
前面我們已經接觸過幾種數據結構了,有數組、鏈表、Hash表、紅黑樹(二叉查詢樹),今天再來看另外一種數據結構:棧。 什麼是棧呢,我就不找它具體的定義了,直接舉個例子,棧就相當於一個很窄的木桶,我們往木桶里放東西,往外拿東西時會發現,我們最開始放的東西在最底部,最先拿出來的是剛剛放進去的。所以,...
前面我們已經接觸過幾種數據結構了,有數組、鏈表、Hash表、紅黑樹(二叉查詢樹),今天再來看另外一種數據結構:棧。 什麼是棧呢,我就不找它具體的定義了,直接舉個例子,棧就相當於一個很窄的木桶,我們往木桶里放東西,往外拿東西時會發現,我們最開始放的東西在最底部,最先拿出來的是剛剛放進去的。所以,棧就是這麼一種先進後出( First In Last Out,或者叫後進先出) 的容器,它只有一個口,在這個口放入元素,也在這個口取出元素。
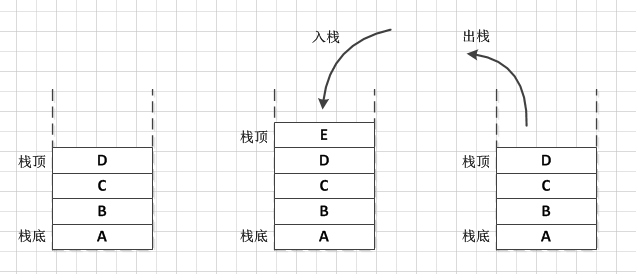 棧最主要了兩個動作就是入棧和出棧操作,其實還是很容易的明白的對不對,那麼我們接下來就看一下Jdk容器中的棧Stack是怎麼實現的吧。
1.定義
棧最主要了兩個動作就是入棧和出棧操作,其實還是很容易的明白的對不對,那麼我們接下來就看一下Jdk容器中的棧Stack是怎麼實現的吧。
1.定義
1 public 2 class Stack<E> extends Vector<E> {
我們發現Stack繼承了Vector,Vector又是什麼東東呢,看一下。
1 public class Vector<E> 2 extends AbstractList<E> 3 implements List<E>, RandomAccess, Cloneable, java.io.Serializable
發現沒有,Vector是List的一個實現類,其實Vector也是一個基於數組實現的List容器,其功能及實現代碼和ArrayList基本上是一樣的。那麼不一樣的是什麼地方的,一個是數組擴容的時候,Vector是*2,ArrayList是*1.5+1;另一個就是Vector是線程安全的,而ArrayList不是,而Vector線程安全的做法是在每個方法上面加了一個synchronized關鍵字來保證的。但是這裡說一句,Vector已經不官方的(大家公認的)不被推薦使用了,正式因為其實現線程安全方式是鎖定整個方法,導致的是效率不高,那麼有沒有更好的提到方案呢,其實也不能說有,但是還真就有那麼一個,Collections.synchronizedList(),這不是我們今天的重點不做深入探討,回到Stack的實現上。
2.Stack&Vector底層存儲 由於Stack是繼承和基於Vector,那麼簡單看一下Vector的一些定義和方法源碼:
1 // 底層使用數組存儲數據 2 protected Object[] elementData; 3 // 元素個數 4 protected int elementCount ; 5 // 自定義容器擴容遞增大小 6 protected int capacityIncrement ; 7 8 public Vector( int initialCapacity, int capacityIncrement) { 9 super(); 10 // 越界檢查 11 if (initialCapacity < 0) 12 throw new IllegalArgumentException( "Illegal Capacity: " + 13 initialCapacity); 14 // 初始化數組 15 this.elementData = new Object[initialCapacity]; 16 this.capacityIncrement = capacityIncrement; 17 } 18 19 // 使用synchronized關鍵字鎖定方法,保證同一時間內只有一個線程可以操縱該方法 20 public synchronized boolean add(E e) { 21 modCount++; 22 // 擴容檢查 23 ensureCapacityHelper( elementCount + 1); 24 elementData[elementCount ++] = e; 25 return true; 26 } 27 28 private void ensureCapacityHelper(int minCapacity) { 29 // 當前元素數量 30 int oldCapacity = elementData .length; 31 // 是否需要擴容 32 if (minCapacity > oldCapacity) { 33 Object[] oldData = elementData; 34 // 如果自定義了容器擴容遞增大小,則按照capacityIncrement進行擴容,否則按兩倍進行擴容(*2) 35 int newCapacity = (capacityIncrement > 0) ? 36 (oldCapacity + capacityIncrement) : (oldCapacity * 2); 37 if (newCapacity < minCapacity) { 38 newCapacity = minCapacity; 39 } 40 // 數組copy 41 elementData = Arrays.copyOf( elementData, newCapacity); 42 } 43 }Vector就簡單看到這裡,其他方法Stack如果沒有調用的話就不進行分析了,不明白的可以去看ArrayList源碼解析。 3.peek()——獲取棧頂的對象
1 /** 2 * 獲取棧頂的對象,但是不刪除 3 */ 4 public synchronized E peek() { 5 // 當前容器元素個數 6 int len = size(); 7 8 // 如果沒有元素,則直接拋出異常 9 if (len == 0) 10 throw new EmptyStackException(); 11 // 調用elementAt方法取出數組最後一個元素(最後一個元素在棧頂) 12 return elementAt(len - 1); 13 } 14 15 /** 16 * 根據index索引取出該位置的元素,這個方法在Vector中 17 */ 18 public synchronized E elementAt(int index) { 19 // 越界檢查 20 if (index >= elementCount ) { 21 throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount); 22 } 23 24 // 直接通過數組下標獲取元素 25 return (E)elementData [index]; 26 }
4.pop()——彈棧(出棧),獲取棧頂的對象,並將該對象從容器中刪除
1 /** 2 * 彈棧,獲取並刪除棧頂的對象 3 */ 4 public synchronized E pop() { 5 // 記錄棧頂的對象 6 E obj; 7 // 當前容器元素個數 8 int len = size(); 9 10 // 通過peek()方法獲取棧頂對象 11 obj = peek(); 12 // 調用removeElement方法刪除棧頂對象 13 removeElementAt(len - 1); 14 15 // 返回棧頂對象 16 return obj; 17 } 18 19 /** 20 * 根據index索引刪除元素 21 */ 22 public synchronized void removeElementAt(int index) { 23 modCount++; 24 // 越界檢查 25 if (index >= elementCount ) { 26 throw new ArrayIndexOutOfBoundsException(index + " >= " + 27 elementCount); 28 } 29 else if (index < 0) { 30 throw new ArrayIndexOutOfBoundsException(index); 31 } 32 // 計算數組元素要移動的個數 33 int j = elementCount - index - 1; 34 if (j > 0) { 35 // 進行數組移動,中間刪除了一個,所以將後面的元素往前移動(這裡直接移動將index位置元素覆蓋掉,就相當於刪除了) 36 System. arraycopy(elementData, index + 1, elementData, index, j); 37 } 38 // 容器元素個數減1 39 elementCount--; 40 // 將容器最後一個元素置空(因為刪除了一個元素,然後index後面的元素都向前移動了,所以最後一個就沒用了 ) 41 elementData[elementCount ] = null; /* to let gc do its work */ 42 }
5.push(E item)——壓棧(入棧),將對象添加進容器並返回
1 /** 2 * 將對象添加進容器並返回 3 */ 4 public E push(E item) { 5 // 調用addElement將元素添加進容器 6 addElement(item); 7 // 返回該元素 8 return item; 9 } 10 11 /** 12 * 將元素添加進容器,這個方法在Vector中 13 */ 14 public synchronized void addElement(E obj) { 15 modCount++; 16 // 擴容檢查 17 ensureCapacityHelper( elementCount + 1); 18 // 將對象放入到數組中,元素個數+1 19 elementData[elementCount ++] = obj; 20 }
6.search(Object o)——返回對象在容器中的位置,棧頂為1
1 /** 2 * 返回對象在容器中的位置,棧頂為1 3 */ 4 public synchronized int search(Object o) { 5 // 從數組中查找元素,從最後一次出現 6 int i = lastIndexOf(o); 7 8 // 因為棧頂算1,所以要用size()-i計算 9 if (i >= 0) { 10 return size() - i; 11 } 12 return -1; 13 }
7.empty()——容器是否為空
1 /** 2 * 檢查容器是否為空 3 */ 4 public boolean empty() { 5 return size() == 0; 6 }到這裡Stack的方法就分析完成了,由於Stack最終還是基於數組的,理解起來還是很容易的(因為有了ArrayList的基礎啦)。 雖然jdk中Stack的源碼分析完了,但是這裡有必要討論下,不知道是否發現這裡的Stack很奇怪的現象, (1)Stack為什麼是基於數組實現的呢? 我們都知道數組的特點:方便根據下標查詢(隨機訪問),但是記憶體固定,且擴容效率較低。很容易想到Stack用鏈表實現最合適的。 (2)Stack為什麼是繼承Vector的? 繼承也就意味著Stack繼承了Vector的方法,這使得Stack有點不倫不類的感覺,既是List又是Stack。如果非要繼承Vector合理的做法應該是什麼:Stack不繼承Vector,而只是在自身有一個Vector的引用,聚合對不對? 唯一的解釋呢,就是Stack是jdk1.0出來的,那個時候jdk中的容器還沒有ArrayList、LinkedList等只有Vector,既然已經有了Vector且能實現Stack的功能,那麼就乾吧。。。 既然用鏈表實現Stack是比較理想的,那麼我們就來嘗試一下吧:
1 import java.util.LinkedList; 2 3 public class LinkedStack<E> { 4 5 private LinkedList<E> linked ; 6 7 public LinkedStack() { 8 this.linked = new LinkedList<E>(); 9 } 10 11 public E push(E item) { 12 this.linked .addFirst(item); 13 return item; 14 } 15 16 public E pop() { 17 if (this.linked.isEmpty()) { 18 return null; 19 } 20 return this.linked.removeFirst(); 21 } 22 23 public E peek() { 24 if (this.linked.isEmpty()) { 25 return null; 26 } 27 return this.linked.getFirst(); 28 } 29 30 public int search(E item) { 31 int i = this.linked.indexOf(item); 32 return i + 1; 33 } 34 35 public boolean empty() { 36 return this.linked.isEmpty(); 37 } 38 }看完後,你說我cha,為什麼這麼簡單,就這麼點代碼。因為這裡使用的LinkedList實現的Stack,記得在LinkedList中說過,LinkedList實現了Deque介面使得它既可以作為棧(先進後出),又可以作為隊列(先進先出)。那麼什麼是隊列呢?Queue見吧! Stack&Vector 完! 參見: 給jdk寫註釋系列之jdk1.6容器(1)-ArrayList源碼解析 給jdk寫註釋系列之jdk1.6容器(2)-LinkedList源碼解析


