
本文版權歸博客園和作者吳雙本人共同所有 轉載和爬蟲請註明原文地址 www.cnblogs.com/tdws。 本文參考和學習資料 《ES權威指南》 一.基本概念 存儲數據到ES中的行為叫做索引,每個索引可以包含多個類型,這些不同的類型存儲著多個文檔,每個文檔有多個屬性。 索引 index/index ...
本文版權歸博客園和作者吳雙本人共同所有 轉載和爬蟲請註明原文地址 www.cnblogs.com/tdws。
本文參考和學習資料 《ES權威指南》
一.基本概念
存儲數據到ES中的行為叫做索引,每個索引可以包含多個類型,這些不同的類型存儲著多個文檔,每個文檔有多個屬性。
索引 index/indexes相當於傳統關係資料庫中的資料庫,是存儲關係型文檔的地方。
索引在ES做動詞的時候,索引一個文檔就是存儲一個文檔到索引(名詞)中,以便被檢閱和查詢到。類似於insert。
預設下,一個文檔中的每個屬性都是被索引的。沒被索引的屬性是不能搜索到的。
二.ES集群 主分片 副分片 健康狀態
垂直的硬體擴容是有極限的,真正的擴容能力來自於水平擴容(為集群內增加更多節點),集群是由一個或者多個擁有相同 cluster.name 配置的節點組成, 它們共同承擔數據和負載的壓力。當有節點加入集群中或者從集群中移除節點時,集群將會重新平均分佈所有的數據。
主節點負責管理集群範圍內所有的變更,增加刪除索引和增加刪除節點等。主節點不涉及文檔級別的變更和搜索等操作。任何一個節點都可接受請求,任何一個節點都知道任意文檔所處位置。
curl -XGET 'localhost:9200/_cluster/health?pretty' 獲取集群健康狀態
status 欄位指示著當前集群在總體上是否工作正常。它的三種顏色含義如下:
green 所有的主分片和副本分片都正常運行。
yellow 所有的主分片都正常運行,但不是所有的副本分片都正常運行。
red 有主分片沒能正常運行。
分片是一個底層的工作單元,是數據的容器,一個分片是一個Lucene實例。它本身就是一個完整的搜索引擎,到本文最後的分頁,相信你能更加理解。應用不會與分片交互。一個分片可以使主分片或者副本分片。副本分片只是主分片的一個拷貝。副本分片用於從災難中保護數據並未搜索讀取操作提供服務,註意只是讀操作。
預設情況下創建一個索引,會被分配5個分片。當然我們也可以指定分片數量還有副本數量,比如:
curl -XPUT 'localhost:9200/blogs?pretty' -H 'Content-Type: application/json' -d'
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
假設我們目前集群中只有一個節點,那麼剛纔三個分片的存儲是這樣的。即使我們設置了1個副本分片也沒用,因為相同數據的主分片和副本分片在一個節點上沒有任何意義。

如果此時,我們為集群增加一個節點,主分片和副本分片是下圖這樣的。副本分片得以創建,並分配在新節點上。現在我們的容災能力就可以允許失去一臺節點的數據,數據讀取服務節點就是兩個。

接下來,集群中再加入節點,情況如下圖所示。為了提高更強的服務能力和容災能力,均勻分佈了主分片和副本分片,現在我們三個node,失去任意一臺,都能保障數據和服務。

最後,關閉node1,使集群失去MASTER, 而集群必須擁有一個主節點來保證正常工作,所以發生的第一件事情就是選舉一個新的主節點: Node 2 。在失去Master的同時,也失去了主分片 1 和 2 ,並且在缺失主分片的時候索引也不能正常工作。 如果此時來檢查集群的狀況,我們看到的狀態將會為 red :不是所有主分片都在正常工作。幸運的是,在其它節點上存在著這兩個主分片的完整副本, 所以新的主節點立即將這些分片在 Node 2 和 Node 3 上對應的副本分片提升為主分片, 此時集群的狀態將會為 yellow 。 這個提升主分片的過程是瞬間發生的,如同按下一個開關一般。

如果現在恢復node1,如果 Node 1 依然擁有著之前的分片,它將嘗試去重用它們,同時僅從主分片複製發生了修改的數據文件。
三.基本的操作
一個文檔的 _index 、 _type 和 _id 唯一標識一個文檔。
索引僅僅是一個邏輯上的命名空間,這個命名空間由一個或者多個分片組合在一起。對於應用程式而言,無需關註分片,只需要知道一個文檔位於一個索引內。
索引index名稱必須小寫,不能以下劃線開頭,不能有逗號。類型type名稱可以大寫或者小寫,但是不能以下劃線或者句號開頭,不應該包含逗號並且長度在265字元及以內。
當你創建一個新文檔的時候,要麼主動給id,要麼讓ES自動生成。所以,確保創建一個新文檔的最簡單辦法是,使用索引請求的 POST 形式讓 Elasticsearch 自動生成唯一 _id,比如:
POST /website/blog/ { ... }
以下兩種方式為等效操作:
PUT /website/blog/123?op_type=create { ... }
PUT /website/blog/123/_create { ... }
在獲取文檔的時候,_source欄位是用於篩選我們只想要的目標欄位,比如
GET /website/blog/123?_source=title,text
如果想要得到http響應頭部,可以通過傳遞 -i 比如
curl -i -XGET http://localhost:9200/website/blog/124?pretty
如果只想得到source欄位,不想得到任何其他元數據,使用方式如下:
GET /website/blog/123/_source
如果查詢文檔是否存在,使用Http HEAD,比如:
curl -i -XHEAD http://localhost:9200/website/blog/123 //存在則返回200 OK,不存在則是404Not Found
在 Elasticsearch 中文檔是 不可改變 的,不能修改它們。 相反,如果想要更新現有的文檔,需要 重建索引或者進行替換, 我們可以使用相同的 index API 進行實現。和使用創建時PUT是一樣的,ES內部都做了。部分更新,也是如此。使用DELETE刪除文檔,刪除文檔不會立即將文檔從磁碟中刪除,只是將文檔標記為已刪除狀態,隨著你不斷的索引更多的數據,Elasticsearch 將會在後臺清理標記為已刪除的文檔。
四.併發衝突的解決
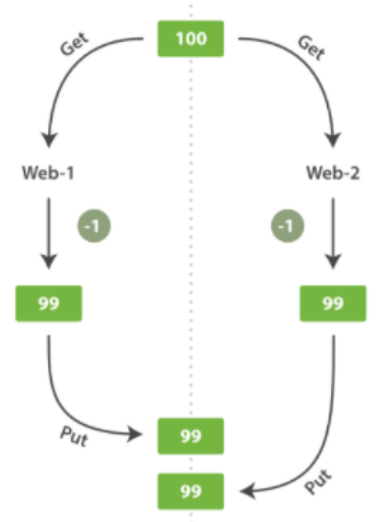
假設上圖操作的是庫存數量stock_count ,web_1 對 stock_count 所做的更改已經丟失,因為 web_2 不知道它的 stock_count 的拷貝已經過期。變更越頻繁,讀數據和更新數據的間隙越長,也就越可能丟失變更。在資料庫領域中,有悲觀和樂觀兩種方法通常被用來確保併發更新時變更不會丟失:
悲觀併發控制
悲觀併發控制一般鎖住當前被操作的資源。
樂觀併發控制
Elasticsearch 中使用的這種方法假定衝突是不可能發生的,並且不會阻塞正在嘗試的操作。 然而,如果源數據在讀寫當中被修改,更新將會失敗。應用程式接下來將決定該如何解決衝突。 例如,可以重試更新、使用新的數據、或者將相關情況報告給用戶。Elasticsearch 是分散式的,當創建和更新文檔的時候,如果你是多個node,並且還有replication備份數據,這中間就會有時間差存在,並且還會存在檢索-修改-重建索引間隔。或者說併發更新發生的時候,所獲取併在處理中的數據,可能已經被其他請求更新掉,這就導致數據的過期,結果就是覆蓋更新,過期數據覆蓋新數據。在ES中 我們解決此問題的方式就是利用更新中指定_version版本號來確保相互衝突的更新不會丟失。所有文檔的更新或刪除 API,都可以接受 version 參數,比如:
PUT /website/blog/1?version=1
過指定了version,如果請求到達ES後,該條數據version已經不是1了,這時就會更新失敗並返回409 Conflict響應碼。之後應該怎麼處理,就取決於你的場景了,正如上面所說的可以重試更新、使用新的數據、或者將相關情況報告給用戶。另外一種方式是使用外部版本號,而非ES內置自增的版本號。外部的版本號源於你自己的系統控制,比如更新一條ES文檔,指定使用外部版本號為5:
PUT /website/blog/2?version=5&version_type=external
為了併發控制,下一次你的請求給到了version為10,如果你的請求version小於等於上面的5則會更新失敗,像前面提到的409一樣,只有新version大於ES文檔已有version,更新才會成功。
PUT /website/blog/2?version=10&version_type=external
ES文檔是不可變的,即使是在部分更新情況下。比如:
POST /website/blog/1/_update { "doc" : { "tags" : [ "testing" ], "views": 0 } } //其將會覆蓋現有欄位,增加新欄位。被稱為Update API
部分更新的時候,如果被更新的文檔還不存在,這時應該使用upsert參數
POST /website/pageviews/1/_update { "script" : "ctx._source.views+=1", "upsert": { "views": 1 } }
如果你某個場景中經常會出現所更新文檔不存在的情況下,那麼使用它是明智之選,該方式會在文檔存在的時候,直接執行更新腳本將值應用,不存在的時候,則執行upsert.
ES update API還提供了retry_on_conflict參數,指示了返回失敗之前,要重試多少次。
POST /website/pageviews/1/_update?retry_on_conflict=5
update API和前面index API所提到的樂觀併發控制一樣,也支持制定version參數來控制衝突。
ES提供了mget API (multi-get),可以減少網路傳輸時間等,比如:
GET /_mget { "docs" : [ { "_index" : "website", "_type" : "blog", "_id" : 2 }, { "_index" : "website", "_type" : "pageviews", "_id" : 1, "_source": "views" } ] }
可以看到這段代碼中index和type 實在docs數組的item項中。所得到的響應數組中,每個item和使用單個get拿到的結果是一樣的。
如果想檢索的數據都在相同的 _index 中(甚至相同的 _type 中),則可以在 URL 中指定預設的 /_index或者預設的 /_index/_type 。
你仍然可以通過單獨請求覆蓋這些值:
GET /website/blog/_mget { "docs" : [ { "_id" : 2 }, { "_type" : "pageviews", "_id" : 1 } ] }
事實上,如果所有文檔的 _index 和 _type 都是相同的,你可以只傳一個 ids 數組,而不是整個 docs 數組:
GET /website/blog/_mget { "ids" : [ "2", "1" ] }
如果數組中某個尋找目標未找到結果,則響應數組中,其他值正常,未找到的found欄位則為false "found" : false,並不妨礙其他文檔。所以在應用中,應該檢查的不是200還是404,而是found欄位標記。
既然提供了mget, 同時bulk API也提供了單個步驟進行多次create index, update和delete請求。
POST /_bulk {
"delete": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }} { "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }} { "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} } { "doc" : {"title" : "My updated blog post"} }
delete是沒有請求體的,而create,update 請求體是必須的 如上所示。如果其中哪個操作失敗了,則會在響應中的一個對應的item中給出相應的error. 而成功的則給出200.比如
{ "took": 3, "errors": true, "items": [
{ "create": { "_index": "website", "_type": "blog", "_id": "123", "status": 409, "error": "DocumentAlreadyExistsException [[website][4] [blog][123]: document already exists]" }},
{ "index": { "_index": "website", "_type": "blog", "_id": "123", "_version": 5, "status": 200 }} ] }
bulk 不是原子性的,不能用它來實現事務控制。每個請求是單獨處理的,因此一個請求的成功或失敗不會影響其他的請求。為什麼是下麵這種格式的寫法,為什麼是每個請求單獨處理,這是因為不同的文檔數據,他們主分片可能不同,每個文檔可能被分配給不同節點,所以ES這種設計的方式是最明智的。如果使用json數組,看起來簡便了,實則導致需要ES解析大量數據,占用更多記憶體,讓JVM來花大量時間進行回收。相反ES現有的方式,則可以直接將原始請求轉發到正確的分片上,用最小的記憶體處理。
也許你正在批量索引日誌數據到相同的 index 和 type 中。 但為每一個文檔指定相同的元數據是一種浪費。相反,可以像 mget API 一樣,在 bulk 請求的 URL 中接收預設的 /_index 或者 /_index/_type ,比如:
POST /website/_bulk { "index": { "_type": "log" }} { "event": "User logged in" }
POST /website/log/_bulk { "index": {}} { "event": "User logged in" } { "index": { "_type": "blog" }} { "title": "Overriding the default type" }
五.分散式文檔存儲
當索引一個文檔的時候,文檔將被存儲到ES的一個主分片當中。ES索引文檔到分片遵從公式:shard = hash(routing) % number_of_primary_shards 。
routing是一個可變值,預設你為文檔_id。 如上公式hash出的結果是 0 到 number_of_primary_shards-1 之間的餘數,將來我們尋找數據所在分片,就是這樣找到的。所以在創建索引的時候就要確定好主分片數量,並且永遠不改變primary_shards ,因為一旦改變了,之前hash路由的值將全部無效,文檔也就不能被正確找到。當然如果你想擴容,可以有其他的奇技淫巧,後面將會提到。

比如我們有三個節點,兩個主分片,每個主分片有兩個副本。我們依然可以將請求指向任意節點,每個節點都知道任一文檔的位置,並轉發請求到目標節點。為了擴展負載,更好的做法是輪詢所有節點,以單節點免壓力過大。我想,ES知道任一文檔的位置,通過上一段給出的公式即可。
向node1發送存儲數據請求,路由到node3主分片上,複製給node1和node2,最後返回結果給node1

向node1 發送更新數據請求,路由到node3主分片,更改_source,重新索引數據,成功後複製到node1和node2。如果是部分更新的時候,通知副本節點更新的時候,不是轉發部分更新的內容,而是轉發完整文檔的新版本。

六.搜索
上面,我們可以簡單的把ES當作NOSQL風格的分散式文檔存儲系統。我們可以將文檔扔到ES里,然後根據ID檢索。但其真正的強大之處並不在於此,而是從無規律的數據找出有意義的信息,從大數據到大信息。
搜索(search) 可以做到:
1.在類似於 gender 或者 age 這樣的欄位 上使用結構化查詢,join_date 這樣的欄位上使用排序,就像SQL的結構化查詢一樣。
2.全文檢索,找出所有匹配關鍵字的文檔並按照相關性(relevance) 排序後返回結果。
3.以上二者兼而有之。
下麵分析一則查詢:
GET /_search (curl -XGET 'localhost:9200/_search?pretty')
{ "hits" : { "total" : 14, "hits" :
[ { "_index": "us", "_type": "tweet", "_id": "7", "_score": 1,
"_source": { "date": "2014-09-17", "name": "John Smith", "tweet": "The Query DSL is really powerful and flexible", "user_id": 2 } },
... 9 RESULTS REMOVED ... ], "max_score" : 1 },
"took" : 4,
"_shards" : { "failed" : 0, "successful" : 10, "total" : 10 }, "timed_out" : false }
解釋一下查詢結果:
hits是返回結果最重要的部分,其中total代表匹配總數,每個文檔都有元數據_index庫,_type類型,_id編號,_source值欄位,_score代表相關性,文檔按照相關性倒序返回。
_took欄位代表搜索花了多少ms .
_shards告訴我們參與分片的總數和成功與失敗多少個。正常情況下不會出現失敗,如果遇到災難故障比如同一分片原始數據和副本都丟失了,那麼對這個分片將沒有可用副本做響應,ES則會報告有失敗的分片,但正確返回剩餘分片結果。
time_out指示了是否查詢超時,在查詢的時候,你也可以設置超時時間 GET /_search?timeout=10ms 。關於超時需要特別註意的是,超時並不是停止執行查詢,而是告知正在協調節點,在所設置的時間內,返回目前已查詢收集到的的結果。在後臺,即使結果已經返回給我們了,但是查詢仍然在執行。為什麼說是返回已收集到的文檔,是因為在集群內搜索的時候,協調節點轉發請求到其他節點的主分片或者副分片上,彙集結果。
不記得什麼是協調節點了嗎?Elasticsearch集群中作為客戶端接入的節點叫協調節點。協調節點會將客戶端請求路由到集群中合適的分片上。對於讀請求來說,協調節點每次會選擇不同的分片處理請求,以實現負載均衡。
一些在一個或多個特殊的索引並且在一個或者多個特殊的類型中進行搜索查詢的示範:
/_search 在所有的索引中搜索所有的類型
/gb/_search 在 gb 索引中搜索所有的類型
/gb,us/_search 在 gb 和 us 索引中搜索所有的文檔
/g*,u*/_search 在任何以 g 或者 u 開頭的索引中搜索所有的類型
/gb/user/_search 在 gb 索引中搜索 user 類型
/gb,us/user,tweet/_search 在 gb 和 us 索引中搜索 user 和 tweet 類型
/_all/user,tweet/_search 在所有的索引中搜索 user 和 tweet 類型
分頁搜索,如果每頁展示 5 條結果,可以用下麵方式請求得到 1 到 3 頁的結果:
GET /_search?size=5 GET /_search?size=5&from=5 GET /_search?size=5&from=10
ES返回分頁數據的思路是 : 比如在一個有 5 個主分片的索引中搜索。 當我們請求結果的第一頁(結果從 1 到 10 ),每一個分片產生前 10 的結果,並且返回給 協調節點 ,協調節點對 50 個結果排序得到全部結果的前 10 個。
這也說明在深度分頁中,所將付出的代價,比如獲取第1000頁,那麼每個節點查詢出10010條,最後到協調節點中,從50050條拋棄50040條取10條. 補充一句 為什麼每個分片可以做我們想要的查詢,想要的數量和結果?是因為每個分片都是一個Lucene實例,是一個完整的搜索引擎。


