
前面的話 集合、字典和散列表可以存儲不重覆的值。在集合中,我們感興趣的是每個值本身,並把它當作主要元素。在字典中,我們用[鍵,值]的形式來存儲數據。在散列表中也是一樣(也是以[鍵,值]對的形式來存儲數據)。但是兩種數據結構的實現方式略有不同,本文將詳細介紹字典和散列表這兩種數據結構 字典 集合表示一 ...
前面的話
集合、字典和散列表可以存儲不重覆的值。在集合中,我們感興趣的是每個值本身,並把它當作主要元素。在字典中,我們用[鍵,值]的形式來存儲數據。在散列表中也是一樣(也是以[鍵,值]對的形式來存儲數據)。但是兩種數據結構的實現方式略有不同,本文將詳細介紹字典和散列表這兩種數據結構
字典
集合表示一組互不相同的元素(不重覆的元素)。在字典中,存儲的是[鍵,值]對,其中鍵名是用來查詢特定元素的。字典和集合很相似,集合以[值,值]的形式存儲元素,字典則是以[鍵,值]的形式來存儲元素。字典也稱作映射
【創建字典】
與Set類相似,ECMAScript 6同樣包含了一個Map類的實現,即我們所說的字典
下麵將要實現的類就是以ECMAScript 6中Map類的實現為基礎的。它和Set類很相似(但不同於存儲[值,值]對的形式,我們將要存儲的是[鍵,值]對)
這是我們的Dictionary類的骨架:
function Dictionary() { var items = {}; }
與Set類類似,我們將在一個Object的實例而不是數組中存儲元素。 然後,我們需要聲明一些映射/字典所能使用的方法
set(key,value):向字典中添加新元素。 remove(key):通過使用鍵值來從字典中移除鍵值對應的數據值。 has(key):如果某個鍵值存在於這個字典中,則返回true,反之則返回false。 get(key):通過鍵值查找特定的數值並返回。 clear():將這個字典中的所有元素全部刪除。 size():返回字典所包含元素的數量。與數組的length屬性類似。 keys():將字典所包含的所有鍵名以數組形式返回。 values():將字典所包含的所有數值以數組形式返回。
【has】
首先來實現has(key)方法。之所以要先實現這個方法,是因為它會被set和remove等其他方法調用。這個方法的實現和之前在Set類中的實現是一樣的。使用JavaScript中的in操作符來驗證一個key是否是items對象的一個屬性。可以通過如下代碼來實現:
this.has = function(key) { return key in items; }
【set】
該方法接受一個key和一個value作為參數。我們直接將value設為items對象的key屬性的值。它可以用來給字典添加一個新的值,或者用來更新一個已有的值
this.set = function(key, value) { items[key] = value; //{1} }
【remove】
它和Set類中的remove方法很相似,唯一的不同點在於我們將先搜索key(而不是value),然後我們可以使用JavaScript的delete操作符來從items對象中移除key屬性
this.remove = function(key) { if (this.has(key)) { delete items[key]; return true; } return false; }
【get】
get方法首先會驗證我們想要檢索的值是否存在(通過查找key值),如果存在,將返回該值, 反之將返回一個undefined值
this.get = function(key) { return this.has(key) ? items[key] : undefined; };
【values】
首先,我們遍歷items對象的所有屬性值(行{1})。為了確定值存在,我們使用has函數來驗證key確實存在,然後將它的值加入values數組(行{2})。最後,我們就能返回所有找到的值。這個方法以數組的形式返回字典中所有values實例的值:
this.values = function() { var values = {}; for (var k in items) { //{1} if (this.has(k)) { values.push(items[k]); //{2} } } return values; };
【clear】
this.clear = function(){ items = {}; };
【size】
this.size = function(){ return Object.keys(items).length; };
【keys】
keys方法返回在Dictionary類中所有用於標識值的鍵名。要取出一個JavaScript對象中所有的鍵名,可以把這個對象作為參數傳入Object類的keys方法,如下:
this.keys = function() { return Object.keys(items); };
【items】
下麵來驗證items屬性的輸出值。我們可以實現一個返回items變數的方法,叫作getItems:
this.getItems = function() { return items; }
【完整代碼】
Dictionary類的完整代碼如下所示
function Dictionary(){ var items = {}; this.set = function(key, value){ items[key] = value; //{1} }; this.delete = function(key){ if (this.has(key)){ delete items[key]; return true; } return false; }; this.has = function(key){ return items.hasOwnProperty(key); //return value in items; }; this.get = function(key) { return this.has(key) ? items[key] : undefined; }; this.clear = function(){ items = {}; }; this.size = function(){ return Object.keys(items).length; }; this.keys = function(){ return Object.keys(items); }; this.values = function(){ var values = []; for (var k in items) { if (this.has(k)) { values.push(items[k]); } } return values; }; this.each = function(fn) { for (var k in items) { if (this.has(k)) { fn(k, items[k]); } } }; this.getItems = function(){ return items; } }
【使用Dictionary類】
首先,我們來創建一個Dictionary類的實例,然後給它添加三條電子郵件地址。我們將會使用這個dictionary實例來實現一個電子郵件地址簿。使用我們創建的類來執行如下代碼:
var dictionary = new Dictionary(); dictionary.set('Gandalf', '[email protected]'); dictionary.set('John', '[email protected]'); dictionary.set('Tyrion', '[email protected]');
如果執行瞭如下代碼,輸出結果將會是true:
console.log(dictionary.has('Gandalf'));
下麵的代碼將會輸出3,因為我們向字典實例中添加了三個元素:
console.log(dictionary.size());
現在,執行下麵的幾行代碼:
console.log(dictionary.keys()); console.log(dictionary.values()); console.log(dictionary.get('Tyrion'));
輸出結果分別如下所示:
["Gandalf", "John", "Tyrion"] ["[email protected]", "[email protected]", "[email protected]"] [email protected]
最後,再執行幾行代碼:
dictionary.remove('John');
再執行下麵的代碼:
console.log(dictionary.keys());
console.log(dictionary.values());
console.log(dictionary.getItems());
輸出結果如下所示:
["Gandalf", "Tyrion"] ["[email protected]", "[email protected]"] Object {Gandalf: "[email protected]", Tyrion: "[email protected]"}
移除了一個元素後,現在的dictionary實例中只包含兩個元素了
散列表
下麵將詳細介紹HashTable類,也叫HashMap類,是Dictionary類的一種散列表實現方式
散列演算法的作用是儘可能快地在數據結構中找到一個值。如果要在數據結構中獲得一個值(使用get方法),需要遍歷整個數據結構來找到它。如果使用散列函數,就知道值的具體位置,因此能夠快速檢索到該值。散列函數的作用是給定一個鍵值,然後返回值在表中的地址
舉個例子,我們繼續使用在前面使用的電子郵件地址簿。我們將要使用最常見的散列函數——“lose lose”散列函數,方法是簡單地將每個鍵值中的每個字母的ASCII值相加
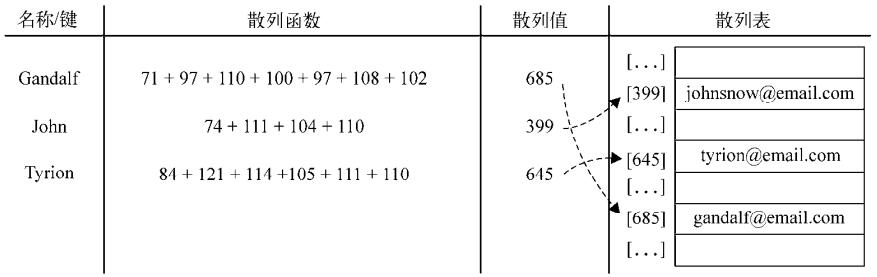
【創建散列表】
我們將使用數組來表示我們的數據結構,從搭建類的骨架開始:
function HashTable(){ var table = []; }
然後,給類添加一些方法。我們給每個類實現三個基礎的方法
put(key,value):向散列表增加一個新的項(也能更新散列表)。 remove(key):根據鍵值從散列表中移除值。 get(key):返回根據鍵值檢索到的特定的值。
在實現這三個方法之前,要實現的第一個方法是散列函數,它是HashTable類中的一個私有方法:
var loseloseHashCode = function (key) { var hash = 0; //{1} for (var i = 0; i < key.length; i++) { //{2} hash += key.charCodeAt(i); //{3} } return hash % 37; //{4} };
給定一個key參數,就能根據組成key的每個字元的ASCII碼值的和得到一個數字。所以,首先需要一個變數來存儲這個總和(行{1})。然後,遍歷key(行{2})並將從ASCII表中查到的每個字元對應的ASCII值加到hash變數中(可以使用JavaScript的String類中的charCodeAt方法——行{3})。最後,返回hash值。為了得到比較小的數值,我們會使用hash值和一個任意數做除法的餘數(mod)
【put】
現在,有了散列函數,我們就可以實現put方法了:
this.put = function(key, value) { var position = loseloseHashCode(key); //{5} console.log(position + ' - ' + key); //{6} table[position] = value; //{7} };
首先,根據給定的key和所創建的散列函數計算出它在表中的位置(行{5})。為了便於展示信息,我們將計算出的位置輸出至控制台(行{6})。由於它不是必需的,我們也可以將這行代碼移除。然後要做的,是將value參數添加到用散列函數計算出的對應的位置上(行{7})
【get】
從HashTable實例中查找一個值也很簡單。為此,將會實現一個get方法。首先,我們會使用所創建的散列函數來求出給定key所對應的位置。這個函數會返回值的位置,因此我們所要做的就是根據這個位置從數組table中獲得這個值。
this.get = function (key) { return table[loseloseHashCode(key)]; };
【remove】
要從HashTable實例中移除一個元素,只需要求出元素的位置(可以使用散列函數來獲取)並賦值為undefined。
對於HashTable類來說,我們不需要像ArrayList類一樣從table數組中將位置也移除。由於元素分佈於整個數組範圍內,一些位置會沒有任何元素占據,並預設為undefined值。我們也不能將位置本身從數組中移除(這會改變其他元素的位置),否則,當下次需要獲得或移除一個元素的時候,這個元素會不在我們用散列函數求出的位置上
this.remove = function(key) { table[loseloseHashCode(key)] = undefined; };
【完整代碼】
HashTable類的完整代碼如下所示
function HashTable() { var table = []; var loseloseHashCode = function (key) { var hash = 0; for (var i = 0; i < key.length; i++) { hash += key.charCodeAt(i); } return hash % 37; }; var djb2HashCode = function (key) { var hash = 5381; for (var i = 0; i < key.length; i++) { hash = hash * 33 + key.charCodeAt(i); } return hash % 1013; }; var hashCode = function (key) { return loseloseHashCode(key); }; this.put = function (key, value) { var position = hashCode(key); console.log(position + ' - ' + key); table[position] = value; }; this.get = function (key) { return table[hashCode(key)]; }; this.remove = function(key){ table[hashCode(key)] = undefined; }; this.print = function () { for (var i = 0; i < table.length; ++i) { if (table[i] !== undefined) { console.log(i + ": " + table[i]); } } }; }
【使用HashTable類】
下麵執行一些代碼來測試HashTable類:
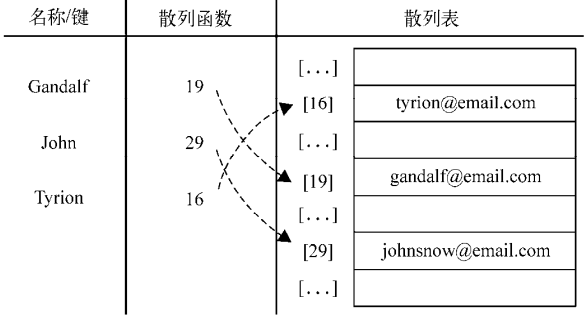
var hash = new HashTable(); hash.put('Gandalf', '[email protected]'); hash.put('John', '[email protected]'); hash.put('Tyrion', '[email protected]');
執行上述代碼,會在控制臺中獲得如下輸出:
19 - Gandalf 29 - John 16 - Tyrion
下麵的圖表展現了包含這三個元素的HashTable數據結構:
現在來測試get方法:
console.log(hash.get('Gandalf')); console.log(hash.get('Loiane'));
獲得如下的輸出:
[email protected]
undefined
由於Gandalf是一個在散列表中存在的鍵,get方法將會返回它的值。而由於Loiane是一個不存在的鍵,當我們試圖在數組中根據位置獲取值的時候(一個由散列函數生成的位置),返回值將會是undefined(即不存在)
然後,我們試試從散列表中移除Gandalf:
hash.remove('Gandalf'); console.log(hash.get('Gandalf'));
由於Gandalf不再存在於表中,hash.get('Gandalf')方法將會在控制臺上給出undefined的輸出結果
【散列集合】
在一些編程語言中,還有一種叫作散列集合的實現。散列集合由一個集合構成,但是插入、移除或獲取元素時,使用的是散列函數。我們可以重用本章中實現的所有代碼來實現散列集合,不同之處在於,不再添加鍵值對,而是只插入值而沒有鍵。例如,可以使用散列集合來存儲所有的英語單詞(不包括它們的定義)。和集合相似,散列集合只存儲唯一的不重覆的值
處理衝突
有時候,一些鍵會有相同的散列值。不同的值在散列表中對應相同位置的時候,我們稱其為衝突。例如,我們看看下麵的代碼會得到怎樣的輸出結果:
var hash = new HashTable(); hash.put('Gandalf', '[email protected]'); hash.put('John', '[email protected]'); hash.put('Tyrion', '[email protected]'); hash.put('Aaron', '[email protected]'); hash.put('Donnie', '[email protected]'); hash.put('Ana', '[email protected]'); hash.put('Jonathan', '[email protected]'); hash.put('Jamie', '[email protected]'); hash.put('Sue', '[email protected]'); hash.put('Mindy', '[email protected]'); hash.put('Paul', '[email protected]'); hash.put('Nathan', '[email protected]');
輸出結果如下:
19 - Gandalf 29 - John 16 - Tyrion 16 - Aaron 13 - Donnie 13 - Ana 5 - Jonathan 5 - Jamie 5 - Sue 32 - Mindy 32 - Paul 10 – Nathan
Tyrion和Aaron有相同的散列值(16)。Donnie和Ana有相同的散列值(13),Jonathan、Jamie和Sue有相同的散列值(5),Mindy和Paul也有相同的散列值(32)
那HashTable實例會怎樣呢?執行之前的代碼後散列表中會有哪些值呢?為了獲得結果,我們來實現一個叫作print的輔助方法,它會在控制臺上輸出HashTable中的值:
this.print = function() { for (var i = 0; i < table.length; ++i) { //{1} if (table[i] !== undefined) { //{2} console.log(i + ": " + table[i]);//{3} } } };
首先,遍曆數組中的所有元素(行{1})。當某個位置上有值的時候(行{2}),會在控制臺上輸出位置和對應的值(行{3})。現在來使用這個方法:
hash.print();
在控制臺上得到如下的輸出結果:
5:[email protected] 10:[email protected] 13:[email protected] 16:[email protected] 19:[email protected] 29:[email protected] 32:[email protected]
Jonathan、Jamie和Sue有相同的散列值,也就是5。由於Sue是最後一個被添加的,Sue將是在HashTable實例中占據位置5的元素。首先,Jonathan會占據這個位置,然後Jamie會覆蓋它,然後Sue會再次覆蓋。這對於其他發生衝突的元素來說也是一樣的。
使用一個數據結構來保存數據的目的顯然不是去丟失這些數據,而是通過某種方法將它們全部保存起來。因此,當這種情況發生的時候就要去解決它。處理衝突有幾種方法:分離鏈接、線性探查和雙散列法
【分離鏈接】
分離鏈接法包括為散列表的每一個位置創建一個鏈表並將元素存儲在裡面。它是解決衝突的最簡單的方法,但是它在HashTable實例之外還需要額外的存儲空間
例如,我們在之前的測試代碼中使用分離鏈接的話,輸出結果將會是這樣:
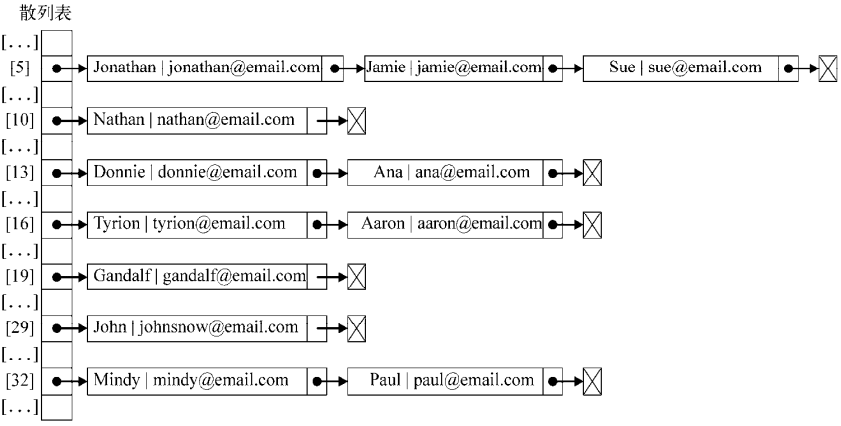
在位置5上,將會有包含三個元素的LinkedList實例;在位置13、16和32上,將會有包含兩個元素的LinkedList實例;在位置10、19和29上,將會有包含單個元素的LinkedList實例
對於分離鏈接和線性探查來說,只需要重寫三個方法:put、get和remove。這三個方法在每種技術實現中都是不同的
為了實現一個使用了分離鏈接的HashTable實例,我們需要一個新的輔助類來表示將要加入LinkedList實例的元素。我們管它叫ValuePair類(在HashTable類內部定義):
var ValuePair = function(key, value){ this.key = key; this.value = value; this.toString = function() { return '[' + this.key + ' - ' + this.value + ']'; } };
這個類只會將key和value存儲在一個Object實例中。我們也重寫了toString方法,以便之後在瀏覽器控制臺中輸出結果
我們來實現第一個方法,put方法,代碼如下:
this.put = function(key, value){ var position = loseloseHashCode(key); if (table[position] == undefined) { //{1} table[position] = new LinkedList(); } table[position].append(new ValuePair(key, value)); //{2} };
在這個方法中,將驗證要加入新元素的位置是否已經被占據(行{1})。如果這個位置是第一次被加入元素,我們會在這個位置上初始化一個LinkedList類的實例(你已經在第5章中學習過)。然後,使用append方法向LinkedList實例中添加一個ValuePair實例(鍵和值)(行{2})
然後,我們實現用來獲取特定值的get方法:
this.get = function(key) { var position = loseloseHashCode(key); if (table[position] !== undefined){ //{3} //遍歷鏈表來尋找鍵/值 var current = table[position].getHead(); //{4} while(current.next){ //{5} if (current.element.key === key){ //{6} return current.element.value; //{7} } current = current.next; //{8} } //檢查元素在鏈表第一個或最後一個節點的情況 if (current.element.key === key){ //{9} return current.element.value; } } return undefined; //{10} };
我們要做的第一個驗證,是確定在特定的位置上是否有元素存在(行{3})。如果沒有,則返回一個undefined表示在HashTable實例中沒有找到這個值(行{10})。如果在這個位置上有值存在,我們知道這是一個LinkedList實例。現在要做的是遍歷這個鏈表來尋找我們需要的元素。在遍歷之前先要獲取鏈表表頭的引用(行{4}),然後就可以從鏈表的頭部遍歷到尾部(行{5},current.next將會是null)。
Node鏈表包含next指針和element屬性。而element屬性又是ValuePair的實例,所以它又有value和key屬性。可以通過current.element.next來獲得Node鏈表的key屬性,並通過比較它來確定它是否就是我們要找的鍵(行{6})。(這就是要使用ValuePair這個輔助類來存儲元素的原因。我們不能簡單地存儲值本身,這樣就不能確定哪個值對應著特定的鍵。)如果key值相同,就返回Node的值(行{7});如果不相同,就繼續遍歷鏈表,訪問下一個節點(行{8})。
如果要找的元素是鏈表的第一個或最後一個節點,那麼就不會進入while迴圈的內部。因此,需要在行{9}處理這種特殊的情況
使用分離鏈接法從HashTable實例中移除一個元素和之前在本章實現的remove方法有一些不同。現在使用的是鏈表,我們需要從鏈表中移除一個元素。來看看remove方法的實現:
this.remove = function(key){ var position = loseloseHashCode(key); if (table[position] !== undefined){ var current = table[position].getHead(); while(current.next){ if (current.element.key === key){ //{11} table[position].remove(current.element); //{12} if (table[position].isEmpty()){ //{13} table[position] = undefined; //{14} } return true; //{15} } current = current.next; } // 檢查是否為第一個或最後一個元素 if (current.element.key === key){ //{16} table[position].remove(current.element); if (table[position].isEmpty()){ table[position] = undefined; } return true; } } return false; //{17} };
在remove方法中,我們使用和get方法一樣的步驟找到要找的元素。遍歷LinkedList實例時,如果鏈表中的current元素就是要找的元素(行{11}),使用remove方法將其從鏈表中移除。然後進行一步額外的驗證:如果鏈表為空了(行{13}——鏈表中不再有任何元素了),就將散列表這個位置的值設為undefined(行{14}),這樣搜索一個元素或列印它的內容的時候,就可以跳過這個位置了。最後,返回true表示這個元素已經被移除(行{15})或者在最後返回false表示這個元素在散列表中不存在(行{17})。同樣,需要和get方法一樣,處理元素在第一個或最後一個的情況(行{16})
重寫了這三個方法後,我們就擁有了一個使用了分離鏈接法來處理衝突的HashMap實例
分離鏈接的HashMap的完整代碼如下所示
function HashTableSeparateChaining(){ var table = []; var ValuePair = function(key, value){ this.key = key; this.value = value; this.toString = function() { return '[' + this.key + ' - ' + this.value + ']'; } }; var loseloseHashCode = function (key) { var hash = 0; for (var i = 0; i < key.length; i++) { hash += key.charCodeAt(i); } return hash % 37; }; var hashCode = function(key){ return loseloseHashCode(key); }; this.put = function(key, value){ var position = hashCode(key); console.log(position + ' - ' + key); if (table[position] == undefined) { table[position] = new LinkedList(); } table[position].append(new ValuePair(key, value)); }; this.get = function(key) { var position = hashCode(key); if (table[position] !== undefined && !table[position].isEmpty()){ //iterate linked list to find key/value var current = table[position].getHead(); do { if (current.element.key === key){ return current.element.value; } current = current.next; } while(current); } return undefined; }; this.remove = function(key){ var position = hashCode(key); if (table[position] !== undefined){ //iterate linked list to find key/value var current = table[position].getHead(); do { if (current.element.key === key){ table[position].remove(current.element); if (table[position].isEmpty()){ table[position] = undefined; } return true; } current = current.next; } while(current); } return false; }; this.print = function() { for (var i = 0; i < table.length; ++i) { if (table[i] !== undefined) { console.log(table[i].toString()); } } }; }
【線性探查】
另一種解決衝突的方法是線性探查。當想向表中某個位置加入一個新元素的時候,如果索引為index的位置已經被占據了,就嘗試index+1的位置。如果index+1的位置也被占據了,就嘗試index+2的位置,以此類推
繼續實現需要重寫的三個方法。第一個是put方法:
this.put = function(key, value){ var position = loseloseHashCode(key); // {1} if (table[position] == undefined) { // {2} table[position] = new ValuePair(key, value); // {3} } else { var index = ++position; // {4} while (table[index] != undefined){ // {5} index++; // {6} } table[index] = new ValuePair(key, value); // {7} } };
和之前一樣,先獲得由散列函數生成的位置(行{1}),然後驗證這個位置是否有元素存在(如果這個位置被占據了,將會通過行{2}的驗證)。如果沒有元素存在,就在這個位置加入新元素(行{3}——一個ValuePair的實例)
如果這個位置已經被占據了,需要找到下一個沒有被占據的位置(position的值是undefined),因此我們聲明一個index變數並賦值為position+1(行{4}——在變數名前使用自增運算符++會先遞增變數值然後再將其賦值給index)。然後驗證這個位置是否被占據(行{5}),如果被占據了,繼續將index遞增(行{6}),直到找到一個沒有被占據的位置。然後要做的,就是將值分配到這個位置(行{7})
如果再次執行前面實例中插入數據的代碼,下圖展示使用了線性探查的散列表的最終結果:

讓我們來模擬一下散列表中的插入操作
1、試著插入Gandalf。它的散列值是19,由於散列表剛剛被創建,位置19還是空的——可以在這裡插入數據
2、試著在位置29插入John。它也是空的,所以可以插入這個姓名
3、試著在位置16插入Tyrion。它是空的,所以可以插入這個姓名
4、試著插入Aaron,它的散列值也是16。位置16已經被Tyrion占據了,所以需要檢查索引值為position+1的位置(16+1)。位置17是空的,所以可以在位置17插入Aaron
5、接著,試著在位置13插入Donnie。它是空的,所以可以插入這個姓名
6、想在位置13插入Ana,但是這個位置被占據了。因此在位置14進行嘗試,它是空的,所以可以在這裡插入姓名
7、然後,在位置5插入Jonathan,這個位置是空的,所以可以插入這個姓名
8、試著在位置5插入Jamie,但是這個位置被占了。所以跳至位置6,這個位置是空的,因此可以在這個位置插入姓名
9、試著在位置5插入Sue,但是位置被占據了。所以跳至位置6,但也被占了。接著跳至位置7,這裡是空的,所以可以在這裡插入姓名。以此類推
現在插入了所有的元素,下麵實現get方法來獲取它們的值
this.get = function(key) { var position = loseloseHashCode(key); if (table[position] !== undefined){ //{8} if (table[position].key === key) { //{9} return table[position].value; //{10} } else { var index = ++position; while (table[index] === undefined || table[index].key !== key){ //{11} index++; } if (table[index].key === key) { //{12} return table[index].value; //{13} } } } return undefined; //{14} };
要獲得一個鍵對應的值,先要確定這個鍵存在(行{8})。如果這個鍵不存在,說明要查找的值不在散列表中,因此可以返回undefined(行{14})。如果這個鍵存在,需要檢查我們要找的值是否就是這個位置上的值(行{9})。如果是,就返回這個值(行{10})。
如果不是,就在散列表中的下一個位置繼續查找,直到找到一個鍵值與我們要找的鍵值相同的元素(行{11})。然後,驗證一下當前項就是我們要找的項(行{12}——只是為了確認一下)並且將它的值返回(行{13})。
我們無法確定要找的元素實際上在哪個位置,這就是使用ValuePair來表示HashTable元素的原因
remove方法和get方法基本相同,不同之處在於行{10}和{13},它們將會由下麵的代碼代替:
table[index]=undefined;
要移除一個元素,只需要給其賦值為undefined,來表示這個位置不再被占據並且可以在必要時接受一個新元素
線性探查的HashTable的完整代碼如下所示
function HashLinearProbing(){ var table = []; var ValuePair = function(key, value){ this.key = key; this.value = value; this.toString = function() { return '[' + this.key + ' - ' + this.value + ']'; } }; var loseloseHashCode = function (key) { var hash = 0; for (var i = 0; i < key.length; i++) { hash += key.charCodeAt(i); } return hash % 37; }; var hashCode = function(key){ return loseloseHashCode(key); }; this.put = function(key, value){ var position = hashCode(key); console.log(position + ' - ' + key); if (table[position] == undefined) { table[position] = new ValuePair(key, value); } else { var index = ++position; while (table[index] != undefined){ index++; } table[index] = new ValuePair(key, value); } }; this.get = function(key) { var position = hashCode(key); if (table[position] !== undefined){ if (table[position].key === key) { return table[position].value; } else { var index = ++position; while (table[index] !== undefined && (table[index] && table[index].key !== key)){


