
目錄 1.序 2.題庫 3. Oracle 資料庫 資料庫本質是用電腦存儲數據的一種系統。它是位於 用戶 和系統 之間的一種管理軟體。 1.序 1.1 登錄SQLPLUS 1.2 創建一個自己的用戶(比如 vip/vip) 1.3 切換到用戶 1.4 使用 1.5 激活內置的測試賬號,這裡面有幾張 ...
目錄
1.序
2.題庫
3.
Oracle 資料庫
資料庫本質是用電腦存儲數據的一種系統。它是位於 用戶 和系統 之間的一種管理軟體。
1.序
1.1 登錄SQLPLUS
cmd sqlplus [用戶名]/[密碼][@資料庫] [參數] sqlplus sys/orcl as sysdba -- 登錄 sys 用戶,必須指定 sysdba 或 sysoper 身份 sqlplus system/orcl -- 資料庫管理員
1.2 創建一個自己的用戶(比如 vip/vip)
create user vip identified by vip; -- 註意,新創建的用戶,什麼許可權都沒有,需要授權後才能使用 grant create session to vip; -- 授予登錄的許可權 grant connect to vip; -- 角色是很多許可權的打包,connect 是一種角色,它包含了連接查看數據的一些基本許可權 grant dba to vip; -- dba 是絕大多數許可權的集合,它基本能做所有事情,所以很少單獨授予用戶。但在測試環境中,這樣,很爽。 -- 上面的創建用戶、授予許可權兩步操作,可以簡化為下麵一步: grant dba to vip identified by vip; -- 註意,使用分號結尾
1.3 切換到用戶
sqlplus vip/vip -- 在 cmd 下 conn vip/vip -- 在 sqlplus 中
1.4 使用
create table aaa (id int);
1.5 激活內置的測試賬號,這裡面有幾張示例庫,可以用它們練習下查詢
alter user scott account unlock; conn scott/tiger
1.6 修改密碼
alter user scott identified by [newpassword];
2.題庫
2.1 題庫一
- 在芝加哥工作的人中,誰的工資最高
- 查詢每個部門下有多少員工
- 查詢除去 salesman 所有平均工資超過 1500 的部門
- 查詢在 new york 工作的所有員工的姓名,部門名稱和工資信息
- 查詢姓名為 King 的員工的編號,名稱跟部門
- 查詢各種工作的最低工資
- 查詢工齡大於10年的所有員工信息
- 查詢每個部門員工數量,平均工資和平均工作年限
- 統計各部門每個工種的人數,平均工資。
- 查詢從事同一種工作但不屬於同一部門的員工信息。
- 查詢所有員工工資都大於1000的部門的信息及員工信息
- 查詢入職日期早於其直接上級的所有員工信息。
- 列出雇員中(除去mgr為空的人)工資第二高的人。
- 列出1981年來公司所有員工的總收入(包括sal和comm)
2.2 題庫二
- 查詢工資為 2500 到 4000 的人的數量(用不同方式查詢)
select count(*) from emp where sal >= 2500 and sal <= 4000; -- vs. select count(*) from emp where sal between 2500 and 4000;
- 查詢部門編號為 10 和 30 的所有人(用不同方式查詢)
- 查詢部門編號為 10 和 30 中名字中不含有 ‘C’ 的所有人
- 查詢部門編號為 10 和 30 中名字首字母之外不含有 ‘C’ 的所有人
- 查詢部門編號為 10 和 30 中所有的經理以及名字首字母之外不含有 ‘C’ 的所有人
- 查詢紐約和芝加哥地區所有的經理以及名字首字母之外不含有 ‘C’ 的所有人
- 查詢紐約和芝加哥地區所有的經理以及頂頭上司名字的首字母之外不含有 ‘C’ 的所有人
- 查詢每個人的工資等級
-- 初始化數據 create table salgrade as select * from scott.salgrade; -- 分別查看數據 select * from emp; select * from salgrade; -- 雜交 select * from emp, salgrade; -- 過濾掉不合適的 select ename, grade from emp e, salgrade s where e.sal between s.losal and s.hisal;
- 查詢每個部門的平均工資的等級
-- 分析題目 -- 1. 需要先查詢出每個部門的平均工資 -- 2. 根據 salgrade 表中的數據,獲取每個部門平均工資的等級 -- 這是所有的人 select * from emp; -- 按照部門分組 select deptno, avg(sal) from emp group by deptno; -- 結果: -- | DEPTNO | AVG(SAL) | -- | 30 | 1566.66667 | -- | 20 | 2258.33333 | -- | 10 | 2916.66667 | -- 跟 salgrade 表,雜交,總共 15 條結果 select * from (select deptno, avg(sal) sal from emp group by deptno) t, salgrade s; -- 過濾掉工資範圍不合適的數據 select * from (select deptno, avg(sal) sal from emp group by deptno) t, salgrade s where t.sal between s.losal and s.hisal; -- 結果就是這樣,就對了 -- | DEPTNO | SAL | GRADE | LOSAL | HISAL | -- | 10 | 2916.66667 | 4 | 2001 | 3000 | -- | 20 | 2258.33333 | 4 | 2001 | 3000 | -- | 30 | 1566.66667 | 3 | 1401 | 2000 | -- 需要將部門名稱顯示出來,再雜交->過濾一次就可以了 select * from (select deptno, avg(sal) sal from emp group by deptno) t, salgrade s, dept d where t.deptno = d.deptno and t.sal between s.losal and s.hisal; -- 最後的最後,設置顯示欄位 select dname, grade from (select deptno, avg(sal) sal from emp group by deptno) t, salgrade s, dept d where t.deptno = d.deptno and t.sal between s.losal and s.hisal; -- 最終結果,完美 --| DNAME | GRADE | --| ACCOUNTING | 4 | --| RESEARCH | 4 | --| SALES | 3 |
2.3 題庫三
- 查詢每個組最高工資的那些人
- 有下麵一個表,寫一條 sql 語句計算男女之差
gender number 男 46 女 10 - 給 emp 中的人加工資,請寫出相關語句:
條件 加多少 1000元以下 50% 2000元以下 30% 3000元以下 20% 其他 5% - 給 emp 中的人加工資,如上。但
1981/5/1之後來的所有人,只加2%, 請寫出語句。 - 計算你們從入學到現在過了多少個周末
- 計算你們從現在到畢業還有多少天,還有多少個周末
- 計算你們在學校的時間內,每天花費多少錢
查詢各種工作中的最低工資
看到最低、最大、平均之類的題目,首先想到的是分組函數的使用。
也就是 group by, having。
select job, min(sal) from emp group by job;
在芝加哥工作的人中,誰的工資最高
[題目] 從 scott 用戶的 emp/dept 表中,找到 “來自芝加哥最有錢的那個人” 。
首先,我們需要理清思路。
這裡總共有兩個條件:
- 這個人來自芝加哥
- 這個人是最有錢的,而且是芝加哥最有錢的
我們可以看出,第二個條件是依賴第一個條件的。
所以,分兩步查詢:
- 找出所有來自芝加哥的人
- 從這些人中,找到最有錢的那個。這一步,可以通過 max 函數或者 order by 方式實現。
下麵是語句示例:
---- 第一步:找到來自芝加哥的所有人。下麵兩種寫法等價: select e.* from emp e join dept d on (e.deptno=d.deptno) where d.loc='CHICAGO'; select e.* from emp e, dept d where d.deptno = e.deptno and d.loc='CHICAGO'; ---- 第二步,基於上面結果,篩選出最有錢的那個 -- 可以通過 max 函數 select e.* from emp e, dept d where e.deptno = d.deptno and d.loc='CHICAGO' and sal = (select max(sal) from emp e, dept d where e.deptno = d.deptno and d.loc='CHICAGO'); -- 可以通過 order by 方式 select ename from (select e.*, d.* from emp e, dept d where e.deptno = d.deptno and d.loc='CHICAGO' order by sal desc) where rownum = 1;
註意,實現的方式,不止上面的那些。但總體 思路 是一樣的。
所以,思路永遠是最重要的。
查詢所有員工工資都大於1000的部門的信息及員工信息
最核心的問題: 查詢出符合條件的部門編號。
第一種思路
1.查詢出所有的部門編號
select * from emp;
2.查詢出所有工資少於 1000 的人, 我們要把它所在的部門,從上面的結果中排除掉。
select deptno from emp where sal < 1000;
3.將上面查詢出的不符合條件的部門排除掉
select distinct deptno from emp where deptno not in (select deptno from emp where sal < 1000);
4.修改上面語句,增加最終的條件,查詢所有的其他信息
select d.dname, e.* from emp e join dept d on(e.deptno = d.deptno) where e.deptno not in (select deptno from emp where sal < 1000)
第二種思路
使用分組函數(group by / having)
分組函數主要用來統計分析。
一個完整的查詢語句如下,其中 group by 和 having 是用來分組和篩選分組。
select [欄位] from [表名] where [條件] group by [分組欄位] having [對分組結果進行篩選] order by [欄位]
示例:
select deptno, -- 分組欄位 count(*), -- 人數 sum(sal), -- 工資總和 avg(sal), -- 平均工資 max(sal), -- 最高工資 min(sal) -- 最低工資 from emp group by deptno -- 按照部門分組,進行統計 having avg(sal) > 2000; -- 只顯示平均工資大於 2000 的分組
那我們的題目的解決思路就是:
1.按照部門分組
select deptno from emp group by deptno;
2.篩選,排除最低工資小於 1000 的部門。 即:得到符合條件的部門的編號。
select deptno from emp group by deptno having min(sal) > 1000;
3.完善最終語句,得到最終結果。
select * from emp e, dept d where e.deptno = d.deptno and e.deptno in (select deptno from emp group by deptno having min(sal) > 1000);
查詢當月總共有多少個周五
首先,第一步,得到本月所有日期的結果集,兩種方式:
- 使用已有表的 rownum 構建
- 使用 oracle 的 connect by level 語句(結構化查詢)
得到有 n 條記錄的虛表:
select rownum from dba_objects where rownum < 32; select level from dual connect by level < 32;
將虛表轉化為我們需要的日期表:
select trunc(sysdate, 'MON') + rownum - 1 from dba_objects where rownum < 32; select trunc(sysdate, 'MON') + level - 1 from dual connect by level < 32;
其次,在上面結果集的基礎上進行篩選:
-- 1. select * from (select trunc(sysdate, 'MON') + rownum - 1 d from dba_objects where rownum < 32) where to_char(d, 'day') = '星期五' and d <= last_day(sysdate); -- 2. select * from (select trunc(sysdate, 'MON') + level - 1 d from dual connect by level < 32) where to_char(d, 'day') = '星期五' and d <= last_day(sysdate);
當然,你也可以將 last_day 這一段放到裡面:
select * from (select trunc(sysdate, 'MON') + level - 1 d from dual connect by level <= extract(day from last_day(sysdate))) where to_char(d, 'd') = 6;
3.管理系統
3.1 學生管理系統
根據我們學校的實際情況,請幫助設計一個學生管理系統。
比如, 學生,老師,班級,課程。按照你自己的設計,酌情增加。
基本步驟:
- 先用 e-r 圖,將實體的關係表述出來。
這樣的圖能幫助我們理清思路,並能幫助團隊間的有效交流。
一定在圖畫好之後再去著手資料庫表的創建。要秉承先設計後實現的思路。
你可以用一些知名的工具(如 visio)去畫,也可以手動在紙上畫。
- 根據設計好的圖,寫出相應的建表語句。
- 也可以進一步根據實體關係和表,創建相應的 Java 實體類。進一步可以 DAO,進一步可以 Service【可選】
- 最後,將圖跟語句一起上交。這個過程著重思考下項目從設計到編碼是怎麼一個過程。
需求分析 -> *概要設計* -> 詳細實現。
3.2 博客管理系統
首先,設計一個博客表(blog), 至少有下麵欄位
- id
- author
- title
- content(要求是 clob 類型)
- image(要求是 blob 類型)
- create_time
用 Java 完成基本的 =CRUD=,並掌握使用 PL/SQL 操作 blob/clob 的技巧。
4.體繫結構
Oracle 採取的是 Client/Server 架構。

客戶端(client)操作資料庫的請求發送後,服務端的監聽器(TNSListener)接收到請求,並將其轉發給相應的資料庫實例(Instance),再由實例(Instance)去操縱資料庫(Database)。 返回操作結果,是一個相反的過程。下麵是個簡陋的圖示:
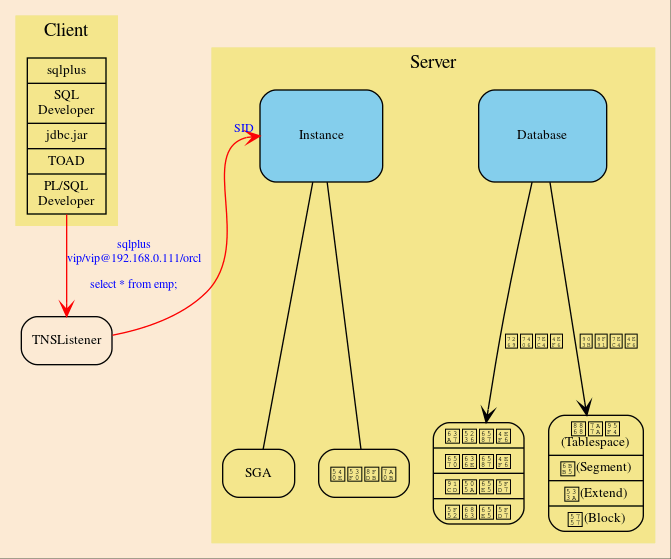
Client
Sqlplus
這是一個輕量級的功能強大的客戶端, 是 dba 必須掌握的工具。
用 sqlplus 連接資料庫的語法為:
# Usage: # sqlplus 用戶名/密碼@主機名:埠號/實例名 # 參數個數不是固定的 sqlplus # 會要求你輸入用戶名密碼,預設連接本地 ORACLE_SID 變數指定的資料庫 sqlplus vip # 會要求你輸入密碼 sqlplus vip/vip # 連接本地 ORACLE_SID 變數指定的資料庫 sqlplus sys/hello as sysdba # sys 用戶必須用 sysdba 或 sysoper 的身份登錄 sqlplus vip@192.168.0.111/orcl # 連接 192.168.0.111 機器上的 orcl 資料庫,用戶名為 vip sqlplus vip@192db # 連接 別名 為 192db 的資料庫
我們可以配置 sqlplus 的一些行為,兩個命令:
- show. 用來顯示配置參數
- set. 用來設置配置參數
比如:
show all -- 顯示所有配置參數 show lines -- 顯示 lines 的配置信息 show errors -- 顯示錯誤 set lines[ize] 333 -- 將行寬設置為 333 set pages[ize] 444 -- 將每頁的記錄數設置為 444 set echo off/on -- 導入外部文件,是否要顯示原始 sql 語句 set feedback on/off -- 是否顯示“查詢到xx數據”等信息 set timing on/off -- 是否顯示語句的執行時間 set autocommit on/off -- 是否啟用自動提交 set autotrace on/off -- 是否輸出執行計劃 set serveroutput on/off-- 是否顯示來自服務端的信息 column aaa format a22 -- 將列 'aaa' 的寬度限製為 22 個字幕'a'的大小。column 命令很強大,語句也複雜,此處不提。
在 sqlplus 中有緩衝區的概念:
緩衝區是用來記錄上一次執行的命令語句的空間。
我們可以通過一些列簡單命令,對上一次輸入的語句進行一些控制:
- 增
append/insert - 刪
delete - 改
change - 查
list - 執行修改後的語句
run或者/
例子:
list -- 顯示完整的緩存區 list 3 -- 顯示並定位到第三行 list 3 5 -- 顯示第三行到第五行的內容 list last -- 定位到最後一行
list 3 del -- 刪除第三行
list 3 append order by sal -- 定位到第三行,然後追加 order by sal insert order by sal -- 開啟新的一行,插入 order by sal
還有其他一些命令:
get D:\aaa.sql -- 將文件載入到緩衝區,但不執行 start D:\aaa.sql -- 將文件載入到緩衝區,並且執行 @D:\aaa.sql -- 是上面一條語句的簡寫形式 save D:\bbb.sql -- 將緩衝區的內容保存到文件中 edit -- 調用外部編輯器,編輯緩衝區 clear screen -- 清空緩衝區
show user -- 顯示當前用戶 show parameters -- 顯示 oracle 的配置參數 show parameters nls -- 顯示 oracle 中所有跟語言配置相關的一些參數 describe emp -- 顯示 emp 表的結構信息
JDBC
用 Java 連接資料庫,需要用到 jdbc 驅動,它們可以在下麵目錄中找到:
主目錄\product\12.1.0\dbhome_1\jdbc\lib\*.jar
比如 ojdbc7_g.jar, 7 表示適用於 JDK 版本 1.7, g 表示自帶更多調試信息。
TNSListener
TNSListener,是用來監聽來自客戶端的請求,並將其轉發給相對應的服務端實例的一種後臺服務。
它是溝通客戶端與服務端的一個橋梁。
比如,下麵用 sqlplus 客戶端將會連接 localhost 上的 orcl 資料庫:
sqlplus vip/vip@localhost/orcl
請求會發送到 localhost 主機的 1521 號埠, 作為監聽的 TNSListener 收到這個請求後,再把請求轉發給對應的 orcl 資料庫實例。
所以必須開啟監聽服務,並且配置正確,才能連接操作資料庫。
註:如果用 sqlplus vip/vip 的方式連接資料庫,即沒有指定連接的機器,那麼預設連接的是本機資料庫 這種連接是不需要監聽服務的,因為為了增加連接速度,這樣的本地連接 oracle 會使用一個專用的進程直接連接實例
我們可以使用 Oracle 提供的 lsnrctl 命令操縱監聽服務的開啟或關閉:
lsnrctl status # 查看狀態
lsnrctl stop # 停止監聽服務
lsnrctl start # 開啟監聽服務
lsnrctl reload # 重啟監聽服務
lsnrctl services # 查看監聽的連接情況
我們可以使用 Oracle 的 Net Manager 工具來配置自己的監聽器。
實質上,用 Net Manager 配置跟直接修改下麵文件的作用是一樣的:
主目錄\product\12.1.0\dbhome_1\network\admin\listener.ora
我們在 Net Manager 中對 listener 的配置對應的是這一段代碼:
LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 0.0.0.0)(PORT = 1521)) ) ... )
只要修改其中的 host/port 等,重啟監聽服務即可。
Server
Oracle 服務端分為兩部分:
Instance實例Database資料庫
實例(Instance)
實例, 又稱為資料庫引擎,由 SGA(System Global Area, 系統全局區) 和 一系列後臺進程 組成。 它需要啟動才會生成,用來載入並管理一個資料庫。
服務啟動的大致過程:
- [讀取] 讀取系統的 ORACLE_SID 環境變數,確定要啟動的實例名字,比如為 xxoo
- [載入] 從
$ORABASE/admin/xxoo和$ORA_HOME/database/SPFILEXXOO.ora等位置載入相關配置文件。配置文件的名字是根據 sid 來定義的。 - [啟動] 從配置文件中,讀取相關信息,比如資料庫名字、資料庫控制文件位置、SGA 等信息,並根據這些,初始化資料庫載入需要的
記憶體空間(SGA)和相關進程。 - [裝載] 根據配置文件中讀取的資料庫信息,找到各種數據文件位置,並裝載資料庫。
- [啟動] 進行數據校驗等,如果沒有問題,啟動資料庫。
可以通過查看啟動過程協助理解:
-- 首先,登錄 sys 用戶,只有管理員才有完全操縱資料庫的權力 -- shutdown 用來關閉。如果不帶參數,預設為 normal ---- immediate 表示立即關閉,如果有未處理完操作,回滾並斷開 ---- normal 表示等待所有連接斷開才關閉資料庫 ---- 其他參數,略 shutdown immediate; -- 啟動資料庫,分解為三個動作: ---- 啟動實例 ---- 利用啟動的實例去掛載資料庫 ---- 校驗並打開資料庫 -- 只有完全打開,才能進行完全的數據操作 -- 也可以指定參數,啟動到某個階段。這是在維護資料庫中使用的命令。 startup -- 如果不加參數, startup nomount -- 啟動到 nomount 階段 startup mount -- 啟動到 mount 階段 -- 當然,也可以這樣分步啟動: startup nomount alter database mount alter database open
資料庫(Database)
資料庫, 是保存在硬碟上的文件集合,它是數據的主要載體。
$OracleBase\oradata\[資料庫名字]\
可以從不同的角度去認識資料庫,比如物理/邏輯角度:
物理組件
資料庫是保存在操作系統的一系列文件。
預設安裝情況下,這些文件都在 $ORACLE_BASE/oradata 文件夾下:
oradata/ └── orcl [資料庫的名字] ├── CONTROL01.CTL ├── CONTROL02.CTL ├── EXAMPLE01.DBF ├── REDO01.LOG ├── REDO02.LOG ├── REDO03.LOG ├── SYSAUX01.DBF ├── SYSTEM01.DBF ├── TEMP01.DBF ├── UNDOTBS01.DBF └── USERS01.DBF
從文件角度分析,一個資料庫包含下麵幾類(組件):
- 控制文件(control file)。記錄資料庫的物理結構和其他信息,如資料庫名稱、各種文件位置等。多副本。
select * from v$controlfile;
- 數據文件(data file)。用來存儲數據的文件,會自動擴張。數據以塊為單位進行保存。
select name, status, enabled from v$datafile;
- 重做日誌文件(redo log)。用來記錄用戶的所有操作,為了備份恢復。 一個資料庫至少有兩個日誌組,每個日誌組至少有一個成員,成員之間是鏡像關係。 用戶的操作會記錄到 redo log 中,當一個組記錄滿了,會自動切換到下一個組。輪流迴圈。
-- 需要理解 Oracle 日誌的思路: -- 它採取了【多個分組,輪流迴圈寫入;每組多成員,互為鏡像;保存更多信息,使用歸檔模式】的方式,保證了記錄安全性。 -- 在生產環境中,需要日誌調整到不同的磁碟中,這樣,即使某個文件損壞,或某塊磁碟損壞,都可以通過鏡像的日誌文件對數據進行恢復。 -- 查看 redo log 日誌組 select * from v$log; select * from v$logfile; -- 增加/刪除 日誌組 alter database add logfile 'd:/sss.rlog' size 100m; alter database drop logfile 'd:/sss.rlog'; -- 清空日誌組 alter database clear logfile group 1; alter database clear unarchived logfile group 1; -- 為日誌組 增加/刪除 成員 alter database add logfile member 'd:/ssss.log' to group 1; alter database drop logfile member 'd:/ssss.log'; -- 重命名文件 -- 首先,在文件夾管理器里,將文件改名,比如,改為 ssss.redolog -- 其次,重啟資料庫到 mount 狀態,然後執行重命名命令 alter database rename file 'd:/ssss.log' to 'd:/ssss.redolog'; -- 日誌組一般是在寫滿的時候自動切換。 -- 我們也可以手動切換 alter system switch logfile;
- 歸檔日誌文件。是重做日誌的補充(redo log 記錄的記錄是有限的),可以把寫滿的 redo log 進行備份。
-- Oracle 的歸檔模式預設是關閉的 -- 歸檔模式會占用大量空間 -- 但他們用更多的空間,保存更多的歷史記錄,保障更大的安全性 -- 查看狀態 archive log list; -- 切換資料庫到歸檔模式 alter database archivelog; -- 啟動 archive log start; -- 查看狀態 archive log list;
- 其他文件
邏輯組件
https://docs.oracle.com/cd/B28359_01/server.111/b28318/physical.htm#CNCPT1082
從 Oracle 內部管理數據的角度,可以將 Oracle 分為4個組件:
- 表空間(tablespace)
- 最基本的邏輯結構,是 Oracle 中進行數據恢復的最小單位,容納著表、索引等對象
- 資料庫是由若幹表空間組成的。一個表空間至少對應一個物理文件。
- 實際開發中,不建議使用預設表空間。請為自己的業務創建自己的表空間。
-- 內置的各種表空間 ---- system/sysaux 系統表空間/系統輔助表空間,用來保存系統字典表和其他信息,資料庫創建完會自動生成 ---- users 用戶表空間,創建新用戶時,預設使用的表空間 ---- temp 臨時表空間 ---- undo 回滾表空間 -- 查看表空間信息 select * from v$tablespace; -- 查看所有表空間跟文件對應關係 SELECT FILE_NAME, BLOCKS, TABLESPACE_NAME from dba_data_files; -- 創建表空間 create tablespace xxx datafile 'D:/sss.dbf' size 50m autoextend on next 50m maxsize 1024m; -- 創建臨時表空間 create temporary tablespace yyy tempfile 'D:/ANOTHER_TMP.dbf' size 5m; -- 刪除表空間 drop tablespace xxx;
- 段(Segment)
- 段是對象在資料庫中占用的空間
- 包括索引段、數據段等
- 表空間被劃分為若幹區域,每個區域負責存放不同類型數據,這些區域這就是段
- 區(Extend)
- 由連續的數據塊組成,由 Oracle 自動分配管理
- 會自動擴展大小
- 塊(Block)
- 數據塊是 Oracle 資料庫最小的邏輯單元
- 它代表在讀寫操作的時候,每次處理的數據大小是多少
- 正常情況下,它是操作系統塊的整數倍,預設是 8 KB
- 可以通過參數 db_block_size 控制
show parameters block;

用戶許可權
安裝完 Oracle,預設有兩個用戶:
SYS用戶,又叫資料庫系統管理員、特權用戶,資料庫中至高無上的存在。- 它是資料庫的系統管理員,負責資料庫的安裝、維護、升級、備份、恢復、優化等操作。
- 在它之下,保存著資料庫所有的系統字典。
- 不能用 normal 身份登錄,必須用 SYSDBA/SYSOPER 身份登錄。
SYSTEM用戶,資料庫管理員,它擁有 DBA 角色,主要負責對資料庫中各種對象,各種資源的管理。SCOTT用戶,一個示例用戶,預設是鎖定的,需要解鎖使用。
新創建的用戶,是不能做任何事情的(甚至不能登錄)。 必須要為用戶授予許可權,才能做相應的事情。 可以說,用戶是許可權的容器。
許可權分為兩種:

用戶(User)
用戶是用於 資源管理 和 許可權控制 的一


