
一、分散式緩存簡圖 二、為什麼使用Memcached分散式緩存呢? 三、Memcached基礎原理 四、Memcache下載與安裝 五、MencacheHelper.cs 示例使用 結合Session與項目配置緩存 六、Redis和Memcache的區別總結 一、分散式緩存簡圖 二、為什麼使用Mem
一、分散式緩存簡圖
二、為什麼使用Memcached分散式緩存呢?
三、Memcached基礎原理
四、Memcache下載與安裝
五、MencacheHelper.cs 示例使用 結合Session與項目配置緩存
六、Redis和Memcache的區別總結
一、分散式緩存簡圖

二、為什麼使用Memcached分散式緩存呢?
首先先講講為何要緩存,在數據驅動的web開發中,經常要重覆從資料庫中取出相同的數據,這種重覆極大的增加了資料庫負載。緩存是解決這個問題的好辦法。但是ASP.NET中的雖然已經可以實現對頁面局部進行緩存,但還是不夠靈活。Memcached應運而生。
1、高併發訪問資料庫的痛楚:死鎖!
2、磁碟IO之痛,資料庫讀寫說白了就是跟磁碟打交道,磁碟讀取速度是有限制的,一般高點也就7200轉
3、多客戶端共用緩存
4、Net+Memory >> IO
5、讀寫性能完美 1s 讀取可以達到1w次 寫:10w次
6、超簡單集群搭建 Clister
7、開源 Open Source
8、沒有提供主從賦值功能,也沒提供容災等功能(容災:即數據備份能使意外發生後恢複數據,Memcached不會進行備份,由於是緩存在記憶體中的,一斷電就會失去數據
),所以所有的代碼基本都只考慮性能最佳。如要考慮容災,則可使用Redis分散式緩存
9、學習成本非常低,入門非常容易
10、豐富的成功的案例。很多大型公司都是用這個來做分散式緩存
註:Memcached在企業中一般都是在linux下跑,才能達到性能最佳。
三、Memcached基礎原理
底層通信是使用Socket
可以將緩存伺服器理解為Socket服務端,將WEB伺服器理解為客戶端。

四、Memcache下載與安裝
下載,百度一下或者直接在csdn上搜一下windows Memcache穩定版就行,0積分。
1、下載完後,就這麼個exe
2、安裝,敲幾行cmd命令就行,截圖如下,左邊是我們電腦服務列表,可以看到,已經啟動了我們的Memcached(Memcache是這個開源項目的名稱,加個d,Memcached是具體這個應用程式,也就是這個exe的名稱)
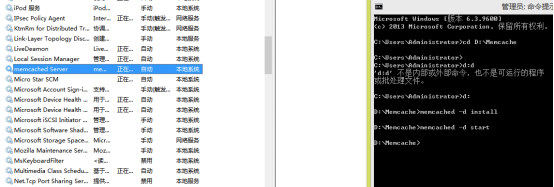
3、現在已經啟動服務了,且將其安裝到windows服務上了,這樣一來,就不用每次手動去啟動了,隨電腦而啟動。
現在來測試下,隨便新建個控制台應用程式


1 using Memcached.ClientLibrary; 2 using System; 3 using System.Collections.Generic; 4 using System.Linq; 5 using System.Text; 6 using System.Threading.Tasks; 7 8 namespace 測試 9 { 10 public class MemcacheTset 11 { 12 public static void Test() 13 { 14 string[] serverlist = { "127.0.0.1:11211" }; //伺服器列表,可多個 用逗號隔開 15 16 //初始化池 17 SockIOPool pool = SockIOPool.GetInstance(); 18 19 //根據實際情況修改下麵參數 20 pool.SetServers(serverlist); 21 pool.InitConnections = 3; 22 pool.MinConnections = 3; 23 pool.MaxConnections = 5; 24 pool.SocketConnectTimeout = 1000; 25 pool.SocketTimeout = 3000; 26 pool.MaintenanceSleep = 30; 27 pool.Failover = true; 28 pool.Nagle = false; 29 pool.Initialize(); // initialize the pool for memcache servers 30 31 //獲得客戶端實例 32 MemcachedClient mc = new MemcachedClient();//初始化一個客戶端 33 mc.EnableCompression = false; 34 35 Console.WriteLine("---------測試----------"); 36 mc.Set("test","my value");//存儲數據到緩存伺服器,這裡將字元串"my value"緩存,key 37 38 if (mc.KeyExists("test"))//測試緩存存在key為test的項目 39 { 40 Console.WriteLine("test is Exists"); 41 Console.WriteLine(mc.Get("test").ToString());//在緩存中獲取key為test的項目 42 } 43 else 44 { 45 Console.WriteLine("test not Exists"); 46 } 47 48 Console.ReadLine(); 49 50 mc.Delete("test");//移除緩存中key為test的項目 51 52 if (mc.KeyExists("test")) 53 { 54 Console.WriteLine("test is Exists"); 55 Console.WriteLine(mc.Get("test").ToString()); 56 } 57 else 58 { 59 Console.WriteLine("test not Exists"); 60 } 61 62 Console.ReadLine(); 63 64 SockIOPool.GetInstance().Shutdown();//關閉池,關閉sockets 65 } 66 } 67 }View Code
如果程式運行正常,說明我們的Memcache服務已啟動且運行正常。
有一點,別忘咯,就是我們Memcache的驅動,同樣,百度C# Memcache安裝就OK。
好了,現在我們就實際來應用下吧。
五、MencacheHelper.cs 示例使用 結合項目配置緩存
對於什麼是項目配置,相信大家肯定都熟悉的,就是將業務中不經常更改的數據如系統郵件地址,將其存在資料庫中,方便更改。
然後,回頭看這幾個字,“不經常更改”,我們就得註意了,這樣的數據,我們就得想到緩存了,緩存就是用來管理這樣的數據。然後呢,我們就可以使用我們的Memcache來管理它了。
項目中,我們可以新建個MemcacheHelper類來封裝下代碼,我寫了個最簡單的存取刪除。
1 using Memcached.ClientLibrary; 2 using System; 3 using System.Collections.Generic; 4 using System.Linq; 5 using System.Text; 6 using System.Threading.Tasks; 7 8 namespace JOEY.BookShop.Common 9 { 10 public class MemcacheHelper 11 { 12 private static readonly MemcachedClient mc; 13 static MemcacheHelper() 14 { 15 string[] serverlist = { "127.0.0.1:11211" }; //伺服器列表,可多個 用逗號隔開 16 17 //初始化池 18 SockIOPool pool = SockIOPool.GetInstance(); 19 20 //根據實際情況修改下麵參數 21 pool.SetServers(serverlist); 22 pool.InitConnections = 3; 23 pool.MinConnections = 3; 24 pool.MaxConnections = 5; 25 pool.SocketConnectTimeout = 1000; 26 pool.SocketTimeout = 3000; 27 pool.MaintenanceSleep = 30; 28 pool.Failover = true; 29 pool.Nagle = false; 30 pool.Initialize(); // initialize the pool for memcache servers 31 32 //獲得客戶端實例 33 mc = new MemcachedClient();//初始化一個客戶端 34 mc.EnableCompression = false; 35 } 36 37 /// <summary> 38 /// 存 39 /// </summary> 40 /// <param name="key"></param> 41 /// <param name="value"></param> 42 public static void Set(string key, object value) 43 { 44 mc.Set(key, value); 45 } 46 47 public static void Set(string key, object value, DateTime time) 48 { 49 mc.Set(key, value, time); 50 } 51 52 /// <summary> 53 /// 取 54 /// </summary> 55 /// <param name="key"></param> 56 /// <returns></returns> 57 public static object Get(string key) 58 { 59 if (mc.KeyExists(key)) 60 { 61 return mc.Get(key); 62 } 63 else 64 { 65 return null; 66 } 67 68 } 69 70 /// <summary> 71 /// 刪除 72 /// </summary> 73 /// <param name="key"></param> 74 /// <returns></returns> 75 public static bool Delete(string key) 76 { 77 if (mc.KeyExists(key)) 78 { 79 mc.Delete(key); 80 return true; 81 } 82 return false; 83 } 84 } 85 }View Code
1 var setting = this.DbSession.SettingsDal.LoadEntities(c => c.Name == "系統郵件地址").FirstOrDefault(); 2 string value = setting.Value.Trim(); 3 MemcacheHelper.Set("setting_" + key, value);
這樣就將我們的從資料庫中取出的系統郵件地址存儲到了Memcache中,很方便吧。取的話就是:
object obj = MemcacheHelper.Get("setting_" + "系統郵件地址");
這裡由於存取的數據均為字元串,不存在序列化的問題,如果存取的對象類型不是字元串,如某個表Model,那麼就得通過序列化來進行操作,對於序列化,本人是使用Json.Net來操作。
再來個輔助類吧。
1 using Newtonsoft.Json; 2 using System; 3 using System.Collections.Generic; 4 using System.Linq; 5 using System.Text; 6 using System.Threading.Tasks; 7 8 namespace JOEY.BookShop.Common 9 { 10 /// <summary> 11 /// Json.Net 序列化,對於由於相互引用類型導致的序列化死迴圈,可在該對象上加個特性標簽[JsonIgnore] 如在Model中有外鍵,兩個模型間相互引用即造成該問題 12 /// </summary> 13 public class SerializeHelper 14 { 15 /// <summary> 16 /// 傳入對象,序列化成字元串返回 17 /// </summary> 18 /// <param name="obj"></param> 19 /// <returns></returns> 20 public static string SerializeToString(object obj) 21 { 22 return JsonConvert.SerializeObject(obj); 23 } 24 /// <summary> 25 /// 傳入序列化字元串,反序列化成對應對象返回 26 /// </summary> 27 /// <typeparam name="T">泛型,對應對象類型</typeparam> 28 /// <param name="serializeStr">序列化後的字元串</param> 29 /// <returns></returns> 30 public static T DeserializeToObject<T>(string serializeStr) 31 { 32 return JsonConvert.DeserializeObject<T>(serializeStr); 33 } 34 } 35 }View Code
很容易就能看懂,對吧。當然驅動也是需要的。同樣百度哦。
這裡有個小問題,這個程式集,Newtonsoft.Json在我的MVC項目中本身就存在,而我在其他項目(即項目Common)中用的時候用的網上下的,選的版本是4.5,由於MVC項目引用了Common,這樣貌似就出現了版本不一致的情況,貌似是這樣,會提示錯誤。於是我把MVC中的dll給刪除了,重新載入Common下的dll(現在想想我為什麼不把Common下的刪了,去引用MVC下這個呢- -),這樣一來,又出現一個問題,未能載入文件或程式集“Newtonsoft.Json,Version=4.5.0.0。估計是配置項的原因,於是,百度了下,在web.config runtime節點下添加了這麼幾行,修改後為:
<dependentAssembly>
<assemblyIdentity name="Newtonsoft.Json" publicKeyToken="30ad4fe6b2a6aeed" culture="neutral" />
<bindingRedirect oldVersion="0.0.0.0-8.0.0.0" newVersion="8.0.0.0" />
</dependentAssembly>
8.0.0.0是當前這個dll的版本,估計是版本更新通知吧。具體為何這樣做是有點迷糊的。誰能指點下呢,感激~~~
六、Redis和Memcache的區別總結(摘自百度知道)
1. Redis是什麼
這個問題的結果影響了我們怎麼用Redis。如果你認為Redis是一個key value store, 那可能會用它來代替MySQL;如果認為它是一個可以持久化的cache, 可能只是它保存一些頻繁訪問的臨時數據。Redis是REmote DIctionary Server的縮寫,在Redis在官方網站的的副標題是A persistent key-value database with built-in net interface written in ANSI-C for Posix systems,這個定義偏向key value store。還有一些看法則認為Redis是一個memory database,因為它的高性能都是基於記憶體操作的基礎。另外一些人則認為Redis是一個data structure server,因為Redis支持複雜的數據特性,比如List, Set等。對Redis的作用的不同解讀決定了你對Redis的使用方式。
互聯網數據目前基本使用兩種方式來存儲,關係資料庫或者key value。但是這些互聯網業務本身並不屬於這兩種數據類型,比如用戶在社會化平臺中的關係,它是一個list,如果要用關係資料庫存儲就需要轉換成一種多行記錄的形式,這種形式存在很多冗餘數據,每一行需要存儲一些重覆信息。如果用key value存儲則修改和刪除比較麻煩,需要將全部數據讀出再寫入。Redis在記憶體中設計了各種數據類型,讓業務能夠高速原子的訪問這些數據結構,並且不需要關心持久存儲的問題,從架構上解決了前面兩種存儲需要走一些彎路的問題。
2. Redis不可能比Memcache快
很多開發者都認為Redis不可能比Memcached快,Memcached完全基於記憶體,而Redis具有持久化保存特性,即使是非同步的,Redis也不可能比Memcached快。但是測試結果基本是Redis占絕對優勢。一直在思考這個原因,目前想到的原因有這幾方面。
Libevent。和Memcached不同,Redis並沒有選擇libevent。Libevent為了迎合通用性造成代碼龐大(目前Redis代碼還不到libevent的1/3)及犧牲了在特定平臺的不少性能。Redis用libevent中兩個文件修改實現了自己的epoll event loop(4)。業界不少開發者也建議Redis使用另外一個libevent高性能替代libev,但是作者還是堅持Redis應該小巧並去依賴的思路。一個印象深刻的細節是編譯Redis之前並不需要執行./configure。
CAS問題。CAS是Memcached中比較方便的一種防止競爭修改資源的方法。CAS實現需要為每個cache key設置一個隱藏的cas token,cas相當value版本號,每次set會token需要遞增,因此帶來CPU和記憶體的雙重開銷,雖然這些開銷很小,但是到單機10G+ cache以及QPS上萬之後這些開銷就會給雙方相對帶來一些細微性能差別(5)。
3. 單台Redis的存放數據必須比物理記憶體小
Redis的數據全部放在記憶體帶來了高速的性能,但是也帶來一些不合理之處。比如一個中型網站有100萬註冊用戶,如果這些資料要用Redis來存儲,記憶體的容量必須能夠容納這100萬用戶。但是業務實際情況是100萬用戶只有5萬活躍用戶,1周來訪問過1次的也只有15萬用戶,因此全部100萬用戶的數據都放在記憶體有不合理之處,RAM需要為冷數據買單。
這跟操作系統非常相似,操作系統所有應用訪問的數據都在記憶體,但是如果物理記憶體容納不下新的數據,操作系統會智能將部分長期沒有訪問的數據交換到磁碟,為新的應用留出空間。現代操作系統給應用提供的並不是物理記憶體,而是虛擬記憶體(Virtual Memory)的概念。
基於相同的考慮,Redis 2.0也增加了VM特性。讓Redis數據容量突破了物理記憶體的限制。並實現了數據冷熱分離。
4. Redis的VM實現是重覆造輪子
Redis的VM依照之前的epoll實現思路依舊是自己實現。但是在前面操作系統的介紹提到OS也可以自動幫程式實現冷熱數據分離,Redis只需要OS申請一塊大記憶體,OS會自動將熱數據放入物理記憶體,冷數據交換到硬碟,另外一個知名的“理解了現代操作系統(3)”的Varnish就是這樣實現,也取得了非常成功的效果。
作者antirez在解釋為什麼要自己實現VM中提到幾個原因(6)。主要OS的VM換入換出是基於Page概念,比如OS VM1個Page是4K, 4K中只要還有一個元素即使只有1個位元組被訪問,這個頁也不會被SWAP, 換入也同樣道理,讀到一個位元組可能會換入4K無用的記憶體。而Redis自己實現則可以達到控制換入的粒度。另外訪問操作系統SWAP記憶體區域時block進程,也是導致Redis要自己實現VM原因之一。
5. 用get/set方式使用Redis
作為一個key value存在,很多開發者自然的使用set/get方式來使用Redis,實際上這並不是最優化的使用方法。尤其在未啟用VM情況下,Redis全部數據需要放入記憶體,節約記憶體尤其重要。
假如一個key-value單元需要最小占用512位元組,即使只存一個位元組也占了512位元組。這時候就有一個設計模式,可以把key復用,幾個key-value放入一個key中,value再作為一個set存入,這樣同樣512位元組就會存放10-100倍的容量。
這就是為了節約記憶體,建議使用hashset而不是set/get的方式來使用Redis,詳細方法見參考文獻(7)。
6. 使用aof代替snapshot
Redis有兩種存儲方式,預設是snapshot方式,實現方法是定時將記憶體的快照(snapshot)持久化到硬碟,這種方法缺點是持久化之後如果出現crash則會丟失一段數據。因此在完美主義者的推動下作者增加了aof方式。aof即append only mode,在寫入記憶體數據的同時將操作命令保存到日誌文件,在一個併發更改上萬的系統中,命令日誌是一個非常龐大的數據,管理維護成本非常高,恢復重建時間會非常長,這樣導致失去aof高可用性本意。另外更重要的是Redis是一個記憶體數據結構模型,所有的優勢都是建立在對記憶體複雜數據結構高效的原子操作上,這樣就看出aof是一個非常不協調的部分。
其實aof目的主要是數據可靠性及高可用性,在Redis中有另外一種方法來達到目的:Replication。由於Redis的高性能,複製基本沒有延遲。這樣達到了防止單點故障及實現了高可用。
小結
要想成功使用一種產品,我們需要深入瞭解它的特性。Redis性能突出,如果能夠熟練的駕馭,對國內很多大型應用具有很大幫助。


