
本文出處:http://www.cnblogs.com/wy123/p/7501261.html (保留出處並非什麼原創作品權利,本人拙作還遠遠達不到,僅僅是為了鏈接到原文,因為後續對可能存在的一些錯誤進行修正或補充,無他) 資料庫在處理併發事物的過程中,在不同的隔離級別下有不同的鎖表現,在非可序列 ...
本文出處:http://www.cnblogs.com/wy123/p/7501261.html
(保留出處並非什麼原創作品權利,本人拙作還遠遠達不到,僅僅是為了鏈接到原文,因為後續對可能存在的一些錯誤進行修正或補充,無他)
資料庫在處理併發事物的過程中,在不同的隔離級別下有不同的鎖表現,在非可序列化隔離級別下,存在著臟讀,不可重覆讀,丟失更新,幻讀等情況。
本文不討論臟讀和不可重覆讀以及丟失更新的情形,僅討論幻讀,幻讀是指在一個事物中,同一個條件,存在兩次讀到的數據行數不一致的情況。
最高隔離級別也即可序列化隔離級別消除了幻讀,幻讀的消除過程中會通過Range鎖(也即範圍鎖)來實現事物隔離的。
那麼,Range鎖是如何產生的?產生Range鎖時,鎖定的範圍又是如何確定的?不同的索引產生的Range鎖範圍有什麼區別?
本文將對此進行一個粗淺的分析與推斷。
查閱了很多資料,尚未得到一個非常清晰的答案,原因在於:
1,沒有指明Range鎖的範圍,觀察鎖的時候看到Range鎖產生之後就收場,並沒有分析Range鎖產生時,鎖定的具體範圍是什麼,鎖定已存在的值沒問題,是否鎖定未存在的值?
1,非唯一索引與唯一索引的情況下產生的範圍鎖,鎖定的範圍包不包括臨界值 ?
2,對於查詢表中不存在的key值(分兩種,一種是介於表中最大與最小Key之間,一種是位於最大或者最小key值之外),鎖定的範圍到底是怎麼樣的?
測試中發現一個有意思的問題,對於唯一索引,當鎖定目標是一個表中已存在的Key值的時候,錶面上產生的是一個key鎖,真的就僅僅鎖定了當前的這一個Key(數據行)嗎?
同時,對於那個經典的“併發情況下存在則更新,不存在的插入”的處理,其背後的原理,也可以用Range鎖來解釋。
說明一下本文測試的原則:
1,測試均在可序列化隔離級別下測試(set transaction isolation level serializable )。
2,測試的原則是,Session1中採用排它鎖的方式加鎖,利用共用鎖與排它鎖不相容的特點,Session2中採用共用鎖的方式來不斷探測Session1中產生的鎖的範圍。
3,測試資料庫是SQL Server 2014
1,測試環境構建
1.1 新建測試表並寫入數據
create table TestLock ( Id int, Name varchar(100) ) create clustered index idx_id on TestLock(id) insert into TestLock values (10,'aaa') insert into TestLock values (20,'bbb') insert into TestLock values (30,'ccc') insert into TestLock values (40,'ddd') insert into TestLock values (50,'eee')
1.2 測試表中的數據行存儲位置分析
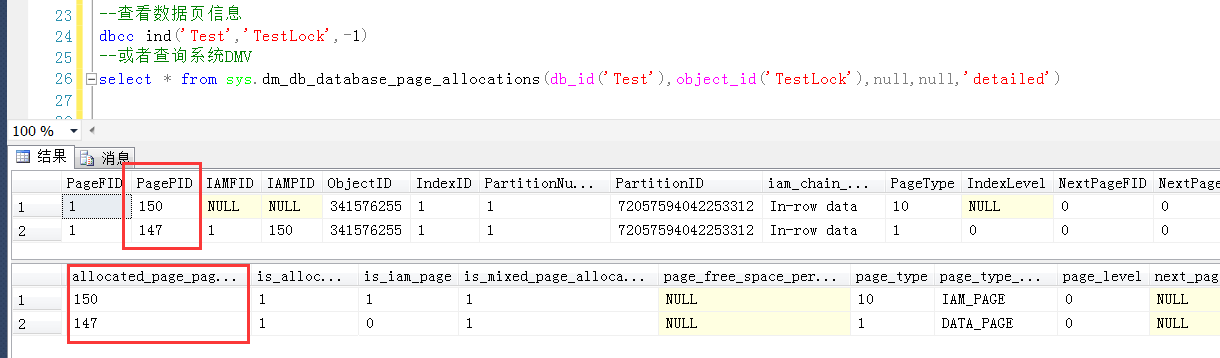
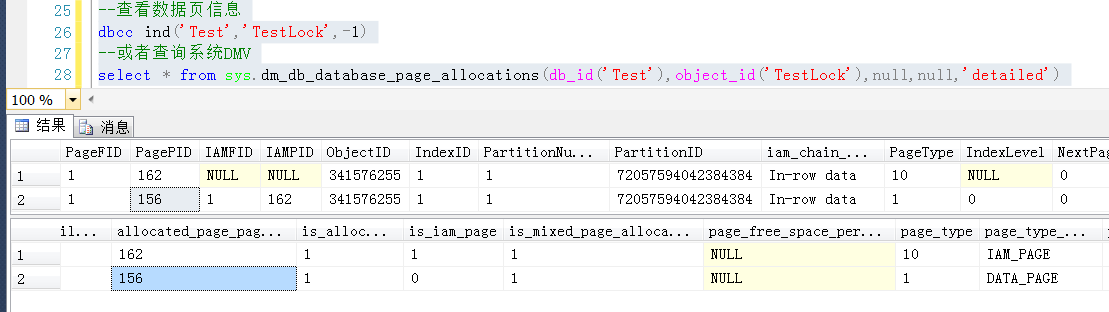
通過系統命令或者表查詢測試表的page信息
--查看數據頁信息 dbcc ind('Test','TestLock',-1) --或者查詢系統DMV select * from sys.dm_db_database_page_allocations(db_id('Test'),object_id('TestLock'),null,null,'detailed')
表TestLock的數據頁面為147
1.3 查詢147號頁面的數據行的KeyHashValue(可以認為是數據行的唯一標識)
DBCC TRACEON(3604) DBCC PAGE(Test,1,147,3)
這裡找到數據行對應的KeyHashValue如下圖所示
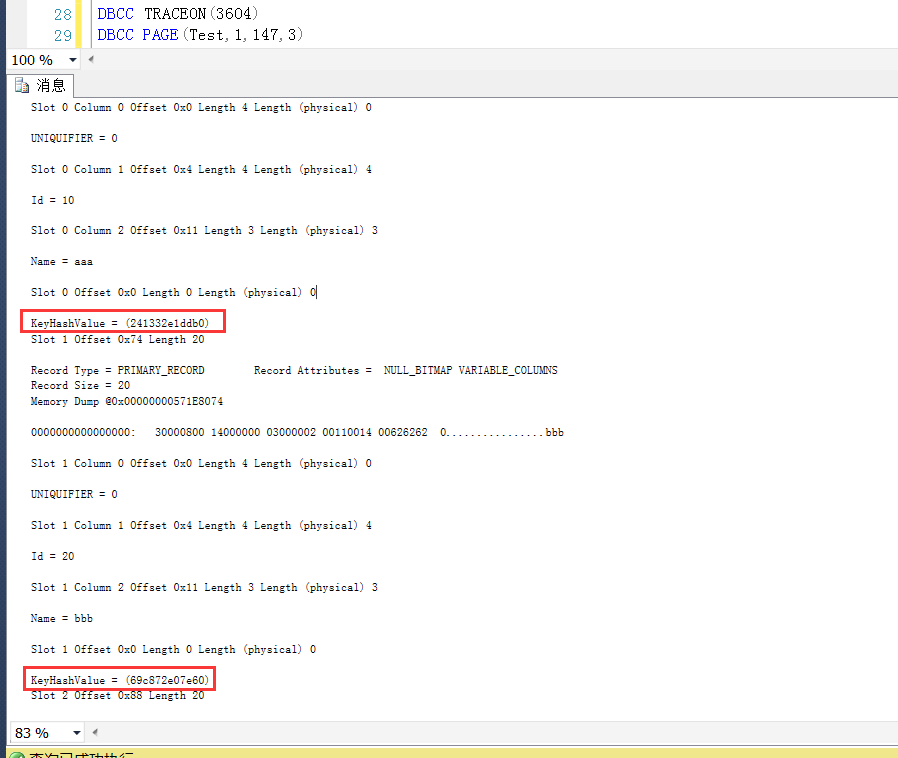
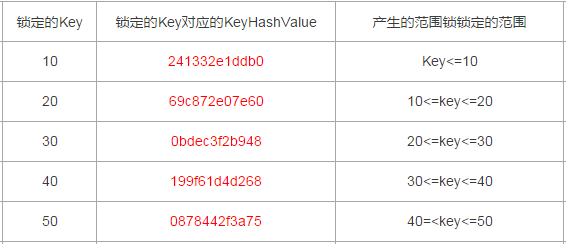
整理出來的數據行Id與其對應的KeyHashValue如下
10:241332e1ddb0
20:69c872e07e60
30:0bdec3f2b948
40:199f61d4d268
50:0878442f3a75
2,Range鎖產生時,鎖定的範圍初步分析
2.1 Range鎖產生的場景分析
在可序列化隔離級別下,測試一個Range鎖產生的情況
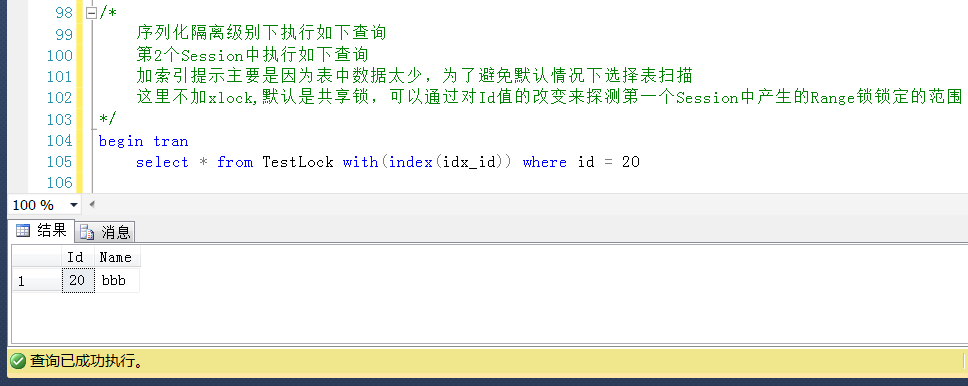
如代碼中的備註所示,第一個Session中執行如下查詢,暫不提交事物
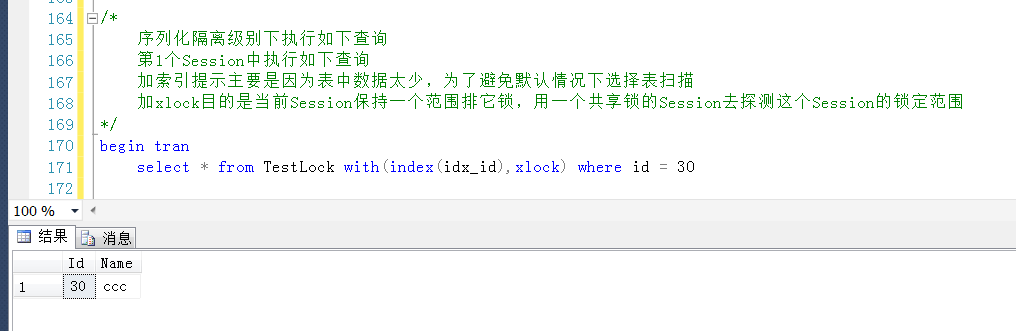
第一個Session中執行情況先保持(不提交也不回滾),另開一個查詢視窗,也即第二個Session中查詢產生的Range鎖
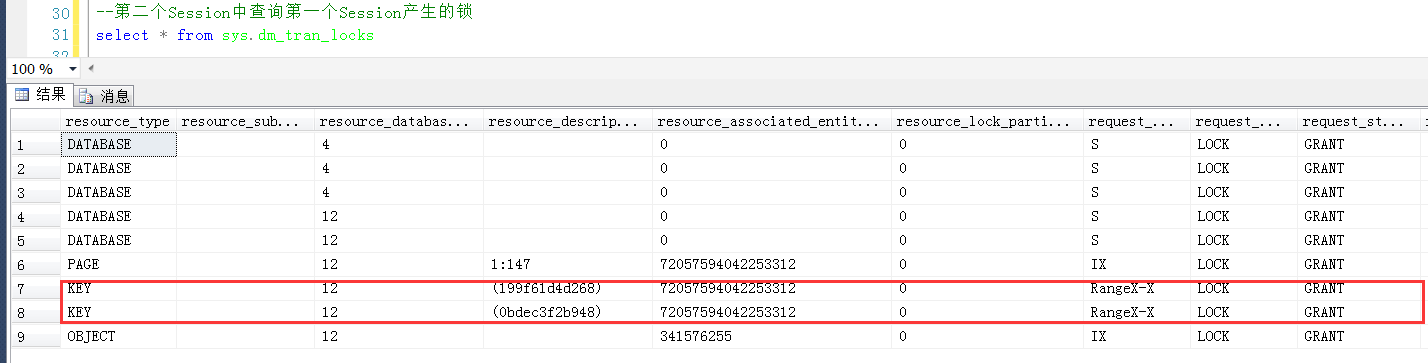
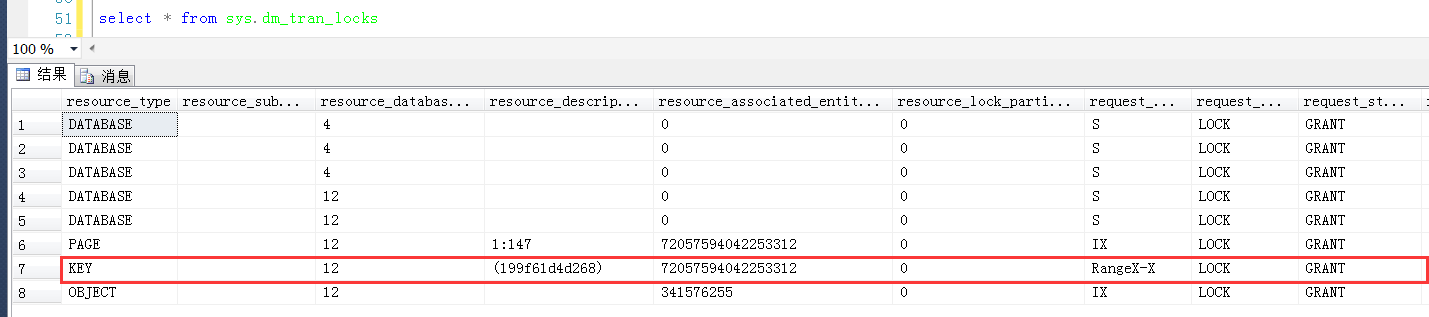
可以清楚地看到產生兩個Range鎖的resource_description分別是0bdec3f2b948和199f61d4d268
對照上面分析出來的數據行與KeyHashValue的關係,說明這個兩個resource_description的值分別是30和40
最重要的問題就在這裡,Range鎖的resource_description是0bdec3f2b948和199f61d4d268,既然是RangeX-X,也就是範圍鎖,那麼這兩個Range鎖定的範圍是多大?
這裡先給出結論,當在產生key類型的Range鎖的時候,
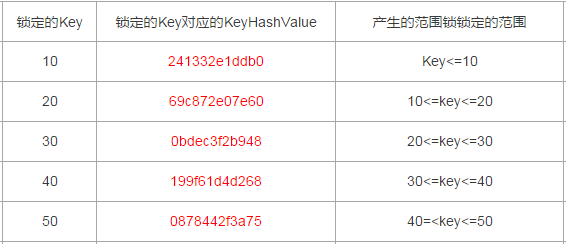
以上述測試case為例,每一個Range鎖對應的範圍如下(以下表格內容都包括臨界值,臨界值跟索引是否唯一也有關,下文會有說明)
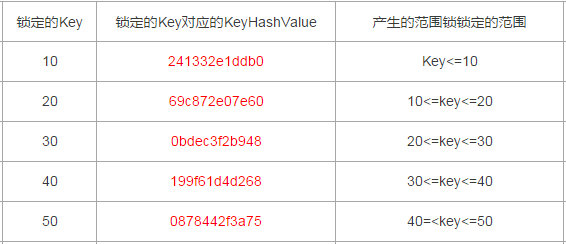
以上述測試為例,產生了兩個RangeX-X類型的Key類型鎖,分別是Id為30和40對應的RangeX-X,那麼鎖定的範圍就是20~40,
既然是一個範圍鎖,就跟表中是區間的數據是否存在無關。
上面的話怎麼理解?
如何證明鎖定的範圍就是20~40,看以下測試:
2.2查詢被鎖定區間的值,不管這個值是否已經存在於表中,都是會被被阻塞的
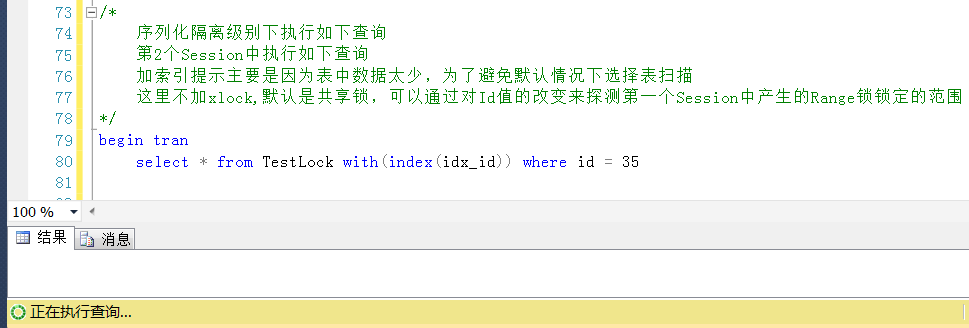
Session2中以序列化隔離級別執行如下代碼,
查詢Id = 35的Id值,雖然Id = 35是一個不存在的值,但是這個區間被鎖定了,按道理,查詢Id = 35的查詢是會被阻塞的。
測試正如所預料的,因為這個區間被鎖定了(排它鎖),查詢這個區間的任何一個值都被阻塞,而不管查詢的Id值是否存在
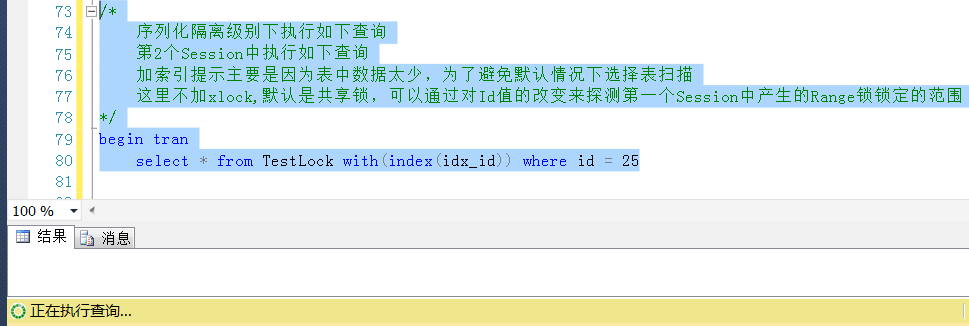
繼續測試,回滾Session2中的查詢,查詢一個下限範圍的Id,
同樣的道理,雖然Id = 25是一個不存在的值,但是這個區間被鎖定了,按道理,查詢Id = 25的查詢是會被阻塞的。
也是正如所預料的,因為這個區間被鎖定了(排它鎖),查詢這個區間的任何一個值都被阻塞,而不管查詢的Id值是否存在
2.3查詢非鎖定區間的值,不管這個值是否已經存在於表中,都是不會被被阻塞的
上面說了,鎖定的範圍就是20~40,那麼查詢一個非此區間的Id,是不會被鎖定的。
繼續測試,回滾Session2的查詢,查詢一個Id = 50的值,在非鎖定範圍之內(也即非20~40這個區間的Id),是可以正常查詢的,也是預期的。
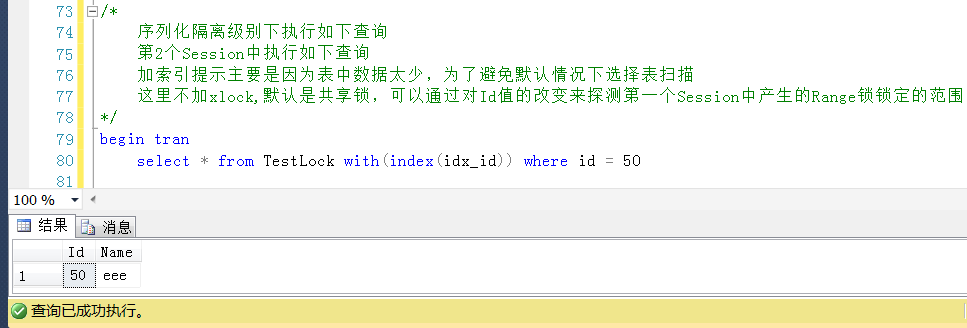
繼續回滾Session2中的查詢,查詢一個小於20且存在的Id值,查詢成功
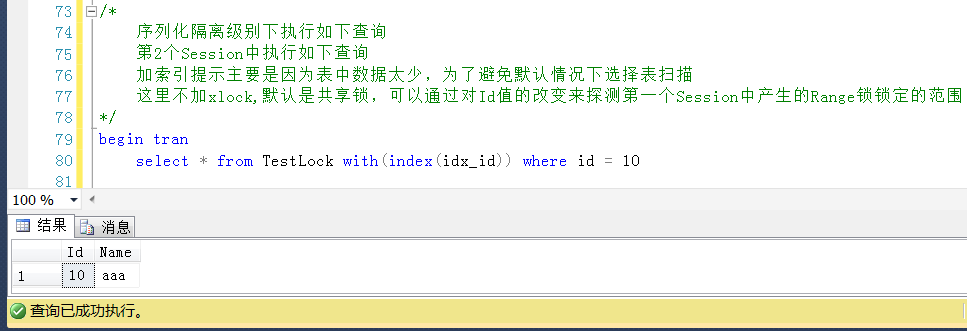
繼續回滾Session2中的查詢,查詢一個小於20且不存在的Id值,這裡使用Id = 15,查詢成功
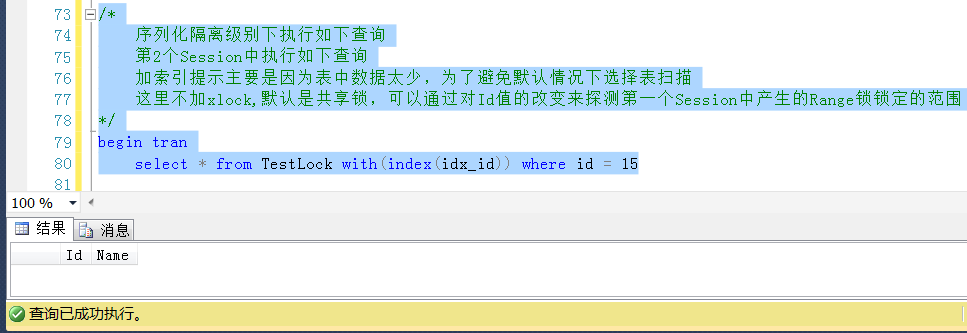
以上測試可以說明,一個Key類型的Range鎖,都對應一個範圍,加鎖的時候鎖定的是一個範圍,對於鎖定範區間的值,不管是否存在,都是會被阻塞的,而不僅僅是鎖定已有數據行的作用。
3,非唯一索引情況下,範圍鎖鎖定的範圍分析
那麼,一個Key類型的Range鎖究竟鎖定的範圍是多大?
這也是一個非常有意思的問題,這裡同樣先給出結論,分為以下幾種情況:
3.1 如果鎖定的目標Id的值存在與表中,且大於表中的最大值,小於表中的最小值,那麼鎖定的區間就是小於鎖定目標的第一個最大值,大於鎖定目標的第一個最小值這個區間。
上述測試已經說明瞭這個鎖的區間
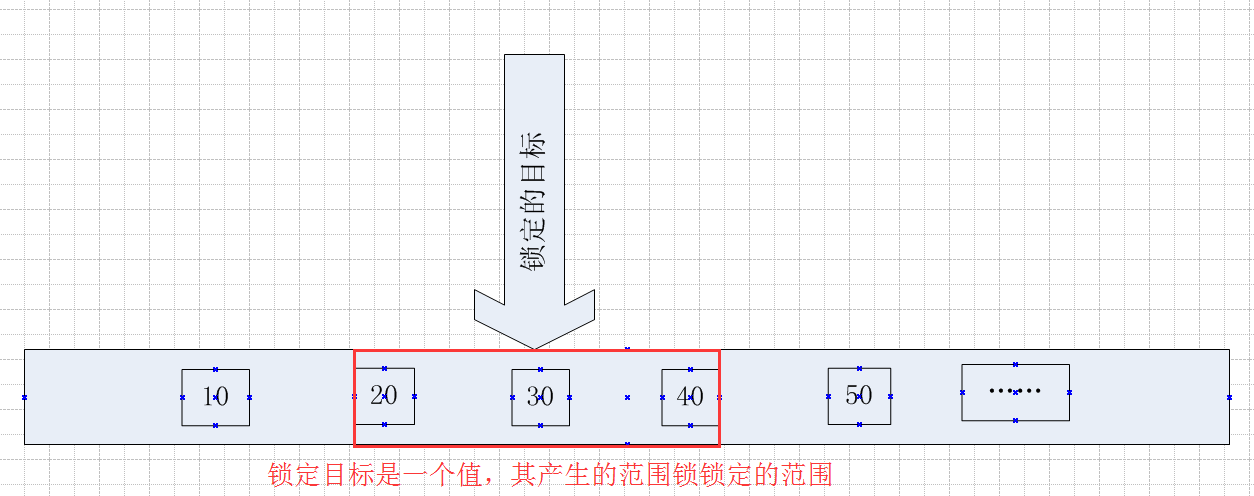
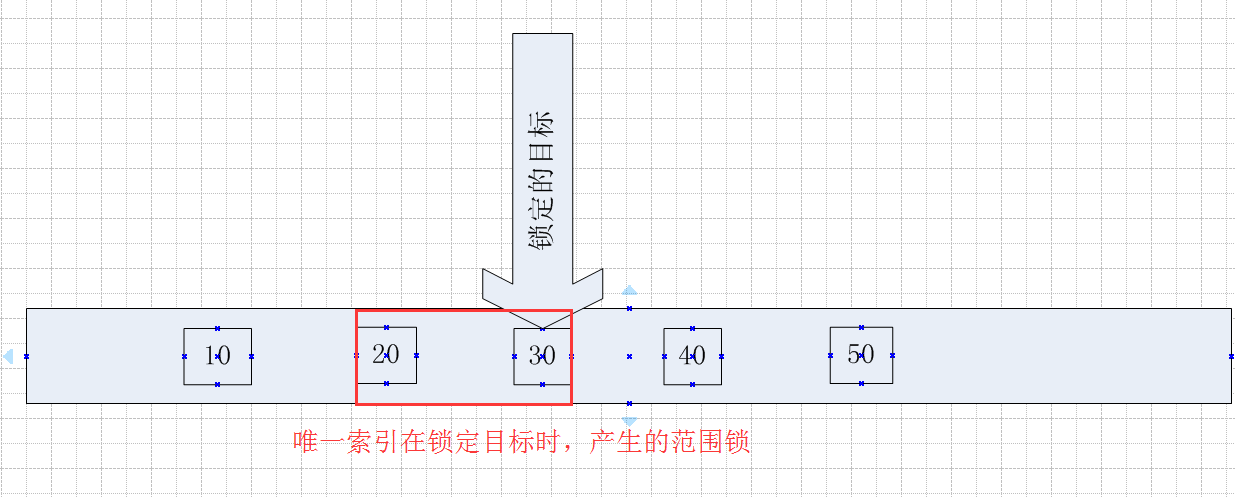
比如上述測試鎖定的目標值,在Session1中以xlock的方式鎖定Id =30,產生的範圍鎖,鎖定的範圍是下限值是20(小於30的最大值),上限值是40(大於30的最小值)
文字說起來有點繞,畫個圖看起來就直觀了,如下
鎖定的目標是30,因為在鎖定30的時候會產生範圍鎖,這個範圍鎖鎖定的區間是20~40
3.2 如果鎖定的目標Id的值不存在與表中,且大於表中的最大值,小於表中的最小值,那麼鎖定的區間就是小於鎖定目標的第一個最大值,大於鎖定目標的第一個最小值這個區間。
重新開始測試,Session1和Session2中都回滾之前的測試
在Session1中執行一個Id = 35的查詢,這個查詢是添加了排它鎖的方式執行的,這個Id是不存在的。
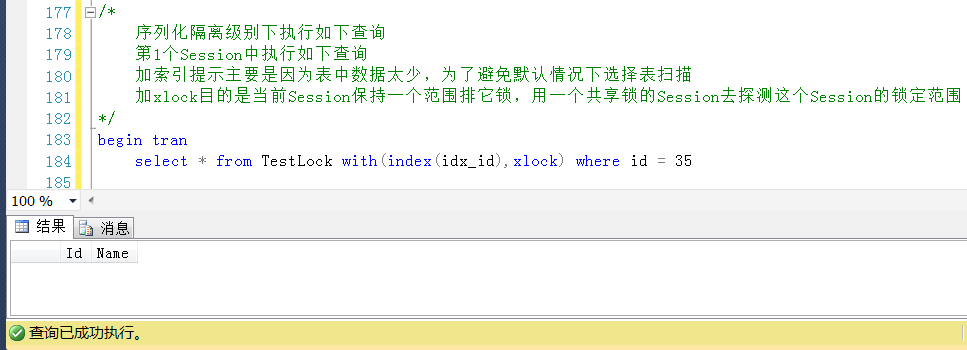
在Session2中觀察產生的鎖,會發現有一個resource_description是199f61d4d268的範圍鎖 。
KeyHashValue為199f61d4d268的Id是40,結合上述列表,40這個Id對應的鎖的範圍是30~40
那麼究竟鎖定的範圍是不是30~40,同樣可以在Session2中用共用鎖查詢的方式來探測Session1中鎖定的範圍
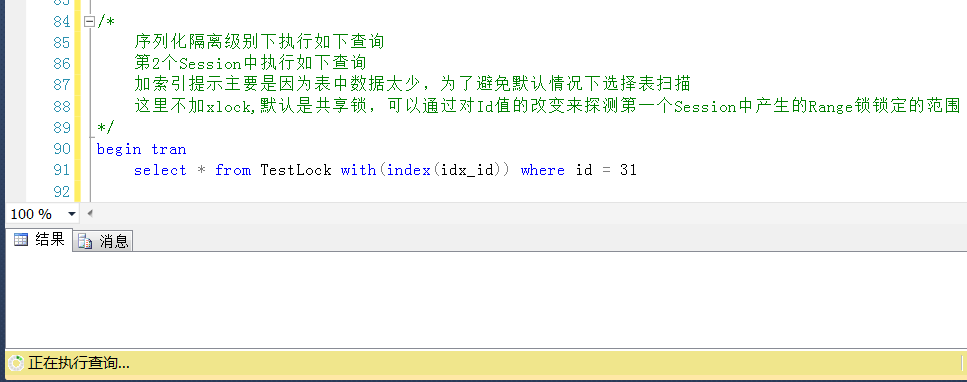
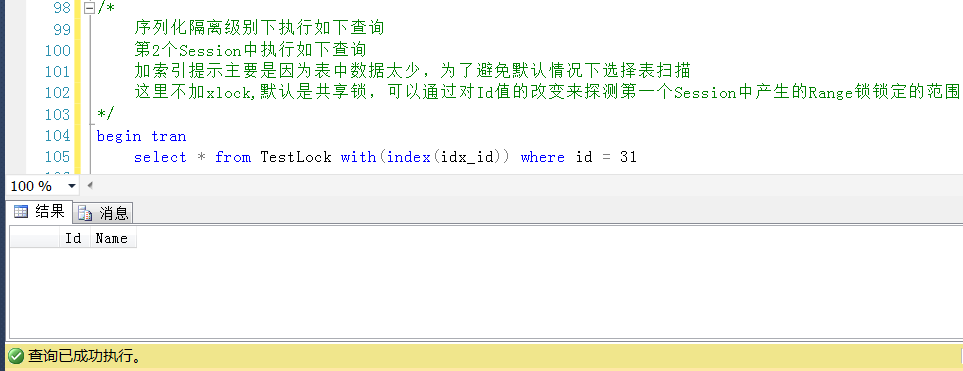
測試1,查詢Id = 31的值,被鎖定
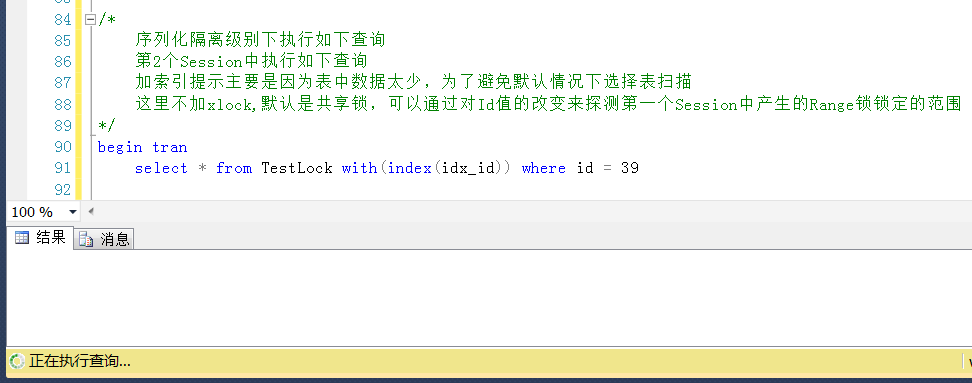
測試2,查詢Id=39的值,被鎖定
測試3,查詢Id = 29得值,位於鎖定區間之外,查詢成功,儘管這是一個不存在的值,但是在鎖定區間之外,可以查詢成功。
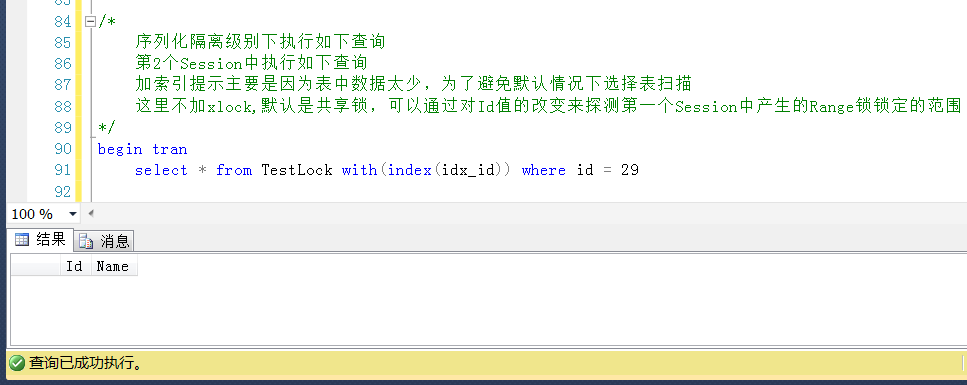
測試4,查詢Id = 50的值,位於鎖定區間之外,查詢成功,這是一個存在的Id值
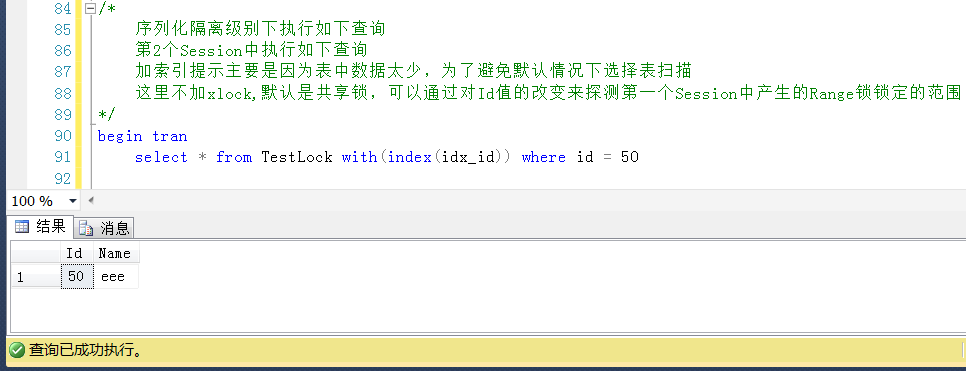
當鎖定的目標在表中不存在的時候,且鎖定目標大於表中已存在的最小Id值,小於最大Id值,
那麼鎖定的區間就是小於鎖定目標的第一個最大值,大於鎖定目標的第一個最小值這個區間。
同理,當產生範圍鎖的時候,鎖定的是一個區間,而不管這個區間是否存在值,或者存在多少個值。
同樣用一個圖來表示,看起來更直觀一點
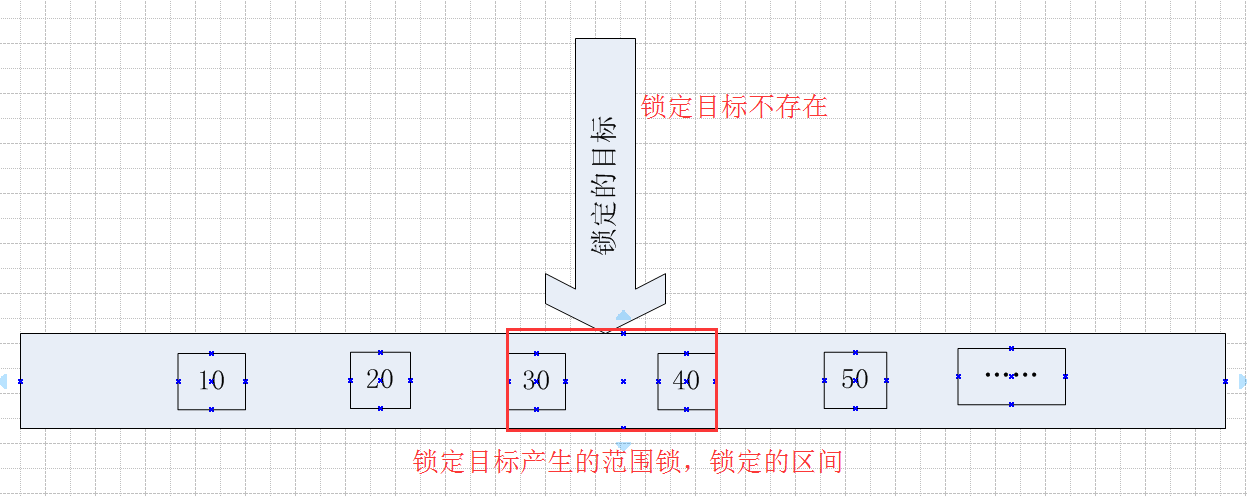
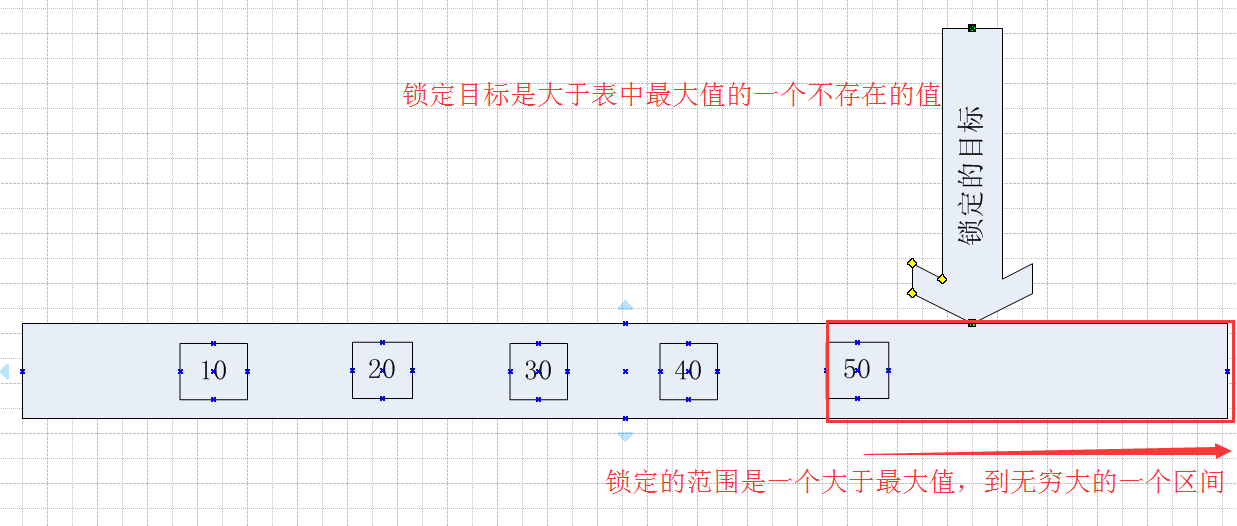
3.3 如果鎖定的目標Id的值不存在與表中,且大於表中的最大值 ,鎖定的範圍是一個表中最大值到無窮大的一個範圍
重新開始測試,Session1和Session2中都回滾之前的測試
在Session1中執行一個Id = 60的查詢,這個查詢是添加了排它鎖的方式執行的,這個Id是不存在的

在Session2中觀察產生的範圍鎖,這一次發現resource_description是一個(ffffffffffff),可以認為(ffffffffffff)這個KeyHashValue是一個無窮大的值
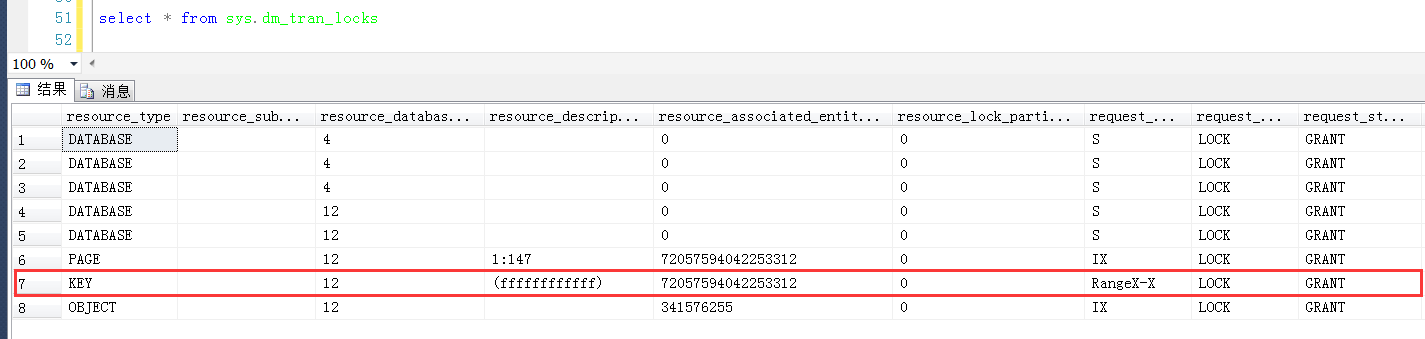
那麼問題就來了,鎖定範圍的上限是一個無窮大的值,那麼下限在哪裡?
同樣,可以在Session2中採用共用鎖探測的方式來觀察Session1鎖定的範圍
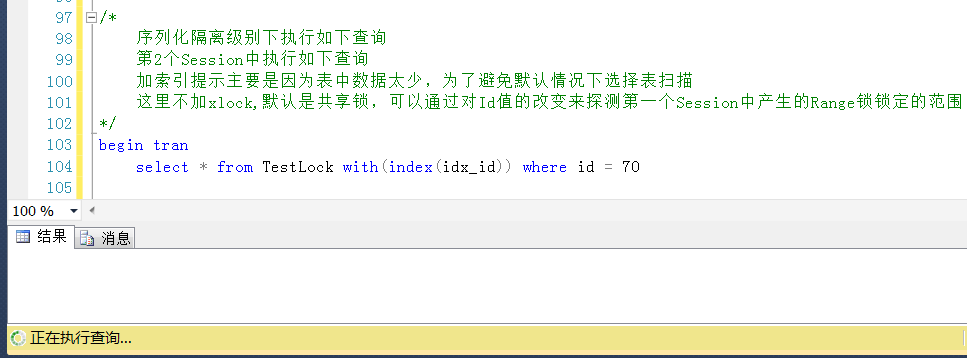
測試1,在Session2中查詢Id = 70的值,Id = 70是大於表中的一個最大值,被鎖定(鎖定範圍上限為無窮大,同理更大值也能被鎖定)
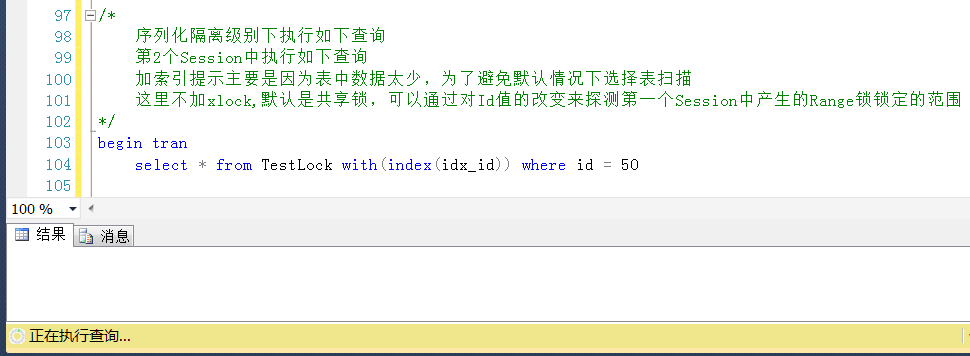
測試1,在Session2中查詢Id = 50的值,Id = 50是表中的一個最大值,被鎖定
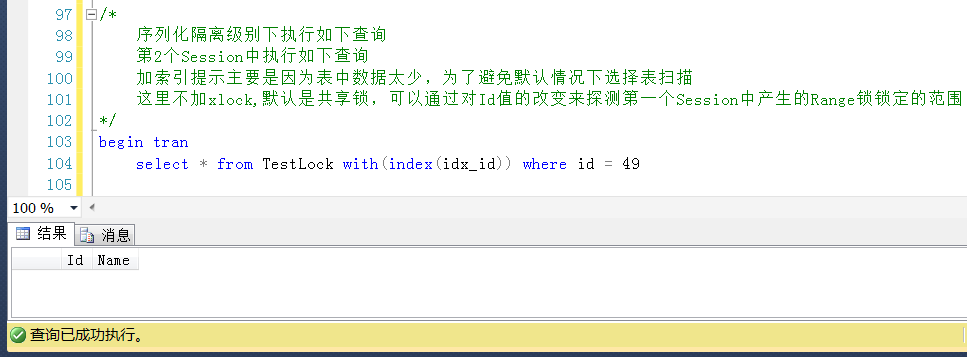
測試3,在Session2中查詢Id = 49的值,Id = 49是小於表中的一個最大值,未被鎖定,儘管這個值不存在
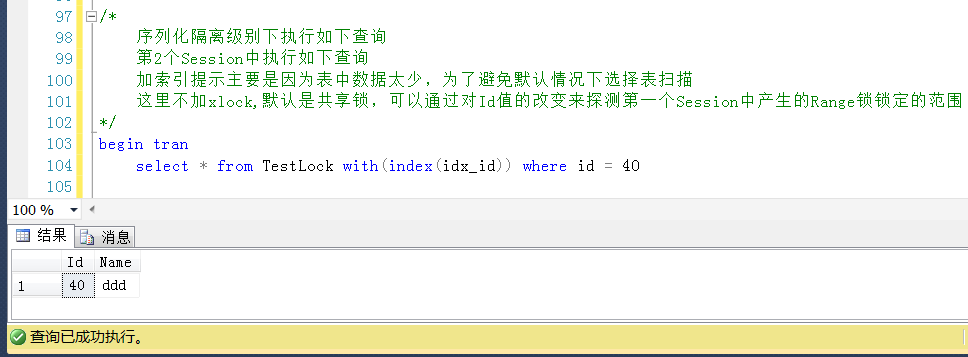
測試4,在Session2中查詢Id = 40的值,Id = 40是小於表中的一個最大值且存在的值,未被鎖定
當鎖定的目標在表中不存在的時候,且鎖定目標大於表中已存在的最大Id值,那麼鎖定的區間就是從表中最大值開始到無窮大的一個區間。
同樣用一個圖來表示,看起來更直觀一點
4,關於索引是否唯一與鎖定期間臨界值的關係
上文測試過程中,給出的Key與其對應的範圍鎖的鎖定關係中如下,鎖定範圍是包含了臨界值的(雙閉區間),但是一直沒有刻意測試臨界值。
沒有刻意測試臨界值是因為臨界值是否被鎖定,是跟索引的唯一性有關,如果索引時非唯一的,對應的範圍鎖在鎖定的時候就包含臨界值,如果索引唯一,情況是不一樣的。
下文中會有說明。
對於唯一索引,分為以下幾種情況:
4.1 唯一索引情況下,鎖定目標為已存在的Id值,且Id值大於表中的最小Id,小於表中的最大Id
在索引唯一的情況下,鎖定目標是一個表中已存在的Id值,那麼究竟是不是範圍鎖?
很多人認為如果鎖定目標是已存在的唯一索引,沒有產生Range鎖的時候就沒有“範圍鎖”的概念了,其實是不對的。
繼續測試,回滾Session1,Session2,刪除表中一開始創建的非唯一索引,Id上創建成一個唯一的聚集索引。

測試在觀察數據的索引頁,發生了變化(重建了聚集索引,數據頁發生了變化,想一想為什麼?)
用同樣的方式得到數據的KeyHashValue與數據行的對應關係如下
10:d08358b1108f
20:286fc18d83ea
30:8034b699f2c9
40:d8b6f3f4a521
50:f84b73ce9e8d
同理在Session1中查詢一個已存在的Id值,作為鎖定目標
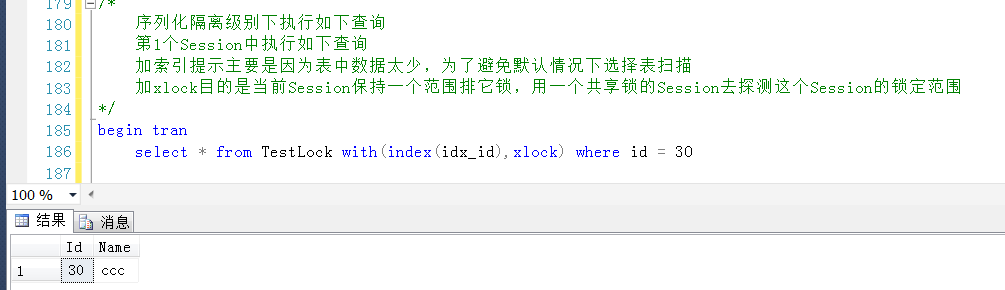
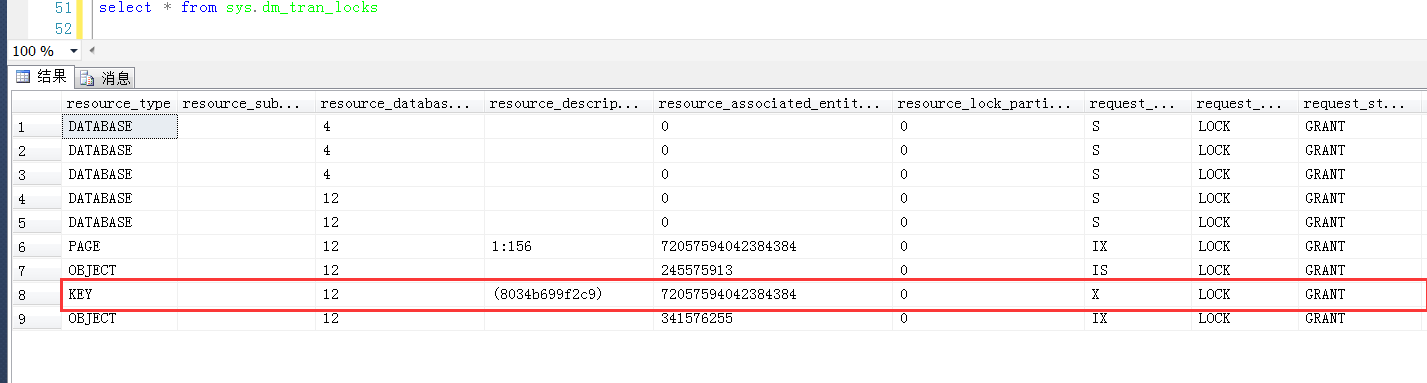
在Session2中觀察產生的鎖,鎖定的行是很明顯是Id = 30的數據行,但是是一個X鎖,而非範圍鎖(RangeX-X)。
那麼此時,僅僅是會鎖定當前行嗎?
測試1,在Session2中查詢一個小於輸定目標(但是大於20,因為20是小於鎖定目標的已存在的最大值)的值,發現依舊是被鎖定,
測試2,再測一個Id =29的值,一樣是被鎖定的
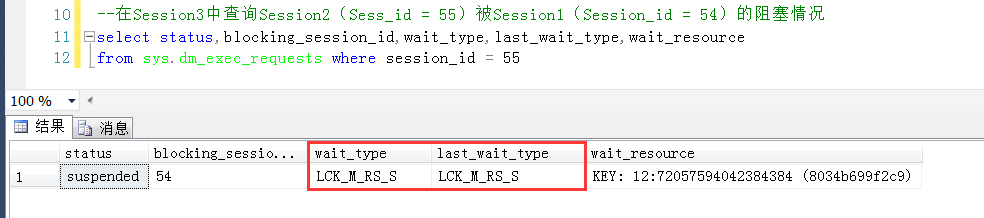
這裡捎帶看一下Session2(Sess_id = 55)被Session1(Session_id = 54)的阻塞情況
這裡的wait_type為LCK_M_RS_S,LCK_M_RS_S是啥鎖?LCK_M_RS_S:等待獲取當前鍵值上的共用鎖以及當前鍵和上一個鍵之間的共用範圍鎖
依舊是是“當前鍵和上一個鍵之間的共用範圍鎖”啊,依舊是範圍鎖啊,因此說,鎖定已存在與表中的唯一索引的時候,雖然沒有變現出來範圍鎖(sys.dm_tran_locks),但是本質上仍然是範圍鎖。
測試3,測試一個小於鎖定目標,且存在與表中的最大值(也就是20),發現未被鎖定(這就是唯一索引與非唯一索引在臨界值上的鎖定區別,如果是非唯一索引,這個20的臨界值將會被鎖定)
測試4,測試一個大於鎖定區間的值,也即如下的Id = 31,查詢是成功的,即便是Id= 31不存在的。
從中可以發現,在唯一索引的情況下,
如果鎖定的目標Id的值存在與表中,且大於表中的最大值,小於表中的最小值,那麼鎖定的區間就是當前值到小於鎖定目標的第一個最大值
具實際例子來說就是,鎖定目標是30的情況下,鎖定的區間值是(20,30]
4.2 唯一索引情況下,鎖定目標為不存在的Id值,且Id值大於表中的最小Id,小於表中的最大Id
這種情況就不一一截圖了,結論如同非唯一索引,比如鎖定目標為Id = 35的情況下,鎖的範圍是(30,40],也即左開(區間)右閉(區間)
4.3 唯一索引情況下,鎖定目標為不存在的Id值,且Id值大於表中的最大Id
這種情況也就不一一截圖了,結論如同非唯一索引,比如鎖定目標為Id = 60的情況下,鎖的範圍是(50,+∞),也即左開(區間)
5,關於查詢條件是一個區間值的情況
因為知道了單個值查詢的鎖的區間,對於範圍查詢的情況,無非就是將查詢範圍進行分解,分解出單個值鎖定的範圍,然後將這個區間進行合併得到一個區間的並集。
有興趣的可以自行測試。
6,關於查詢條件是一個非聚集索引的情況
上述都是以聚集索引為查詢條件進行測試的,如果是非聚集索引情況雷同,只不過是多了非聚集索引一級的鎖,有時間再測試。
總結:
序列化隔離級別下會阻止幻讀的產生,幻讀的產生是通過範圍鎖鎖定的是一個範圍來實現的,
Range 鎖最主要的是鎖定一個範圍,鎖定的不僅僅是表中已有的數據,而是一個區間,而不管這個範圍之內是否存在數據,
任何Session試圖操作被其他Session範圍鎖鎖定的數據,不管在表中是否存在,都將被阻塞,直到產生範圍鎖的Session事物提交。
此時也不難理解,對於那個最經典的問題:併發情況下,存在則更新,不存在則插入,不管採用什麼寫法,
比如併發插入,任何一個Session執行之前,都先鎖定一個範圍,即便是這個值不存在,
等到相同的值進來的時候,同樣需要鎖定一個範圍,那麼此時是會被阻塞的,因此可以實現併發存在則更新,不存在則插入的效果
瞭解了Range鎖的鎖定原理,也不會糾結不同寫法的區別了,目的都是加Range鎖,鎖定範圍,防止併發情況下的幻讀出現。
以上純屬個人測試和簡單的推斷,難免存在錯誤的地方,如有興趣,歡迎探討指正,謝謝。
最後
其實樓主是看了MySQL的gap鎖、next-key鎖之後回頭來看SQL Server中的Range鎖的,
最終發現,除了一些細節,鎖的實現在套路上都是一樣的,比如對待幻讀的處理上,可謂是在“道”的層面上都是一個原則。
一個叫做Range範圍鎖,一個叫做gap鎖、next-key鎖,不同的表現形式只是“術”上的問題罷了。
太累了,眼睛脖子都受不鳥了。
參考資料,各種翻書,各種上網查。



