
目錄 · ZooKeeper安裝 · 分散式一致性理論 · 一致性級別 · 集中式系統 · 分散式系統 · ACID特性 · CAP理論 · BASE理論 · 一致性協議 · ZooKeeper概況 · ZooKeeper API · 命令 · Java API · Curator · ZooKee ...
目錄
· 分散式一致性理論
· 一致性級別
· 集中式系統
· 分散式系統
· ACID特性
· CAP理論
· BASE理論
· 一致性協議
· 命令
· Java API
· Curator
· 數據發佈/訂閱
· 配置管理
· 命名服務
· 集群管理
· Master選舉
· 分散式鎖
· 分散式隊列
· Hadoop
· HBase
· Kafka
ZooKeeper安裝
|
ID |
Host Name |
|
1 |
centos1 |
|
2 |
centos2 |
1. 配置機器名。
vi /etc/hosts
192.168.0.220 centos1
192.168.0.221 centos2
2. 安裝JDK並配置環境變數(JAVA_HOME、CLASSPATH、PATH)。
3. 配置文件。
tar zxvf zookeeper-3.4.8.tar.gz -C /opt/app/ cd /opt/app/zookeeper-3.4.8/ mkdir data/ logs/ vi conf/zoo.cfg # 集群每台機器的zoo.cfg配置必須一致。
tickTime=2000 dataDir=/opt/app/zookeeper-3.4.8/data/ dataLogDir=/opt/app/zookeeper-3.4.8/data_logs/ clientPort=2181 initLimit=5 syncLimit=2 server.1=centos1:2888:3888 # 每台機器都要感知集群的機器組成,配置格式為“server.id=host:port:port”。id範圍1~255。 server.2=centos2:2888:3888
# 在dataDir目錄創建myid文件。根據zoo.cfg配置,id應與機器對應。如centos1的id為1,centos2的id為2. echo 1 > data/myid echo 2 > data/myid
4. 啟動、關閉。
bin/zkServer.sh start bin/zkServer.sh stop bin/zkServer.sh status
5. 驗證。
bin/zkCli.sh -server centos1:2181
[zk: centos1:2181(CONNECTED) 0] ls / [zookeeper] [zk: centos1:2181(CONNECTED) 1] create /helloworld 123 Created /helloworld [zk: centos1:2181(CONNECTED) 2] ls / [helloworld, zookeeper] [zk: centos1:2181(CONNECTED) 3] quit Quitting...
bin/zkCli.sh -server centos2:2181
[zk: centos2:2181(CONNECTED) 0] ls / [helloworld, zookeeper] [zk: centos2:2181(CONNECTED) 1] get /helloworld 123 cZxid = 0x100000008 ctime = Sat Jun 18 16:10:12 CST 2016 mZxid = 0x100000008 mtime = Sat Jun 18 16:10:12 CST 2016 pZxid = 0x100000008 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 3 numChildren = 0 [zk: centos2:2181(CONNECTED) 2] quit Quitting...
分散式一致性理論
一致性級別
1. 強一致性:寫入與讀出數據一致。用戶體驗好,但對系統影響較大。
2. 弱一致性:寫入後不承諾立即可以讀到,也不承諾多久之後達到一致,但會儘可能保證到某個時間級別(比如秒級)後數據一致。細分:
a) 會話一致性:只保證同一個客戶端會話中寫入與讀出數據一致,其他會話無法保證。
b) 用戶一致性:只保證同一個用戶中寫入與讀出數據一致,其他會話無法保證。
c) 最終一致性:保證在一定時間內,達到數據一致性。業界比較推崇的大型分散式系統數據一致性。
集中式系統
1. 特點:部署結構簡單。
2. 問題:有明顯的單點問題。
分散式系統
1. 定義:分散式系統是一個硬體或軟體組件分佈在不同的網路電腦上,彼此之間僅僅通過消息傳遞進行通信和協調的系統(摘自《分散式系統概念與設計》)。
2. 特點。
a) 分佈性:多台電腦在空間上隨意分佈,並且分佈情況隨時變動。
b) 對等性:無主/從之分,既無控制整個系統的主機,也無被控制的從機。
c) 併發性:例如多個節點併發操作一些共用資源,諸如資料庫或分散式存儲。
d) 缺乏全局時鐘:空間上隨意分佈的多個進程,由於缺乏全局時鐘序列控制,很難定義誰先執行誰後執行
e) 故障總是會發生。
3. 副本(Replica):分散式系統對數據和服務提供的一種冗餘方式。目的是為了提高數據的可靠性和服務的可用性。
4. 併發:如果邏輯控制流在時間上重疊,那麼它們就是併發的。
5. 問題。
a) 通信異常:網路光纖、路由器或DNS等硬體設備或系統導致網路不可用;網路正常時通信延時大於單機,通常單機記憶體訪問延時時納秒數量級(約10ns),網路通信延時在0.1~1ms左右(105~106倍於記憶體訪問)。
b) 網路分區:俗稱“腦裂”。原書解釋有問題,摘一段來自網路的解釋:“Imagine that you have 10-node cluster and for some reason the network is divided into two in a way that 4 servers cannot see the other 6. As a result you ended up having two separate clusters; 4-node cluster and 6-node cluster. Members in each sub-cluster are thinking that the other nodes are dead even though they are not. This situation is called Network Partitioning (aka Split-Brain Syndrome).”。每個節點的加入與退出可看作特殊的網路分區。
c) 三態:三態即成功、失敗和超時。由於網路不可靠,可能會出現超時。超時的兩種情況:1)請求(消息)並未被成功地發送到接收方;2)請求(消息)成功地被接收方接收後進行了處理,但反饋響應給發送方時消息丟失。
d) 節點故障:每個節點每時每刻都可能出現故障。
ACID特性
1. 事務(Transaction):由一系列對系統中數據進行訪問與更新的操作所組成的一個程式執行邏輯單元(Unit),狹義上的事務特指資料庫事務。
2. 原子性(Atomicity):
a) 事務中各項操作只允許全部成功執行或全部執行失敗。
b) 任何一項操作失敗都將導致事務失敗,同時其他已執行的操作將被撤銷。
3. 一致性(Consistency):如果資料庫發生故障,事務尚未完成被迫中斷,事務中已執行的寫操作不應該寫入資料庫。
4. 隔離性(Isolation):
a) 一個事務的執行不能被其他事務干擾。
b) Read Uncommitted、Read Committed、Repeatable Read、Serializable4個隔離級別,隔離性依次增高,併發性依次降低。
c) 4個隔離級別解決的隔離問題。
|
級別 \ 問題 |
臟讀 |
重覆讀 |
幻讀 |
|
Read Uncommitted |
有 |
有 |
有 |
|
Read Committed |
無 |
有 |
有 |
|
Repeatable Read |
無 |
無 |
有 |
|
Serializable |
無 |
無 |
無 |
5. 持久性(Durability):一旦事務執行成功,對資料庫的修改必須永久保存。
CAP理論
1. 內容:一個分散式系統不可能同時滿足一致性(Consistency)、可用性(Availability)和分區容錯性(Partion tolerance)這三個基本需求,最多只能同時滿足其中兩項。
2. 一致性:多個副本之間保持一致的特性。
3. 可用性:系統提供的服務必須一直處於可用狀態,對於用戶的每個操作請求總是能在有限時間內返回結果。“有限時間內”是系統設計之初設定好的運行指標,通常不同系統會有很大不同。
4. 分區容錯性:遇到任何網路分區故障時,仍然能提供一致性和可用性的服務。
5. 權衡(摘自網路):
a) 對於多數大型互聯網應用的場景,主機眾多、部署分散,而且現在的集群規模越來越大,所以節點故障、網路故障是常態,而且要保證服務可用性達到N個9,即保證P和A,捨棄C(退而求其次保證最終一致性)。雖然某些地方會影響客戶體驗,但沒達到造成用戶流程的嚴重程度。
b) 對於涉及到錢財這樣不能有一絲讓步的場景,C必須保證。網路發生故障寧可停止服務,這是保證CA,捨棄P。貌似這幾年國內銀行業發生了不下10起事故,但影響面不大,報到也不多,廣大群眾知道的少。還有一種是保證CP,捨棄A。例如網路故障事只讀不寫。
BASE理論
1. BASE是Basically Available(基本可用)、Soft state(軟狀態)和Eventually consistency(最終一致性)的簡寫。
2. BASE核心思想:即使無法做到強一致性(Strong consistency),但可根據應用的自身業務特點,採用適當方式達到最終一致性(Eventually consistency)。
3. BASE是對CAP中一致性和可用性權衡的結果,來源於對大規模互聯網系統分散式時間總結。
4. 基本可用:不可預知故障時,允許損失部分可用性。比如響應時間的損失、功能的損失。
5. 軟狀態:允許系統中的數據存在中間狀態,並認為該狀態不會影響系統整體可用性,即允許不同節點的數據副本同步存在延時。
6. 最終一致性:所有數據副本,在經過一段時間同步後,最終能達到一個一致性狀態。
一致性協議
1. 最著名的一致性協議和演算法:二階段提交協議(2PC/Two-Phase Commit)、三階段提交協議(3PC/Three-Phase Commit)和Paxos演算法。
2. 絕大多數關係資料庫採用2PC協議完成分散式事務。
ZooKeeper概況
1. ZooKeeper是一個分散式數據一致性解決方案,是Google Chubby(論文)的開源實現。
2. ZooKeeper採用ZAB(ZooKeeper Atomic Broadcast)一致性協議。
3. ZooKeeper保證如下分散式一致性特性。
a) 順序一致性:同一客戶端發起的請求,最終會嚴格按發起順序應用到ZooKeeper中。
b) 原子性:所有請求的處理結果在整個集群所有機器上的應用情況是一致的。
c) 單一視圖(Single System Image):客戶端連接ZooKeeper任意一個伺服器,看到的數據模型都是一致的。
d) 可靠性:應用了客戶端請求之後,引起的數據變更被永久保存。
e) 實時性:僅保證在一定時間後,最終一致性。
4. ZooKeeper的設計目標。
a) 簡單的數據模型:提供樹形結構的命令空間,樹上的數據節點稱為ZNode。
b) 可以構建集群。
c) 順序訪問:客戶端每個更新請求,都會分配一個全局唯一的遞增編號,這個編號反應了所有操作的先後順序。
d) 高性能:全局數據存儲在記憶體,尤其適用於讀為主的應用場景。
5. 集群角色。
a) 沒有Master/Slave,而引入三種角色。
b) Leader:為客戶端提供讀、寫服務。通過Leader選舉過程產生。
c) Follower:為客戶端提供讀、寫服務,如果是寫請求則轉發給Leader。參與Leader選舉過程。
d) Observer:與Follower相同,唯一區別是不參加Leader選舉過程。
6. 數據節點ZNode。
a) 分為持久節點和臨時節點(Ephemeral Node),臨時節點在客戶端會話失效後被移除,而持久節點在執行移除操作後才被移除。
b) 順序節點(Sequence Node),被創建時ZooKeeper自動在其節點名後追加一個整型數字(唯一命名)。
7. 版本:每個ZNode都有一個Stat數據結構,包含version(當前ZNode的版本)、cversion(當前ZNode子節點的版本)和aversion(當前ZNode的ACL版本)。
8. Watcher。
a) 允許客戶端在指定節點上註冊一些Watcher,在這些特定事件觸發時,ZooKeeper將事件通知到註冊的客戶端上。
b) 即Publish/Subscribe(發佈/訂閱)。
9. ACL(Access Control Lists)。
a) ZooKeeper採用ACL策略進行許可權控制,類似UNIX文件系統許可權控制。
b) CREATE:創建子節點許可權。
c) READ:獲取節點數據和子節點列表的許可權。
d) WRITE:更新節點數據的許可權。
e) DELETE:刪除子節點的許可權。
f) ADMIN設置節點ACL的許可權。
10. 集群組成。
a) “過半存貨即可用”指如果ZooKeeper集群要對外可用,必須要有過半的機器正常工作並且彼此之間正常通信。即如果搭建一個允許F台機器宕機的集群,則要部署2xF+1台伺服器。
b) 6台機器的集群可用性上並不比5台機器的集群高,所以產生了“官方推薦伺服器數為奇數”的說法。
c) 需澄清:任意伺服器數的ZooKeeper集群都能部署且正常運行。
ZooKeeper API
命令
1. 創建節點:create [-s] [-e] path data [acl],-s順序節點,-e臨時節點。
2. 列出子節點:ls path [watch]。
3. 獲取節點:get path [watch]。
4. 更新節點:set path data [version]。
5. 刪除節點:delete path [version]。
6. 刪除節點及其子節點:rmr path。
7. 舉例。
[zk: localhost:2181(CONNECTED) 0] create /test A Created /test [zk: localhost:2181(CONNECTED) 1] create /test/mynode B Created /test/mynode [zk: localhost:2181(CONNECTED) 2] create -s /test/snode 0 Created /test/snode0000000001 [zk: localhost:2181(CONNECTED) 3] create -s /test/snode 0 Created /test/snode0000000002 [zk: localhost:2181(CONNECTED) 4] create -s /test/snode 0 Created /test/snode0000000003 [zk: localhost:2181(CONNECTED) 5] ls /test [snode0000000002, mynode, snode0000000001, snode0000000003] [zk: localhost:2181(CONNECTED) 6] get /test/mynode B cZxid = 0x200000029 ctime = Sun Jun 19 00:04:05 CST 2016 mZxid = 0x200000029 mtime = Sun Jun 19 00:04:05 CST 2016 pZxid = 0x200000029 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 1 numChildren = 0 [zk: localhost:2181(CONNECTED) 7] set /test/mynode C cZxid = 0x200000029 ctime = Sun Jun 19 00:04:05 CST 2016 mZxid = 0x20000002d mtime = Sun Jun 19 00:05:34 CST 2016 pZxid = 0x200000029 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 1 numChildren = 0 [zk: localhost:2181(CONNECTED) 8] delete /test/mynode [zk: localhost:2181(CONNECTED) 9] ls /test [snode0000000002, snode0000000001, snode0000000003]
Java API
待補充。
Curator
1. Curator是Netflix開源的一套ZooKeeper客戶端框架,解決了很多ZooKeeper客戶端非常底層的細節開發工作(如連接重連、反覆註冊Watcher、NodeExistsException異常等),是全世界最廣泛的ZooKeeper客戶端之一。
2. Curator的API最大亮點在於遵循了Fluent設計風格。
3. Maven依賴配置。
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>2.10.0</version> </dependency> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>2.10.0</version> </dependency>
ZooKeeper應用場景
數據發佈/訂閱
ZooKeeper採用推拉結合的“發佈/訂閱”方式:客戶端向伺服器註冊關註的節點,節點的數據變化時,伺服器向客戶端發送Watcher事件通知,客戶端收到通知後主動到伺服器獲取最新數據。
配置管理
1. 全局配置信息通常具備3個特性:
a) 數據量比較小;
b) 運行時數據內容動態變化;
c) 集群中個機器共用,配置一致。
2. 例如機器列表信息、運行時的開關配置、資料庫配置信息等。
3. 實現原理:“發佈/訂閱”(Watcher)。
4. 以資料庫切換舉例。
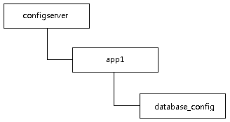
a) 配置存儲:管理員創建ZNode存儲配置。
1 import org.apache.curator.RetryPolicy; 2 import org.apache.curator.framework.CuratorFramework; 3 import org.apache.curator.framework.CuratorFrameworkFactory; 4 import org.apache.curator.retry.ExponentialBackoffRetry; 5 import org.apache.curator.utils.CloseableUtils; 6 7 public class CreateConfig { 8 9 public static void main(String[] args) throws Exception { 10 String path = "/configserver/app1/database_config"; 11 String config = "jdbc.driver=com.mysql.jdbc.Driver\n" 12 + "jdbc.url=jdbc:mysql://centos1:3306/test?useUnicode=true&characterEncoding=utf8\n" 13 + "jdbc.username=test\n" 14 + "jdbc.password=test\n"; 15 16 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); 17 CuratorFramework client = null; 18 try { 19 client = CuratorFrameworkFactory.builder() 20 .connectString("centos1:2181,centos2:2181") 21 .sessionTimeoutMs(5000) 22 .retryPolicy(retryPolicy) 23 .build(); // Fluent 24 client.start(); 25 client.create() 26 .creatingParentContainersIfNeeded() 27 .forPath(path, config.getBytes()); 28 } finally { 29 CloseableUtils.closeQuietly(client); 30 } 31 } 32 33 }
b) 配置獲取:集群機各機器啟動時獲取配置,並註冊該ZNode數據變更的Watcher。
1 import org.apache.curator.RetryPolicy; 2 import org.apache.curator.framework.CuratorFramework; 3 import org.apache.curator.framework.CuratorFrameworkFactory; 4 import org.apache.curator.framework.recipes.cache.NodeCache; 5 import org.apache.curator.framework.recipes.cache.NodeCacheListener; 6 import org.apache.curator.retry.ExponentialBackoffRetry; 7 import org.apache.curator.utils.CloseableUtils; 8 9 public class RunServer { 10 11 public static void main(String[] args) throws Exception { 12 String path = "/configserver/app1/database_config"; 13 14 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); 15 CuratorFramework client = null; 16 NodeCache nodeCache = null; 17 try { 18 client = CuratorFrameworkFactory.builder() 19 .connectString("centos1:2181,centos2:2181") 20 .sessionTimeoutMs(5000) 21 .retryPolicy(retryPolicy) 22 .build(); 23 client.start(); 24 byte[] data = client.getData() 25 .forPath(path); 26 System.out.println("Get config when server starting."); 27 System.out.println(new String(data)); 28 29 // Register watcher 30 nodeCache = new NodeCache(client, path, false); 31 nodeCache.start(true); 32 final NodeCache nc = nodeCache; 33 nodeCache.getListenable().addListener(new NodeCacheListener() { 34 35 @Override 36 public void nodeChanged() throws Exception { 37 System.out.println("Get config when changed."); 38 System.out.println(new String(nc.getCurrentData().getData())); 39 } 40 41 }); 42 43 Thread.sleep(Long.MAX_VALUE); 44 45 } finally { 46 CloseableUtils.closeQuietly(nodeCache); 47 CloseableUtils.closeQuietly(client); 48 } 49 } 50 51 }
c) 配置變更:管理員修改ZNode的數據(配置)。
1 import org.apache.curator.RetryPolicy; 2 import org.apache.curator.framework.CuratorFramework; 3 import org.apache.curator.framework.CuratorFrameworkFactory; 4 import org.apache.curator.retry.ExponentialBackoffRetry; 5 import org.apache.curator.utils.CloseableUtils; 6 7 public class UpdateConfig { 8 9 public static void main(String[] args) throws Exception { 10 String path = "/configserver/app1/database_config"; 11 String config = "jdbc.driver=com.mysql.jdbc.Driver\n" 12 + "jdbc.url=jdbc:mysql://centos2:3306/test?useUnicode=true&characterEncoding=utf8\n" 13 + "jdbc.username=foo\n" 14 + "jdbc.password=foo\n"; 15 16 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); 17 CuratorFramework client = null; 18 try { 19 client = CuratorFrameworkFactory.builder() 20 .connectString("centos1:2181,centos2:2181") 21 .sessionTimeoutMs(5000) 22 .retryPolicy(retryPolicy) 23 .build(); // Fluent 24 client.start(); 25 client.setData() 26 .forPath(path, config.getBytes()); 27 } finally { 28 CloseableUtils.closeQuietly(client); 29 } 30 } 31 32 }
命名服務
1. 分散式系統中,被命名的實體通常是集群中的機器、提供的服務地址或遠程對象等。
2. 廣義上命名服務的資源定位不一定是實體資源,比如分散式全局唯一ID。
3. 以資料庫主鍵(分散式全局唯一ID的一種)舉例。

a) 可使用UUID,但UUID的缺點:長度過長;字面上看不出含義。
b) 實現原理:順序節點。
c) 代碼。
1 import org.apache.curator.RetryPolicy; 2 import org.apache.curator.framework.CuratorFramework; 3 import org.apache.curator.framework.CuratorFrameworkFactory; 4 import org.apache.curator.retry.ExponentialBackoffRetry; 5 import org.apache.curator.utils.CloseableUtils; 6 import org.apache.zookeeper.CreateMode; 7 8 public class GenerateId { 9 10 public static void main(String[] args) throws Exception { 11 for (int index = 0; index < 10; index++) { 12 // type1-job-0000000000 13 System.out.println(generate("type1")); 14 } 15 for (int index = 0; index < 5; index++) { 16 // type2-job-0000000000 17 System.out.println(generate("type2")); 18 } 19 } 20 21 private static String generate(String type) throws Exception { 22 String path = "/generateid/" + type + "/job-"; 23 24 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); 25 CuratorFramework client = null; 26 try { 27 client = CuratorFrameworkFactory.builder() 28 .connectString("centos1:2181,centos2:2181") 29 .sessionTimeoutMs(5000) 30 .retryPolicy(retryPolicy) 31 .build(); 32 client.start(); 33 path = client.create() 34 .creatingParentContainersIfNeeded() 35 .withMode(CreateMode.PERSISTENT_SEQUENTIAL) 36 .forPath(path); 37 return type + '-' + path.substring(path.lastIndexOf('/') + 1); 38 } finally { 39 CloseableUtils.closeQuietly(client); 40 } 41 } 42 43 }
集群管理
1. 集群機器監控。
a) 實現過程:監控系統在/cluster_server節點上註冊Watcher監聽,添加機器時,由機器在/cluster_server節點下創建一個臨時節點/cluster_server/[host_name],並定時寫入運行狀態信息。
b) 既能實時獲取機器的上/下線情況,又能獲取機器的運行信息。
c) 適合大規模分散式系統監控。
2. 分散式日誌收集。
a) 日誌系統包含日誌源機器和收集器機器,由於硬體問題、擴容、機房遷移或網路問題等原因,他們都在變更。
b) 實現過程。
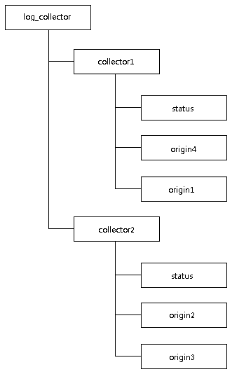
i. 註冊收集器機器:收集器機器啟動時創建一個持久節點/log_collector/[collector_hostname],再創建一個臨時節點/log_collector/[collector_hostname]/status,寫入運行狀態信息。
ii. 任務分發:日誌系統將全部日誌源機器分為若幹組,分別在相應的收集器機器創建的節點/log_collector/[collector_hostname]下創建持久節點/log_collector/[collector_hostname]/[origin_hostname],而收集器機器獲取/log_collector/[collector_hostname]的子節點來得到日誌源機器列表,同時Watcher監聽/log_collector/[collector_hostname]的子節點變化。
iii. 動態分配:日誌系統始終Watcher監聽/log_collector下的全部子節點,當有新收集器機器加入時,則將負載高的任務重新分配給新收集器機器;當有收集器機器退出時,則將其下的日誌源機器重新分配給其他收集器機器。
Master選舉
1. Master用來協調集群中其他系統單元,具有對分散式系統狀態變更的決定權。例如讀寫分離場景中,客戶端寫請求是由Master處理的。
2. 實現原理:利用ZooKeeper強一致性,保證在分散式高併發情況下節點創建一定全局唯一,即保證客戶端無法重覆創建一個已存在的ZNode。
3. 實現過程:選舉時,集群中各機器同時創建臨時節點/master_election,並寫入機器信息,創建成功的機器成為Master,創建失敗的機器Watcher監控節點/master_election開始等待,一旦該節點被移除則重新選舉。
4. Curator封裝了Master選舉功能。
1 import org.apache.curator.RetryPolicy; 2 import org.apache.curator.framework.CuratorFramework; 3 import org.apache.curator.framework.CuratorFrameworkFactory; 4 import org.apache.curator.framework.recipes.leader.LeaderSelector; 5 import org.apache.curator.framework.recipes.leader.LeaderSelectorListenerAdapter; 6 import org.apache.curator.retry.ExponentialBackoffRetry; 7 import org.apache.curator.utils.CloseableUtils; 8 9 public class MasterElection { 10 11 public static void main(String[] args) throws Exception { 12 String path = "/master_election"; 13 14 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); 15 CuratorFramework client = null; 16 LeaderSelector selector = null; 17 try { 18 client = CuratorFrameworkFactory.builder() 19 .connectString("centos1:2181,centos2:2181") 20 .sessionTimeoutMs(5000) 21 .retryPolicy(retryPolicy) 22 .build(); 23 client.start(); 24 selector = new LeaderSelector(client, path, new LeaderSelectorListenerAdapter() { 25 26 @Override 27 public void takeLeadership(CuratorFramework client) throws Exception { 28 long threadId = Thread.currentThread().getId(); 29 System.out.println("Thread" + threadId + " is master."); 30 Thread.sleep(3000); 31 System.out.println("Thread" + threadId + " has been down."); 32 System.exit(0); 33 } 34 35 }); 36 selector.autoRequeue(); 37 selector.start(); 38 Thread.sleep(Long.MAX_VALUE); 39 40 } catch (InterruptedException e) { 41 e.printStackTrace(); 42 43 } finally { 44 CloseableUtils.closeQuietly(selector); 45 CloseableUtils.closeQuietly(client); 46 } 47 } 48 49 }
分散式鎖
1. 分散式鎖是控制分散式系統之間同步訪問共用資源的一種方式。
2. 分散式鎖分為排它鎖(Exclusive Lock,簡稱X鎖,又稱寫鎖、獨占鎖)和共用鎖(Shared Lock,簡稱S鎖,又稱讀鎖)。
a) 排它鎖類似JDK的synchronized和ReentrantLock。
b) 共用鎖類似JDK的ReadWriteLock中的讀鎖。
3. 排它鎖實現過程:與Master選舉類似。所有客戶端同時創建臨時節點/execlusive_lock,創建成功的客戶端獲取了鎖,創建失敗的客戶端Watcher監聽節點/execlusive_lock開始等待,一旦該節點被移除(即排它鎖已釋放)則重覆該過程。
4. 共用鎖實現過程:
a) 創建持久節點/shared_lock。
b) 所有客戶端根據需要的鎖類型(R/W)創建臨時順序節點/shared_lock/[hostname-R/W-],如/shared_lock/[host1-R-0000000000]、/shared_lock/host1-W-0000000003。
c) 獲取/shared_lock下的所有子節點。
d) 各客戶端確定自己的節點順序。
i. 當前客戶端需要R鎖時,如果無比自己序號小的子節點或所有比自己序號小的子節點都是R鎖,則獲取R鎖成功;如果比自己序號小的子節點有W鎖,則Watcher監聽該W鎖節點並等待。
ii. 當前客戶端需要W鎖時,如果自己序號是最小的子節點,則獲取W鎖成功,否則Watcher監聽比自己序號小的子節點中序號最大的節點並等待。
e) 各客戶端收到Watcher通知後,則獲取鎖成功。
5. Curator封裝了分散式鎖功能。
分散式隊列
1. 業界分散式隊列產品大多是消息中間件(或稱消息隊列),ZooKeeper也可實現分散式隊列功能。
2. 分散式隊列分為FIFO和Barrier兩種:
a) FIFO即常見的隊列;
b) Barrier類似JDK的CyclicBarrier,等待的數量達到一定值時才執行。
3. FIFO實現過程(類似共用鎖):
a) 創建持久節點/queue_fifo。
b) 所有客戶端創建臨時順序節點/queue_fifo/[hostname-],如/queue_fifo/host1-0000000000。
c) 獲取/ queue_fifo下的所有子節點。
d) 各客戶端確定自己的節點順序:如果自己序號是最小的子節點,則執行;否則Watcher監聽比自己序號小的節點中序號最大的節點並等待。
e) 收到Watcher通知後,則執行。
4. Barrier實現過程:
a) 創建持久節點/queue_barrier。
b) 所有客戶端創建臨時節點/queue_barrier/[hostname],如/queue_fifo/host1。
c) 獲取/ queue_fifo下的所有子節點。
d) 如果子節點數大於或等於某值,則執行;否則Watcher監聽節點/queue_barrier並等待。
e) 收到Watcher通知後,重覆步驟c。
Hadoop
1. HDFS的NameNode和YARN的ResourceManager都是基於ZooKeeper實現HA。
2. YARN的HA實現過程(類似Master選舉):
a) 運行期間,多個ResourceManager並存,但只有一個為Active狀態,其他為Standby狀態。
b) 當Active狀態的節點無法工作時,Standby狀態的節點競爭選舉產生新的Active節點。
c) 假設ResourceManager1“假死”,可能會導致ResourceManager2變為Active狀態,當ResourceManager1恢復後,出現“腦裂”。通過ACL許可權控制可以解決,即ResourceManager1恢復後發現ZNode不是自己創建,則自動切換為Standby狀態。
HBase
與大部分分散式NoSQL資料庫不同的是,HBase的數據寫入是強一致性的,甚至索引列也是強一致性。
Kafka
Kafka主要用於實現低延時的發送和收集大量的事件和日誌數據。大型互聯網Web應用中,指網站的PV數和用戶訪問記錄等。
作者:netoxi
出處:http://www.cnblogs.com/netoxi
本文版權歸作者和博客園共有,歡迎轉載,未經同意須保留此段聲明,且在文章頁面明顯位置給出原文連接。歡迎指正與交流。


