
參考文檔: 本文涉及postgresql基於非同步方式的主從複製的配置驗證。 一.主從複製簡介 1. 基於文件的日誌傳送 創建一個高可用性(HA)集群配置可採用連續歸檔,集群中主伺服器工作在連續歸檔模式下,備伺服器工作在連續恢復模式下(1台或多台可隨時接管主伺服器),備持續從主伺服器讀取WAL文件。 ...
參考文檔:
- 備機日誌傳送:https://www.postgresql.org/docs/9.6/static/warm-standby.html
- 英文文檔:https://www.postgresql.org/docs/current/static/index.html
- 中文文檔:http://www.postgres.cn/docs/9.6/
- pg_basebackup:https://www.postgresql.org/docs/current/static/app-pgbasebackup.html
- 參考1:http://blog.csdn.net/wlwlwlwl015/article/details/53287855
- 參考2:http://www.cnblogs.com/yjf512/p/4499547.html
本文涉及postgresql基於非同步方式的主從複製的配置驗證。
一.主從複製簡介
1. 基於文件的日誌傳送
創建一個高可用性(HA)集群配置可採用連續歸檔,集群中主伺服器工作在連續歸檔模式下,備伺服器工作在連續恢復模式下(1台或多台可隨時接管主伺服器),備持續從主伺服器讀取WAL文件。
連續歸檔不需要對資料庫表做任何改動,可有效降低管理開銷,對主伺服器的性能影響也相對較低。
直接從一個資料庫伺服器移動WAL記錄到另一臺伺服器被稱為日誌傳送,PostgreSQL通過一次一文件(WAL段)的WAL記錄傳輸實現了基於文件的日誌傳送。
- 日誌傳送所需的帶寬取根據主伺服器的事務率而變化;
- 日誌傳送是非同步的,即WAL記錄是在事務提交後才被傳送,那麼在一個視窗期內如果主伺服器發生災難性的失效則會導致數據丟失,還沒有被傳送的事務將會被丟失;
- 數據丟失視窗可以通過使用參數archive_timeout進行限制,可以低至數秒,但同時會增加文件傳送所需的帶寬。
2. 流複製
PostgreSQL在9.x之後引入了主從的流複製機制,所謂流複製,就是備伺服器通過tcp流從主伺服器中同步相應的數據,主伺服器在WAL記錄產生時即將它們以流式傳送給備伺服器,而不必等到WAL文件被填充。
- 預設情況下流複製是非同步的,這種情況下主伺服器上提交一個事務與該變化在備伺服器上變得可見之間客觀上存在短暫的延遲,但這種延遲相比基於文件的日誌傳送方式依然要小得多,在備伺服器的能力滿足負載的前提下延遲通常低於一秒;
- 在流複製中,備伺服器比使用基於文件的日誌傳送具有更小的數據丟失視窗,不需要採用archive_timeout來縮減數據丟失視窗;
- 將一個備伺服器從基於文件日誌傳送轉變成基於流複製的步驟是:把recovery.conf文件中的primary_conninfo設置指向主伺服器;設置主伺服器配置文件的listen_addresses參數與認證文件即可。
二.驗證環境
1. 操作系統
CentOS-7-x86_64-Everything-1511
2. PostgresSQL版本
PostgreSQL 9.6.3:https://www.postgresql.org/download/linux/redhat/
3. 主機
採用VMware ESXi虛擬出的2台伺服器:
host1:psql_master,10.11.4.186
host2:psql_standby,10.11.4.187
三.主庫配置
1. 創建複製用戶
#需要一個賬號進行主從同步 postgres=#create role repl login replication encrypted password 'repl@123';
2. 認證文件pg_hba.conf
#配置從庫可以採用repl賬號進行同步 [root@psql_master ~]# vim /var/lib/pgsql/9.6/data/pg_hba.conf host replication repl 10.11.4.187/32 md5
3. 主庫配置文件postgresql.conf
[root@psql_master ~]# vim /var/lib/pgsql/9.6/data/postgresql.conf #監聽埠 listen_addresses = '*' #主從設置為熱備模式,流複製必選參數 wal_level = hot_standby #流複製允許的連接進程,一般同standby數量一致 max_wal_senders = 2 #流複製在沒有基於文件的連續歸檔時,主伺服器可能在備機收到WAL日誌前回收這些舊的WAL,此時備機需要重新從一個新的基礎備份初始化;可設置wal_keep_segments為一個足夠高的值來確保舊的WAL段不會被太早重用;1個WAL日誌為16MB,所以在設置wal_keep_segments時,在滿足空間的前提下可以儘量設置大一些 wal_keep_segments = 64 #預設參數,非主從配置相關參數,表示到資料庫的連接數,一般從庫做主要的讀服務時,設置值需要高於主庫 max_connections = 100
4. 重啟服務
#同時註意打開防火牆埠打開 [root@psql_master ~]# systemctl restart postgresql-9.6
四.從庫配置
從庫安裝postgresql後,暫不初始化,如果從庫已初始化,可以清空其data目錄(預設安裝是/ /var/lib/pgsql/9.6/data/目錄)。
1. 基礎備份
[root@psql_standby ~]# pg_basebackup -h 10.11.4.186 -p 5432 -U repl -F p -P -D /var/lib/pgsql/9.6/data/ #-h,主庫主機,-p,主庫服務埠; #-U,複製用戶; #-F,p是預設輸出格式,輸出數據目錄和表空間相同的佈局,t表示tar格式輸出; #-P,同--progress,顯示進度; #-D,輸出到指定目錄; #因為主庫採用的是md5認證,這裡需要密碼認證。

2. 備份目錄許可權
#基於root賬號做的基礎備份,需要將相關目錄文件的許可權變更 [root@psql_standby ~]# chown -R postgres:postgres /var/lib/pgsql/9.6/data/
3. 從庫配置文件postgresql.conf
#在基礎備份時,初始化文件是從主庫複製來的,所以配置文件一致,可將wal_level,max_wal_senders與wal_keep_segments等參數註釋,以下是新增或修改的參數 [root@psql_standby ~]# vim /var/lib/pgsql/9.6/data/postgresql.conf #在備份的同時允許查詢 hot_standby = on #可選,流複製最大延遲 max_standby_streaming_delay = 30s #可選,從向主報告狀態的最大間隔時間 wal_receiver_status_interval = 10s #可選,查詢衝突時向主反饋 hot_standby_feedback = on #預設參數,非主從配置相關參數,表示到資料庫的連接數,一般從庫做主要的讀服務時,設置值需要高於主庫 max_connections = 1000
4. 恢覆文件recovery.conf
#在做基礎備份時,也可通過-R參數在備份結束後自動生產一個recovery.conf文件 [root@psql_standby ~]# cp /usr/pgsql-9.6/share/recovery.conf.sample /var/lib/pgsql/9.6/data/recovery.conf [root@psql_standby ~]# chown postgres:postgres /var/lib/pgsql/9.6/data/recovery.conf [root@psql_standby ~]# vim /var/lib/pgsql/9.6/data/recovery.conf #指明從庫身份 standby_mode = on #連接到主庫信息 primary_conninfo = 'host=10.11.4.186 port=5432 user=repl password=repl@123' #同步到最新數據 recovery_target_timeline = 'latest' #指定觸發文件,文件存在時,將觸發從庫提升為主庫,前提是必須設置”standby_mode = on”;如果不設置此參數,也可採用”pg_ctl promote“觸發從庫切換成主庫 #trigger_file = ‘/var/lib/pgsql/9.6/data/trigger_activestandby’
5. 重啟服務
[root@psql_standby ~]# systemctl restart postgresql-9.6
五.使用驗證
1. 查看進程
1)主庫sender進程
[root@psql_master ~]# ps -ef | grep postgres

2)從庫receiver過程
[root@psql_standby ~]# ps -ef | grep postgres

2. 查看複製狀態(主庫)
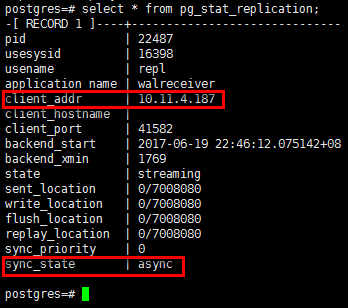
postgres=# \x postgres=# select * from pg_stat_replication; #pid,sender進程; #usesysid,複製用戶id; #usename,複製用戶名; #application_name,複製進程名; #client_addr,從庫客戶端地址; #client_hostname,從庫客戶端名; #client_port,從庫客戶端port; #backend_start,主從複製開始時間; #backend_xmin,當前後端的xmin範圍,由備機提供; #state,同步狀態,startup:連接中;catchup:同步中;streaming:同步; #sent_location,主傳送wal的位置; #write_location,從接收wal的位置; #flush_location,從刷盤的wal位置; #replay_location,從同步到資料庫的wal位置; #sync_priority,同步優先順序,0表示非同步;1~?表示同步,數字越小優先順序越高; #sync_state, async:非同步;sync:同步;potential;當前是非同步,但可能升級到同步模式; #另外,”select pg_is_in_recovery();“命令也可以查看主從狀態,false是主,true為從。
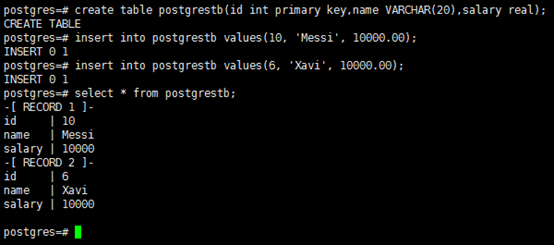
3. 表複製測試
1)建表(主庫)
postgres=# create table postgrestb(id int primary key,name VARCHAR(20),salary real); postgres=# insert into postgrestb values(10, 'Messi', 10000.00); postgres=# insert into postgrestb values(6, 'Xavi', 10000.00); postgres=# select * from postgrestb;
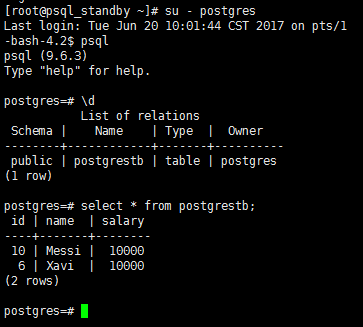
2)查詢(從庫)
[root@psql_standby ~]# su - postgres -bash-4.2$ psql postgres=# \d postgres=# select * from postgrestb;
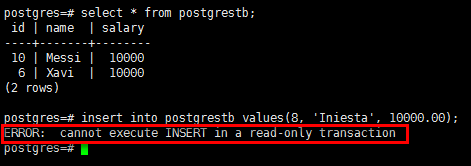
3)從庫寫測試
#從庫只讀,不能寫入數據 postgres=# insert into postgrestb values(8, 'Iniesta', 10000.00);
4. 主從切換
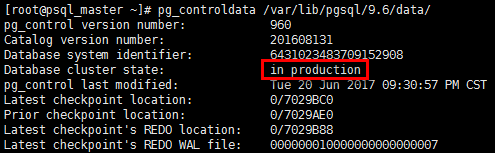
1)切換前狀態
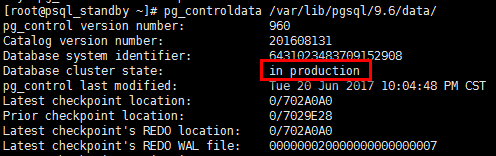
[root@psql_master ~]# pg_controldata /var/lib/pgsql/9.6/data/
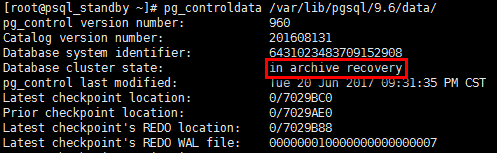
[root@psql_standby ~]# pg_controldata /var/lib/pgsql/9.6/data/
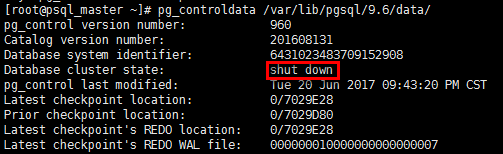
2)主庫故障
#以postgres賬戶停止主庫 [root@psql_master ~]# su - postgres -c "pg_ctl stop -m fast"

[root@psql_master ~]# pg_controldata /var/lib/pgsql/9.6/data/
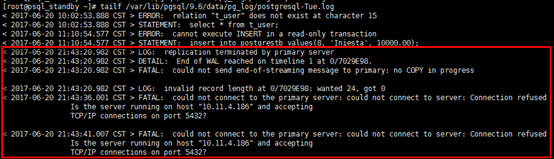
3)創建用戶查看從庫日誌
#日誌已經明確是不能連接到主庫 [root@psql_standby ~]# tailf /var/lib/pgsql/9.6/data/pg_log/postgresql-Tue.log
4)激活從庫
#採用”pg_ctl promote“切換從庫為主庫; #切換後,從庫的recovery.conf文件名字變成了recovery.done [root@psql_standby ~]# su - postgres -c "pg_ctl promote"

5)查看從庫日誌,狀態與進程
[root@psql_standby ~]# tailf /var/lib/pgsql/9.6/data/pg_log/postgresql-Tue.log
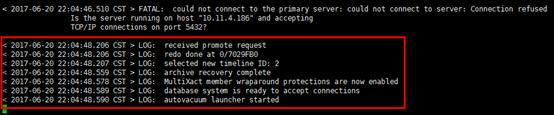
[root@psql_standby ~]# tailf /var/lib/pgsql/9.6/data/pg_log/postgresql-Tue.log
[root@psql_standby ~]# ps aux | grep postgres

6)總結
- 配合keepalived可以做postgresql的高可用,需要寫檢測主從狀態腳本,可參考:https://github.com/francs/PostgreSQL-Keepalived-HA;
- 檢測trigger_file存在與否也可完成從庫切換主庫;
- 從庫切換到主庫,故障的原主庫恢復後,可將其降為備庫,主要是設置recovery.conf文件與postgres.conf文件,最差的情況下可清空此時的備庫(原主庫)的$PGDATA,重新同步數據。
六.同步流複製(補充)
1. 與非同步流複製的區別
- 同步複製必須等待主庫與從庫都寫完wal後才能commit事務,在一定程度上會增加事務的響應時間;
- 配置同步複製步驟:
- 在主庫postgresql.conf文件中設置參數synchronous_standby_names為1個字元串或"*",存在多個從庫時使用逗號分隔;
- 在主庫postgresql.conf文件中設置參數synchronous_commit參數設置為"on",控制是否等待wal日誌buffer刷入磁碟再返回用戶事務狀態信息,同步流複製需要打開;
- 從庫的recovery.conf中primary_conninfo參數需要指明"application_name"。
2. 註意事項
- 當只有1個從做同步流複製時,如果從庫故障,則主庫的寫也會掛起(可以看到postgres下會有數據操作的waiting進程),此時的方案建議採用1+1+n的方式,即1 master+1 slave(同步)+n slave(非同步),做同步的slave故障後,可從n個非同步slave中選舉1個切換成同步模式;
- 設置synchronous_commit = off 後,即使同步複製模式的從庫故障,主庫的事務也不會出現等待掛起的現象。


