
XML 使用DTD(document type definition)文檔類型來標記數據和定義數據,格式統一且跨平臺和語言,已成為業界公認的標準。 目前 XML 描述數據龍頭老大的地位漸漸受到 Json 威脅。經手項目中,模塊/系統之間交互數據方式有 XML 也有 Json,說不上孰好孰壞。 XML ...
XML 使用DTD(document type definition)文檔類型來標記數據和定義數據,格式統一且跨平臺和語言,已成為業界公認的標準。
目前 XML 描述數據龍頭老大的地位漸漸受到 Json 威脅。經手項目中,模塊/系統之間交互數據方式有 XML 也有 Json,說不上孰好孰壞。
XML 規整/有業界標準/很容易和其他外部的系統進行交互,Json 簡單/靈活/占帶寬比小。
仁者見仁智者見智,項目推進中描述數據方式需要根據具體場景拿捏。
這篇博客主要描述目前 Java 中比較主流的 XML 解析底層方式,給需要這方面項目實踐的同學一些參考。
Demo 項目 git 地址:https://git.oschina.net/LanboEx/xml-parse-demo.git
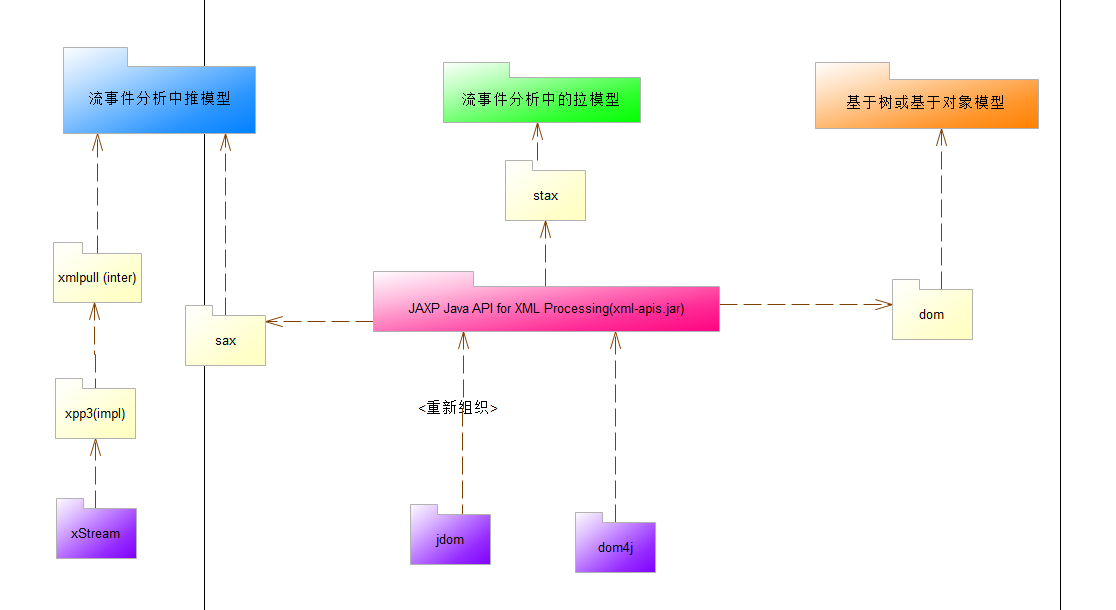
sax/satx/dom 由國外開源社區或組織貢獻,Sun 重新組織起名 JAXP 自JDK 1.6 起陸續將他們添加進去。
xmlpull 在 JDK 中沒有看到它的身影,如果需要使用它,你需要添加額外的類庫。
jdom/dom4j/xstream... 是基於這些底層解析方式重新組織封裝的開源類庫,提供簡介的 API,有機會再寫一篇博客描述。
dom4j 是基於 JAXP 解析方式,性能優異、功能強大、極易使用的優秀開源類庫。
jdom 如果你細看內部代碼,其實也是基於 JAXP 但具體包結構被重新組織, API 大量使用了 Collections 類,在性能上被 dm4j 壓了好幾個檔次。
實例 Demo 中需要解析的 xml 文件如下,中規中矩不簡單,也不複雜,示例業務場景都能將節點的值解析出來,組成業務實體對象。


<?xml version="1.0"?>
<classGrid>
<classGridlb>
<class_id>320170105000009363</class_id>
<class_number>0301</class_number>
<adviser>018574</adviser>
<studentGrid>
<studentGridlb>
<stu_id>030101</stu_id>
<stu_name>齊天</stu_name>
<stu_age>9</stu_age>
<stu_birthday>2008-11-07</stu_birthday>
</studentGridlb>
<studentGridlb>
<stu_id>030102</stu_id>
<stu_name>張惠</stu_name>
<stu_age>10</stu_age>
<stu_birthday>2009-04-08</stu_birthday>
</studentGridlb>
<studentGridlb>
<stu_id>030103</stu_id>
<stu_name>龍五</stu_name>
<stu_age>9</stu_age>
<stu_birthday>2008-11-01</stu_birthday>
</studentGridlb>
</studentGrid>
</classGridlb>
<classGridlb>
<class_id>420170105000007363</class_id>
<class_number>0302</class_number>
<adviser>018577</adviser>
<studentGrid>
<studentGridlb>
<stu_id>030201</stu_id>
<stu_name>馬寶</stu_name>
<stu_age>10</stu_age>
<stu_birthday>2009-09-02</stu_birthday>
</studentGridlb>
</studentGrid>
</classGridlb>
</classGrid>
Demo.xml
1. 基於樹或基於對象模型
官方 W3C 標準,以層次結構組織的節點或信息片斷的集合。允許在樹中尋找特定信息,分析該結構通常需要載入整個文檔和構造層次結構。
最早的一種解析模型,載入整個文檔意味著在大文件 XMl 會遇到性能瓶頸。
dom 解析代碼示例:
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();//得到DOM解析器的工廠實例
DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();//從DOM工廠中獲得DOM解析器
Document doc = dbBuilder.parse(Thread.currentThread().getContextClassLoader().getResource("demo.xml").getPath());
NodeList nList = doc.getElementsByTagName("studentGridlb");
List<StudentGridlb> studentGridlbList = new ArrayList<>();
for (int i = 0; i < nList.getLength(); i++) {
StudentGridlb studentGridlb = new StudentGridlb();
NodeList childNodes = nList.item(i).getChildNodes();
for (int k = 0; k < childNodes.getLength(); k++) {
if (childNodes.item(k) instanceof Element) {
Element element = (Element) childNodes.item(k);
if ("stu_id".equals(element.getNodeName())) {
studentGridlb.setStu_id(element.getTextContent());
}
if ("stu_name".equals(element.getNodeName())) {
studentGridlb.setStu_name(element.getTextContent());
}
if ("stu_age".equals(element.getNodeName())) {
studentGridlb.setStu_age(Integer.parseInt(element.getTextContent()));
}
if ("stu_birthday".equals(element.getNodeName())) {
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
studentGridlb.setStu_birthday(format.parse(element.getTextContent()));
}
}
}
studentGridlbList.add(studentGridlb);
}
dom 解析方式有個最大的優點可以在任何時候在樹中上下導航,獲取和操作任意部分的數據。
2. 流事件分析中推模型
靠事件驅動的模型,當它每發現一個節點就引發一個事件,需要編寫這些事件的處理程式。
這樣的做法很麻煩,而且不靈活,主流的分析方式有 xmlpull 和 JAXP 中的 sax。
xmlpull demo (引入 xmlpull.jar xpp3_min.jar]):
XmlPullParserFactory pullParserFactory = XmlPullParserFactory.newInstance();
XmlPullParser pullParser = pullParserFactory.newPullParser();//獲取XmlPullParser的實例
pullParser.setInput(Thread.currentThread().getContextClassLoader().getResourceAsStream("demo.xml"), "UTF-8");
int event = pullParser.getEventType();
List<StudentGridlb> studentGridlbList = new ArrayList<>();
StudentGridlb studentGridlb = new StudentGridlb();
while (event != XmlPullParser.END_DOCUMENT) {
String nodeName = pullParser.getName();
switch (event) {
case XmlPullParser.START_DOCUMENT:
System.out.println("xmlpull 解析 xml 開始:");
break;
case XmlPullParser.START_TAG:
if ("stu_id".equals(nodeName)) {
studentGridlb.setStu_id(pullParser.nextText());
}
if ("stu_name".equals(nodeName)) {
studentGridlb.setStu_name(pullParser.nextText());
}
if ("stu_age".equals(nodeName)) {
studentGridlb.setStu_age(Integer.parseInt(pullParser.nextText()));
}
if ("stu_birthday".equals(nodeName)) {
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
studentGridlb.setStu_birthday(format.parse(pullParser.nextText()));
}
break;
case XmlPullParser.END_TAG:
if ("studentGridlb".equals(nodeName)) {
studentGridlbList.add(studentGridlb);
studentGridlb = new StudentGridlb();
}
break;
}
event = pullParser.next();
}
xmlpull 為介面層,xpp3_min 為實現層,其實可以引入另外自帶介面層 xpp3 版本。
<dependency>
<groupId>xmlpull</groupId>
<artifactId>xmlpull</artifactId>
<version>1.1.3.1</version>
</dependency>
<dependency>
<groupId>xpp3</groupId>
<artifactId>xpp3_min</artifactId>
<version>1.1.4c</version>
</dependency>
sax demo:
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance(); //獲取SAX分析器的工廠實例,專門負責創建SAXParser分析器
SAXParser saxParser = saxParserFactory.newSAXParser();
InputStream inputStream = new FileInputStream(new File(Thread.currentThread().getContextClassLoader().getResource("demo.xml").getPath()));
SAXHandler xmlSAXHandler = new SAXHandler();
saxParser.parse(inputStream, xmlSAXHandler);
sax 解析時還需要單獨編寫時間響應 Handler ,和集合排序時實現的Comparator 類似。
public class SAXHandler extends DefaultHandler {
private List<StudentGridlb> studentGridlbList = null;
private StudentGridlb studentGridlb = null;
private String tagName;
@Override
public void startDocument() throws SAXException {
System.out.println("---->startDocument() is invoked...");
studentGridlbList = new ArrayList<>();
}
@Override
public void endDocument() throws SAXException {
System.out.println("---->endDocument() is invoked...");
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println("-------->startElement() is invoked...,qName:" + qName);
if ("studentGridlb".equals(qName)) {
this.studentGridlb = new StudentGridlb();
}
this.tagName = qName;
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("-------->endElement() is invoked...");
if (qName.equals("studentGridlb")) {
this.studentGridlbList.add(this.studentGridlb);
}
this.tagName = null;
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.println("------------>characters() is invoked...");
if (this.tagName != null) {
String contentText = new String(ch, start, length);
if (this.tagName.equals("stu_id")) {
this.studentGridlb.setStu_id(contentText);
}
if (this.tagName.equals("stu_name")) {
this.studentGridlb.setStu_name(contentText);
}
if (this.tagName.equals("stu_age")) {
this.studentGridlb.setStu_age(Integer.parseInt(contentText));
}
if (this.tagName.equals("stu_birthday")) {
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
try {
this.studentGridlb.setStu_birthday(format.parse(contentText));
} catch (ParseException e) {
e.printStackTrace();
}
}
}
}
public List<StudentGridlb> getStudentGridlbList() {
return studentGridlbList;
}
public void setStudentGridlbList(List<StudentGridlb> studentGridlbList) {
this.studentGridlbList = studentGridlbList;
}
}
SAXHandler
推模式不需要等待所有數據都被處理,分析就能立即開始;
只在讀取數據時檢查數據,不需要保存在記憶體中;
可以在某個條件得到滿足時停止解析,不必解析整個文檔;
效率和性能較高,能解析大於系統記憶體的文檔;
當然缺點也很突出例如需要自己負責TAG的處理邏輯(例如維護父/子關係等),使用麻煩;
單嚮導航,很難同時訪問同一文檔的不同部分數據,不支持 XPath;
3. 流事件分析中的拉模型
在遍歷文檔時,把感興趣的部分從讀取器中拉出,不需要引發事件,允許我們選擇性地處理節點;
大大提高了靈活性,以及整體效率,拉模式中比較常見 stax,stax 提供了兩套 API 共使用。
stax demo(基於游標的方式解析XML):
InputStream stream = new FileInputStream(Thread.currentThread().getContextClassLoader().getResource("demo.xml").getPath());
XMLInputFactory factory = XMLInputFactory.newInstance();
XMLStreamReader parser = factory.createXMLStreamReader(stream);
List<StudentGridlb> studentGridlbList = new ArrayList<>();
StudentGridlb studentGridlb = null;
while (parser.hasNext()) {
int event = parser.next();
if (event == XMLStreamConstants.START_DOCUMENT) {
System.out.println("stax 解析xml 開始.....");
}
if (event == XMLStreamConstants.START_ELEMENT) {
if (parser.getLocalName().equals("stu_id")) {
studentGridlb = new StudentGridlb();
studentGridlb.setStu_id(parser.getElementText());
} else if (parser.getLocalName().equals("stu_name")) {
studentGridlb.setStu_name(parser.getElementText());
} else if (parser.getLocalName().equals("stu_age")) {
studentGridlb.setStu_age(Integer.parseInt(parser.getElementText()));
} else if (parser.getLocalName().equals("stu_birthday")) {
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
studentGridlb.setStu_birthday(format.parse(parser.getElementText()));
}
}
if (event == XMLStreamConstants.END_ELEMENT) {
if (parser.getLocalName().equals("studentGridlb")) {
studentGridlbList.add(studentGridlb);
}
}
if (event == XMLStreamConstants.END_DOCUMENT) {
System.out.println("stax 解析xml 結束.....");
}
}
parser.close();
stax demo(基於迭代方式解析XML):
XMLInputFactory xmlInputFactory = XMLInputFactory.newInstance();
XMLEventReader xmlEventReader = xmlInputFactory.createXMLEventReader(Thread.currentThread().getContextClassLoader().getResourceAsStream("demo.xml"));
List<StudentGridlb> studentGridlbList = new ArrayList<>();
StudentGridlb studentGridlb = null;
while (xmlEventReader.hasNext()) {
XMLEvent event = xmlEventReader.nextEvent();
if (event.isStartElement()) {
String name = event.asStartElement().getName().toString();
if (name.equals("stu_id")) {
studentGridlb = new StudentGridlb();
studentGridlb.setStu_id(xmlEventReader.getElementText());
} else if (name.equals("stu_name")) {
studentGridlb.setStu_name(xmlEventReader.getElementText());
} else if (name.equals("stu_age")) {
studentGridlb.setStu_age(Integer.parseInt(xmlEventReader.getElementText()));
} else if (name.equals("stu_birthday")) {
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
studentGridlb.setStu_birthday(format.parse(xmlEventReader.getElementText()));
}
}
if (event.isEndElement()) {
String name = event.asEndElement().getName().toString();
if (name.equals("studentGridlb")) {
studentGridlbList.add(studentGridlb);
}
}
}
xmlEventReader.close();
基於指針的 stax API,這種方式儘管效率高,但沒有提供 XML 結構的抽象,因此是一種低層 API。
stax 基於迭代器的 API 是一種面向對象的方式,這也是它與基於指針的 API 的最大區別。
基於迭代器的 API 只需要確定解析事件的類型,然後利用其方法獲得屬於該事件對象的信息。
通過將事件轉變為對象,讓應用程式可以用面向對象的方式處理,有利於模塊化和不同組件之間的代碼重用。
Ok,這篇博客對 java 底層解析 xml 方式做了點總結。其實在實際項目中,上述幾種方式解析 xml 編寫起來都很費事。
都會引入封裝起來的穩定開源庫,如 dom4j/jdom/xstream.....,這些類庫屏蔽了底層複雜的部分,呈現給我們簡潔明瞭的 API;
但如果公司業務複雜程度已經遠遠超出了開源類庫的提供的範疇,不妨自己依賴底層解析技術自己造輪子。

