
1》hadoop簡介: Hadoop是一個開發和運行處理大規模數據的軟體平臺,是Apache的一個用java語言實現開源軟體框架,實現在大量電腦組成的集群中對海量數據進行 分散式計算.Hadoop框架中最核心設計就是:HDFS和MapReduce,HDFS提供了海量數據的存儲,MapReduce提 ...
1》hadoop簡介:
Hadoop是一個開發和運行處理大規模數據的軟體平臺,是Apache的一個用java語言實現開源軟體框架,實現在大量電腦組成的集群中對海量數據進行 分散式計算.Hadoop框架中最核心設計就是:HDFS和MapReduce,HDFS提供了海量數據的存儲,MapReduce提供了對數據的計算;HDFS:Hadoop Distributed File System,Hadoop的分散式文件系統.大文件被分成預設64M一塊的數據塊分佈存儲在集群機器中;MapReduce:Hadoop為每一個input split創建一個task調用 Map計算,在此task中依次處理此split中的一個個記錄(record),map會將結果以key--value的形式輸出,hadoop負責按key值將map的輸出整理後作為Reduce的輸 入,Reduce Task的輸出為整個job的輸出,保存在HDFS上.
Hadoop的集群主要由 NameNode,DataNode,Secondary NameNode,JobTracker,TaskTracker組成.
NameNode中記錄了文件是如何被拆分成block以及這些block都存儲到了哪些DateNode節點.
NameNode同時保存了文件系統運行的狀態信息.
DataNode中存儲的是被拆分的blocks.
Secondary NameNode幫助NameNode收集文件系統運行的狀態信息.
JobTracker當有任務提交到Hadoop集群的時候負責Job的運行,負責調度多個TaskTracker.
TaskTracker負責某一個map或者reduce任務.
1>hdfs分散式文件系統
Hadoop分散式文件系統(HDFS)被設計成適合運行在通用硬體(commodity hardware)上的分散式文件系統。它和現有的分散式文件系統有很多共同點。 但同時,它和其他的分散式文件系統的區別也是很明顯的。HDFS是一個高度容錯性的系統,適合部署在廉價的機器上。HDFS能提供高吞吐量的數據訪 問,非常適合大規模數據集上的應用。
HDFS的優點:
· 1)高容錯性
數據自動保存多個副本;
副本丟失後,自動恢復;
· 2)適合批處理
移動計算而非數據;
數據位置暴露給計算框架 ;
· 3)適合大數據處理
GB、TB、甚至PB級數據 ;
百萬規模以上的文件數量 ;
10K+節點規模;
· 4)流式文件訪問
一次性寫入,多次讀取;
保證數據一致性 ;
· 5)可構建在廉價機器上
通過多副本提高可靠性 ;
提供了容錯和恢復機制;
2>mapreduce大規模數據集的並行運算
MapReduce是一種編程模型,用於大規模數據集(大於1TB)的並行運算。概念"Map(映射)"和"Reduce(歸約)",是它們的主要思想,都是從函 數式編程語言里借來的,還有從矢量編程語言里借來的特性。它極大地方便了編程人員在不會分散式並行編程的情況下,將自己的程式運行在分散式系統 上。 當前的軟體實現是指定一個Map(映射)函數,用來把一組鍵值對映射成一組新的鍵值對,指定併發的Reduce(歸約)函數,用來保證所有映射的 鍵值對中的每一個共用相同的鍵組。
2》安裝環境
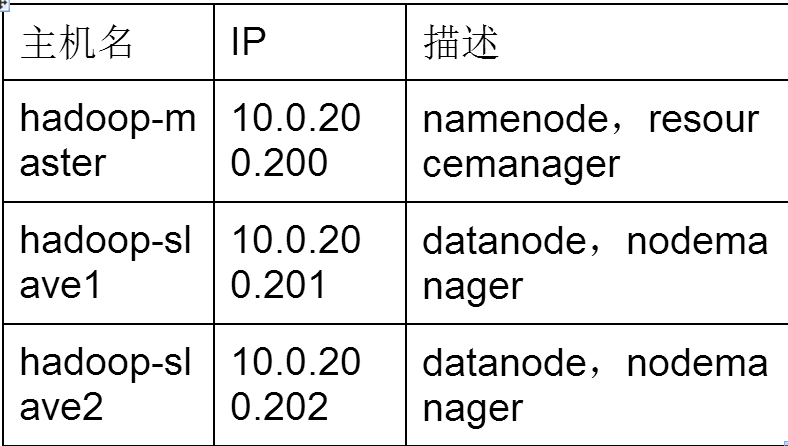
實驗需要3台虛擬機,一主兩從式,一臺主機master當協調節點處理多個slave節點,用戶能訪問master節點來管理整個hadoop集群
硬體:3台虛擬機
記憶體:至少512MB
硬碟:至少20G
操作系統:rhel6.4 64位 最小化安裝
1>安裝openssh
在每台虛擬機上安裝openssh,最小化虛擬機預設沒有安裝,自行配置yum安裝openssh。3台虛擬機之間需要相互ssh登錄
[root@master ~]#yum install openssh* -y
2>配置主機名和IP
為了方便管理,規範性命名,使用連續網段的IP的靜態IP
[root@master ~]#vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop-master
[root@master ~]#vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="System eth0"
HWADDR=B8:97:5A:00:4E:54
IPADDR=10.0.200.200
NETMASK=255.255.0.0
GATEWAY=10.0.2.253
DNS1=114.114.114.114
配置/etc/hosts,把/etc/hosts的IP信息分發到所有主機上
[root@master ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.200.200 hadoop-master
10.0.200.201 hadoop-slave1
10.0.200.202 hadoop-slave2
3>安裝JDK
安裝JDK參考百度,本實驗使用 jdk1.8.0_31版本,由於hadoop使用java語言編寫,所有運行hadoop的機器都要安裝jdk安裝JDK如下效果:
解壓之後在/etc/profile文件中添加如下內容:
export JAVA_HOME=/usr/local/src/jdk1.8.0_31
export HADOOP_INSTALL=/home/hadoop/hadoop.2.6.0
export PATH=$PATH:$HADOOP_INSTALL/bin
更新文件:source /etc/profile
[root@master ~]# java -version
java version "1.8.0_31"
Java(TM) SE Runtime Environment (build 1.8.0_31-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.31-b07, mixed mode)
4>ssh無密登錄;
在所有機器上創建hadoop用戶,統一密碼hadoop,在master上創建hadoop用戶的公鑰,改名authorized_keys分發到所有機器上,授予600許可權
[root@master ~]#useradd hadoop
[root@master ~]#passwd hadoop
[root@master ~]#su - hadoop
[hadoop@master ~]$ssh-keygen -t rsa
[hadoop@master ~]$ cd .ssh
[hadoop@master .ssh]$ mv id_rsa.pub authorized_keys
[hadoop@master .shh]$ chmod 600 authorized_keys
[hadoop@master .ssh]$ scp authorized_keys hadoop-slave1:~/.ssh/
[hadoop@master .ssh]$ scp authorized_keys hadoop-slave2:~/.ssh/
可以看到在master上可以無密登錄到slave1上,在後面數百台機器上運行hadoop集群;
註意:在客戶端創建的.ssh的許可權必須是700,否則不會成功;
5>hadoop安裝和配置
在主節點上操作,解壓hadoop-2.6.0.tar.gz到hadoop用戶家目錄,編輯hadoop的配置文件,用hadoop用戶操作(編輯文件沒有許可權時記得用root用戶給予 許可權);
hadoop官網下載: http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.6.0/
[hadoop@master ~]# su - hadoop
[hadoop@master ~]$ tar zxvf hadoop-2.6.0.tar.gz
[hadoop@master ~]$ cd hadoop-2.6.0/etc/hadoop/
修改hadoop-env.sh和yarn-env.sh文件的JAVA_HOME來指定JDK的路徑
[hadoop@master ~]$ vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_31
[hadoop@master ~]$ vi yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_31
編輯從節點列表文件slaves
[hadoop@master ~]$vi slaves
hadoop-slvae1
hadoop-slave2
編輯core-site.xml,指定主節點的地址和埠
[hadoop@master ~]$ vi core-site.xml
<configuration>
<property>
<name>fs.default.FS</name>
<value>hdfs://hadoop-master:9000</value>
</property>
</configuration>
複製mapred-site.xml.template為mapred-site.xml,指定mapreduce工作方式
[hadoop@master ~]$vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
編輯yarn-site.xml,指定yran的主節點和埠
[hadoop@master ~]$vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master:9001</value>
</property>
</configuration>
將hadoop-2.6.0文件夾分發到其他2台虛擬機上
[hadoop@master ~]$scp -r hadoop-2.6.0 hadoop-slave1:~
[hadoop@master ~]$scp -r hadoop-2.6.0 hadoop-slave2:~
3》運行測試
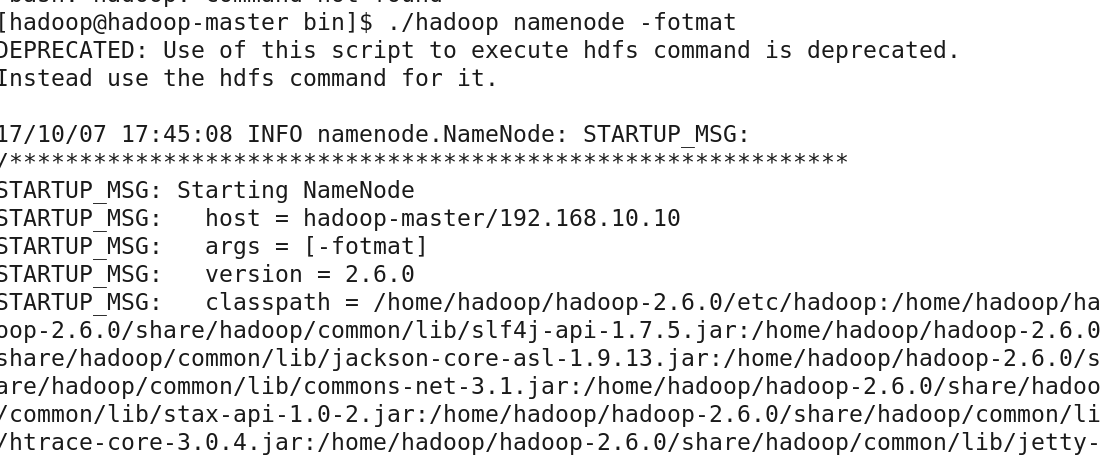
格式化分散式文件系統
[hadoop@master ~]$ hadoop-2.6.0/bin/hadoop namenode -fotmat
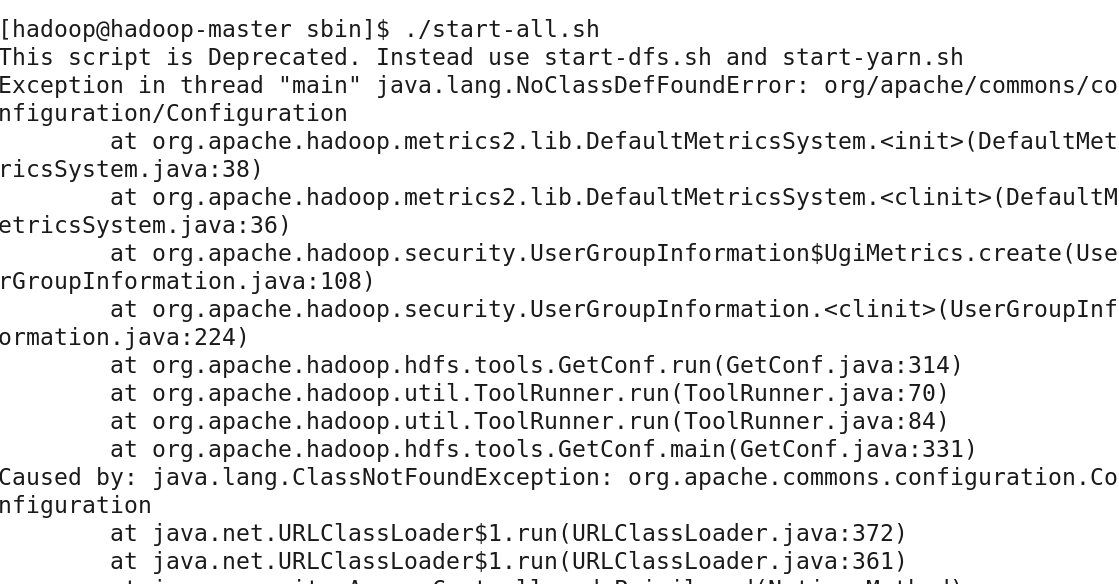
[hadoop@master ~]$ hadoop-2.6.0/sbin/start-all.sh
打開瀏覽器http://10.0.200.200:8088進行查看;
運行mapreduce測試
[hadoop@hadoop-master ~]$ hadoop jar hadoop-2.6.0/share/hadoop/mapreduce/hadoop- mapreduce-examples-2.6.0.jar pi 1 1000000000
Number of Maps = 1
Samples per Map = 1000000000
16/08/20 22:59:09 WARN util.NativeCodeLoader: Unable to load native-hadoop librar y for your platform... using builtin-java classes where applicable
Wrote input for Map #0
Starting Job
16/08/20 22:59:13 INFO client.RMProxy: Connecting to ResourceManager at hadoop-ma ster/192.168.100.50:8032
16/08/20 22:59:15 INFO input.FileInputFormat: Total input paths to process : 1
16/08/20 22:59:16 INFO mapreduce.JobSubmitter: number of splits:1
16/08/20 22:59:17 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_147 1704622640_0001
16/08/20 22:59:19 INFO impl.YarnClientImpl: Submitted application application_147 1704622640_0001
16/08/20 22:59:20 INFO mapreduce.Job: The url to track the job: http://hadoop-mas ter:8088/proxy/application_1471704622640_0001/
16/08/20 22:59:20 INFO mapreduce.Job: Running job: job_1471704622640_0001
16/08/20 22:59:42 INFO mapreduce.Job: Job job_1471704622640_0001 running in uber mode : false
16/08/20 22:59:42 INFO mapreduce.Job: map 0% reduce 0%
16/08/20 23:00:07 INFO mapreduce.Job: map 67% reduce 0%
16/08/20 23:00:46 INFO mapreduce.Job: map 100% reduce 0%
16/08/20 23:01:20 INFO mapreduce.Job: map 100% reduce 100%
16/08/20 23:01:24 INFO mapreduce.Job: Job job_1471704622640_0001 completed successfully
16/08/20 23:01:24 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=28
FILE: Number of bytes written=211893
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=270
HDFS: Number of bytes written=215
HDFS: Number of read operations=7
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=58521
Total time spent by all reduces in occupied slots (ms)=31620
Total time spent by all map tasks (ms)=58521
Total time spent by all reduce tasks (ms)=31620
Total vcore-seconds taken by all map tasks=58521
Total vcore-seconds taken by all reduce tasks=31620
Total megabyte-seconds taken by all map tasks=59925504
Total megabyte-seconds taken by all reduce tasks=32378880
Map-Reduce Framework
Map input records=1
Map output records=2
Map output bytes=18
Map output materialized bytes=28
Input split bytes=152
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=28
Reduce input records=2
Reduce output records=0
Spilled Records=4
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=519
CPU time spent (ms)=50240
Physical memory (bytes) snapshot=263278592
Virtual memory (bytes) snapshot=4123402240
Total committed heap usage (bytes)=132087808
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=118
File Output Format Counters
Bytes Written=97
Job Finished in 131.664 seconds
Estimated value of Pi is 3.14159272000000000000


