
一、Redis簡介 1.關於關係型資料庫和nosql資料庫 關係型資料庫是基於關係表的資料庫,最終會將數據持久化到磁碟上,而nosql數據 庫是基於特殊的結構,並將數據存儲到記憶體的資料庫。從性能上而言,nosql資料庫 要優於關係型資料庫,從安全性上而言關係型資料庫要優於nosql資料庫,所以在實 ...
一、Redis簡介
1.關於關係型資料庫和nosql資料庫
關係型資料庫是基於關係表的資料庫,最終會將數據持久化到磁碟上,而nosql數據 庫是基於特殊的結構,並將數據存儲到記憶體的資料庫。從性能上而言,nosql資料庫 要優於關係型資料庫,從安全性上而言關係型資料庫要優於nosql資料庫,所以在實 際開發中一個項目中nosql和關係型資料庫會一起使用,達到性能和安全性的雙保證。
2.為什麼要使用Redis
1)易擴展
2)大數據量提高性能
3)多樣靈活的數據模型
3.redis在Linux上的安裝
1)安裝redis編譯的c環境,yum install gcc-c++
2)將redis-2.6.16.tar.gz上傳到Linux系統中
3)解壓到/usr/local下 tar -xvf redis-2.6.16.tar.gz -C /usr/local
4)進入redis-2.6.16目錄 使用make命令編譯redis
5)在redis-2.6.16目錄中 使用make PREFIX=/usr/local/redis install命令安裝 redis到/usr/local/redis中
6)拷貝redis-2.6.16中的redis.conf到安裝目錄redis的bin中
7)啟動redis 在bin下執行命令redis-server redis.conf
8)如需遠程連接redis,需配置redis埠6379在linux防火牆中開發
/sbin/iptables -I INPUT -p tcp --dport 6379 -j ACCEPT
/etc/rc.d/init.d/iptables save
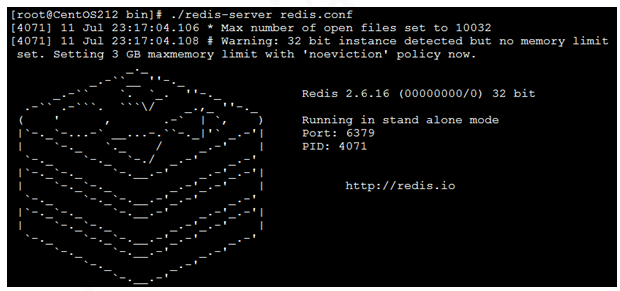
啟動後看到如上歡迎頁面,但此視窗不能關閉,視窗關閉就認為redis也關閉瞭解決方案:可以通過修改配置文件 配置redis後臺啟動,即伺服器啟動了但不會創建控制台視窗
將redis.conf文件中的daemonize從no修改成yes表示後臺啟動
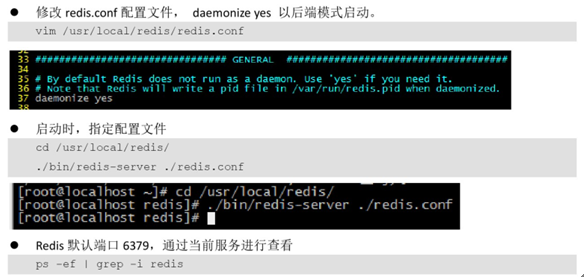
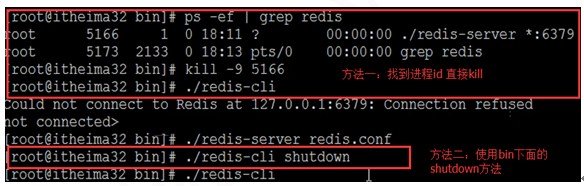
使用命令查看6379埠是否啟動ps -ef | grep redis
在bin下麵使用./redis-cli進入客戶端
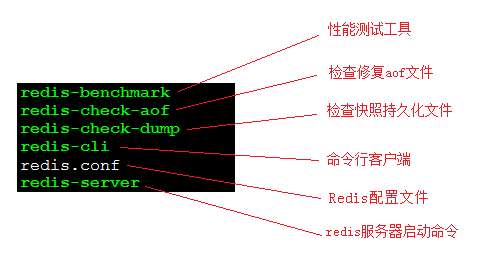
8)通過後臺啟動後怎麼關閉?
二、使用java去操作Redis




三、Redis的常用命令
redis是一種高級的key-value的存儲系統
其中的key是字元串類型,儘可能滿足如下幾點:
1)key不要太長,最好不要操作1024個位元組,這不僅會消耗記憶體還會降低查找效率
2)key不要太短,如果太短會降低key的可讀性
3)在項目中,key最好有一個統一的命名規範(根據企業的需求)
其中value 支持五種數據類型:
1)字元串型 string
2)字元串列表 lists
3)字元串集合 sets
4)有序字元串集合 sorted sets
5)哈希類型 hashs
我們對Redis的學習,主要是對數據的存儲,下麵將來學習各種Redis的數據類型的存儲操作:

1.存儲字元串string
字元串類型是Redis中最為基礎的數據存儲類型,它在Redis中是二進位安全的,這便意味著該類型可以接受任何格式的數據,如JPEG圖像數據或Json對象描述信息等。 在Redis中字元串類型的Value最多可以容納的數據長度是512M

1)set key value:設定key持有指定的字元串value,如果該key存在則進行覆蓋操作。總是返回”OK”
2)get key:獲取key的value。如果與該key關聯的value不是String類型,redis 將返回錯誤信息,因為get命令只能用於獲取String value;如果該key不存在,返 回null。

3)getset key value:先獲取該key的值,然後在設置該key的值。

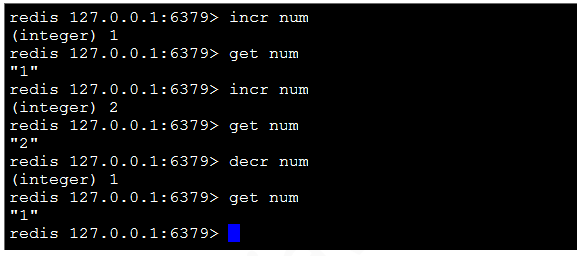
4)incr key:將指定的key的value原子性的遞增1.如果該key不存在,其初始值 為0,在incr之後其值為1。如果value的值不能轉成整型,如hello,該操作將執 行失敗並返回相應的錯誤信息。
5)decr key:將指定的key的value原子性的遞減1.如果該key不存在,其初始值 為0,在incr之後其值為-1。如果value的值不能轉成整型,如hello,該操作將執 行失敗並返回相應的錯誤信息。
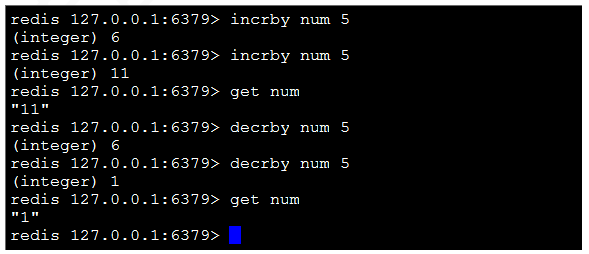
6)incrby key increment:將指定的key的value原子性增加increment,如果該 key不存在,器初始值為0,在incrby之後,該值為increment。如果該值不能轉成 整型,如hello則失敗並返回錯誤信息
7)decrby key decrement:將指定的key的value原子性減少decrement,如果 該key不存在,器初始值為0,在decrby之後,該值為decrement。如果該值不能 轉成整型,如hello則失敗並返回錯誤信息
8)append key value:如果該key存在,則在原有的value後追加該值;如果該 key 不存在,則重新創建一個key/value

2.存儲lists類型
在Redis中,List類型是按照插入順序排序的字元串鏈表。和數據結構中的普通鏈表一樣,我們可以在其頭部(left)和尾部(right)添加新的元素。在插入時,如果該鍵並不存在,Redis將為該鍵創建一個新的鏈表。與此相反,如果鏈表中所有的元素均被移除,那麼該鍵也將會被從資料庫中刪除。List中可以包含的最大元素數量是4294967295。
從元素插入和刪除的效率視角來看,如果我們是在鏈表的兩頭插入或刪除元素,這將會是非常高效的操作,即使鏈表中已經存儲了百萬條記錄,該操作也可以在常量時間內完成。然而需要說明的是,如果元素插入或刪除操作是作用於鏈表中間,那將會是非常低效的。相信對於有良好數據結構基礎的開發者而言,這一點並不難理解。

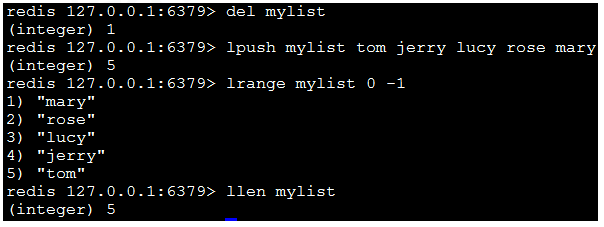
1)lpush key value1 value2...:在指定的key所關聯的list的頭部插入所有的 values,如果該key不存在,該命令在插入的之前創建一個與該key關聯的空鏈 表,之後再向該鏈表的頭部插入數據。插入成功,返回元素的個數。
2)rpush key value1、value2…:在該list的尾部添加元素
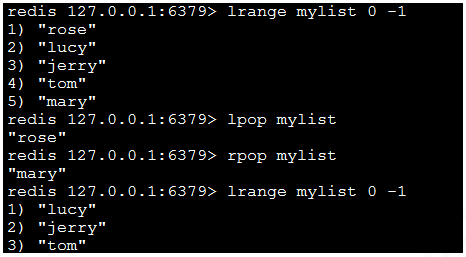
3)lrange key start end:獲取鏈表中從start到end的元素的值,start、end可 為負數,若為-1則表示鏈表尾部的元素,-2則表示倒數第二個,依次類推…

4)lpushx key value:僅當參數中指定的key存在時(如果與key管理的list中沒 有值時,則該key是不存在的)在指定的key所關聯的list的頭部插入value。
5)rpushx key value:在該list的尾部添加元素

6)lpop key:返回並彈出指定的key關聯的鏈表中的第一個元素,即頭部元素。
7)rpop key:從尾部彈出元素。
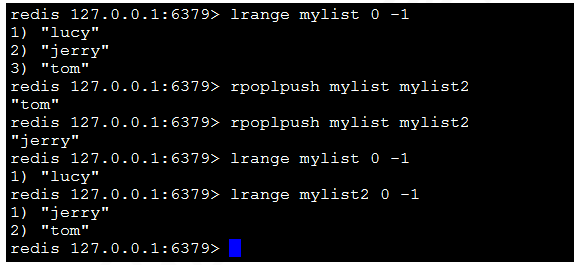
8)rpoplpush resource destination:將鏈表中的尾部元素彈出並添加到頭部
9)llen key:返回指定的key關聯的鏈表中的元素的數量。
10)lset key index value:設置鏈表中的index的腳標的元素值,0代錶鏈表的頭元 素,-1代錶鏈表的尾元素。

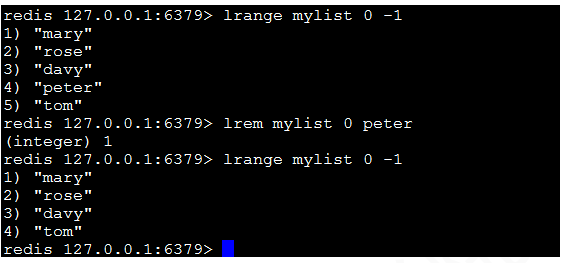
11)lrem key count value:刪除count個值為value的元素,如果count大於0,從頭向尾遍歷並刪除count個值為value的元素,如果count小於0,則從尾向頭遍歷並刪除。如果count等於0,則刪除鏈表中所有等於value的元素。
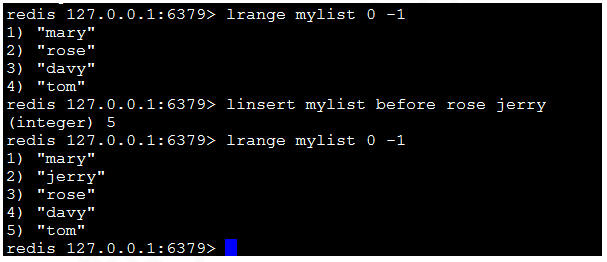
12)linsert key before|after pivot value:在pivot元素前或者後插入value這個元素。
3.存儲sets類型
在Redis中,我們可以將Set類型看作為沒有排序的字元集合,和List類型一樣,我們也可以在該類型的數據值上執行添加、刪除或判斷某一元素是否存在等操作。需要 說明的是,這些操作的時間是常量時間。Set可包含的最大元素數是4294967295。
和List類型不同的是,Set集合中不允許出現重覆的元素。和List類型相比,Set類 型在功能上還存在著一個非常重要的特性,即在伺服器端完成多個Sets之間的聚合計 算操作,如unions、intersections和differences。由於這些操作均在服務端完成, 因此效率極高,而且也節省了大量的網路IO開銷
1)sadd key value1、value2…:向set中添加數據,如果該key的值已有則不會 重覆添加
2)smembers key:獲取set中所有的成員
3)scard key:獲取set中成員的數量
4)sismember key member:判斷參數中指定的成員是否在該set中,1表示存 在,0表示不存在或者該key本身就不存在
5)srem key member1、member2…:刪除set中指定的成員
6)srandmember key:隨機返回set中的一個成員
7)sdiff sdiff key1 key2:返回key1與key2中相差的成員,而且與key的順序有關。即返回差集。

8)sdiffstore destination key1 key2:將key1、key2相差的成員存儲在destination上
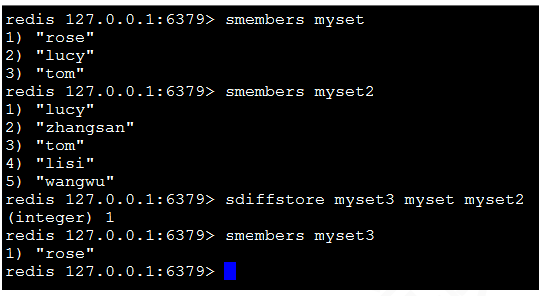
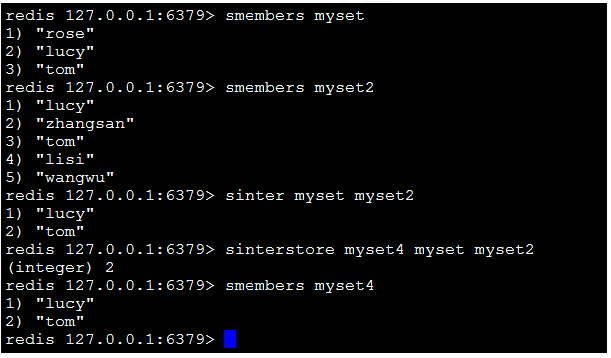
9)sinter key[key1,key2…]:返回交集。
10)sinterstore destination key1 key2:將返回的交集存儲在destination上
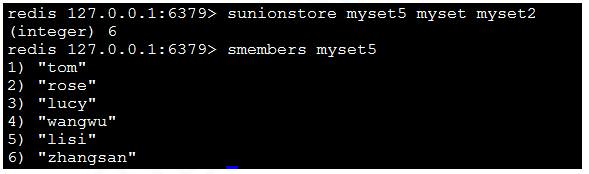
11)sunion key1、key2:返回並集。

12)sunionstore destination key1 key2:將返回的並集存儲在destination上
4.存儲sortedset
Sorted-Sets和Sets類型極為相似,它們都是字元串的集合,都不允許重覆的成員出現在一個Set中。它們之間的主要差別是Sorted-Sets中的每一個成員都會有一個分 數(score)與之關聯,Redis正是通過分數來為集合中的成員進行從小到大的排序。然而需要額外指出的是,儘管Sorted-Sets中的成員必須是唯一的,但是分數(score) 卻是可以重覆的。
在Sorted-Set中添加、刪除或更新一個成員都是非常快速的操作,其時間複雜度為 集合中成員數量的對數。由於Sorted-Sets中的成員在集合中的位置是有序的,因此, 即便是訪問位於集合中部的成員也仍然是非常高效的。事實上,Redis所具有的這一 特征在很多其它類型的資料庫中是很難實現的,換句話說,在該點上要想達到和Redis 同樣的高效,在其它資料庫中進行建模是非常困難的。
例如:游戲排名、微博熱點話題等使用場景。
1)zadd key score member score2 member2 … :將所有成員以及該成員的 分數存放到sorted-set中
2)zcard key:獲取集合中的成員數量

3)zcount key min max:獲取分數在[min,max]之間的成員
zincrby key increment member:設置指定成員的增加的分數。
zrange key start end [withscores]:獲取集合中腳標為start-end的成員,[withscores]參數表明返回的成員包含其分數。
zrangebyscore key min max [withscores] [limit offset count]:返回分數在[min,max]的成員並按照分數從低到高排序。[withscores]:顯示分數;[limit offset count]:offset,表明從腳標為offset的元素開始並返回count個成員。
zrank key member:返回成員在集合中的位置。
zrem key member[member…]:移除集合中指定的成員,可以指定多個成員。
zscore key member:返回指定成員的分數
5.存儲hash
Redis中的Hashes類型可以看成具有String Key和String Value的map容器。所以該類型非常適合於存儲值對象的信息。如Username、Password和Age等。如果 Hash中包含很少的欄位,那麼該類型的數據也將僅占用很少的磁碟空間。每一個Hash可以存儲4294967295個鍵值對。
1)hset key field value:為指定的key設定field/value對(鍵值對)。
2)hgetall key:獲取key中的所有filed-vaule

3)hget key field:返回指定的key中的field的值

4)hmset key fields:設置key中的多個filed/value
5)hmget key fileds:獲取key中的多個filed的值
6)hexists key field:判斷指定的key中的filed是否存在
7)hlen key:獲取key所包含的field的數量
8)hincrby key field increment:設置key中filed的值增加increment,如:age 增加20
總結:
1、nosql
2、redis安裝----linux(重點)
3、jedis(重點)
4、redis的數據操作類型 5種 (瞭解) --- string和hash
5、redis的其他


