
可能很多Java的初學者對String的存儲和賦值有迷惑,以下是一個很簡單的測試用例,你只需要花幾分鐘時間便可理解。 1.在看例子之前,確保你理解以下幾個術語: 棧:由JVM分配區域,用於保存線程執行的動作和數據引用。棧是一個運行的單位,Java中一個線程就會相應有一個線程棧與之對應。 堆:由JVM ...
可能很多Java的初學者對String的存儲和賦值有迷惑,以下是一個很簡單的測試用例,你只需要花幾分鐘時間便可理解。
1.在看例子之前,確保你理解以下幾個術語:
棧:由JVM分配區域,用於保存線程執行的動作和數據引用。棧是一個運行的單位,Java中一個線程就會相應有一個線程棧與之對應。
堆:由JVM分配的,用於存儲對象等數據的區域。
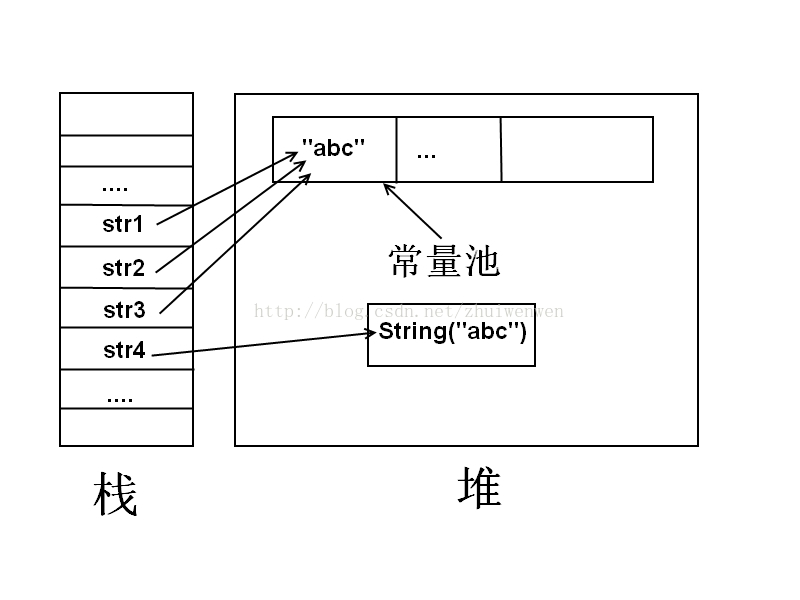
常量池:在編譯的階段,在堆中分配出來的一塊存儲區域,用於存儲顯式的String,float或者integer.例如String str="abc"; abc這個字元串是顯式聲明,所以存儲在常量池。
2.看這個例子,用JDK5+junit4.5寫的例子,完全通過測試
import static org.junit.Assert.assertNotSame; import static org.junit.Assert.assertSame; import org.junit.Test; /** * @author Heis * */ public class StringTest{ @Test public void testTheSameReference1(){ String str1="abc"; String str2="abc"; String str3="ab"+"c"; String str4=new String(str2); //str1和str2引用自常量池裡的同一個string對象 assertSame(str1,str2); //str3通過編譯優化,與str1引用自同一個對象 assertSame(str1,str3); //str4因為是在堆中重新分配的另一個對象,所以它的引用與str1不同 assertNotSame(str1,str4); } }
- 第一個斷言很好理解,因為在編譯的時候,"abc"被存儲在常量池中,str1和str2的引用都是指向常量池中的"abc"。所以str1和str2引用是相同的。
- 第二個斷言是由於編譯器做了優化,編譯器會先把字元串拼接,再在常量池中查找這個字元串是否存在,如果存在,則讓變數直接引用該字元串。所以str1和str3引用也是相同的。
- str4的對象不是顯式賦值的,編譯器會在堆中重新分配一個區域來存儲它的對象數據。所以str1和str4的引用是不一樣的。
另一種說法,求大神指點
JVM記憶體分四種: 1、棧區(stacksegment)—由編譯器自動分配釋放,存放函數的參數值,局部變數的值等,具體方法執行結束之後,系統自動釋放JVM記憶體資源 2、堆區(heapsegment)—一般由程式員分配釋放,存放由new創建的對象和數組,jvm不定時查看這個對象,如果沒有引用指向這個對象就回收 3、靜態區(datasegment)—存放全局變數,靜態變數和字元串常量,不釋放 4、代碼區(codesegment)—存放程式中方法的二進位代碼,而且是多個對象共用一個代碼空間區域 在方法(代碼塊)中定義一個變數時,java就在棧中為這個變數分配JVM記憶體空間,當超過變數的作用域後,java會自動釋放掉為該變數所分配的JVM記憶體空間;在堆中分配的JVM記憶體由java虛擬機的自動垃圾回收器來管理,堆的優勢是可以動態分配JVM記憶體大小,生存期也不必事先告訴編譯器,因為它是在運行時動態分配JVM記憶體的。缺點就是要在運行時動態分配JVM記憶體,存取速度較慢;棧的優勢是存取速度比堆要快,缺點是存在棧中的數據大小與生存期必須是確定的無靈活性。 ◆java堆由Perm區和Heap區組成,Heap區則由Old區和New區組成,而New區又分為Eden區,From區,To區,Heap={Old+NEW={Eden,From,To}},見圖1所示。 Heap區分兩大塊,一塊是NEWGeneration,另一塊是OldGeneration.在NewGeneration中,有一個叫Eden的空間,主要是用來存放新生的對象,還有兩個SurvivorSpaces(from,to),它們用來存放每次垃圾回收後存活下來的對象。在OldGeneration中,主要存放應用程式中生命周期長的JVM記憶體對象,還有個PermanentGeneration,主要用來放JVM自己的反射對象,比如類對象和方法對象等。 在NewGeneration塊中,垃圾回收一般用Copying的演算法,速度快。每次GC的時候,存活下來的對象首先由Eden拷貝到某個SurvivorSpace,當SurvivorSpace空間滿了後,剩下的live對象就被直接拷貝到OldGeneration中去。因此,每次GC後,EdenJVM記憶體塊會被清空。在OldGeneration塊中,垃圾回收一般用mark-compact的演算法,速度慢些,但減少JVM記憶體要求. 垃圾回收分多級,0級為全部(Full)的垃圾回收,會回收OLD段中的垃圾;1級或以上為部分垃圾回收,只會回收NEW中的垃圾,JVM記憶體溢出通常發生於OLD段或Perm段垃圾回收後,仍然無JVM記憶體空間容納新的Java對象的情況。 JVM調用GC的頻度還是很高的,主要兩種情況下進行垃圾回收:當應用程式線程空閑;另一個是JVM記憶體堆不足時,會不斷調用GC,若連續回收都解決不了JVM記憶體堆不足的問題時,就會報outofmemory錯誤。因為這個異常根據系統運行環境決定,所以無法預期它何時出現。 根據GC的機制,程式的運行會引起系統運行環境的變化,增加GC的觸發機會。為了避免這些問題,程式的設計和編寫就應避免垃圾對象的JVM記憶體占用和GC的開銷。顯示調用System.GC()只能建議JVM需要在JVM記憶體中對垃圾對象進行回收,但不是必須馬上回收,一個是並不能解決JVM記憶體資源耗空的局面,另外也會增加GC的消耗。 ◆當一個URL被訪問時,JVM記憶體區域申請過程如下: A.JVM會試圖為相關Java對象在Eden中初始化一塊JVM記憶體區域 B.當Eden空間足夠時,JVM記憶體申請結束。否則到下一步 C.JVM試圖釋放在Eden中所有不活躍的對象(這屬於1或更高級的垃圾回收),釋放後若Eden空間仍然不足以放入新對象,則試圖將部分Eden中活躍對象放入Survivor區 D.Survivor區被用來作為Eden及OLD的中間交換區域,當OLD區空間足夠時,Survivor區的對象會被移到Old區,否則會被保留在Survivor區 E.當OLD區空間不夠時,JVM會在OLD區進行完全的垃圾收集(0級) F.完全垃圾收集後,若Survivor及OLD區仍然無法存放從Eden複製過來的部分對象,導致JVM無法在Eden區為新對象創建JVM記憶體區域,則出現"outofmemory錯誤"
本文摘自:http://blog.csdn.net/zhuiwenwen/article/details/12351565,感謝作者:zhuiwenwen


