
哈希(Hash)又稱散列,它是一個很常見的演算法。在Java的HashMap數據結構中主要就利用了哈希。哈希演算法包括了哈希函數和哈希表兩部分。我們數組的特性可以知道,可以通過下標快速(O(1))的定位元素,同理在哈希表中我們可以通過鍵(哈希值)快速的定位某個值,這個哈希值的計算就是通過哈希函數(has ...
哈希(Hash)又稱散列,它是一個很常見的演算法。在Java的HashMap數據結構中主要就利用了哈希。哈希演算法包括了哈希函數和哈希表兩部分。我們數組的特性可以知道,可以通過下標快速(O(1))的定位元素,同理在哈希表中我們可以通過鍵(哈希值)快速的定位某個值,這個哈希值的計算就是通過哈希函數(hash(key) = address )計算得出的。通過哈希值即能定位元素[address] = value,原理同數組類似。
最好的哈希函數當然是每個key值都能計算出唯一的哈希值,但往往可能存在不同的key值的哈希值,這就造成了衝突,評判一個哈希函數是否設計良好的兩個方面:
1.衝突少。
2.計算快。
下麵給出幾種常用的哈希函數,它們的背後都有一定的數學原理且經過大量實踐,其數學原理不在這裡探究。
BKDR哈希函數(h = 31 * h + c)
這個哈希函數被應用在Java的字元串哈希值計算。
//String#hashCode public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; //BKDR 哈希函數,常數可以是131、1313、13131…… } hash = h; } return h; }
DJB2 哈希函數(h = h << 5 + h + c = h = 33 * h + c)
ElasticSearch就利用了DJB2哈希函數對要索引文檔的指定key進行哈希。
SDBM哈希函數(h = h << 6 + h << 16 - h + c = 65599 * h + c)
在SDBM(一種簡單的資料庫引擎)中被應用。
以上只是列舉了三種哈希函數,我們做下試驗,看看它們的衝突情況是怎麼樣的。
Java
1 package com.algorithm.hash; 2 3 import java.util.HashMap; 4 import java.util.UUID; 5 6 /** 7 * 三種哈希函數衝突數比較 8 * Created by yulinfeng on 6/27/17. 9 */ 10 public class HashFunc { 11 12 public static void main(String[] args) { 13 int length = 1000000; //100萬字元串 14 //利用HashMap來計算衝突數,HashMap的鍵值不能重覆所以length - map.size()即為衝突數 15 HashMap<String, String> bkdrMap = new HashMap<String, String>(); 16 HashMap<String, String> djb2Map = new HashMap<String, String>(); 17 HashMap<String, String> sdbmMap = new HashMap<String, String>(); 18 getStr(length, bkdrMap, djb2Map, sdbmMap); 19 System.out.println("BKDR哈希函數100萬字元串的衝突數:" + (length - bkdrMap.size())); 20 System.out.println("DJB2哈希函數100萬字元串的衝突數:" + (length - djb2Map.size())); 21 System.out.println("SDBM哈希函數100萬字元串的衝突數:" + (length - sdbmMap.size())); 22 } 23 24 /** 25 * 生成字元串,並計算衝突數 26 * @param length 27 * @param bkdrMap 28 * @param djb2Map 29 * @param sdbmMap 30 */ 31 private static void getStr(int length, HashMap<String, String> bkdrMap, HashMap<String, String> djb2Map, HashMap<String, String> sdbmMap) { 32 for (int i = 0; i < length; i++) { 33 System.out.println(i); 34 String str = UUID.randomUUID().toString(); 35 bkdrMap.put(String.valueOf(str.hashCode()), str); //Java的String.hashCode就是BKDR哈希函數, h = 31 * h + c 36 djb2Map.put(djb2(str), str); //DJB2哈希函數 37 sdbmMap.put(sdbm(str), str); //SDBM哈希函數 38 } 39 } 40 41 /** 42 * djb2哈希函數 43 * @param str 44 * @return 45 */ 46 private static String djb2(String str) { 47 int hash = 0; 48 for (int i = 0; i != str.length(); i++) { 49 hash = hash * 33 + str.charAt(i); //h = h << 5 + h + c = h = 33 * h + c 50 } 51 return String.valueOf(hash); 52 } 53 54 /** 55 * sdbm哈希函數 56 * @param str 57 * @return 58 */ 59 private static String sdbm(String str) { 60 int hash = 0; 61 for (int i = 0; i != str.length(); i++) { 62 hash = 65599 * hash + str.charAt(i); //h = h << 6 + h << 16 - h + c = 65599 * h + c 63 } 64 return String.valueOf(hash); 65 } 66 }
以下是10萬、100萬、200萬的衝突數情況:
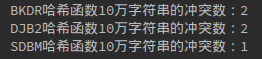


反覆試驗實際上三種哈希函數的衝突數差不多。
Python3
1 import uuid 2 3 def hash_test(length, bkdrDic, djb2Dic, sdbmDic): 4 for i in range(length): 5 string = str(uuid.uuid1()) #基於時間戳 6 bkdrDic[bkdr(string)] = string 7 djb2Dic[djb2(string)] = string 8 sdbmDic[sdbm(string)] = string 9 10 #BDKR哈希函數 11 def bkdr(string): 12 hash = 0 13 for i in range(len(string)): 14 hash = 31 * hash + ord(string[i]) # h = 31 * h + c 15 return hash 16 17 #DJB2哈希函數 18 def djb2(string): 19 hash = 0 20 for i in range(len(string)): 21 hash = 33 * hash + ord(string[i]) # h = h << 5 + h + c 22 return hash 23 24 #SDBM哈希函數 25 def sdbm(string): 26 hash = 0 27 for i in range(len(string)): 28 hash = 65599 * hash + ord(string[i]) # h = h << 6 + h << 16 - h + c 29 return hash 30 31 length = 100 32 bkdrDic = dict() #bkdrDic = {} 33 djb2Dic = dict() 34 sdbmDic = dict() 35 hash_test(length, bkdrDic, djb2Dic, sdbmDic) 36 print("BKDR哈希函數100萬字元串的衝突數:%d"%(length - len(bkdrDic))) 37 print("DJB2哈希函數100萬字元串的衝突數:%d"%(length - len(djb2Dic))) 38 print("SDBM哈希函數100萬字元串的衝突數:%d"%(length - len(sdbmDic)))
哈希表是一種數據結構,它需要配合哈希函數使用,用於建立索引,便於快速查找——《演算法筆記》。一般來講它就是一個定長的存儲空間,比如HashMap預設的哈希表就是定長為16的Entry數組。有了定長的存儲空間過後,剩下的問題就是如何將值放入哪個位置,通常如果哈希值是m,長度為n,那麼這個值就放到m mod n位置處。
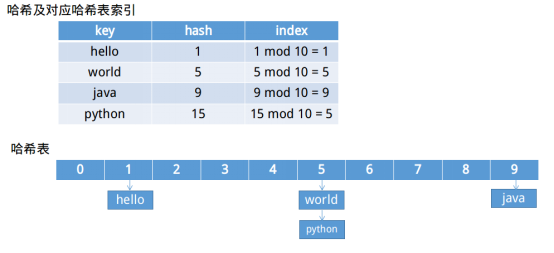
上圖就是哈希和哈希表,以及產生衝突的解決辦法(拉鏈法)。產生衝突後的解決辦法有很多,有再哈希一次直到沒有衝突,也有向上圖一樣採用拉鏈法利用鏈表將相同位置的元素串聯。
想象一下,上面的例子哈希表的長度為10,產生了1次衝突,如果哈希表長度為20,那麼就不會產生衝突查找更快但會浪費更多空間,如果哈希表長度為2,將會倒置3次衝突查找更慢但這樣又會節省不少空間。所以哈希表的長度選擇至關重要,但同時也是一個重要的難題。
補充:
哈希在很多方面有應用,例如在不同的值有不同的哈希值,但也可以將哈希演算法設計精妙使得相似或相同的值有相似或相同的哈希值。也就是說如果兩個對象完全不同,那麼它們的哈希值也完全不同;如果兩個對象完全相同,那麼它們的哈希值也完全相同;兩個對象越相似,那麼它們的哈希值也就越相似。這實際上就是相似性問題,也就是說這個思想可以被推廣應用到相似性的計算(例如Jaccard距離問題),最終應用到廣告精準投放、商品推薦等。
另外,一致性哈希也可應用在負載均衡,如何保證每台伺服器能均勻的分攤負載壓力,一個好的哈希演算法也可做到。


