
python多進程和多線程誰更快 python3.6 threading和multiprocessing 四核+三星250G 850 SSD 自從用多進程和多線程進行編程,一致沒搞懂到底誰更快。網上很多都說python多進程更快,因為GIL(全局解釋器鎖)。但是我在寫代碼的時候,測試時間卻是多線程更 ...
python多進程和多線程誰更快
- python3.6
- threading和multiprocessing
- 四核+三星250G-850-SSD
自從用多進程和多線程進行編程,一致沒搞懂到底誰更快。網上很多都說python多進程更快,因為GIL(全局解釋器鎖)。但是我在寫代碼的時候,測試時間卻是多線程更快,所以這到底是怎麼回事?最近再做分詞工作,原來的代碼速度太慢,想提速,所以來探求一下有效方法(文末有代碼和效果圖)
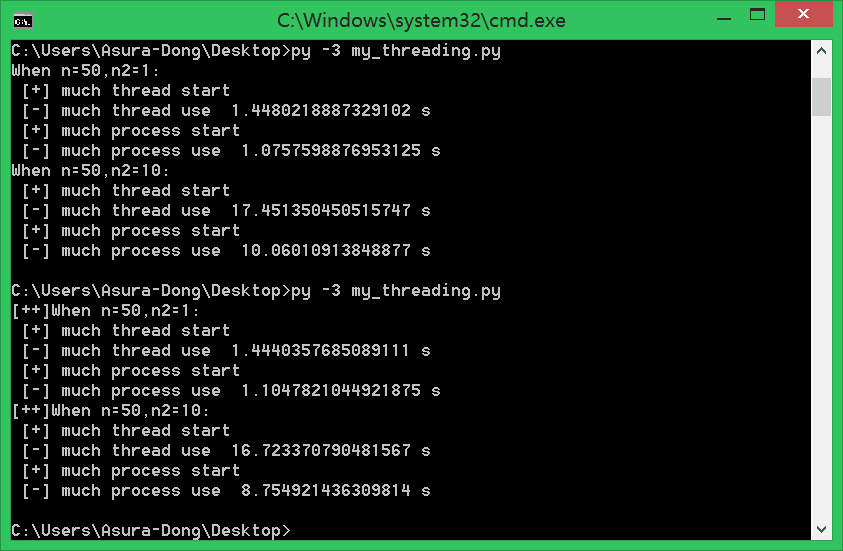
這裡先來一張程式的結果圖,說明線程和進程誰更快
一些定義
並行是指兩個或者多個事件在同一時刻發生。併發是指兩個或多個事件在同一時間間隔內發生
線程是操作系統能夠進行運算調度的最小單位。它被包含在進程之中,是進程中的實際運作單位。一個程式的執行實例就是一個進程。
實現過程
而python裡面的多線程顯然得拿到GIL,執行code,最後釋放GIL。所以由於GIL,多線程的時候拿不到,實際上,它是併發實現,即多個事件,在同一時間間隔內發生。
但進程有獨立GIL,所以可以並行實現。因此,針對多核CPU,理論上採用多進程更能有效利用資源。
現實問題
在網上的教程裡面,經常能見到python多線程的身影。比如網路爬蟲的教程、埠掃描的教程。
這裡拿埠掃描來說,大家可以用多進程實現下麵的腳本,會發現python多進程更快。那麼不就是和我們分析相悖了嗎?
import sys,threading
from socket import *
host = "127.0.0.1" if len(sys.argv)==1 else sys.argv[1]
portList = [i for i in range(1,1000)]
scanList = []
lock = threading.Lock()
print('Please waiting... From ',host)
def scanPort(port):
try:
tcp = socket(AF_INET,SOCK_STREAM)
tcp.connect((host,port))
except:
pass
else:
if lock.acquire():
print('[+]port',port,'open')
lock.release()
finally:
tcp.close()
for p in portList:
t = threading.Thread(target=scanPort,args=(p,))
scanList.append(t)
for i in range(len(portList)):
scanList[i].start()
for i in range(len(portList)):
scanList[i].join()誰更快
因為python鎖的問題,線程進行鎖競爭、切換線程,會消耗資源。所以,大膽猜測一下:
在CPU密集型任務下,多進程更快,或者說效果更好;而IO密集型,多線程能有效提高效率。
import time
import threading
import multiprocessing
max_process = 4
max_thread = max_process
def fun(n,n2):
#cpu密集型
for i in range(0,n):
for j in range(0,(int)(n*n*n*n2)):
t = i*j
def thread_main(n2):
thread_list = []
for i in range(0,max_thread):
t = threading.Thread(target=fun,args=(50,n2))
thread_list.append(t)
start = time.time()
print(' [+] much thread start')
for i in thread_list:
i.start()
for i in thread_list:
i.join()
print(' [-] much thread use ',time.time()-start,'s')
def process_main(n2):
p = multiprocessing.Pool(max_process)
for i in range(0,max_process):
p.apply_async(func = fun,args=(50,n2))
start = time.time()
print(' [+] much process start')
p.close()#關閉進程池
p.join()#等待所有子進程完畢
print(' [-] much process use ',time.time()-start,'s')
if __name__=='__main__':
print("[++]When n=50,n2=0.1:")
thread_main(0.1)
process_main(0.1)
print("[++]When n=50,n2=1:")
thread_main(1)
process_main(1)
print("[++]When n=50,n2=10:")
thread_main(10)
process_main(10)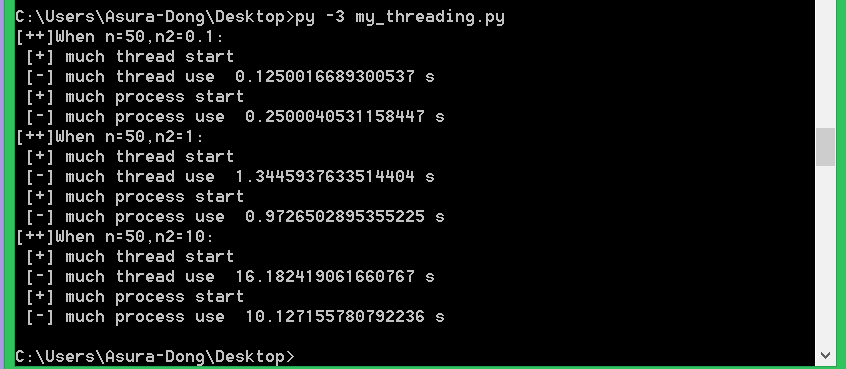
可以看出來,當對cpu使用率越來越高的時候(代碼迴圈越多的時候),差距越來越大。驗證我們猜想
CPU和IO密集型
- CPU密集型代碼(各種迴圈處理、計數等等)
- IO密集型代碼(文件處理、網路爬蟲等)
判斷方法:
- 直接看CPU占用率, 硬碟IO讀寫速度
- 計算較多->CPU;時間等待較多(如網路爬蟲)->IO
- 請自行百度
參考
為什麼在Python里推薦使用多進程而不是多線程?
如何判斷進程是IO密集還是CPU密集
搞定python多線程和多進程

