在netbeans里開發,有一個重要文件makefile,是用來編譯所有的文件。 項目的目錄結構如下,扁平的目錄結構,如何實現自動化編譯,寫makefile呢? 第一版 基礎版: CC = g++ CFLAGS = -O3 -DNDEBUG SOURCE =AdaBoost.cpp aodesele
在netbeans里開發,有一個重要文件makefile,是用來編譯所有的文件。
項目的目錄結構如下,扁平的目錄結構,如何實現自動化編譯,寫makefile呢?
第一版 基礎版:
CC = g++
CFLAGS = -O3 -DNDEBUG
SOURCE =AdaBoost.cpp aodeselect.cpp sample.cpp vfan.cpp kdbext2.cpp tan_gen.cpp
petal: ${SOURCE}
$(CC) -o $@ ${SOURCE} $(CFLAGS)
.PHONY:clean
clean:
rm -f petal.exe
簡簡單單,petal依賴所有的cpp,如果cpp有所修改那麼就會全部重新編譯,生成新的petal
十分耗時,大致需要
CFLAGS 就是傳給編譯器的編譯參數,定義成了一個變數
第二版
雛形版
:
CC = g++
CFLAGS = -O3 -DNDEBUG Debug版會使用參數-g;Release版使用-O3 –DNDEBUG
SOURCE =AdaBoost.cpp aodeselect.cpp sample.cpp變數的用法
default: petal 目標是生成default,要生成default,就要生成 petal ,規則沒寫,就是生成petal
echo "default"
depend: .depend 沒什麼用
echo "depend"
.depend: $(SOURCE) 依賴的是所有的.cpp 只要一個cpp文件有所修改 就要執行如下命令
echo ".depend"
rm -f ./.depend 刪除當前目錄下的.depend
$(CC) $(CFLAGS) -MM $^ >> ./.depend; -MM 自動找尋源文件中包含的非標準庫頭文件,並生成一個依賴關係 > 是定向輸出到文件,如果文件不存在,就創建文件;如果文件存在,就將其清空; >> 這個是將輸出內容追加到目標文件中。如果文件不存在,就創建文件;如果文件存在,則將新的內容追加到那個文件的末尾,該文件中的原有內容不受影響
$^--所有的依賴文件
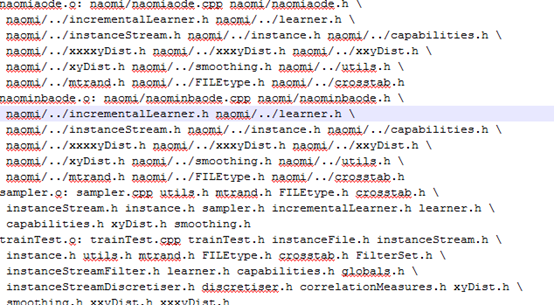
.depend里的示例內容如下:
naomiaode.o: naomi/naomiaode.cpp naomi/naomiaode.h \
naomi/../incrementalLearner.h naomi/../learner.h \
naomi/../instanceStream.h naomi/../instance.h naomi/../capabilities.h \
naomi/../xxxxyDist.h naomi/../xxxyDist.h naomi/../xxyDist.h \
naomi/../xyDist.h naomi/../smoothing.h naomi/../utils.h \
naomi/../mtrand.h naomi/../FILEtype.h naomi/../crosstab.h
其實就是找出source所有的cpp文件依賴的頭文件,並放到.depend里
include .depend 要把.depend加進來
petal: ${SOURCE}
$(CC) -o $@ ${SOURCE} $(CFLAGS) g++ -o 目標可執行文件 源文件 參數
petal64: ${SOURCE} 沒有寫要生成它,毫無作用
$(CC) -o $@ ${SOURCE} $(CFLAGS) –DSIXTYFOURBITCOUNTS
輸出:
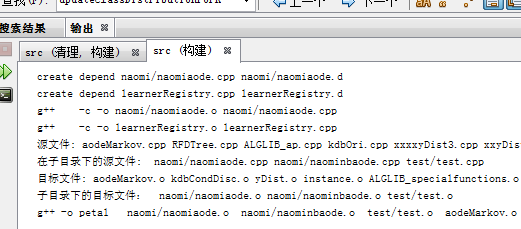
.depend文檔:
流程:
首先我遇到了include 就要先生成.depend文檔,生成完文檔後,把文檔中的.o與.c的依賴關係代替include指令,包括到makefile裡面來。所以要生成.depend對象,如果源代碼.cpp有所修改的話,就要刪除原來的.depend文檔,把依賴關係重新寫入文檔中。
Include階段結束
然後,最終目標是default,要生成default,就要生成依賴petal,要生成petal,看一看發現.cpp有所修改,重新全部編譯,刪去.o中間文件(直接 – a.cpp不會出現.o中間文件)
生成了petal,生成完petal後,就返回去生成deafault,所謂的生成default不是說我一定要真的-o deafault才好,我要有default.exe,不是這樣的,執行規則,就是生成對象,可惜default的規則,就是一條echo.那麼列印完字元串,default也就生成了
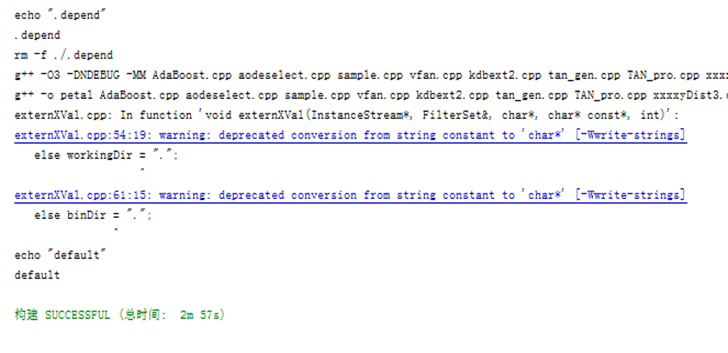
這一版本因為有要輸出所有頭文件依賴,耗時驚人 2m57s
而且白把依賴關係include進來了,可惜petal依賴的還是cpp文件,生成依賴關係毫無作用
第三版 自動化編譯 依賴.o 依賴於目標代碼:
我們把petal不依賴於cpp,不然每次都要全部重新編譯,不如依賴.o ,哪個cpp改了,就生成那個的.o,其它cpp的.o都不用動,編譯迅速
在舊版本的make中,使用編譯器此項功能通常的做法是:在Makefile中書寫一個偽目標"depend"的規則來定義自動產生依賴關係文件的命令。輸入"make depend"將生成一個稱為"depend"的文件,其中包含了所有源文件的依賴規則描述。Makefile使用"include"指示符包含這個文件。
這就是第二版的做法的初衷,depend對象也就是這麼來的,這樣petal依賴.o 再把.o依賴那些cpp和頭文件都包含進來,哪個cpp改了,從而要改哪個.o對象,也就明白了,那麼別的.o都不用重新編譯,連接起來是非常快的,而且可以利用隱含規則,不必寫如何通過.cpp和.h生成.o,十分爽
CC = g++
CFLAGS = -O3 -DNDEBUG
SOURCE = naomi/naomiaode.cpp naomi/naominbaode.cpp sampler.cpp trainTest.cpp ALGLIB_ap.cpp
OBJ= naomi/naomiaode.o naomi/naominbaode.o sampler.o trainTest.o ALGLIB_ap.o
default:petal 要註意的是要把目標放在第一個 一旦include進來之後,include進來的第一條目標naomi/naomiaode.o: naomi/naomiaode.cpp naomi/naomiaode.h \就是總目標了,所以就不以petal作為目標了
echo "default"
depend: .depend 可以使用make depend手動產生.depend依賴文件
echo "depend"
.depend: $(SOURCE)
echo ".depend"
rm -f ./.depend
$(CC) $(CFLAGS) -MM $^ >> ./.depend;
include .depend
petal: ${OBJ}
$(CC) -o $@ ${OBJ} $(CFLAGS)
.PHONY:clean
clean:
rm -f ${OBJ} petal.exe
現在makefile文件其實是這樣的:
.depend: $(SOURCE)
echo ".depend"
rm -f ./.depend
$(CC) $(CFLAGS) -MM $^ >> ./.depend;
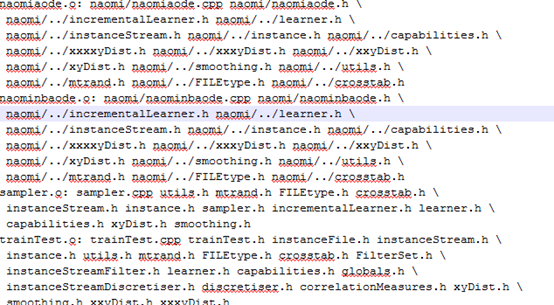
Petal: naomi/naomiaode.o naomi/naominbaode.o sampler.o trainTest.o ALGLIB_ap.o
$(CC) -o $@ ${OBJ} $(CFLAGS)
現在petal依賴於.o,而.o 依賴於cpp 與 h,當修改一個cpp的時候,會重新生成.depend文件,包括進.o最新的依賴,然後檢查petal是否需要重新生成,petal依賴的naomi/naomiaode.o需要重新生成嗎?由於cpp的修改時間比.o的早,要重新生成.o petal依賴的sampler.o需要重新生成嗎?一個個檢查下去
比如我修改了 
以下四個文件,而petal的依賴關係為:
petal:AdaBoost.o aodeselect.o sample.o vfan.o
所以會按序重新生成:
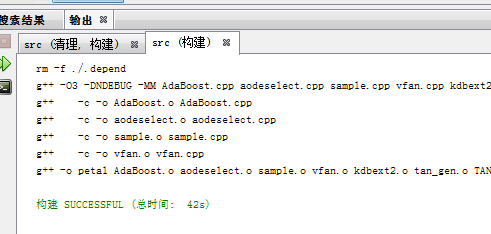
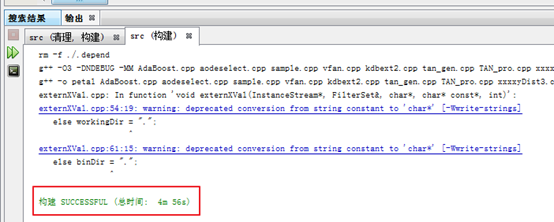
速度很快,但是這個版本還是有他自己的問題:
- 修改.h的時候,沒有重新生成.depend會出錯
- 修改一個.cpp,沒有必要重新產生所有cpp的依賴,依賴關係其實也像目標文件一樣,修改 了cpp或h的文件重新產生它的依賴關係,沒有修改的依賴關係不動。所以才有了.d文件版
當修改一個cpp的時候
,比如naomi/naomiaode.cpp
就要重新寫.depend文件,耗時較大

可以很明顯地看到,只重新編譯了naomiaode.cpp,耗時只有40s!!!! 從3分鐘降到40s秒,劃時代的進步,真正發揮了make的作用。
當修改一個非子目錄下的.h的時候
因為修改頭文件,可以把新的頭文件包含在文件中,需要重新生成.o的依賴關係,但是因為.depend只依賴了cpp所以不會因為頭文件的修改而修改.depend文件,實際上這樣是錯誤的。

因為 aode.o: aode.h 所以它就會根據.o的依賴關係重新生成.o 速度十分快
對於naomi文件夾下的
.depend里的對象是
naominbaode.o: naomi/naominbaode.cpp naomi/naominbaode.h \
naomi/../incrementalLearner.h naomi/../learner.h \
naomi/../instanceStream.h naomi/../instance.h naomi/../capabilities.h \
naomi/../xxxxyDist.h naomi/../xxxyDist.h naomi/../xxyDist.h \
naomi/../xyDist.h naomi/../smoothing.h naomi/../utils.h \
naomi/../mtrand.h naomi/../FILEtype.h naomi/../crosstab.h
並不存在的一個目標,正確的路徑是naomi/ naominbaode.o
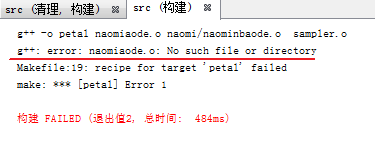
首先按照道理來說 naominbaode.o根本不存在,那麼每次編譯的時候就會重新產生naomiaode.o,但是事實並非如此:
比如我刪除了aode.o就會重新生成.o,因為petal的依賴的.o不存在
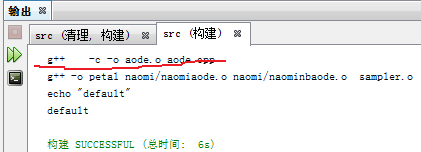
但是我修改了aode.cpp之後,並沒有重新生成naominbaode.o,僅僅重新生成了aode.o

註:不可以去掉OBJ = naomi/naomiaode.o naomi/naominbaode.o 里的naomi
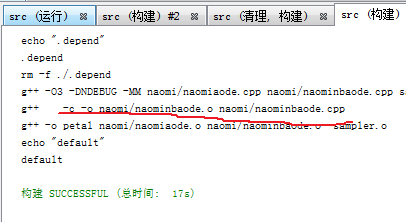
然後修改
改naominbaode.cpp會自動地重新生成.o 和.depend
但是依舊能正確地產生
g++ -c -o naomi/naominbaode.o naomi/naominbaode.cpp
但是如果改的是naominbaode.h就 不同了,
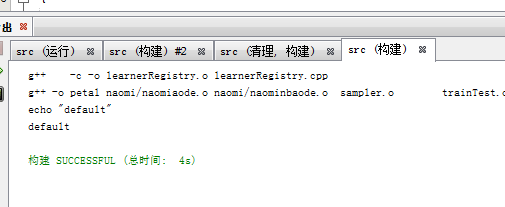
並沒有重新生成g++ -c -o naomi/naominbaode.o naomi/naominbaode.cpp
而只修改了learnerRegistry.cpp
如果真的能找到naominbaode.o的話,它依賴了naomi/naominbaode.h,那麼頭文件被修改,.o應該重新生成,但是沒有,如果真的找不到naominbaode.o的話,為什麼修改了naomi/naominbaode.cpp會重新生成 naomi/naominbaode.o ,而且並不是每次都會重新生成naomi/naominbaode.o的,這樣不一致的表現,為子目錄版帶來了巨大的困難,
說明這是路徑問題,檢查naominbaode.o是否需要重新產生的時候,根本沒有找到它在哪裡,它不在根目錄下。
只要改成naomi/ naominbaode.o 修改naomi/naominbaode.h時就會連同naominbaode.o一起更新
naomi/naomiaode.o: naomi/naomiaode.cpp naomi/naomiaode.h \
naomi/../incrementalLearner.h naomi/../learner.h \
naomi/../instanceStream.h naomi/../instance.h naomi/../capabilities.h \
naomi/../xxxxyDist.h naomi/../xxxyDist.h naomi/../xxyDist.h \
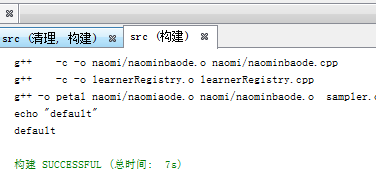
在makefile下執行命令
pwd;
cd ./naomi; \
pwd; \
pwd;
pwd;
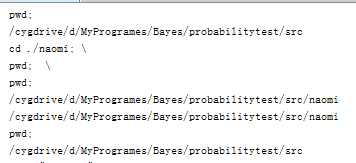
Pwd就是顯示當前目錄
那麼為什麼要把幾個命令寫在"同一行"(是對於make來說,因為\的作用就是連接行),並用分號隔開每個命令?因為在Makefile這樣做才能使上一個命令作用於下一個命令。
\為運行環境續命,第一個pwd把它的路徑傳給了第二個pwd,第二個pwd沒有加\,所以最後一個pwd又反彈回了原來的路徑。
一個目標多條
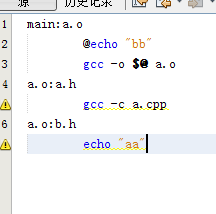
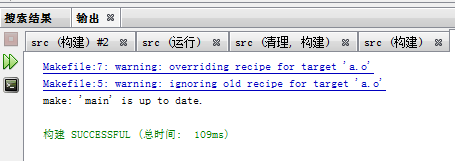
如果有多條命令,就會忽略老的一條
而如果是這樣的話
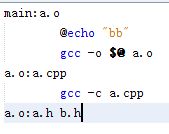
如果我修改了a.cpp b.h或者 a.h就會重新生成a.o
gcc –c a.pp生成a.o
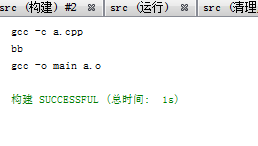
把規則寫在第二條下麵也是一樣的效果
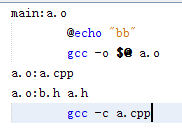
所以相當於寫成了
-
o: a.cpp b,h a.h
gcc –c a.cpp
有重覆的效果也是一樣的
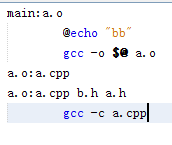
其中a.cpp是重覆的,但是沒有關係
這為下麵.d文件版分開寫的規則奠定了基礎
第四版:無子文件版
參考:
http://blog.chinaunix.net/uid-20316928-id-3395996.html
https://segmentfault.com/a/1190000000349917
CC = g++
CFLAGS = -O3 -DNDEBUG
SOURCES = $(wildcard *.cpp)
OBJS := $(patsubst %.cpp, %.o,$(SOURCES))
petal:$(OBJS)
@echo "源文件:" $(SOURCES)
@echo "目標文件:" $(OBJS)
$(CC) -o $@ $(OBJS) $(CFLAGS)
%.d :%.cpp
@echo "create depend";
@set -e; \
gcc -MM $< > $@.$$$$; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; \
rm -f $@.$$$$
-include $(OBJS:.o=.d)
.PHONY:clean
clean:
@echo "開始清理項目..."
@echo "正在刪除所有的.d文件"
rm -f $(OBJS:.o=.d)
@echo "正在刪除所有的.o文件"
rm -rf $(OBJS)
@echo "正在刪除petal"
rm -f petal.exe
@echo "清理結束"
前面兩行很簡單就是定義編譯變數和編譯選項。
SOURCES = $(wildcard *.c) 這句話意思是定義一個變數SOURCES,它的值包含當前目錄下所有.c文件。 在我的例子里我把這個值列印出來了就是dList.c memory.c test.c debug.c
$(wildcard PATTEN) 是Makefile內建的一個函數:
函數名稱:獲取匹配模式文件名函數—wildcard
函數功能:列出當前目錄下所有符合模式"PATTERN"格式的文件名。
返回值:空格分割的、存在當前目錄下的所有符合模式"PATTERN"的文件名。
函數說明:"PATTERN"使用shell可識別的通配符,包括"?"(單字元)、"*"(多字元)等
OBJS := $(patsubst %.c, %.o,$(SOURCES)) 這一行是定義了一個變數OBJS,它的值是將變數SOURCES里的內容以空格分開,將所有.c文件替換成.o. 在我的例子里列印出來就是dList.o memory.o test.o debug.o。
$(patsubst PATTEN, REPLACEMENT, TEXT)也是內建函數
函數名稱:模式替換函數—patsubst。
函數功能:搜索"TEXT"中以空格分開的單詞,將否符合模式"TATTERN"替換為"REPLACEMENT"
sinclude $(SOURCES:.c=.d) 這一行是非常關鍵的,它在當前Makefile里去include另外的Makefile. 這裡"另外"的Makefile是將SOURCES變數里所有.c替換成.d。 在我的例子里就是dList.d memory.d test.d debug.d. 意思就是執行到這裡
的時候先去依次執行dList.d memory.d test.d debug.d. 這裡的.d文件就是包含了每個.c文件自動生成的對頭文件的依賴關係。這個依賴關係將由下麵的%d:%c來完成。
%d: %c
此規則的含義是:所有的.d文件依賴於同名的.c文件。
第一行;使用c編譯器自自動生成依賴文件($<)的頭文件的依賴關係,並輸出成為一個臨時文件,"$$$$"表示當前進程號。如果$(CC)為GNU的c編譯工具,產生的依賴關係的規則中,依賴頭文件包括了所有的使用的系統頭文件和用戶定義的頭文件。如果需要生成的依賴描述文件不包含系統頭文件,可使用"-MM"代替"-M"。
第二行;使用sed處理第二行已產生的那個臨時文件並生成此規則的目標文件。經過這一行後test.d里內容如下:test.o: test.c aaron.h dList.h debug.h 其他.d里以此類推。
第三行;刪除臨時文件。
.d文件的內容如下:
a2de3.o a2de3.d: a2de3.cpp a2de3.h incrementalLearner.h learner.h \
instanceStream.h instance.h capabilities.h xxxyDist3.h xxyDist.h \
xyDist.h smoothing.h utils.h mtrand.h FILEtype.h crosstab.h \
correlationMeasures.h xxxyDist.h globals.h
在.d文件里,不僅闡明瞭如何生成.o文件,而且闡明瞭如何生成它自己,結合
%d: %c規則,在第一次時sinclude $(SOURCES:.c=.d) 在例子里其實.d文件開始並不存在,所以當Makefile在include這些.d文件時首先看.d存在不,不存在就要去尋找.d的依賴文件和規則。這裡就找到了%d: %c從而創建出真正的.d文件。
而後來頭文件或者cpp發生修改了,.makefile會將所讀取的每個makefile(.d)作為一個目標,如重新生成a.d 尋找更新a.d的規則。如果需要重新產生a.d就重新產生,重新引入,所以會重新產生.d文件。這樣的規則是符合邏輯的,因為不論是頭文件還是cpp的修改,都有可能導致目標文件的依賴關係發生變化,必須重新生成依賴文件,解決了上一版的問題。

到這裡基本的意義弄明白了,但是讓我不解的是%d: %c這個依賴的規則怎麼能被執行到的?按照我的理解Makefile在執行時首先檢查終極目標main是否存在,如果不存在則建立(根據main的依賴規則),如果存在在需要查看
main的依賴文件是否存在並且是最新的,這我的例子里就是要看test.o dList.o memory.o debug.o是否存在且最新。這樣追下去是否沒有%d: %c什麼事啊, .d文件也應該不存在或者說是空的。儘管我們include了.d文件,但是沒有依賴規則去執行它啊。後來仔細閱讀了
Makefile文件的重建才明白了。
Makefile如果由其它文件重建(這裡我的Makefile include了所有.d文件,.d也可以看成是一個Makefile),Makefile在讀入所有其他makefile文件(.d)之後,先把這些.d包括進來,然後將所讀取的每個makefile(.d)作為一個目標,如重新生成a.d 尋找更新a.d的規則。如果需要重新產生a.d就重新產生,重新引入 同樣
如果此目標不存在則根據依賴規則重新創建。其實這裡的關鍵點就是對於
include了理解,它是把include的文件首先當成一個目標,然後要去尋找其依賴文件和規則的,而不是我事先想象的簡單的把其他文件的內容包含過來。
到此,問題解決,基本達到預期。
seq.d : seq.c
@set -e; \
gcc -MM $< > $@.$$$$; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; \
rm -f $@.$$$$
-include seq.d
生成規則中的執行命令解釋
第一個命令@set -e。@關鍵字告訴make不輸出該行命令;set -e的作用是,當後面的命令的返回值非0時,立即退出。
那麼為什麼要把幾個命令寫在"同一行"(是對於make來說,因為\的作用就是連接行),並用分號隔開每個命令?因為在Makefile這樣做才能使上一個命令作用於下一個命令。這裡是想要set -e作用於後面的命令。
第二個命令gcc -MM $< > $@.$$$$, 作用是根據源文件生成依賴關係,並保存到臨時文件中。內建變數$<的值為第一個依賴文件(那seq.c),$$$$為字元串"$$",由於makefile中所有的$字元都是特殊字元(即使在單引號之中!),要得到普通字元$,需要用$$來轉義; 而$$是shell的特殊變數,它的值為當前進程號;使用進程號為尾碼的名稱創建臨時文件,是shell編程常用做法,這樣可保證文件唯一性。這個臨時文件的名字為seq.d.1223 $@代表目標文件 seq.d gcc –MM seq.c > seq.d.1223
註意這一步的輸出是:
a2de3.o : a2de3.cpp a2de3.h incrementalLearner.h learner.h \
instanceStream.h instance.h capabilities.h xxxyDist3.h xxyDist.h \
xyDist.h smoothing.h utils.h mtrand.h FILEtype.h crosstab.h \
correlationMeasures.h xxxyDist.h globals.h
既不包含子目錄路徑,也不包含 a2de3.d所以需要加工
第三個命令作用是將目標文件加入依賴關係的目錄列表中,並保存到目標文件。唯一要註意的是內建變數$*,$*的值為第一個依賴文件去掉尾碼的名稱(這裡即是seq)。
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@;
sed是 linux文本處理工具
這條sed命令的結構是s/match/replace/g。有時為了清晰,可以把每個/寫成逗號,即這裡的格式s,match,replace,g。
該命令表示把源串內的match都替換成replace,s指示match可以是正則表達式。
g表示把每行內所有match都替換,如果去掉g,則只有每行的第1處match被替換(實際上不需要g,因為一個.d文件中,只會在開頭有一個main.o:)。
所以要尋找的目標是:\($*\)\.o[ :]*
替換成: \1.o $@ :
使用到了4個正則表示式的知識點。
$*是第一個依賴文件去掉尾碼的名稱假設為main
1. \(main\)為創建一個字元標簽,給後邊的replacement-pattern使用。如\1.o,展開後就是main.o 而\顯然是為了轉義
2. \. 在正則表達式中'.'作用是匹配一個字元。所以需要使用轉義元字元'\'來轉義。
3. [ :] 匹配一組字元里的任意字元。這個[] 裡面放的是一個空格和一個冒號
4 *匹配0個或多個前一字元
所以正則式[ :]*,表示若幹個空格或冒號,(其實一個.d里只會有一個冒號,如果這裡寫成[ ]*:,即匹配若幹個空格後跟一個冒號,也是可以的)
去掉轉義後就是尋找 main.o: 或者 main.o :這樣的字元串替換成
\1.o也是為了轉義,不然就真的替換成了1.o了,這裡是字元標簽main
所以替換成 main.o main.d :
最後的效果就是
把臨時文件main.d.temp的內容main.o : main.c command.h改為main.o main.d : main.c command.h,並存入main.d文件的功能。
這個命令為子文件版的打下了基礎
第四個命令是將該臨時文件刪除。
如果把內建變數都替換成其值後,實際內容是這樣子:
全選複製放進筆記
seq.d : seq.c
@set -e; \
gcc -MM seq.c > seq.d.$$$$; \
sed 's,\(seq\)\.o[ :]*,\1.o seq.d : ,g' < seq.d.$$$$ > seq.d; \
rm -f seq.d.$$$$
-include seq.d
最後,再把Makefile的模式匹配應用上,就完成自動生成頭文件依賴功能了:
$'\t' command not find
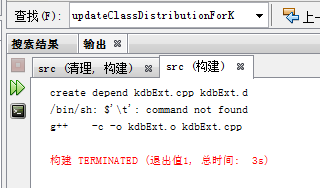
這是因為在規則後面有換行符,把換行符刪去即可
第五版 子文件版
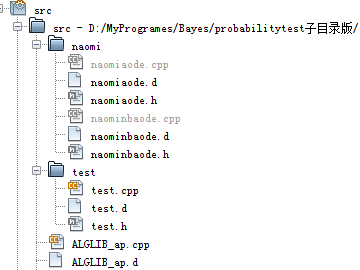
但是src文件夾下麵文件太多了,最好能有許多的文件夾,一方面區分自己寫的和其它文件,另一方面把aode優化演算法,放在一個文件夾下,便於管理,也能達到自動編譯的效果
根據要把 naomiaode.o的路徑寫全的提示,其實只要在sed文本替換上做文章就好了。
文件夾結構:
CC = g++
CFLAGS = -O3 -DNDEBUG
SOURCES = $(wildcard *.cpp )
OBJS := $(patsubst %.cpp, %.o,$(SOURCES))
SUB_DIR1 = naomi
SUB_SOURCES1 = $(wildcard $(SUB_DIR1)/*.cpp)
SUB_OBJS1 = $(patsubst %.cpp, %.o, $(SUB_SOURCES1))
#一個子目錄
SUB_DIR2 = test
SUB_SOURCES2 = $(wildcard $(SUB_DIR2)/*.cpp)
SUB_OBJS2 = $(patsubst %.cpp, %.o, $(SUB_SOURCES2))
#一個子目錄
petal: $(SUB_OBJS1) $(SUB_OBJS2) $(OBJS)
@echo "源文件:" $(SOURCES)
@echo "在子目錄下的源文件: " $(SUB_SOURCES1) $(SUB_SOURCES2)
@echo "目標文件:" $(OBJS)
@echo "子目錄下的目標文件: " $(SUB_OBJS1) $(SUB_OBJS2)
$(CC) -o $@ $(SUB_OBJS1) $(SUB_OBJS2) $(OBJS) $(CFLAGS)
%.d: %.cpp
@echo "create depend" $< $@ $(subst naomi/,,$*)
@set -e; \
gcc -MM $< > $@.$$$$; \
if [ $(findstring $(SUB_DIR1)/,$<)a = $(SUB_DIR1)/a ]; then sed 's,\($(subst $(SUB_DIR1)/,,$*)\)\.o[ :]*,$(SUB_DIR1)\1.o $@ : ,g' < $@.$$$$ > $@; rm -f $@.$$$$; \
elif [ $(findstring $(SUB_DIR2)/,$<)a = $(SUB_DIR2)/a ]; then sed 's,\($(subst $(SUB_DIR2)/,,$*)\)\.o[ :]*,$(SUB_DIR2)/\1.o $@ : ,g' < $@.$$$$ > $@; rm -f $@.$$$$;\
else sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; rm -f $@.$$$$;\
fi
-include $(OBJS:.o=.d) ${SUB_OBJS1:.o=.d} ${SUB_OBJS2:.o=.d}
.PHONY:clean
clean:
@echo "開始清理項目..."
@echo "正在刪除所有的.d文件"
rm -f $(OBJS:.o=.d) $(SUB_OBJS1:.o=.d) $(SUB_OBJS2:.o=.d)
@echo "正在刪除所有的.o文件"
rm -rf $(OBJS) ${SUB_OBJS1} ${SUB_OBJS2}
@echo "正在刪除petal"
rm -f petal.exe
@echo "清理結束"
值得一提的就是
$(subst naomi/,,$*)
$(subst FROM,TO,TEXT)
函數名稱:字元串替換函數
函數功能:把字元串TEXT中的FROM字元串替換為TO
返回值:替換後的新字元串
$(subst ee,EE,feet on the stree) //替換"feet on the street"中的ee為EE。結果得到字元串"fEEt on the strEEt"
當處理naomi文件夾下的文件時,如果仍舊採用第四版,那麼
naomiaode.o: naomi/naomiaode.cpp naomi/naomiaode.h \
naomi/../incrementalLearner.h naomi/../learner.h \
naomi/../instanceStream.h naomi/../instance.h naomi/../capabilities.h \
naomi/../xxxxyDist.h naomi/../xxxyDist.h naomi/../xxyDist.h \
naomi/../xyDist.h naomi/../smoothing.h naomi/../utils.h \
naomi/../mtrand.h naomi/../FILEtype.h naomi/../crosstab.h
而沒有 naomiaode.d
因為$* 是第一個依賴文件去掉尾碼名,第一個依賴文件是naomi/naomiaode.cpp
去掉尾碼名後是naomi/naomiaode,而gcc –mm的輸出是 naomiaode.o,根本找不到
naomi/naomiaode,所以我們要把naomi/naomiaode里的naomi/去掉,使用替換函數把naomi/替換成空的,就能找到要替換的naomiaode.o了
我們的目標是:
naomi/naomiaode.o naomi/naomiaode.d : naomi/naomiaode.cpp naomi/naomiaode.h \
naomi/../incrementalLearner.h naomi/../learner.h \
naomi/../instanceStream.h naomi/../instance.h naomi/../capabilities.h \
naomi/../xxxxyDist.h naomi/../xxxyDist.h naomi/../xxyDist.h \
naomi/../xyDist.h naomi/../smoothing.h naomi/../utils.h \
naomi/../mtrand.h naomi/../FILEtype.h naomi/../crosstab.h
所以要給1.o加上文件夾名,而目標文件$@是自帶路徑的,無需處理。
但是你還要判斷處理的文件究竟屬於哪個文件夾好把naomi/或者test/去掉,所以想到了條件語句if,makefile有自己的條件語句,但是
ifeq ( $(findstring ${SUB_DIR1}/,$<) , $(SUB_DIR1) );
永遠都不等於,為什麼?因為條件判斷里不可以使用自動變數,$<永遠不會被展開!
所以不能使用ifeq只能使用 shell condition
all:
if [ "$(BUILD)" = "debug" ]; then echo "build debug"; else echo "build release"; fi
echo "done"
儘量放在一行里,不要用 == if和[] 之間有空格,a = b之間有空格 a=b是錯誤的
if [ $(findstring $(SUB_OBJS1)/,$<) = $(SUB_OBJS1)/ ];
$(findstring FIND,IN)
函數名稱:查找字元串函數
函數功能:在字元串IN中查找FIND字元串
返回值:如果在IN中找到FIND子字元串,則返回FIND,否則返回空
函數說明:收索是嚴格的文本匹配
$(findstring a,a b c) 返回 a
$(findstring a,b c) 返回空字元
查找在第一個依賴文件里有沒有naomi/如果有,就返回naomi/=naomi/
但是
shell腳本報錯:"[: =: unary operator expected"
在匹配字元串相等時,我用了類似這樣的語句:
if [ $STATUS == "OK" ]; then
echo "OK"
fi
在運行時出現了 [: =: unary operator expected 的錯誤,
究其原因,是因為如果變數STATUS值為空,那麼就成了 [ = "OK"] ,顯然 [ 和 "OK" 不相等並且缺少了 [ 符號,所以報了這樣的錯誤。當然不總是出錯,如果變數STATUS值不為空,程式就正常了,所以這樣的錯誤還是很隱蔽的。
用下麵的方法也能避免這種錯 誤:if [ "$STATUS"x == "OK"x ]; then echo
"OK"fi。當然,x也可以是其他字元。
所以
if [ $(findstring $(SUB_OBJS1)/,$<)a = $(SUB_OBJS1)/a ];
另外rm -f $@.$$$$;拿到if外面去都失敗了,總是出錯。
效果就是即使是 修改naomi/naomiaode.h 也可以重新編譯