
早兩天在網易雲聽歌看評論的時候,突然想把網易雲上所有歌曲都抓取下來然後按照評論數進行一次排名,把評論數超過10萬的歌曲都聽一次,於是便有了這個項目。 因為只是一個小前端,所以使用了Node來寫這個爬蟲。 實現的思路比較簡單,把網易雲上的所有知名歌手先抓取下來,一共是3萬左右。然後每個歌曲選取10首評 ...
早兩天在網易雲聽歌看評論的時候,突然想把網易雲上所有歌曲都抓取下來然後按照評論數進行一次排名,把評論數超過10萬的歌曲都聽一次,於是便有了這個項目。
因為只是一個小前端,所以使用了Node來寫這個爬蟲。
實現的思路比較簡單,把網易雲上的所有知名歌手先抓取下來,一共是3萬左右。然後每個歌曲選取10首評論靠前的歌曲進行統計,所以一共統計了30萬首歌曲,之後或許會統計更多的歌曲。
在本次的抓取過程中,從請求歌曲鏈接到獲取信息並且寫入資料庫的效率大概是0.2秒一首歌曲,30萬首一共需要16.6個小時左右。前面提到的抓取3萬個歌手的效率十分高,不夠10分鐘可以抓取完畢,所以不作時間統計。
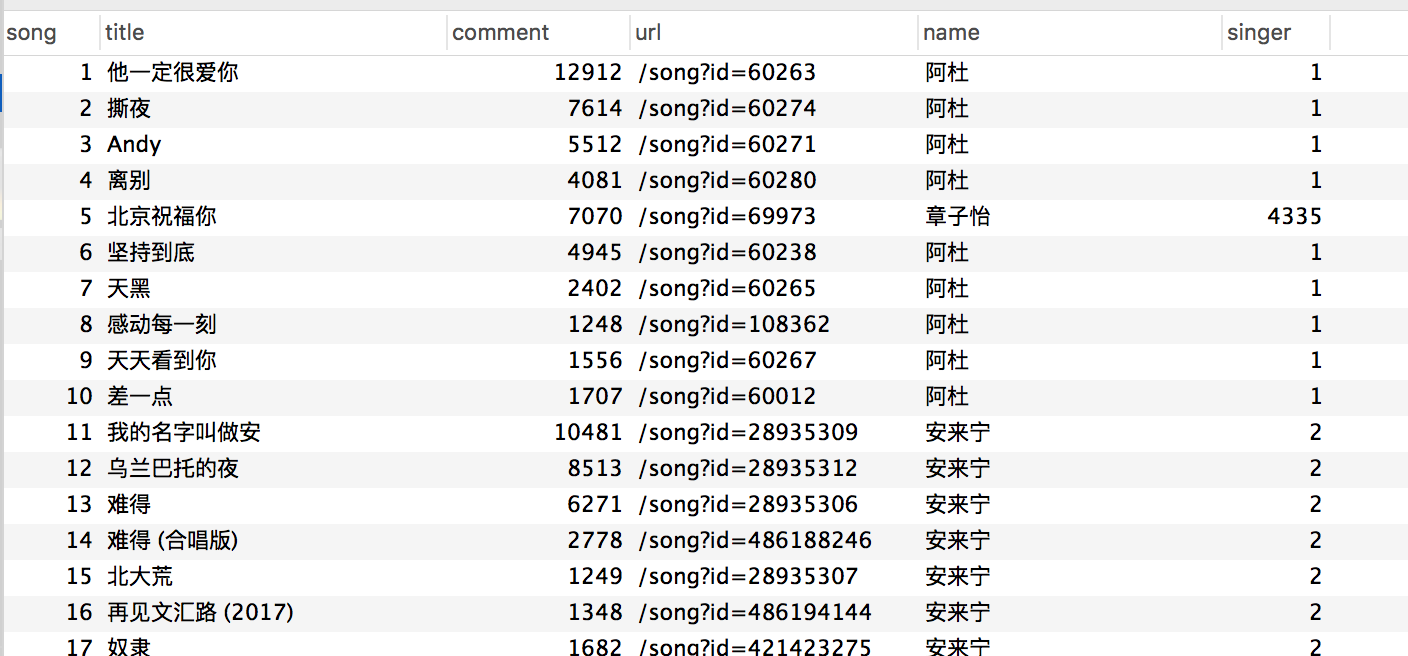
具體的抓取數據可看截圖
歌手信息

歌曲信息
具體的技術細節以及項目代碼可以到我的Github上看,已經開源。很多細節以及項目配置都在Github文檔中寫的很清楚,所以請移步Github地址
https://github.com/qiangzi7723/spider-for-netease-music
過兩天會給這些數據寫一個H5的數據統計以及展示頁面,所以如果喜歡這個項目或者想持續關註此項目更新的同學可以到我的Github上點下Star。


