
1.1 流程式控制制之for迴圈 1 迭代式迴圈:for,語法如下 for i in range(10): 縮進的代碼塊 2 break與continue(同上) 3 迴圈嵌套 for i in range(1,10): for j in range(1,i+1): print('%s*%s=%s' % ...
1.1 流程式控制制之for迴圈
1 迭代式迴圈:for,語法如下
for i in range(10): 縮進的代碼塊
2 break與continue(同上)
3 迴圈嵌套
for i in range(1,10): for j in range(1,i+1): print('%s*%s=%s' %(i,j,i*j),end=' ') print() for+else
1.2 開發工具IDE
1.2.1 為何要用IDE
到現在為止,我們也是寫過代碼的人啦,但你有沒有發現,每次寫代碼要新建文件、寫完保存時還要選擇存放地點,執行時還要切換到命令行調用python解釋器,好麻煩呀,能否一氣呵成,讓我簡單的寫代碼?此時開發工具IDE上場啦,一個好的IDE能幫你大大提升開發效率。
很多語言都有比較流行的開發工具,比如JAVA 的Eclipse, C#,C++的VisualStudio, Python的是啥呢? Pycharm,最好的Python 開發IDE
1.2.2 安裝
下載地址:https://www.jetbrains.com/pycharm/download 選擇Professional 專業版
Comunnity社區版是免費的,但支持的功能不多,比如以後我們會學的Django就不支持,所以還是用專業版,但專業版是收費的,一年一千多,不便宜。唉,萬能的淘寶。。。不宜再多說啦。
註冊完成後啟動,會讓你先創建一個項目,其實就是一個文件夾,我們以後的代碼都存在這裡面
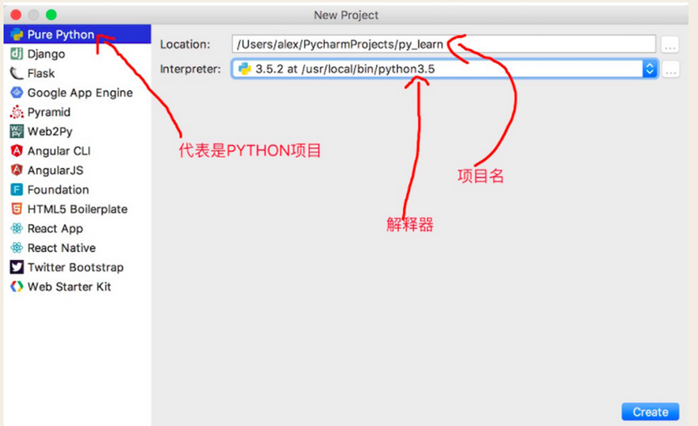
圖1-1
1.2.3 創建目錄
你以後寫的項目可能有成百上千個代碼文件 ,全放在一起可不好,所以一般把同樣功能的代碼放在一個目錄,我們現在以天為單位,為每天的學習創建一個目錄day1,day2,day3...這樣
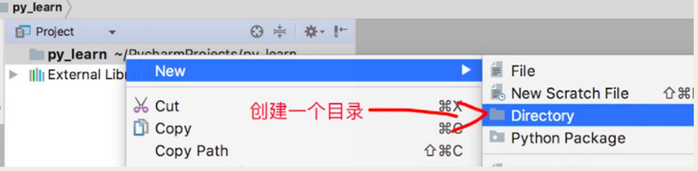
圖1-2
1.2.4 創建代碼文件
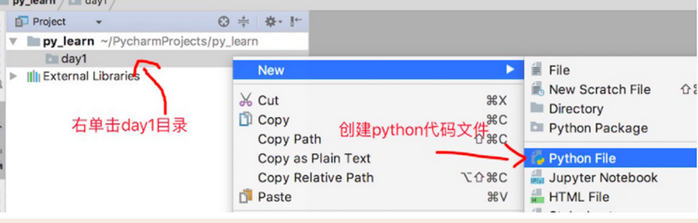
圖1-3
1.2.5 執行代碼
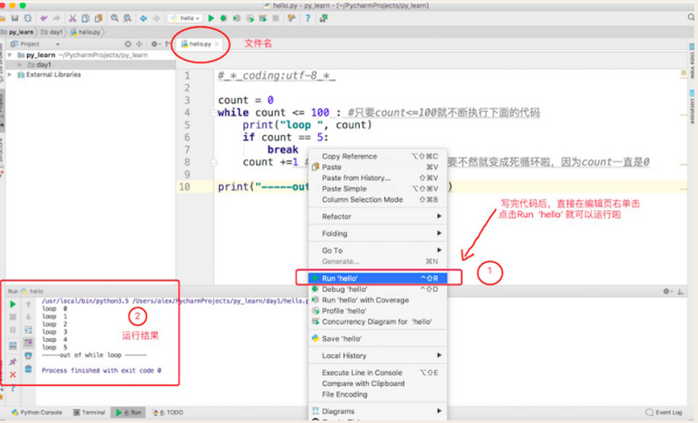
圖1-4
1.3 數據
1.3.1 什麼是數據?
x=10,10是我們要存儲的數據
1.3.2 為何數據要分不同的類型
數據是用來表示狀態的,不同的狀態就應該用不同的類型的數據去表示
1.3.3 數據類型
l 數字(整形,長整形,浮點型,複數)
l 字元串
l 位元組串:在介紹字元編碼時介紹位元組bytes類型
l 列表
l 元組
l 字典
l 集合
1.4 數字
整型與浮點型
複製代碼
#整型int
作用:年紀,等級,身份證號,qq號等整型數字相關
定義:
age=10 #本質age=int(10)
#浮點型float
作用:薪資,身高,體重,體質參數等浮點數相關
salary=3000.3 #本質salary=float(3000.3)
#二進位,十進位,八進位,十六進位
複製代碼
其他數字類型(瞭解)
複製代碼
#長整形(瞭解)
在python2中(python3中沒有長整形的概念):
>>> num=2L
>>> type(num)
<type 'long'>
1.5 字元串
#作用:名字,性別,國籍,地址等描述信息
#定義:在單引號\雙引號\三引號內,由一串字元組成
name='egon'
#優先掌握的操作:
#1、按索引取值(正向取+反向取) :只能取
#2、切片(顧頭不顧尾,步長)
#3、長度len
#4、成員運算in和not in
#5、移除空白strip
#6、切分split
#7、迴圈
1.5.1 需要掌握的操作
複製代碼
#1、strip,lstrip,rstrip
#2、lower,upper
#3、startswith,endswith
#4、format的三種玩法
#5、split,rsplit
#6、join
#7、replace
#8、isdigit
#strip
name='*egon**' print(name.strip('*')) print(name.lstrip('*')) print(name.rstrip('*'))
#lower,upper
name='egon' print(name.lower()) print(name.upper())
#startswith,endswith
name='alex_SB' print(name.endswith('SB')) print(name.startswith('alex'))
#format的三種玩法
res='{} {} {}'.format('egon',18,'male') res='{1} {0} {1}'.format('egon',18,'male') res='{name} {age} {sex}'.format(sex='male',name='egon',age=18)
#split
name='root:x:0:0::/root:/bin/bash' print(name.split(':')) #預設分隔符為空格 name='C:/a/b/c/d.txt' #只想拿到頂級目錄 print(name.split('/',1))
name='a|b|c' print(name.rsplit('|',1)) #從右開始切分
#join
tag=' ' print(tag.join(['egon','say','hello','world'])) #可迭代對象必須都是字元串
#replace
name='alex say :i have one tesla,my name is alex' print(name.replace('alex','SB',1))
#isdigit:可以判斷bytes和unicode類型,是最常用的用於於判斷字元是否為"數字"的方法
age=input('>>: ') print(age.isdigit())
1.6 列表
#作用:多個裝備,多個愛好,多門課程,多個女朋友等
#定義:[]內可以有多個任意類型的值,逗號分隔
my_girl_friends=['alex','wupeiqi','yuanhao',4,5] #本質my_girl_friends=list([...])
或
l=list('abc')
#優先掌握的操作:
#1、按索引存取值(正向存取+反向存取):即可存也可以取
#2、切片(顧頭不顧尾,步長)
#3、長度
#4、成員運算in和not in
#5、追加
#6、刪除
#7、迴圈
#ps:反向步長
l=[1,2,3,4,5,6]
#正向步長
l[0:3:1] #[1, 2, 3]
#反向步長
l[2::-1] #[3, 2, 1]
#列表翻轉
l[::-1] #[6, 5, 4, 3, 2, 1]
1.7 元組
#作用:存多個值,對比列表來說,元組不可變(是可以當做字典的key的),主要是用來讀
#定義:與列表類型比,只不過[]換成()
age=(11,22,33,44,55)本質age=tuple((11,22,33,44,55))
#優先掌握的操作:
#1、按索引取值(正向取+反向取):只能取
#2、切片(顧頭不顧尾,步長)
#3、長度
#4、成員運算in和not in
#5、迴圈
#簡單購物車,要求如下:
實現列印商品詳細信息,用戶輸入商品名和購買個數,則將商品名,價格,購買個數加入購物列表,如果輸入為空或其他非法輸入則要求用戶重新輸入
msg_dic={ 'apple':10, 'tesla':100000, 'mac':3000, 'lenovo':30000, 'chicken':10, }
msg_dic={ 'apple':10, 'tesla':100000, 'mac':3000, 'lenovo':30000, 'chicken':10, } goods_l=[] while True: for key,item in msg_dic.items(): print('name:{name} price:{price}'.format(price=item,name=key)) choice=input('商品>>: ').strip() if not choice or choice not in msg_dic:continue count=input('購買個數>>: ').strip() if not count.isdigit():continue goods_l.append((choice,msg_dic[choice],count)) print(goods_l)
1.8 字典
#作用:存多個值,key-value存取,取值速度
#定義:key必須是不可變類型,value可以是任意類型
info={'name':'egon','age':18,'sex':'male'} #本質info=dict({....})
或
info=dict(name='egon',age=18,sex='male')
或
info=dict([['name','egon'],('age',18)])
或
{}.fromkeys(('name','age','sex'),None)
#優先掌握的操作:
#1、按key存取值:可存可取
#2、長度len
#3、成員運算in和not in
#4、刪除
#5、鍵keys(),值values(),鍵值對items()
#6、迴圈
1 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],將所有大於 66 的值保存至字典的第一個key中,將小於 66 的值保存至第二個key的值中
即: {'k1': 大於66的所有值, 'k2': 小於66的所有值}
a={'k1':[],'k2':[]}
c=[11,22,33,44,55,66,77,88,99,90]
for i in c:
if i>66:
a['k1'].append(i)
else:
a['k2'].append(i)
print(a)
2 統計s='hello alex alex say hello sb sb'中每個單詞的個數
結果如:{'hello': 2, 'alex': 2, 'say': 1, 'sb': 2}
s='hello alex alex say hello sb sb'
l=s.split() dic={} for item in l: if item in dic: dic[item]+=1 else: dic[item]=1 print(dic) s='hello alex alex say hello sb sb' dic={} words=s.split() print(words) for word in words: #word='alex' dic[word]=s.count(word) print(dic)
#利用setdefault解決重覆賦值
'''
setdefault的功能
1:key存在,則不賦值,key不存在則設置預設值
2:key存在,返回的是key對應的已有的值,key不存在,返回的則是要設置的預設值
d={} print(d.setdefault('a',1)) #返回1
d={'a':2222}
print(d.setdefault('a',1)) #返回2222
'''
s='hello alex alex say hello sb sb'
dic={}
words=s.split()
for word in words: #word='alex'
dic.setdefault(word,s.count(word))
print(dic)
#利用集合,去掉重覆,減少迴圈次數
s='hello alex alex say hello sb sb' dic={} words=s.split() words_set=set(words) for word in words_set: dic[word]=s.count(word) print(dic)
1.9 集合
#作用:去重,關係運算,
#定義:
知識點回顧
可變類型是不可hash類型
不可變類型是可hash類型
#定義集合:
集合:可以包含多個元素,用逗號分割,
集合的元素遵循三個原則:
1:每個元素必須是不可變類型(可hash,可作為字典的key)
2:沒有重覆的元素
3:無序
註意集合的目的是將不同的值存放到一起,不同的集合間用來做關係運算,無需糾結於集合中單個值
優先掌握的操作:
#1、長度len
#2、成員運算in和not in
#3、|合集
#4、&交集
#5、-差集
#6、^對稱差集
#7、==
#8、父集:>,>=
#9、子集:<,<=
.關係運算
有如下兩個集合,pythons是報名python課程的學員名字集合,linuxs是報名linux課程的學員名字集合
pythons={'alex','egon','yuanhao','wupeiqi','gangdan','biubiu'}
linuxs={'wupeiqi','oldboy','gangdan'}
1. 求出即報名python又報名linux課程的學員名字集合
2. 求出所有報名的學生名字集合
3. 求出只報名python課程的學員名字
4. 求出沒有同時這兩門課程的學員名字集合
# 有如下兩個集合,pythons是報名python課程的學員名字集合,linuxs是報名linux課程的學員名字集合
pythons={'alex','egon','yuanhao','wupeiqi','gangdan','biubiu'}
linuxs={'wupeiqi','oldboy','gangdan'}
# 求出即報名python又報名linux課程的學員名字集合
print(pythons & linuxs)
# 求出所有報名的學生名字集合
print(pythons | linuxs)
# 求出只報名python課程的學員名字
print(pythons - linuxs)
# 求出沒有同時這兩門課程的學員名字集合
print(pythons ^ linuxs)
去重
1. 有列表l=['a','b',1,'a','a'],列表元素均為可hash類型,去重,得到新列表,且新列表無需保持列表原來的順序
2.在上題的基礎上,保存列表原來的順序
3.去除文件中重覆的行,肯定要保持文件內容的順序不變
4.有如下列表,列表元素為不可hash類型,去重,得到新列表,且新列表一定要保持列表原來的順序
l=[ {'name':'egon','age':18,'sex':'male'}, {'name':'alex','age':73,'sex':'male'}, {'name':'egon','age':20,'sex':'female'}, {'name':'egon','age':18,'sex':'male'}, {'name':'egon','age':18,'sex':'male'}, ]
#去重,無需保持原來的順序
l=['a','b',1,'a','a'] print(set(l))
#去重,並保持原來的順序
#方法一:不用集合
l=[1,'a','b',1,'a'] l1=[] for i in l: if i not in l1: l1.append(i) print(l1)
#方法二:藉助集合
l1=[] s=set() for i in l: if i not in s: s.add(i) l1.append(i) print(l1)
#同上方法二,去除文件中重覆的行
import os with open('db.txt','r',encoding='utf-8') as read_f,\ open('.db.txt.swap','w',encoding='utf-8') as write_f: s=set() for line in read_f: if line not in s: s.add(line) write_f.write(line) os.remove('db.txt') os.rename('.db.txt.swap','db.txt')
#列表中元素為可變類型時,去重,並且保持原來順序
l=[ {'name':'egon','age':18,'sex':'male'}, {'name':'alex','age':73,'sex':'male'}, {'name':'egon','age':20,'sex':'female'}, {'name':'egon','age':18,'sex':'male'}, {'name':'egon','age':18,'sex':'male'}, ]
# print(set(l)) #報錯:unhashable type: 'dict'
s=set()
l1=[]
for item in l:
val=(item['name'],item['age'],item['sex'])
if val not in s:
s.add(val)
l1.append(item)
print(l1)
#定義函數,既可以針對可以hash類型又可以針對不可hash類型
def func(items,key=None): s=set() for item in items: val=item if key is None else key(item) if val not in s: s.add(val) yield item print(list(func(l,key=lambda dic:(dic['name'],dic['age'],dic['sex']))))
1.10 數據類型總結
按存儲空間的占用分(從低到高)
數字
字元串
集合:無序,即無序存索引相關信息
元組:有序,需要存索引相關信息,不可變
列表:有序,需要存索引相關信息,可變,需要處理數據的增刪改
字典:無序,需要存key與value映射的相關信息,可變,需要處理數據的增刪改
按存值個數區分
標量/原子類型 數字,字元串
容器類型 列表,元組,字典
按可變不可變區分
可變 列表,字典
不可變 數字,字元串,元組
按訪問順序區分
直接訪問 數字
順序訪問(序列類型) 字元串,列表,元組
key值訪問(映射類型) 字典
1.11 運算符
身份運算(is ,is not)
is比較的是id,而雙等號比較的是值
毫無疑問,id若相同則值肯定相同,而值相同id則不一定相同
>>> x=1234567890 >>> y=1234567890 >>> x == y True >>> id(x),id(y) (3581040, 31550448) >>> x is y False
1.12 字元編碼
1.12.1 操作系統基礎
圖1-5
1.12.2 文本編輯器存取文件的原理(nodepad++,pycharm,word)
#1、打開編輯器就打開了啟動了一個進程,是在記憶體中的,所以,用編輯器編寫的內容也都是存放與記憶體中的,斷電後數據丟失
#2、要想永久保存,需要點擊保存按鈕:編輯器把記憶體的數據刷到了硬碟上。
#3、在我們編寫一個py文件(沒有執行),跟編寫其他文件沒有任何區別,都只是在編寫一堆字元而已。
1.12.3 python解釋器執行py文件的原理 ,例如python test.py
#第一階段:python解釋器啟動,此時就相當於啟動了一個文本編輯器
#第二階段:python解釋器相當於文本編輯器,去打開test.py文件,從硬碟上將test.py的文件內容讀入到記憶體中(小複習:pyhon的解釋性,決定瞭解釋器只關心文件內容,不關心文件尾碼名)
#第三階段:python解釋器解釋執行剛剛載入到記憶體中test.py的代碼( ps:在該階段,即真正執行代碼時,才會識別python的語法,執行文件內代碼,當執行到name="egon"時,會開闢記憶體空間存放字元串"egon")
1.12.4 總結python解釋器與文件本編輯的異同
#1、相同點:python解釋器是解釋執行文件內容的,因而python解釋器具備讀py文件的功能,這一點與文本編輯器一樣
#2、不同點:文本編輯器將文件內容讀入記憶體後,是為了顯示或者編輯,根本不去理會python的語法,而python解釋器將文件內容讀入記憶體後,可不是為了給你瞅一眼python代碼寫的啥,而是為了執行python代碼、會識別python語法。
1.13 字元編碼介紹
1.13.1 什麼是字元編碼
複製代碼
電腦要想工作必須通電,即用‘電’驅使電腦幹活,也就是說‘電’的特性決定了電腦的特性。電的特性即高低電平(人類從邏輯上將二進位數1對應高電平,二進位數0對應低電平),關於磁碟的磁特性也是同樣的道理。結論:電腦只認識數字
很明顯,我們平時在使用電腦時,用的都是人類能讀懂的字元(用高級語言編程的結果也無非是在文件內寫了一堆字元),如何能讓電腦讀懂人類的字元?
必須經過一個過程:
#字元--------(翻譯過程)------->數字
#這個過程實際就是一個字元如何對應一個特定數字的標準,這個標準稱之為字元編碼
以下兩個場景下涉及到字元編碼的問題:
#1、一個python文件中的內容是由一堆字元組成的,存取均涉及到字元編碼問題(python文件並未執行,前兩個階段均屬於該範疇)
#2、python中的數據類型字元串是由一串字元組成的(python文件執行時,即第三個階段)
1.13.2 字元編碼的發展史與分類
電腦由美國人發明,最早的字元編碼為ASCII,只規定了英文字母數字和一些特殊字元與數字的對應關係。最多只能用 8 位來表示(一個位元組),即:2**8 = 256,所以,ASCII碼最多只能表示 256 個符號
圖1-6
當然我們編程語言都用英文沒問題,ASCII夠用,但是在處理數據時,不同的國家有不同的語言,日本人會在自己的程式中加入日文,中國人會加入中文。
而要表示中文,單拿一個位元組表表示一個漢子,是不可能表達完的(連小學生都認識兩千多個漢字),解決方法只有一個,就是一個位元組用>8位2進位代表,位數越多,代表的變化就多,這樣,就可以儘可能多的表達出不通的漢字,所以中國人規定了自己的標準gb2312編碼,規定了包含中文在內的字元->數字的對應關係。
日本人規定了自己的Shift_JIS編碼,南韓人規定了自己的Euc-kr編碼,所以迫切需要一個世界的標準(能包含全世界的語言)於是unicode應運而生。
ascii用1個位元組(8位二進位)代表一個字元
unicode常用2個位元組(16位二進位)代表一個字元,生僻字需要用4個位元組
這時候亂碼問題消失了,所有的文檔我們都使用但是新問題出現了,如果我們的文檔通篇都是英文,你用unicode會比ascii耗費多一倍的空間,在存儲和傳輸上十分的低效
本著節約的精神,又出現了把Unicode編碼轉化為“可變長編碼”的UTF-8編碼。UTF-8編碼把一個Unicode字元根據不同的數字大小編碼成1-6個位元組,常用的英文字母被編碼成1個位元組,漢字通常是3個位元組,只有很生僻的字元才會被編碼成4-6個位元組。如果你要傳輸的文本包含大量英文字元,用UTF-8編碼就能節省空間
1.13.3 總結字元編碼的發展可分為三個階段
階段一:現代電腦起源於美國,最早誕生也是基於英文考慮的ASCII
ASCII:一個Bytes代表一個字元(英文字元/鍵盤上的所有其他字元),1Bytes=8bit,8bit可以表示0-2**8-1種變化,即可以表示256個字元
ASCII最初只用了後七位,127個數字,已經完全能夠代表鍵盤上所有的字元了(英文字元/鍵盤的所有其他字元),後來為了將拉丁文也編碼進了ASCII表,將最高位也占用了
#階段二:為了滿足中文和英文,中國人定製了GBK
GBK:2Bytes代表一個中文字元,1Bytes表示一個英文字元
為了滿足其他國家,各個國家紛紛定製了自己的編碼
日本把日文編到Shift_JIS里,南韓把韓文編到Euc-kr里
#階段三:各國有各國的標準,就會不可避免地出現衝突,結果就是,在多語言混合的文本中,顯示出來會有亂碼。如何解決這個問題呢???
1、能夠相容萬國字元
#2、與全世界所有的字元編碼都有映射關係,這樣就可以轉換成任意國家的字元編碼
這就是unicode(定長), 統一用2Bytes代表一個字元, 雖然2**16-1=65535,但unicode卻可以存放100w+個字元,因為unicode存放了與其他編碼的映射關係,準確地說unicode並不是一種嚴格意義上的字元編碼表
nicode的詳情:
鏈接:https://pan.baidu.com/s/1dEV3RYp
很明顯對於通篇都是英文的文本來說,unicode的式無疑是多了一倍的存儲空間(二進位最終都是以電或者磁的方式存儲到存儲介質中的)
於是產生了UTF-8(可變長,全稱Unicode Transformation Format),對英文字元只用1Bytes表示,對中文字元用3Bytes,對其他生僻字用更多的Bytes去存
#總結:
記憶體中統一採用unicode,浪費空間來換取可以轉換成任意編碼(不亂碼),硬碟可以採用各種編碼,如utf-8,保證存放於硬碟或者基於網路傳輸的數據量很小,提高傳輸效率與穩定性。
1.13.4 總字元編碼應用之文件編輯器
#1、保證不亂嗎的核心法則就是,字元按照什麼標準而編碼的,就要按照什麼標準解碼,此處的標準指的就是字元編碼
#2、在記憶體中寫的所有字元,一視同仁,都是unicode編碼,比如我們打開編輯器,輸入一個“你”,我們並不能說“你”就是一個漢字,此時它僅僅只是一個符號,該符號可能很多國家都在使用,根據我們使用的輸入法不同這個字的樣式可能也不太一樣。只有在我們往硬碟保存或者基於網路傳輸時,才能確定”你“到底是一個漢字,還是一個日本字,這就是unicode轉換成其他編碼格式的過程了
unicode----->encode-------->utf-8
utf-8-------->decode---------->unicode
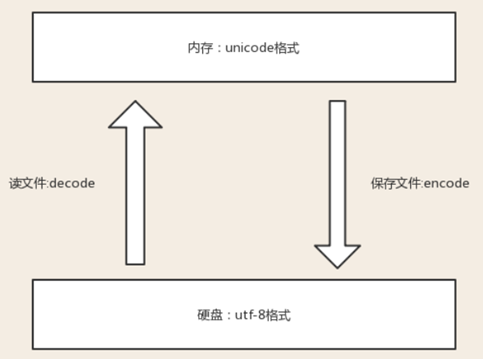
圖1-7
1.13.5 字元編碼應用之python
執行python程式的三個階段
python test.py (執行test.py的第一步,一定是先將文件內容讀入到記憶體中)
階段一:啟動python解釋器
階段二:python解釋器此時就是一個文本編輯器,負責打開文件test.py,即從硬碟中讀取test.py的內容到記憶體中
此時,python解釋器會讀取test.py的第一行內容,#coding:utf-8,來決定以什麼編碼格式來讀入記憶體,這一行就是來設定python解釋器這個軟體的編碼使用的編碼格式這個編碼,
可以用sys.getdefaultencoding()查看,如果不在python文件指定頭信息#-*-coding:utf-8-*-,那就使用預設的
python2中預設使用ascii,python3中預設使用utf-8
階段三:讀取已經載入到記憶體的代碼(unicode編碼格式),然後執行,執行過程中可能會開闢新的記憶體空間,比如x="egon"
記憶體的編碼使用unicode,不代表記憶體中全都是unicode,
在程式執行之前,記憶體中確實都是unicode,比如從文件中讀取了一行x="egon",其中的x,等號,引號,地位都一樣,都是普通字元而已,都是以unicode的格式存放於記憶體中的,但是程式在執行過程中,會申請記憶體(與程式代碼所存在的記憶體是倆個空間)用來存放python的數據類型的值,而python的字元串類型又涉及到了字元的概念
比如x="egon",會被python解釋器識別為字元串,會申請記憶體空間來存放字元串類型的值,至於該字元串類型的值被識別成何種編碼存放,這就與python解釋器的有關了,而python2與python3的字元串類型又有所不同。
1.14 python2與python3字元串類型的區別
在python2中有兩種字元串類型str和unicode
str類型
當python解釋器執行到產生字元串的代碼時(例如x='上'),會申請新的記憶體地址,然後將'上'編碼成文件開頭指定的編碼格式
要想看x在記憶體中的真實格式,可以將其放入列表中再列印,而不要直接列印,因為直接print()會自動轉換編碼,這一點我們稍後再說。
#coding:gbk
x='上' y='下' print([x,y]) #['\xc9\xcf', '\xcf\xc2']
#\x代表16進位,此處是c9cf總共4位16進位數,一個16進位四4個比特位,4個16進位數則是16個比特位,即2個Bytes,這就證明瞭按照gbk編碼中文用2Bytes
print(type(x),type(y)) #(<type 'str'>, <type 'str'>)
記憶體中的數據通常用16進位表示,2位16進位數據代表一個位元組,如\xc9,代表兩位16進位,一個位元組
gbk存中文需要2個bytes,而存英文則需要1個bytes,它是如何做到的???!!!
gbk會在每個bytes,即8位bit的第一個位作為標誌位,標誌位為1則表示是中文字元,如果標誌位為0則表示為英文字元
x=‘你a好’
轉成gbk格式二進位位
8bit+8bit+8bit+8bit+8bit=(1+7bit)+(1+7bit)+(0+7bit)+(1+7bit)+(1+7bit)
這樣電腦按照從左往右的順序讀:
#連續讀到前兩個括弧內的首位標誌位均為1,則構成一個中午字元:你
#讀到第三個括弧的首位標誌為0,則該8bit代表一個英文字元:a
#連續讀到後兩個括弧內的首位標誌位均為1,則構成一個中午字元:好
也就是說,每個Bytes留給我們用來存真正值的有效位數只有7位,而在unicode表中存放的只是這有效的7位,至於首位的標誌位與具體的編碼有關,即在unicode中表示gbk的方式為:
(7bit)+(7bit)+(7bit)+(7bit)+(7bit)
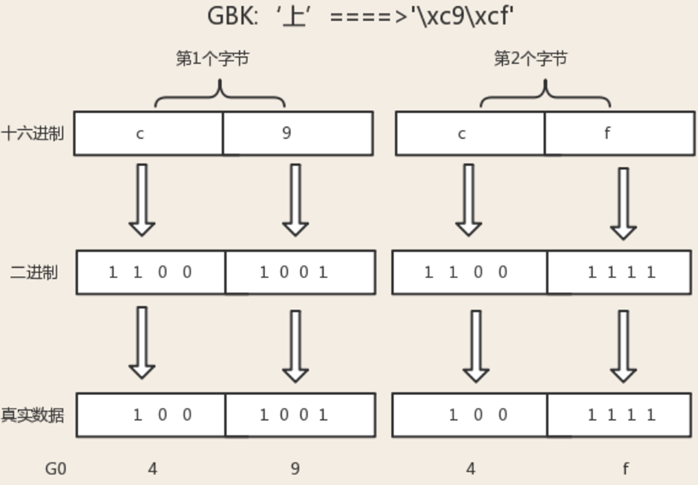
圖1-8
按照上圖翻譯的結果,我們可以去unicode關於漢字的對應關係中去查:鏈接:https://pan.baidu.com/s/1dEV3RYp
# f=open(r'C:\Users\Administrator\PycharmProjects\python20期\day2\a.txt') # f=open('a.txt','r',encoding='utf-8') # data=f.read() # print(data) # print(f) # f.close() #文件關閉,回收操作系統的資源 # print(f) # f.read() # with open('a.txt','r',encoding='utf-8') as f: #f=open('a.txt','r',encoding='utf-8') # pass
1.15 文件處理
1.15.1 讀操作:r只讀模式,預設是rt文本讀
# f=open('a.txt','r',encoding='utf-8') # # data1=f.read() # # print('=1===>',data1) # # data2=f.read() # # print('=2===>',data2) # # # print(f.readlines()) # # # print(f.readline(),end='') # # print(f.readline(),end='') # # print(f.readline(),end='') # # # f.close()
1.15.2 寫操作:w只寫模式,預設是wt文本寫,如果文件不存在則創建,存在則清空+覆蓋
f=open('a.txt','w',encoding='utf-8') # f.write('11111\n') # f.write('222222\n') # f.write('1111\n2222\n3333\n') # f.writelines(['哈哈哈哈\n','你好','alex']) f.close()
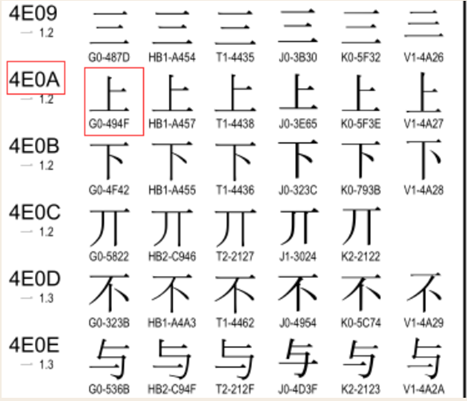
圖1-9
可以看到“”上“”對應的gbk(G0代表的是gbk)編碼就為494F,即我們得出的結果,而上對應的unicode編碼為4E0A,我們可以將gbk-->decode-->unicode
#coding:gbk x='上'.decode('gbk') y='下'.decode('gbk') print([x,y]) #[u'\u4e0a', u'\u4e0b']
unicode類型
當python解釋器執行到產生字元串的代碼時(例如s=u'林'),會申請新的記憶體地址,然後將'林'以unicode的格式存放到新的記憶體空間中,所以s只能encode,不能decode
#coding:gbk x=u'上' #等同於 x='上'.decode('gbk') y=u'下' #等同於 y='下'.decode('gbk') print([x,y]) #[u'\u4e0a', u'\u4e0b'] print(type(x),type(y)) #(<type 'unicode'>, <type 'unicode'>)
unicode這麼好,不會亂碼,那python2為何還那麼彆扭,搞一個str出來呢?python誕生之時,unicode並未像今天這樣普及,很明顯,好的東西你能看得見,龜叔早就看見了,龜叔在python3中將str直接存成unicode,我們定義一個str,無需加u首碼,就是一個unicode
在python3 中也有兩種字元串類型str和bytes
str是unicode
#coding:gbk x='上' #當程式執行時,無需加u,'上'也會被以unicode形式保存新的記憶體空間中, print(type(x)) #<class 'str'> #x可以直接encode成任意編碼格式 print(x.encode('gbk')) #


