
本文是學習時的自我總結,用於日後溫習。如有錯誤還望諒解,不吝賜教 此處附上部分內容所出博客:http://blog.csdn.net/ymh198816/article/details/51998085 Flume+Kafka+Storm+Redis實時分析系統基本架構 1) 整個實時分析系統的架構 ...
本文是學習時的自我總結,用於日後溫習。如有錯誤還望諒解,不吝賜教
此處附上部分內容所出博客:http://blog.csdn.net/ymh198816/article/details/51998085
Flume+Kafka+Storm+Redis實時分析系統基本架構
1) 整個實時分析系統的架構是
2) 先由電商系統的訂單伺服器產生訂單日誌,
3) 然後使用Flume去監聽訂單日誌,
4) 並實時把每一條日誌信息抓取下來並存進Kafka消息系統中,
5) 接著由Storm系統消費Kafka中的消息,
6) 同時消費記錄由Zookeeper集群管理,這樣即使Kafka宕機重啟後也能找到上次的消費記錄,接著從上次宕機點繼續從Kafka的Broker中進行消費。但是由於存在先消費後記錄日誌或者先記錄後消費的非原子操作,如果出現剛好消費完一條消息並還沒將信息記錄到Zookeeper的時候就宕機的類似問題,或多或少都會存在少量數據丟失或重覆消費的問題, 其中一個解決方案就是Kafka的Broker和Zookeeper都部署在同一臺機子上。
7) 接下來就是使用用戶定義好的Storm Topology去進行日誌信息的分析並輸出到Redis緩存資料庫中(也可以進行持久化),最後用Web APP去讀取Redis中分析後的訂單信息並展示給用戶。
之所以在Flume和Storm中間加入一層Kafka消息系統,就是因為在高併發的條件下, 訂單日誌的數據會井噴式增長,如果Storm的消費速度(Storm的實時計算能力那是最快之一,但是也有例外, 而且據說現在Twitter的開源實時計算框架Heron比Storm還要快)慢於日誌的產生速度,加上Flume自身的局限性,必然會導致大量數據滯後並丟失,所以加了Kafka消息系統作為數據緩衝區,而且Kafka是基於log File的消息系統,也就是說消息能夠持久化在硬碟中,再加上其充分利用Linux的I/O特性,提供了可觀的吞吐量。架構中使用Redis作為資料庫也是因為在實時的環境下,Redis具有很高的讀寫速度。
Flume和Kafka對比
(1)kafka和flume都是日誌系統。kafka是分散式消息中間件,自帶存儲,提供push和pull存取數據功能。flume分為agent(數據採集器),collector(數據簡單處理和寫入),storage(存儲器)三部分,每一部分都是可以定製的。比如agent採用RPC(Thrift-RPC)、text(文件)等,storage指定用hdfs做。
(2)kafka做日誌緩存應該是更為合適的,但是 flume的數據採集部分做的很好,可以定製很多數據源,減少開發量。所以比較流行flume+kafka模式,如果為了利用flume寫hdfs的能力,也可以採用kafka+flume的方式。
Flume
- Flume是2009年7月開源的日誌系統。它內置的各種組件非常齊全,用戶幾乎不必進行任何額外開發即可使用。是分散式的日誌收集系統,它將各個伺服器中的數據收集起來並送到指定的地方去,比如HDFS
- Flume特點
1) 可靠性
當節點出現故障時,日誌能夠被傳送到其他節點上而不會丟失。Flume提供了三種級別的可靠性保障,從強到弱依次分別為:end-to-end(收到數據 agent首先將event寫到磁碟上,當數據傳送成功後,再刪除;如果數據發送失敗,可以重新發送),Store on failure(這也是scribe採用的策略,當數據接收方crash時,將數據寫到本地,待恢復後,繼續發送),Best effort(數據發送到接收方後,不會進行確認)
2) 可擴展性
Flume採用了三層架構,分別問agent,collector和storage,每一層均可以水平擴展。其中,所有agent和collector由 master統一管理,這使得系統容易監控和維護,且master允許有多個(使用ZooKeeper進行管理和負載均衡),這就避免了單點故障問題。
3) 可管理性
所有agent和colletor由master統一管理,這使得系統便於維護。用戶可以在master上查看各個數據源或者數據流執行情況,且可以對各個數據源配置和動態載入。
4) 功能可擴展性
用戶可以根據需要添加自己的agent,colletor或者storage。
3. Flume架構
Flume採用了分層架構,由三層組成:agent,collector和storage。其中,agent和collector均由兩部分組成:source和sink,source是數據來源,sink是數據去向。
Flume的核心是Agent進程,是一個運行在伺服器節點的Java進程。
agent:將數據源的數據發送到collector
collector:將多個agent的數據彙總後,載入到storage。它的source和sink與agent類似
storage:存儲系統,可以是一個普通file,也可以是HDFS,Hive,HBase等。
source(數據源):用於收集各種數據
channel:臨時存放數據,可以存放在memory、jdbc、file等
sink:把數據發送到目的地,如HDFS、HBase等
Flume傳輸數據的基本單位是event,事務保證是在event級別進行的,event將傳輸的數據進行封裝
只有在sink將channel中的數據成功發送出去之後,channel才會將臨時數據進行刪除,這種機制保證了數據傳輸的可靠性與安全性。
4. Flume的廣義用法
Flume支持多級Flume的Agent,即sink可以將數據寫到下一個Agent的source中,
且Flume支持扇入(source可以接受多個輸入)、扇出(sink可以將數據輸出多個目的地)
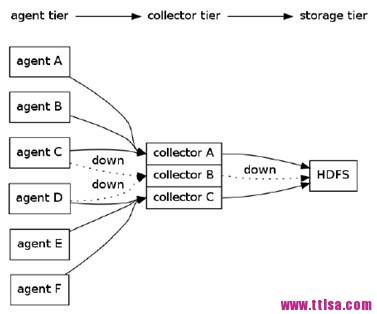
一個複雜的例子如下:有6個agent,3個collector,所有collector均將數據導入HDFS中。agent A,B將數據發送給collector A,agent C,D將數據發送給collectorB,agent C,D將數據發送給collectorB。同時,為每個agent添加end-to-end可靠性保障,如果collector A出現故障時,agent A和agent B會將數據分別發給collector B和collector C。
Kafka
- Kafka是2010年12月份開源的項目,採用scala語言編寫,採用push/pull架構,更適合異構集群數據的傳遞方式
- Kafka 特征
持久性消息:不會丟失任何信息,提供穩定的TB級消息存儲
高吞吐量:Kafka設計工作在商用硬體上,提供每秒百萬的消息
分散式架構,能夠對消息分區
實時:消息由生產者線程生產出來立刻被消費者看到,數據在磁碟上的存取代價為O(1)
3. Kafka架構
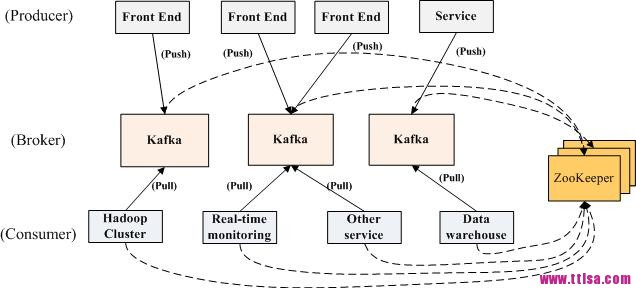
Kafka實際上是一個消息發佈訂閱系統。Kafka將消息以Topic為單位進行歸納,將向Topic發佈消息的程式作為producer,預定消息的作為consumer。Kafka以集群方式運行,可以由一個或多個服務組成,每個服務叫做一個broker。一旦有新的關於某topic的消息,broker會傳遞給訂閱它的所有consumer。 在kafka中,消息是按topic組織的,而每個topic又會分為多個partition,這樣便於管理數據和進行負載均衡。同時,它也使用了 zookeeper進行負載均衡。
1) Producer
向broker發送數據。
Kafka提供了兩種producer介面:
a) low_level介面,用於向特定的broker的某個topic下的某個partition發送數據;
b) high level介面,支持同步/非同步發送數據,基於zookeeper的broker自動識別和負載均衡(基於Partitioner)。producer可以通過zookeeper獲取可用的broker列表,也可以在zookeeper中註冊listener,該listener在添加刪除broker,註冊新的topic或broker註冊已存在的topic時被喚醒:當producer得知以上時間時,可根據需要採取一定的行動。
2) Broker
Broker採取了多種策略提高數據處理效率,包括sendfile和zero copy等技術。
3) Consumer
將日誌信息載入到中央存儲系統上。
kafka提供了兩種consumer介面:
a) low level介面:維護到某一個broker的連接,並且這個連接是無狀態的,每次從broker上pull數據時,都要告訴broker數據的偏移量。
b) high level介面:隱藏了broker的細節,允許consumer從broker上push數據而不必關心網路拓撲結構。更重要的是,對於大部分日誌系統而言,consumer已經獲取的數據信息都由broker保存,而在kafka中,由consumer自己維護所取數據信息
4. Kafka消息發送流程
1) Producer根據指定的partition方法,將消息發佈到指定topic的partition裡面
2) 集群接收到Producer發送的消息後,將其持久化到硬碟,並保留消息指定時長,而不關註消息是否被消費。
3) Consumer從kafka集群pull數據,並控制獲取消息的offset
詳細過程:
Kafka是一個分散式的高吞吐量的消息系統,同時兼有點對點和發佈訂閱兩種消息消費模式。
Kafka主要由Producer,Consumer和Broker組成。Kafka中引入了一個叫“topic”的概念,用來管理不同種類的消息,不同類別的消息會記錄在到其對應的topic池中。而這些進入到topic中的消息會被Kafka寫入磁碟的log文件中進行持久化處理。對於每一個topic里的消息log文件,Kafka都會對其進行分片處理。而每一個消息都會順序寫入中log分片中,並且被標上“offset”的標量來代表這條消息在這個分片中的順序,並且這些寫入的消息無論是內容還是順序都是不可變的。所以Kafka和其它消息隊列系統的一個區別就是它能做到分片中的消息是能順序被消費的,但是要做到全局有序還是有局限性的,除非整個topic只有一個log分片。並且無論消息是否有被消費,這條消息會一直保存在log文件中,當留存時間足夠長到配置文件中指定的retention的時間後,這條消息才會被刪除以釋放空間。對於每一個Kafka的Consumer,它們唯一要存的Kafka相關的元數據就是這個“offset”值,記錄著Consumer在分片上消費到了哪一個位置。通常Kafka是使用Zookeeper來為每一個Consumer保存它們的offset信息,所以在啟動Kafka之前需要有一個Zookeeper集群;而且Kafka預設採用的是先記錄offset再讀取數據的策略,這種策略會存在少量數據丟失的可能。不過用戶可以靈活設置Consumer的“offset”的位置,在加上消息記錄在log文件中,所以是可以重覆消費消息的。log的分片和它們的備份會分散保存在集群的伺服器上,對於每一個partition,在集群上都會有一臺這個partition存在的伺服器作為leader,而這個partitionpartition的其它備份所在的伺服器做為follower,leader負責處理關於這個partition的所有請求,而follower負責這個partition的其它備份的同步工作,當leader伺服器宕機時,其中一個follower伺服器就會被選舉為新的leader。
數據的傳遞方式
1) Socket:最簡單的交互方式,典型的c/s交互模式。傳輸協議可以是TCP/UDP
優點:易於編程,Java有很多框架,隱藏了細節;容易控制許可權,通過https,使得安全性提高;通用性強
缺點:伺服器和客戶端必須同時線上;當傳輸數據量比較大的時候,嚴重占用網路帶寬,導致連接超時
2) FTP/文件共用伺服器方式:適用於大數據量的交互
優點:數據量大時,不會超時,不占用網路帶寬;方案簡單,避免網路傳輸、網路協議相關概念
缺點:不適合做實時類的業務;必須有共同的伺服器,可能存在文件泄密;必須約定文件數據的格式
3) 資料庫共用數據方式:系統A、B通過連接同一個資料庫伺服器的同一張表進行數據交換
優點:使用同一個資料庫,使得交互更簡單,交互方式靈活,可更新,回滾,因為資料庫的事務,交互更可靠
缺點:當連接B的系統越來越多,會導致每個系統分配到的連接不會很多;
一般來說,兩個公司的系統不會開放自己的資料庫給對方,影響安全性
4) 消息方式:Java消息服務(Java Message Service)是message數據傳輸的典型的實現方式
優點:JMS定義了規範,有很多消息中間件可選;消息方式比較靈活,可採取同步、非同步、可靠性的消息處理
缺點:JMS相關的學習對開發有一定的學習成本;在大數據量的情況下,可能造成消息積壓、延遲、丟失甚至中間件崩潰
1.消息隊列
任何軟體工程遇到的問題都可以通過增加一個中間層來解決
消息隊列是在消息的傳輸過程中保存消息的容器。主要目的是提供路由並保證消息的傳遞,如果發送消息時接收者不可用,消息隊列會保留消息,直到可以成功地傳遞它。
2. 消息中間件作用
系統解耦:服務B出現問題不會影響服務A
削峰填谷:對請求壓力實現削峰填谷,降低系統峰值壓力
數據交換:無需暴露企業A和B的內網就可以實現數據交換
非同步通知:減少前端和後端服務之間大量不必要的輪詢請求
定時任務:如生成付款檢查任務,延遲30分鐘


