
獨立索引: 獨立索引是指索引列不能是表達式的一部分,也不能是函數的參數 例1: SELECT actor_id FROM actor WHERE actor_id+1=5 --這種寫法,就算在actor_id上建立了索引,也不起效 例2: SELECT .... WHERE TO_DAYS(CURR ...
獨立索引:
獨立索引是指索引列不能是表達式的一部分,也不能是函數的參數
例1:
SELECT actor_id FROM actor WHERE actor_id+1=5 --這種寫法,就算在actor_id上建立了索引,也不起效
例2:
SELECT .... WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10 --這也是一種錯誤的寫法
多列索引(聯合索引)&選擇合適的索引列順序:
多列索引(Multiple-Column Indexes)也稱為複合索引(composite index),也即同時對多個列建立索引。
什麼時候用多列索引?
- 當出現伺服器對多個索引做相交操作時(通常有多個AND條件),通常意味著需要一個包含所有相關列的多列索引,而不是多個獨立的單列索引。
- 當伺服器需要對多個索引做聯合操作時(通常有多個OR條件),通常需要耗費大量CPU和記憶體資源在演算法的緩存、排序和合併操作上。特別是當其中有些索引的選擇性不高,需要合併掃描返回大量數據的時候。
多列索引的生效規則:
比如(a,b,c),abc都是拍好序的,在任意一段a的下麵b都是排好序的,任何一段b下麵c都是拍好序的。多列索引的生效原則是從前往後依次使用生效,如果中間某個索引沒有使用,那麼斷點前面的索引部分起作用,斷點後面的索引沒有起作用;
還需註意:(a,b,c)多列索引和 (a,c,b)是不一樣的,看上面的圖也看得出來關係順序是不一樣的;
分析幾個實際例子來加強理解
(0)select * from mytable where a=3 and b=5 and c=4; --abc三個索引都在where條件裡面用到了,而且都發揮了作用 (1)select * from mytable where c=4 and b=6 and a=3; --這條語句列出來只想說明 mysql沒有那麼笨,where裡面的條件順序在查詢之前會被mysql自動優化,效果跟上一句一樣 (2)select * from mytable where a=3 and c=7; --a用到索引,b沒有用,所以c是沒有用到索引效果的 (3)select * from mytable where a=3 and b>7 and c=3; --a用到了,b也用到了,c沒有用到,這個地方b是範圍值,也算斷點,只不過自身用到了索引 (4)select * from mytable where b=3 and c=4; --因為a索引沒有使用,所以這裡 bc都沒有用上索引效果 (5)select * from mytable where a>4 and b=7 and c=9; --a用到了 b沒有使用,c沒有使用 (6)select * from mytable where a=3 order by b; --a用到了索引,b在結果排序中也用到了索引的效果,前面說了,a下麵任意一段的b是排好序的 (7)select * from mytable where a=3 order by c; --a用到了索引,但是這個地方c沒有發揮排序效果,因為中間斷點了,使用 explain 可以看到 filesort (8)select * from mytable where b=3 order by a; --b沒有用到索引,排序中a也沒有發揮索引效果
對於如何選擇索引的列順序有一個經驗法則:將選擇性最高的列放到索引最前列。(參考①)
當不需要考慮排序和分組時,將選擇性最高的列放到前面通常是很好的。這時候索引的作用只是用於優化WHERE條件的查找
首碼索引和索引的選擇性:
首碼索引能有效減小索引文件的大小,提高索引的速度。但是首碼索引也有它的壞處:
1.不能再OORDER BY 或 GROUP BY 中使用首碼索引;
2.也不能把他們用作覆蓋索引(Covering index)。
建立首碼索引的語法:
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
示例:
ALTER TABLE city ADD KEY(cityname(7));
什麼叫做索引的選擇性呢?①
所謂索引的選擇性(Selectivity),是指不重覆索引值(也叫作基數,Cardinality)與表記錄數(#T)的比值
Selectivity = Cardinality / #T
顯然選擇性的取值範圍為(0,1],選擇性越高的索引值價值越大
SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles;
- +-------------+
- | Selectivity |
- +-------------+
- | 0.0379 |
- +-------------+
比如employees表只有一個索引<emp_no>,那麼如果我們想按名字搜索一個人,就只能全表掃描了:
EXPLAIN SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido';
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 300024 | Using where |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
這樣全表掃描效率很低,所以我們考慮到把名字建立索引,有兩種選擇,建<first_name>或<first_name,last_name>,看下兩個索引的選擇性:
SELECT count(DISTINCT(first_name))/count(*) AS Selectivity FROM employees; +-------------+ | Selectivity | +-------------+ | 0.0042 | +-------------+ SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees; +-------------+ | Selectivity | +-------------+ | 0.9313 | +-------------+
從結果看顯然<first_name>選擇性太低,<first_name,last_name>選擇性好。但是first_name和last_name加起來長度為30,有沒有兼顧長度和選擇性的辦法?可以考慮用first_name和last_name的前幾個字元建立索引,例如<first_name, left(last_name, 3)>,看看其選擇性:
SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees; +-------------+ | Selectivity | +-------------+ | 0.7879 | +-------------+
選擇性還不錯,但離0.9313還是有點距離,那麼把last_name首碼加到4:
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees; +-------------+ | Selectivity | +-------------+ | 0.9007 | +-------------+
這時選擇性已經很理想了,而這個索引的長度只有18,比<first_name, last_name>短了接近一半,我們把這個首碼索引 建上:
ALTER TABLE employees ADD INDEX `first_name_last_name4` (first_name, last_name(4));
此時再執行一遍按名字查詢,比較分析一下與建索引前的結果:
SHOW PROFILES; +----------+------------+---------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+---------------------------------------------------------------------------------+ | 87 | 0.11941700 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' | | 90 | 0.00092400 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' | +----------+------------+---------------------------------------------------------------------------------+
性能的提升是顯著的,查詢速度提高了120多倍。
聚簇索引
覆蓋索引
冗餘索引和覆蓋索引
未使用的索引
應該刪除未被使用的索引。有兩個工具可以幫助定位未使用的索引。
1.在Percona Server或者MariaDB中先打開userstates伺服器變數(預設是關閉的),然後讓伺服器正常運行一段時間,再通過查詢INFORMATION_SCHEMA.INDEX_STATISTICS就能查到每個索引的使用頻率。
2.在Percona Toolkit中的pt-index-usage,該工具可以讀取查詢日誌,並對日誌中的每條查詢進行EXPLAIN操作,然後列印出關於索引和查詢的報告
索引和鎖
InnoDB只有在訪問行的時候才會對其枷鎖,而索引能夠減少InnoDB訪問的行數,從而減少鎖的數量
InnoDB在二級索引上使用共用(讀)鎖,但訪問主鍵索引需要排他(寫)鎖。這消除了覆蓋索引的可能性,並且使得SELECT FOR UPDATE比LOCK IN SHARE MODE 或非鎖定查詢要慢很多
InnoDB的主鍵選擇與插入優化
在使用InnoDB存儲引擎時,如果沒有特別的需要,請永遠使用一個與業務無關的自增欄位作為主鍵。為什麼呢?
因為InnoDB使用聚集索引,數據記錄本身被存於主索引(一顆B+Tree)的葉子節點上。這就要求同一個葉子節點內(大小為一個記憶體頁或磁碟頁)的各條數據記錄按主鍵順序存放,因此每當有一條新的記錄插入時,MySQL會根據其主鍵將其插入適當的節點和位置,如果頁面達到裝載因數(InnoDB預設為15/16),則開闢一個新的頁(節點)。
如果表使用自增主鍵,那麼每次插入新的記錄,記錄就會順序添加到當前索引節點的後續位置,當一頁寫滿,就會自動開闢一個新的頁。如下圖所示:
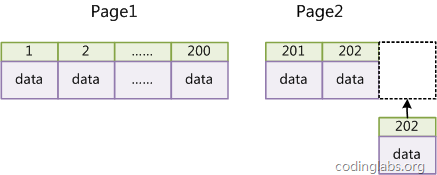
這樣就會形成一個緊湊的索引結構,近似順序填滿。由於每次插入時也不需要移動已有數據,因此效率很高,也不會增加很多開銷在維護索引上。
如果使用非自增主鍵(如果身份證號或學號等),由於每次插入主鍵的值近似於隨機,因此每次新紀錄都要被插到現有索引頁得中間某個位置:
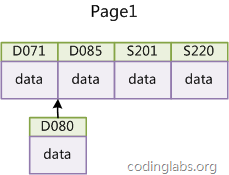
此時MySQL不得不為了將新記錄插到合適位置而移動數據,甚至目標頁面可能已經被回寫到磁碟上而從緩存中清掉,此時又要從磁碟上讀回來,這增加了很多開銷,同時頻繁的移動、分頁操作造成了大量的碎片,得到了不夠緊湊的索引結構,後續不得不通過OPTIMIZE TABLE來重建表並優化填充頁面。
因此,只要可以,請儘量在InnoDB上採用自增欄位做主鍵。
參考文獻:
[1] Baron Schwartz等 著,寧海元等 譯 ;《高性能MySQL》(第3版); 電子工業出版社 ,2013
[2] 張洋blog, http://blog.codinglabs.org/articles/theory-of-mysql-index.html
[3]匿名blog, http://www.cnblogs.com/codeAB/p/6387148.html


