
離開博客園很久了,自從找到工作,到現在基本沒有再寫過博客了。在大學培養起來的寫博客的習慣在慢慢的消失殆盡,感覺汗顏。所以現在要開始重新培養起這個習慣,定期寫博客不僅是對自己學習知識的一種沉澱,更是在督促自己要不斷的學習,不斷的進步。 最近在進一步學習Java併發編程,不言而喻,這部分內容是很重要的。 ...
離開博客園很久了,自從找到工作,到現在基本沒有再寫過博客了。在大學培養起來的寫博客的習慣在慢慢的消失殆盡,感覺汗顏。所以現在要開始重新培養起這個習慣,定期寫博客不僅是對自己學習知識的一種沉澱,更是在督促自己要不斷的學習,不斷的進步。
最近在進一步學習Java併發編程,不言而喻,這部分內容是很重要的。現在就以《併發編程的藝術》一書為主導線,開始新一輪的學習。
進程和線程
進程是一個應用程式在處理機上的一次執行過程,線程是進程的最小基本單位(個人理解)。一個進程可以包含多個線程。
上下文切換
我們都知道,即使是單核處理器也支持多線程,CPU通過時間片分配演算法來給每個線程分配時間讓線程得以執行,因為時間片非常短,所以在用戶角度來講,會感覺多個線程是在同時執行。那什麼是上下文切換呢?舉個例子,當線程A執行到某一步時,此時CPU將時間讓給了線程B進行執行,那麼在進行切換的時候,系統一定要保存此時此刻線程A所執行任務的狀態,比如執行到哪裡、運行時的參數等,那麼當下一次CPU將時間讓給線程A進行執行時,才能正確的切換到A,並繼續執行下去。所以任務從保存到再載入的過程就是一次上下文切換。
雖然上下文切換可以讓我們覺得可以“同時”做很多事,但是上下文切換也是需要系統開銷的。在《Java併發編程的藝術》中,作者舉例演示了串列和併發執行累加操作,在結果中可以看得出,累加操作不同的次數會對不同的結果,所消耗的時間也有差別的。如果累加操作的次數沒有超過百萬次,那麼串列執行結果消耗的時間會比並行執行的時間要少。所以在有些情況下我們需要儘可能的減少上下文切換的次數,使用的方法有:無鎖併發編程,CAS演算法,使用最少線程和使用協程。(這裡筆者也只知道有這幾種方法,至於具體如何使用以及在何種場景下使用還未深入研究)。
volatile與synchronized
volatile
volatile是輕量級的synchronized,它保證了在多處理器開發中,共用變數的可見性,並且volatile不會引起上下文切換和調度。可見性的意思是當一個線程修改了某個變數的值,另外一個線程可以讀到這個變數修改後的值,如果一個變數被volatile修飾,那麼Java記憶體模型確保所有線程看到這個變數的值是一致的。
synchronized
Java中每一個對象都可以作為鎖,具體表現為:
- 對於普通的同步方法,鎖是當前實例對象
- 對於靜態的同步方法,鎖是當前類的Class對象
- 對於同步方法塊,鎖是synchronized括弧里配置的對象
當一個線程訪問同步代碼塊時,必須要先得到鎖,退出或拋出異常時,必須釋放鎖。對於上述三種情況,表現形式為:
1 /** 2 * 普通同步方法,鎖是當前實例對象 3 */ 4 public synchronized void test1(){ 5 //TODO something 6 } 7 8 /** 9 * 靜態同步方法,鎖是當前類的Class對象 10 */ 11 public static synchronized void test2(){ 12 //TODO something 13 } 14 15 /** 16 * 同步方法塊,鎖是synchronized括弧中的對象,這裡是a 17 */ 18 public void test3(Integer a){ 19 synchronized (a){ 20 //TODO something 21 } 22 }
Java記憶體模型
Java中所有實例域、靜態域和數組元素都存儲在堆記憶體中,堆記憶體線上程之間共用。
Java線程之間的通信由Java記憶體模型(JMM)控制。JMM定義了線程和主記憶體的關係:線程之前的共用變數存儲在主記憶體中,每個線程都有一個私有的本地記憶體(也叫工作記憶體),本地記憶體中存儲了該線程讀寫共用變數的副本。本地記憶體是JMM的抽象概念,不真實存在,包涵了緩存,寫緩衝區,寄存器以及其他硬體和編譯器優化。Java記憶體模型結構圖: 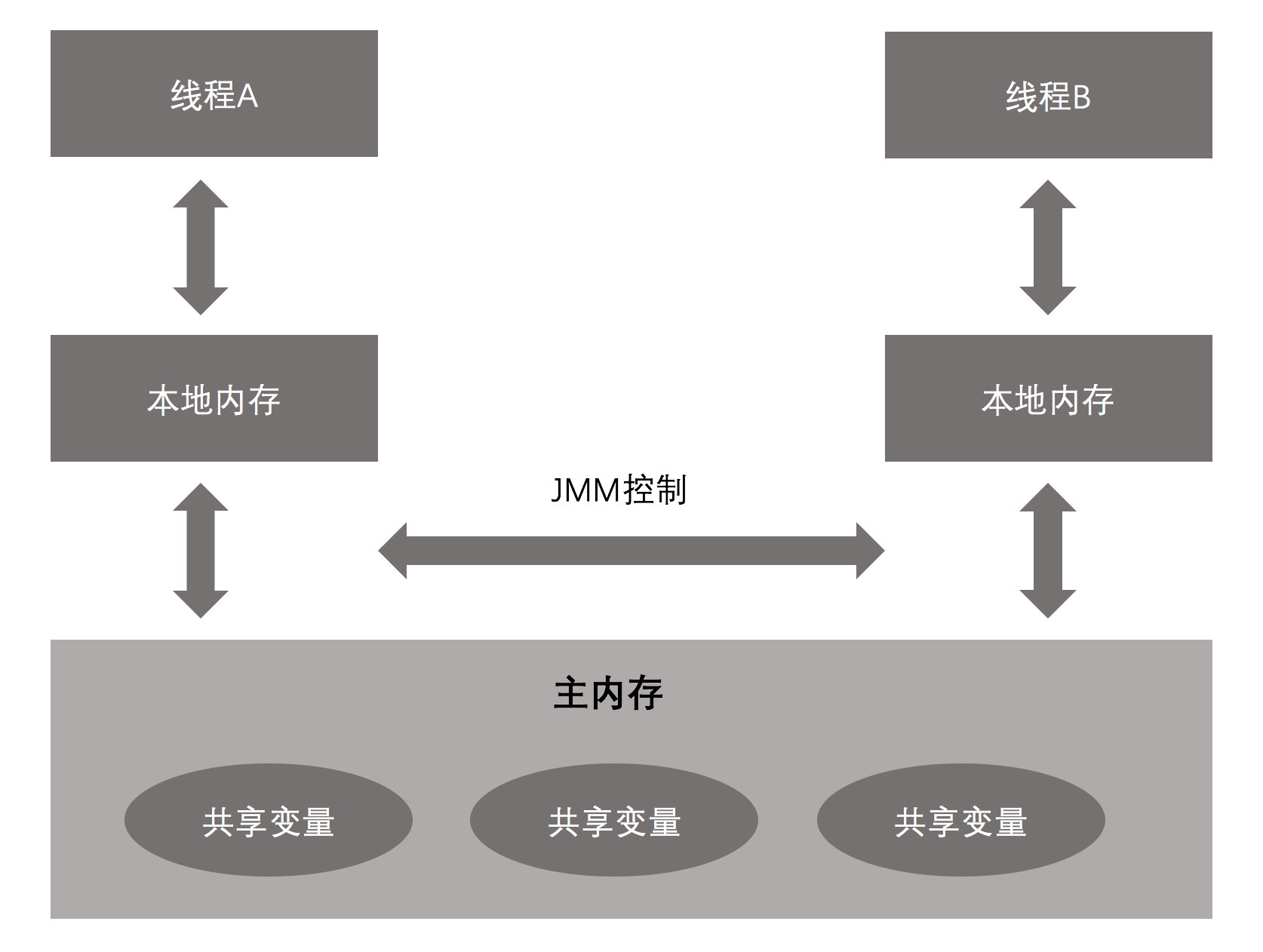
從上圖可以看出,線程A要與線程B進行通信的話,必須要經過兩個步驟:
- 線程A把本地記憶體A中更新過的共用變數刷新要主記憶體中去,
- 線程B到主記憶體中獲取更新之後的共用變數。
如下圖:
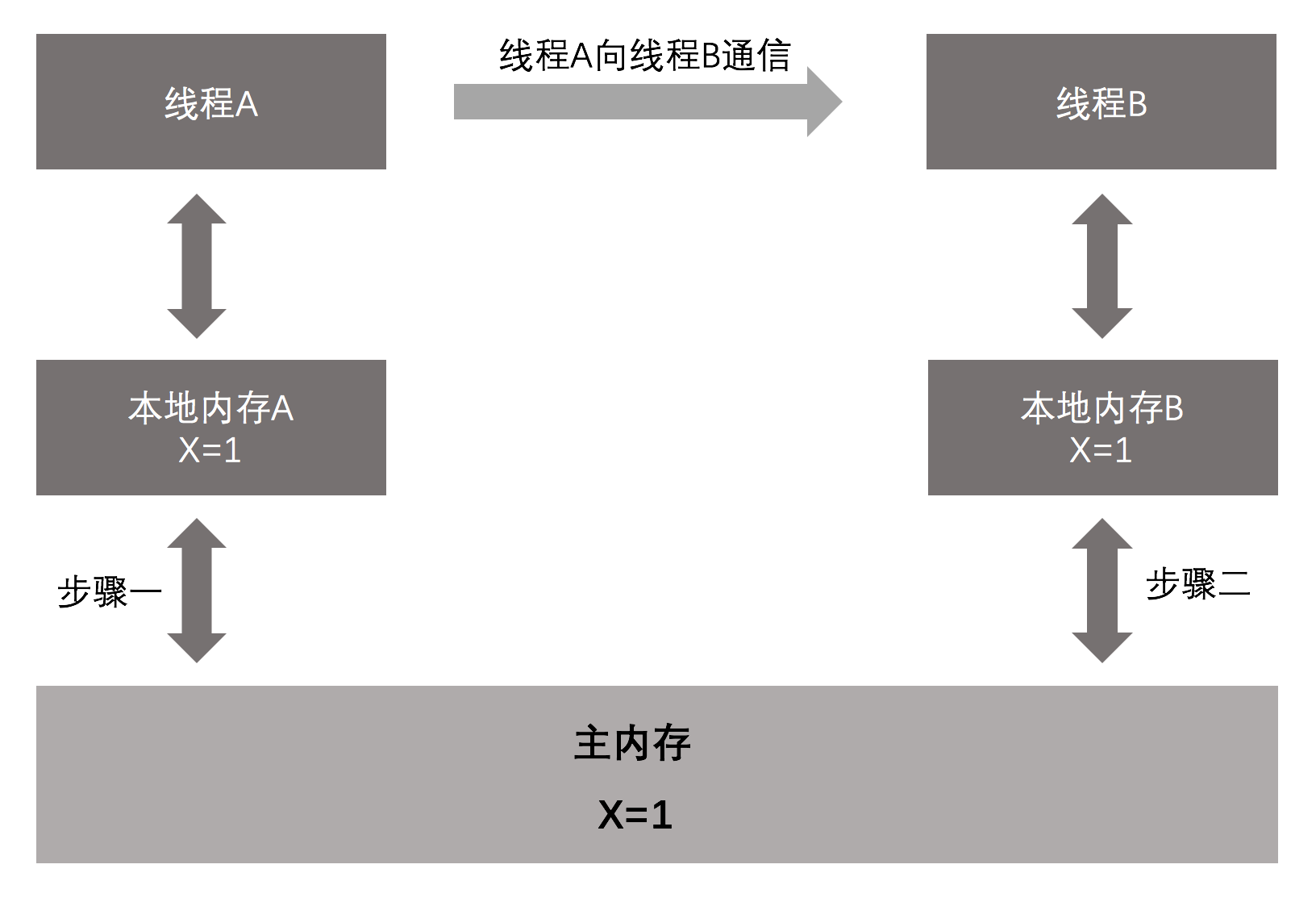
重排序
重排序是指編譯器和處理器為了優化程式性能而對指令序列進行重新排序的一種手段。
數據依賴性
定義:如果兩個操作同時訪問一個變數,且這兩個操作中有一個為寫操作。此時這兩個操作之間就存在數據依賴性。
編譯器和處理器在重排序時,會遵守數據依賴性,編譯器和處理器不會改變存在數據依賴關係的兩個操作的執行順序。
as-if-serial語義
語義:不管怎麼重排序,單線程程式的執行結果不能被改變。編譯器,runtime和處理器都必須遵守as-if-serial語義。
為了遵守as-if-serial語義,編譯器和處理器不會對存在數據依賴關係的操作進行重排序,但是如果操作之間不存在數據依賴關係,那麼就有可能被進行重排序。例如:
1 double pi = 3.14 ; //A 2 double r = 1.0 ; //B 3 double area = pi * r *r ; //C
上面代碼中,C依賴A,C依賴B,所以編譯器不會重排序將C排在A,B之前。但是A,B之間沒有依賴,所以可能被進行重排序,最終的執行順序有兩種:
A->B->C;
B->A->C;
這兩種執行順序對最終結果不會造成影響。
因為存在重排序,所以單線程程式不一定按照程式的順序來執行。
該文主要講述了一些偏概念的東西,先有一些印象,後續會以代碼示例的形式進行全面的複習。

