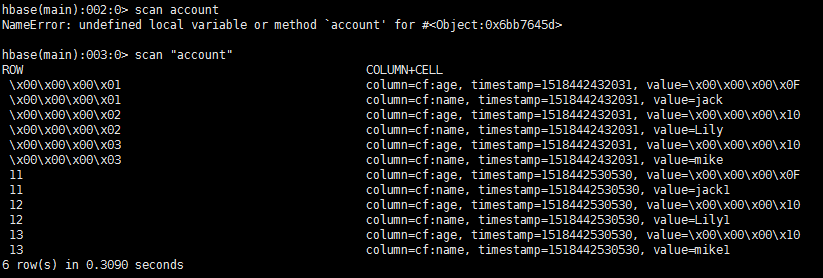
hbase中的數據
1 import org.apache.hadoop.hbase.{HBaseConfiguration, HTableDescriptor, TableName} 2 import org.apache.hadoop.hbase.client.HBaseAdmin 3 import org.apache.hadoop.hbase.mapreduce.TableInputFormat 4 import org.apache.spark._ 5 import org.apache.hadoop.hbase.util.Bytes 6 7 /** 8 * Created by *** on 2018/2/12. 9 * 10 * 從hbase讀取數據轉化成RDD 11 */ 12 object SparkReadHBase { 13 14 def main(args: Array[String]): Unit = { 15 val sparkConf = new SparkConf().setAppName("HBaseTest").setMaster("local") 16 val sc = new SparkContext(sparkConf) 17 18 val tablename = "account" 19 val conf = HBaseConfiguration.create() 20 //設置zooKeeper集群地址,也可以通過將hbase-site.xml導入classpath,但是建議在程式里這樣設置 21 conf.set("hbase.zookeeper.quorum","node02,node03,node04") 22 //設置zookeeper連接埠,預設2181 23 conf.set("hbase.zookeeper.property.clientPort", "2181") 24 conf.set(TableInputFormat.INPUT_TABLE, tablename) 25 26 // 如果表不存在則創建表 27 val admin = new HBaseAdmin(conf) 28 if (!admin.isTableAvailable(tablename)) { 29 val tableDesc = new HTableDescriptor(TableName.valueOf(tablename)) 30 admin.createTable(tableDesc) 31 } 32 33 //讀取數據並轉化成rdd 34 val hBaseRDD = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat], 35 classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable], 36 classOf[org.apache.hadoop.hbase.client.Result]) 37 38 val count = hBaseRDD.count() 39 println(count) 40 hBaseRDD.foreach{case (_,result) =>{ 41 //獲取行鍵 42 val key = Bytes.toString(result.getRow) 43 //通過列族和列名獲取列 44 val name = Bytes.toString(result.getValue("cf".getBytes,"name".getBytes)) 45 val age = Bytes.toInt(result.getValue("cf".getBytes,"age".getBytes)) 46 println("Row key:"+key+" Name:"+name+" Age:"+age) 47 }} 48 49 sc.stop() 50 admin.close() 51 } 52 53 }
(二)、Spark寫HBase
1.第一種方式:
1 import org.apache.hadoop.hbase.HBaseConfiguration 2 import org.apache.hadoop.hbase.client.Put 3 import org.apache.hadoop.hbase.io.ImmutableBytesWritable 4 import org.apache.hadoop.hbase.mapred.TableOutputFormat 5 import org.apache.hadoop.hbase.util.Bytes 6 import org.apache.hadoop.mapred.JobConf 7 import org.apache.spark.{SparkConf, SparkContext} 8 import org.apache.spark.rdd.RDD.rddToPairRDDFunctions 9 /** 10 * Created by *** on 2018/2/12. 11 * 12 * 使用saveAsHadoopDataset寫入數據 13 */ 14 object SparkWriteHBaseOne { 15 def main(args: Array[String]): Unit = { 16 val sparkConf = new SparkConf().setAppName("HBaseTest").setMaster("local") 17 val sc = new SparkContext(sparkConf) 18 19 val conf = HBaseConfiguration.create() 20 //設置zooKeeper集群地址,也可以通過將hbase-site.xml導入classpath,但是建議在程式里這樣設置 21 conf.set("hbase.zookeeper.quorum","node02,node03,node04") 22 //設置zookeeper連接埠,預設2181 23 conf.set("hbase.zookeeper.property.clientPort", "2181") 24 25 val tablename = "account" 26 27 //初始化jobconf,TableOutputFormat必須是org.apache.hadoop.hbase.mapred包下的! 28 val jobConf = new JobConf(conf) 29 jobConf.setOutputFormat(classOf[TableOutputFormat]) 30 jobConf.set(TableOutputFormat.OUTPUT_TABLE, tablename) 31 32 val indataRDD = sc.makeRDD(Array("1,jack,15","2,Lily,16","3,mike,16")) 33 34 35 val rdd = indataRDD.map(_.split(',')).map{arr=>{ 36 /*一個Put對象就是一行記錄,在構造方法中指定主鍵 37 * 所有插入的數據必須用org.apache.hadoop.hbase.util.Bytes.toBytes方法轉換 38 * Put.add方法接收三個參數:列族,列名,數據 39 */ 40 val put = new Put(Bytes.toBytes(arr(0).toInt)) 41 put.add(Bytes.toBytes("cf"),Bytes.toBytes("name"),Bytes.toBytes(arr(1))) 42 put.add(Bytes.toBytes("cf"),Bytes.toBytes("age"),Bytes.toBytes(arr(2).toInt)) 43 //轉化成RDD[(ImmutableBytesWritable,Put)]類型才能調用saveAsHadoopDataset 44 (new ImmutableBytesWritable, put) 45 }} 46 47 rdd.saveAsHadoopDataset(jobConf) 48 49 sc.stop() 50 } 51 }
2.第二種方式:
1 import org.apache.hadoop.hbase.client.{Put, Result} 2 import org.apache.hadoop.hbase.io.ImmutableBytesWritable 3 import org.apache.hadoop.hbase.mapreduce.TableOutputFormat 4 import org.apache.hadoop.hbase.util.Bytes 5 import org.apache.hadoop.mapreduce.Job 6 import org.apache.spark._ 7 /** 8 * Created by *** on 2018/2/12. 9 * 10 * 使用saveAsNewAPIHadoopDataset寫入數據 11 */ 12 object SparkWriteHBaseTwo { 13 def main(args: Array[String]): Unit = { 14 val sparkConf = new SparkConf().setAppName("HBaseTest").setMaster("local") 15 val sc = new SparkContext(sparkConf) 16 17 val tablename = "account" 18 19 sc.hadoopConfiguration.set("hbase.zookeeper.quorum","node02,node03,node04") 20 sc.hadoopConfiguration.set("hbase.zookeeper.property.clientPort", "2181") 21 sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE, tablename) 22 23 val job = new Job(sc.hadoopConfiguration) 24 job.setOutputKeyClass(classOf[ImmutableBytesWritable]) 25 job.setOutputValueClass(classOf[Result]) 26 job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]]) 27 28 val indataRDD = sc.makeRDD(Array("1,jack,15","2,Lily,16","3,mike,16")) 29 val rdd = indataRDD.map(_.split(',')).map{arr=>{ 30 val put = new Put(Bytes.toBytes(arr(0))) 31 put.add(Bytes.toBytes("cf"),Bytes.toBytes("name"),Bytes.toBytes(arr(1))) 32 put.add(Bytes.toBytes("cf"),Bytes.toBytes("age"),Bytes.toBytes(arr(2).toInt)) 33 (new ImmutableBytesWritable, put) 34 }} 35 36 rdd.saveAsNewAPIHadoopDataset(job.getConfiguration()) 37 } 38 }


