
背景 隨著公司業務的高速發展以及數據爆炸式的增長,當前公司各產線都有關於搜索方面的需求,但是以前的搜索服務系統由於架構與業務上的設計,不能很好的滿足各個業務線的期望,主要體現下麵三個問題: 1. 不能支持對語句級別的搜索,大量業務相關的屬性根本無法實現 2. 沒有任何搜索相關的指標評價體系 3. 擴 ...
背景
隨著公司業務的高速發展以及數據爆炸式的增長,當前公司各產線都有關於搜索方面的需求,但是以前的搜索服務系統由於架構與業務上的設計,不能很好的滿足各個業務線的期望,主要體現下麵三個問題:
- 不能支持對語句級別的搜索,大量業務相關的屬性根本無法實現
- 沒有任何搜索相關的指標評價體系
- 擴展性與維護性特別差
基於現狀,對行業內的搜索服務做出充分調研,確認使用ElasticSearch做底層索引存儲,同時重新設計現有搜索服務,使其滿足業務方對維護性、定製化搜索排序方面的需求。
整體技術架構
滬江搜索服務底層基於分散式搜索引擎ElasticSearch,ElasticSearch是一個基於Lucene構建的開源,分散式,Restful搜索引擎;能夠達到近實時搜索,穩定,可靠,快速響應的要求。

搜索服務整體分為5個子系統
- 搜索服務(Search Server) : 提供搜索與查詢的功能
- 更新服務(Index Server) : 提供增量更新與全量更新的功能
- Admin 控制台 : 提供UI界面,方便索引相關的維護操作
- ElasticSearch存儲系統 : 底層索引數據存儲服務
- 監控平臺: 提供基於ELK日誌與zabbix的監控
外部系統介面設計
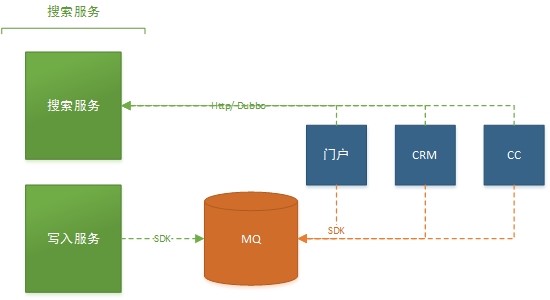
- 查詢
- 查詢介面提供http的調用方式,當出現跨機房訪問的時候,請使用http介面,其餘都可以使用dubbo RPC調用
- 增量更新
- 數據增量更新介面採用提供MQ的方式接入。當業務方出現數據更新的時候,只需將數據推送到對應的MQ通道中即可。更新服務會監聽每個業務方通道,及時將數據更新到ElasticSearch中
- 全量索引
- 更新服務會調用業務方提供的全量Http介面(該介面需提供分頁查詢等功能)
全量更新
眾所周知,全量更新的功能在搜索服務中是必不可少的一環。它主要能解決以下三個問題
- 業務方本身系統的故障,出現大量數據的丟失
- 業務高速發展產生增減欄位或者修改分詞演算法等相關的需求
- 業務冷啟動會有一次性導入大批量數據的需求
基於上面提到的問題,我們與業務方合作實現了全量索引。但是在這個過程中,我們也發現一個通用的問題。在進行全量更新的時候,其實增量更新也在同時進行,如果這兩種更新同時在進行的話,就會有遇到少量增量更新的數據丟失。比如說下麵這個場景
- 業務方發現自己搜索業務alias_A數據大量數據丟失,所以進行索引重建。其中alias_A是別名,就是我們通常說alias,但是底層真正的索引是index_201701011200(建議:索引裡面包含時間屬性,這樣就能知道是什麼創建的)
- 首先創建一個新的索引index_201706011200,然後從數據中拉出數據並插入ES中,並記錄時間戳T1,最後索引完成的時間戳為T2,並切換搜索別名index_1指向index_201706011200。
- 索引創建成功之後的最新數據為T1這個時刻的,但是T1到T2這段時間的數據,並沒有獲取出來。同時index_201701011200老索引還在繼續消費MQ中的數據,包括T1到T2時間內的缺少數據。
- 所以每次索引重建的時候,都會缺少T1到T2時間內的數據。
最後,針對上面這個場景,我們提出通過zookeeper分散式鎖來暫停index consumer的消費,具體步驟如下
- 創建new_index
- 獲取該index 對應的別名,來修改分散式鎖的狀態為stop
- index consumer監控stop狀態,暫停索引數據的更新
- new_index索引數據創建完畢,更新分散式鎖狀態為start
- index consumer監控start狀態,繼續索引數據的更新
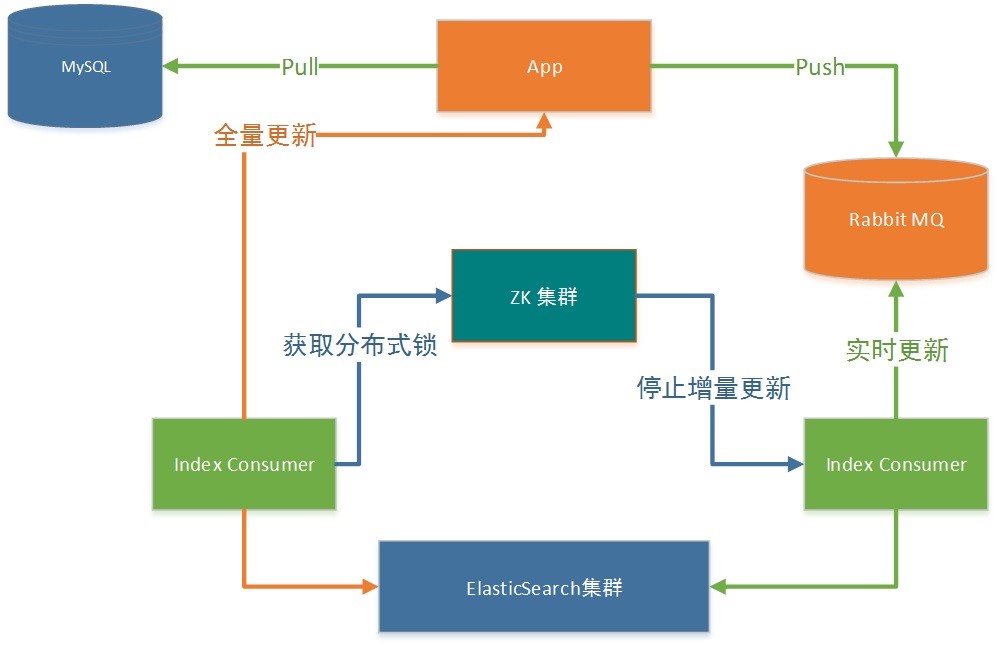
這樣的話,我們就不用擔心在創建索引的這段時間內,數據會有缺少的問題。相信大家對於這種方式解決全量與增量更新數據有所體會。
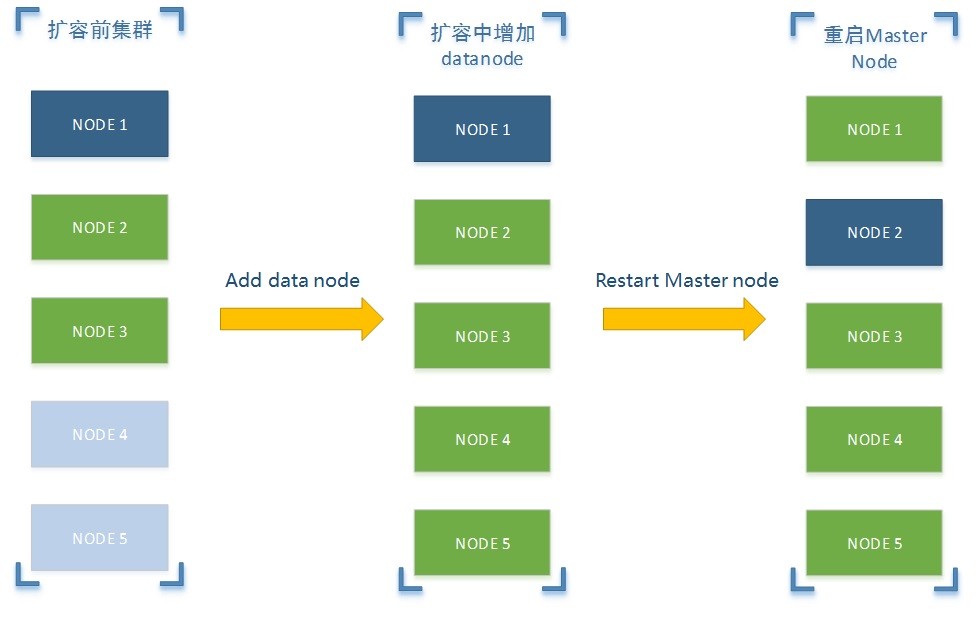
集群無縫擴容
數據量爆炸式的增加,導致我們ES集群最終還是遇到了容量不足的問題。在此背景下,同時結合ES本身提供的無縫擴容功能,我們最終決定對線上ES集群進行了線上的無縫擴容,將從原來的3台機器擴容為5台,具體步驟如下
- 擴容前準備
- 目前我們線上已經有3台機器正在運行著,其中node1為master節點,node2和node3為data節點,節點通信採用單播的形式而非廣播的方式。
- 準備2台(node4與node5)機器,其中機器本身配置與ES配置參數需保持一致
- 擴容中增加節點
- 啟動node4與node5(註意一個一個啟動),啟動完成之後,查看node1,2,3,4,5節點狀態,正常情況下node1,2,3節點都已發現node4與node5,並且各節點之間狀態應該是一致的
- 重啟master node
- 修改node1,2,3節點配置與node4,5保持一致,然後順序重啟node2與node3,一定要優先重啟data node,最後我們在重啟node1(master node).到此為止,我們的線上ES集群就線上無縫的擴容完畢
部署優化
- 查詢與更新服務分離
- 查詢服務與更新服務在部署上進行物理隔離,這樣可以隔離更新服務的不穩定對查詢服務的影響
- 預留一半記憶體
- ES底層存儲引擎是基於Lucene,Lucenede的倒排索引是先在記憶體中生成,然後定期以段的形式非同步刷新到磁碟上,同時操作系統也會把這些段文件緩存起來,以便更快的訪問。所以Lucene的性能取決於和OS的交互,如果你把所有的記憶體都分配給Elasticsearch,不留一點給Lucene,那你的全文檢索性能會很差的。所有官方建議,預留一半以上記憶體給Lucene使用
- 記憶體不要超過32G
- 跨32G的時候,會出現一些現象使得記憶體使用率還不如低於32G,具體原因請參考官方提供的這篇文章 Don’t Cross 32 GB!
- 儘量避免使用wildcard
- 其實使用wildcard查詢,有點類似於在資料庫中使用左右通配符查詢。(如:*foo*z這樣的形式)
- 設置合理的刷新時間
- ES中預設index.refresh_interval參數為1s。對於大多數搜索場景來說,數據生效時間不需要這麼及時,所以大家可以根據自己業務的容忍程度來調整
總結
本章主要介紹公司搜索服務的整體架構,重點對全量更新中數據一致性的問題,ES線上擴容做了一定的闡述,同時列舉了一些公司在部署ES上做的一些優化。本文主要目的,希望大家通過閱讀滬江搜索實踐,能夠給廣大讀者帶來一些關於搭建一套通用搜索的建議。


