
一、特點 • 可通過 DBMS_DATAPUMP 調用 • 可提供以下工具: – expdp – impdp – 基於 Web 的界面 • 提供四種數據移動方法: – 數據文件複製 – 直接路徑 – 外部表 – 網路鏈接支持e • 可與長時間運行的作業分離後再重新掛接 • 可重新啟動數據泵作業 DB... ...
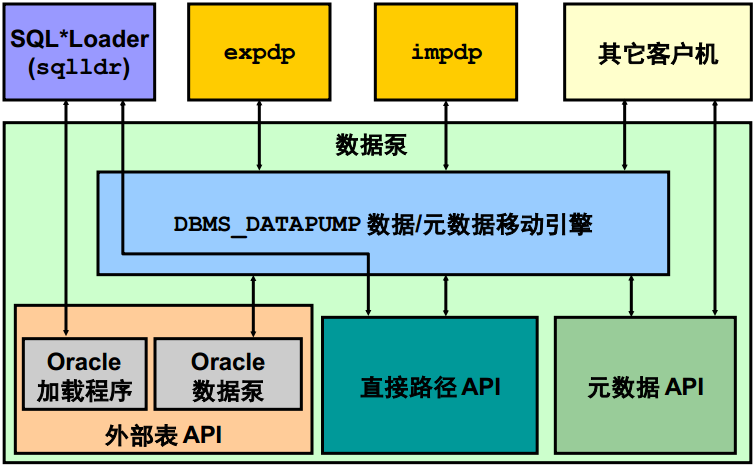
一、特點
• 可通過 DBMS_DATAPUMP 調用
• 可提供以下工具:
– expdp
– impdp
– 基於 Web 的界面
• 提供四種數據移動方法:
– 數據文件複製
– 直接路徑
– 外部表
– 網路鏈接支持e
• 可與長時間運行的作業分離後再重新掛接
• 可重新啟動數據泵作業
DBMS_DATAPUMP 調用示例
declare
h1 NUMBER;
begin
h1 := dbms_datapump.open (operation => 'EXPORT', job_mode => 'SCHEMA', job_name => 'EXPORT000083', version => 'COMPATIBLE');
dbms_datapump.set_parallel(handle => h1, degree => 1);
dbms_datapump.add_file(handle => h1, filename => 'EXPDAT.LOG', directory => 'DUMP_DIR', filetype => 3);
dbms_datapump.set_parameter(handle => h1, name => 'KEEP_MASTER', value => 0);
dbms_datapump.metadata_filter(handle => h1, name => 'SCHEMA_EXPR', value => 'IN(''HR'')');
dbms_datapump.add_file(handle => h1, filename => 'EXPDAT_HR%U.DMP', directory => 'DUMP_DIR', filesize => '10M', filetype => 1);
dbms_datapump.set_parameter(handle => h1, name => 'INCLUDE_METADATA', value => 1);
dbms_datapump.set_parameter(handle => h1, name => 'DATA_ACCESS_METHOD', value => 'AUTOMATIC');
dbms_datapump.set_parameter(handle => h1, name => 'ESTIMATE', value => 'BLOCKS');
dbms_datapump.start_job(handle => h1, skip_current => 0, abort_step => 0);
dbms_datapump.detach(handle => h1);
end;
/
二、優點
與早期的數據移動工具相比,數據泵具有許多優點並提供了一些新的功能,如:
• 細粒度級的對象和數據選擇(EXCLUDE/INCLUDE/CONTENT)
• 顯式指定資料庫版本(VERSION)
• 並行執行 (PARALLEL)
• 估計導出作業占用的空間(ESTIMATE_ONLY)
• 在分散式環境中支持網路模式(NETWORK_LINK)
• 重新映射功能(REMAP_TABLE/REMAP_SCHEMA)
• 在數據泵導出期間壓縮數據 (COMPRESSION),大概是6分之一。
• 通過加密增強安全性(ENCRYPTION/ENCRYPTION_ALGORITHM)
• 能夠將 XMLType 數據作為 CLOB 導出
• 在舊模式下支持舊的導入和導出文件
三、目錄對象
1、什麼目錄
• 目錄對象是一些代表伺服器文件系統上的物理目錄的邏輯結構
• 這些對象包含了特定操作系統目錄的位置
• 目錄對象由 SYS 用戶擁有
• 目錄名在資料庫中是唯一的,因為所有目錄都位於一個名稱空間(即SYS)中
• 為數據泵指定文件位置時,需要用到目錄對象。這是因為數據泵訪問的文件在伺服器上,而不是在客戶機上。
2、創建目錄
create directory dump_dir as '/home/oracle';
grant read on directory dump_dir to hr;
grant write on directory dump_dir to hr;
select * from dba_directories;
四、數據泵導出與導入界面:
– 命令行
– 參數文件
– 互動式命令行
– Enterprise Manager
• 數據泵導出與導入模式:
– 全部
– 方案
– 表
– 表空間
– 可移動表空間
數據泵導入的轉換:
• 使用 REMAP_DATAFILE 重新映射數據文件
• 使用 REMAP_TABLESPACE 重新映射表空間
• 使用 REMAP_SCHEMA 重新映射方案
• 使用 REMAP_TABLE 重新映射表
• 使用 REMAP_DATA 重新映射數據
監視數據泵作業
SELECT * FROM V$DATAPUMP_JOB
出現以下情況時,為預設位置(與是否在舊模式下無關):
— 命令行中不包含 DIRECTORY 參數
— 用戶不具備 EXP_FULL_DATABASE 許可權
五、EXPDP、IMPDP與EXP、IMP的區別
1、EXPDP、IMPDP導出導入的文件只能放在服務端硬碟上,EXP、IMP可以服務端,也可以客戶端。
2、EXPDP、IMPDP兩者配對使用,EXP、IMP兩者配對使用,無法交叉。
3、EXPDP、IMPDP支持導出表、導出方案、導出表空間、導出資料庫4中模式,EXP、IMP只支持導出表、導出方案、導出資料庫3種模式。
4、EXPD/IMPDP使用前需要建DIRECTORY用來存放dmp文件,而EXP/IMP不需要。
grant create any directory to system;
CREATE DIRECTORY dump_dir AS ‘c:\emp’;
GRANT READ, WRITE ON DIRECTORY dump_dir TO scott;
在備份期間,會自動的生成一張與Job_name 相同名稱的表, 該表在備份期間保存metadata數據。 當備份技術後,自動刪除該表。
我們可以使用SQL:
SQL>select * FROM dba_datapump_jobs
查看Job 的信息。如果意外情況導致備份Job失敗,那麼對應保存metadata的表,還是會存在。
這個時候,如果查詢dba_datapump_jobs,會顯示該Job為not running。 這時候,我們只需要drop 掉對應的表,隊友的表名就是job_name
在查詢dba_datapump_jobs。就沒有記錄了。 這個也是一種處理方法。
在開始我就說了,這裡沒有指定Job name。 所以系統自動給我們生成了一個:SYS_EXPORT_FULL_02。
預設是從SYS_EXPORT_FULL_01開始,因為我之前有一個沒有運行的Job,所以這裡從2開始了。
六、EXPDP和IMPDP的語法
1、EXPDP
expdp help=y
格式: expdp KEYWORD=value 或 KEYWORD=(value1,value2,...,valueN)
示例: expdp scott/tiger DUMPFILE=scott.dmp DIRECTORY=dmpdir SCHEMAS=scott
或 TABLES=(T1:P1,T1:P2)
關鍵字 說明 (預設)
------------------------------------------------------------------------------
ATTACH 連接到現有作業, 例如 ATTACH [=作業名]。
COMPRESSION 減小有效的轉儲文件內容的大小關鍵字值為: (METADATA_ONLY) 和 NONE。
CONTENT 指定要卸載的數據, 其中有效關鍵字為:(ALL), DATA_ONLY 和 METADATA_ONLY。
DIRECTORY 供轉儲文件和日誌文件使用的目錄對象。
DUMPFILE 目標轉儲文件 (expdat.dmp) 的列表,例如 DUMPFILE=scott1.dmp, scott2.dmp,dmpdir:scott3.dmp。
ENCRYPTION_PASSWORD 用於創建加密列數據的口令關鍵字。
ESTIMATE 計算作業估計值, 其中有效關鍵字為:(BLOCKS) 和 STATISTICS。
ESTIMATE_ONLY 在不執行導出的情況下計算作業估計值。
EXCLUDE 排除特定的對象類型, 例如EXCLUDE=TABLE:EMP。
FILESIZE 以位元組為單位指定每個轉儲文件的大小。
FLASHBACK_SCN 用於將會話快照設置回以前狀態的 SCN。
FLASHBACK_TIME 用於獲取最接近指定時間的 SCN 的時間。
FULL 導出整個資料庫 (N)。
HELP 顯示幫助消息 (N)。
INCLUDE 包括特定的對象類型, 例如INCLUDE=TABLE_DATA。
JOB_NAME 要創建的導出作業的名稱。
LOGFILE 日誌文件名 (export.log)。
NETWORK_LINK 鏈接到源系統的遠程資料庫的名稱。
NOLOGFILE 不寫入日誌文件 (N)。
PARALLEL 更改當前作業的活動 worker 的數目。
PARFILE 指定參數文件。
QUERY 用於導出表的子集的謂詞子句。
SAMPLE 要導出的數據的百分比;
SCHEMAS 要導出的方案的列表 (登錄方案)。
STATUS 在預設值 (0) 將顯示可用時的新狀態的情況下,要監視的頻率 (以秒計) 作業狀態。
TABLES 標識要導出的表的列表 - 只有一個方案。
TABLESPACES 標識要導出的表空間的列表。
TRANSPORT_FULL_CHECK 驗證所有表的存儲段 (N)。
TRANSPORT_TABLESPACES 要從中卸載元數據的表空間的列表。
VERSION 要導出的對象的版本, 其中有效關鍵字為:(COMPATIBLE), LATEST 或任何有效的資料庫版本。
下列命令在交互模式下有效。
註: 允許使用縮寫
命令 說明
------------------------------------------------------------------------------
ADD_FILE 向轉儲文件集中添加轉儲文件。
CONTINUE_CLIENT 返回到記錄模式。如果處於空閑狀態, 將重新啟動作業。
EXIT_CLIENT 退出客戶機會話並使作業處於運行狀態。
FILESIZE 後續 ADD_FILE 命令的預設文件大小 (位元組)。
HELP 總結交互命令。
KILL_JOB 分離和刪除作業。
PARALLEL 更改當前作業的活動 worker 的數目。
PARALLEL=<worker 的數目>。
START_JOB 啟動/恢復當前作業。
STATUS 在預設值 (0) 將顯示可用時的新狀態的情況下,要監視的頻率 (以秒計) 作業狀態。
STATUS[=interval]
STOP_JOB 順序關閉執行的作業並退出客戶機。STOP_JOB=IMMEDIATE 將立即關閉數據泵作業。
2、IMPDP
IMPDP與EXPDP的不同參數:
1、REMAP_DATAFILE
該選項用於將源數據文件名轉變為目標數據文件名,在不同平臺之間搬移表空間時可能需要該選項.
REMAP_DATAFIEL=source_datafie:target_datafile
2、REMAP_SCHEMA
該選項用於將源方案的所有對象裝載到目標方案中.
REMAP_SCHEMA=source_schema:target_schema
3、REMAP_TABLESPACE
將源表空間的所有對象導入到目標表空間中
REMAP_TABLESPACE=source_tablespace:target:tablespace
4、REUSE_DATAFILES
該選項指定建立表空間時是否覆蓋已存在的數據文件.預設為N
REUSE_DATAFIELS={Y | N}
5、SKIP_UNUSABLE_INDEXES
指定導入是否跳過不可使用的索引,預設為N
6、SQLFILE
指定將導入要指定的索引DDL操作寫入到SQL腳本中
SQLFILE=[directory_object:]file_name
Impdp scott/tiger DIRECTORY=dumpDUMPFILE=tab.dmp SQLFILE=a.sql
sqlfile 參數允許創建DDL 腳本文件
impdp scott/tiger directory=dump_scott dumpfile=a1.dmp sqlfile=c.sql
預設放在directory下,因此不要指定絕對路徑
7、STREAMS_CONFIGURATION
指定是否導入流元數據(StreamMatadata),預設值為Y.
8、TABLE_EXISTS_ACTION
該選項用於指定當表已經存在時導入作業要執行的操作,預設為SKIP
TABBLE_EXISTS_ACTION={SKIP | APPEND |TRUNCATE | FRPLACE }
當設置該選項為SKIP時,導入作業會跳過已存在表處理下一個對象;
當設置為APPEND時,會追加數據,
為TRUNCATE時,導入作業會截斷表,然後為其追加新數據;
當設置為REPLACE時,導入作業會刪除已存在表,重建表並追加數據,
註意,TRUNCATE選項不適用與簇表和NETWORK_LINK選項
9、TRANSFORM
該選項用於指定是否修改建立對象的DDL語句
TRANSFORM=transform_name:value[:object_type]
Transform_name用於指定轉換名,其中SEGMENT_ATTRIBUTES用於標識段屬性(物理屬性,存儲屬性,表空間,日誌等信息),
STORAGE用於標識段存儲性,VALUE用於指定是否包含段屬性或段存儲屬性,object_type用於指定對象類型.
Impdp scott/tiger directory=dumpdumpfile=tab.dmp Transform=segment_attributes:n:table
10、TRANSPORT_DATAFILES
該選項用於指定搬移空間時要被導入到目標資料庫的數據文件
TRANSPORT_DATAFILE=datafile_name
Datafile_name用於指定被覆制到目標資料庫的數據文件
Impdp system/manager DIRECTORY=dump DUMPFILE=tts.dmp
TRANSPORT_DATAFILES=’/user01/data/tbs1.f’
3、常用參數說明
1)ATTACH
該選項用於在客戶會話與已存在導出作用之間建立關聯.語法如下
ATTACH=[schema_name.]job_name
Schema_name用於指定方案名,job_name用於指定導出作業名.註意,如果使用ATTACH選項在命令行除了連接字元串和ATTACH選項外,不能指定任何其他選項,示例如下:
Expdp scott/tiger ATTACH=scott.export_job
2) CONTENT
該選項用於指定要導出的內容.預設值為ALL
CONTENT={ALL | DATA_ONLY | METADATA_ONLY}
當設置CONTENT為ALL 時,將導出對象定義及其所有數據.為DATA_ONLY時,只導出對象數據,為METADATA_ONLY時,只導出對象定義
Expdp scott/tiger DIRECTORY=dump DUMPFILE=a.dump CONTENT=METADATA_ONLY
3) DIRECTORY
指定轉儲文件和日誌文件所在的目錄
DIRECTORY=directory_object
Directory_object用於指定目錄對象名稱.需要註意,目錄對象是使用CREATE DIRECTORY語句建立的對象,而不是OS 目錄
Expdp scott/tiger DIRECTORY=dumpDUMPFILE=a.dump
建立目錄:
SQL> createdirectory dump_dir as 'd:\dump';
目錄已創建。
SQL> grantread,write on directory dump_dir to scott;
授權成功。
查詢創建了那些子目錄:
SELECT * FROM dba_directories;
4) DUMPFILE
用於指定轉儲文件的名稱,預設名稱為expdat.dmp
DUMPFILE=[directory_object:]file_name [,….]
Directory_object用於指定目錄對象名,file_name用於指定轉儲文件名.需要註意,如果不指定directory_object,導出工具會自動使用DIRECTORY選項指定的目錄對象
Expdp scott/tiger DIRECTORY=dump1DUMPFILE=dump2:a.dmp
5.)ESTIMATE
指定估算被導出表所占用磁碟空間分方法.預設值是BLOCKS
EXTIMATE={BLOCKS | STATISTICS}
設置為BLOCKS時,oracle會按照目標對象所占用的數據塊個數乘以數據塊尺寸估算對象占用的空間,設置為STATISTICS時,根據最近統計值估算對象占用空間
Expdp scott/tiger TABLES=empESTIMATE=STATISTICS
DIRECTORY=dump DUMPFILE=a.dump
6.)EXTIMATE_ONLY
指定是否只估算導出作業所占用的磁碟空間,預設值為N
EXTIMATE_ONLY={Y | N}
設置為Y時,導出作用只估算對象所占用的磁碟空間,而不會執行導出作業,為N時,不僅估算對象所占用的磁碟空間,還會執行導出操作.
Expdp scott/tiger ESTIMATE_ONLY=y NOLOGFILE=y
7.)EXCLUDE
該選項用於指定執行操作時釋放要排除對象類型或相關對象
EXCLUDE=object_type[:name_clause] [,….]
Object_type用於指定要排除的對象類型,name_clause用於指定要排除的具體對象.EXCLUDE和INCLUDE不能同時使用
Expdp scott/tiger DIRECTORY=dump DUMPFILE=a.dup EXCLUDE=VIEW
8)FILESIZE
指定導出文件的最大尺寸,預設為0,(表示文件尺寸沒有限制)
9)FLASHBACK_SCN
指定導出特定SCN時刻的表數據
FLASHBACK_SCN=scn_value
Scn_value用於標識SCN值.FLASHBACK_SCN和FLASHBACK_TIME不能同時使用
Expdp scott/tiger DIRECTORY=dumpDUMPFILE=a.dmp FLASHBACK_SCN=358523
10)FLASHBACK_TIME
指定導出特定時間點的表數據
FLASHBACK_TIME=”TO_TIMESTAMP(time_value)”
Expdp scott/tiger DIRECTORY=dumpDUMPFILE=a.dmp FLASHBACK_TIME=“TO_TIMESTAMP(’25-08-200414:35:00’,’DD-MM-YYYYHH24:MI:SS’)”
11)FULL
指定資料庫模式導出,預設為N
FULL={Y | N}
為Y時,標識執行資料庫導出.
12)HELP
指定是否顯示EXPDP命令行選項的幫助信息,預設為N
當設置為Y時,會顯示導出選項的幫助信息.
Expdp help=y
13)INCLUDE
指定導出時要包含的對象類型及相關對象
INCLUDE = object_type[:name_clause] [,… ]
14)JOB_NAME
指定要導出作用的名稱,預設為SYS_XXX
JOB_NAME=jobname_string
15)LOGFILE
指定導出日誌文件文件的名稱,預設名稱為export.log
LOGFILE=[directory_object:]file_name
Directory_object用於指定目錄對象名稱,file_name用於指定導出日誌文件名.如果不指定directory_object.導出作用會自動使用DIRECTORY的相應選項值.
Expdp scott/tiger DIRECTORY=dumpDUMPFILE=a.dmp logfile=a.log
16)NETWORK_LINK
指定資料庫鏈名,如果要將遠程資料庫對象導出到本地常式的轉儲文件中,必須設置該選項.
17)NOLOGFILE
該選項用於指定禁止生成導出日誌文件,預設值為N.
18)PARALLEL
指定執行導出操作的並行進程個數,預設值為1
19)PARFILE
指定導出參數文件的名稱
PARFILE=[directory_path] file_name
20)QUERY
用於指定過濾導出數據的where條件
QUERY=[schema.] [table_name:] query_clause
Schema用於指定方案名,table_name用於指定表名,query_clause用於指定條件限制子句.QUERY選項不能與CONNECT=METADATA_ONLY,EXTIMATE_ONLY,TRANSPORT_TABLESPACES等選項同時使用.
Expdp scott/tiger directory=dump dumpfiel=a.dmp Tables=emp query=’WHERE deptno=20’
21)SCHEMAS
該方案用於指定執行方案模式導出,預設為當前用戶方案.
22)STATUS
指定顯示導出作用進程的詳細狀態,預設值為0
23)TABLES
指定表模式導出
TABLES=[schema_name.]table_name[:partition_name][,…]
Schema_name用於指定方案名,table_name用於指定導出的表名,partition_name用於指定要導出的分區名.
24)TABLESPACES
指定要導出表空間列表
25)TRANSPORT_FULL_CHECK
該選項用於指定被搬移表空間和未搬移表空間關聯關係的檢查方式,預設為N.
當設置為Y時,導出作用會檢查表空間直接的完整關聯關係,如果表空間所在表空間或其索引所在的表空間只有一個表空間被搬移,將顯示錯誤信息.當設置為N時,導出作用只檢查單端依賴,如果搬移索引所在表空間,但未搬移表所在表空間,將顯示出錯信息,如果搬移表所在表空間,未搬移索引所在表空間,則不會顯示錯誤信息.
26)TRANSPORT_TABLESPACES
指定執行表空間模式導出
27)VERSION
指定被導出對象的資料庫版本,預設值為COMPATIBLE.
VERSION={COMPATIBLE | LATEST |version_string}
為COMPATIBLE時,會根據初始化參數COMPATIBLE生成對象元數據;為LATEST時,會根據資料庫的實際版本生成對象元數據.version_string用於指定資料庫版本字元串.
七、模式說明
1、用戶模式
用戶模式導入數據時,會自動創建用戶。
不過在使用過程中,一定要註意dump文件中創建用戶腳本的細節參數,防止帶來不必要的麻煩。
雖然IMPDP工具具有自動創建用戶的功能,不過儘量不要採用這種方法,
還是應該按部就班的手工完成用戶的創建及用戶授權,然後再完成數據的導入。
2、表空間模式
3.12 TRANSPORT_DATAFILES
該選項表示的是表空間的傳輸。用於指定搬移空間時要被導入到目標資料庫的數據文件。
這種方法的操作步驟如下:
(1)將表空間改成read only 狀態,然後copy 待傳輸的表空間的所有數據文件到目標庫。 這裡可以進行重命名。
SQL> alter tablespace dave read only;
(2)按transport 方式導出表空間。如:
expdp directory=backup dumpfile=tts.dmp transport_tablespaces=dave
註意:這步操作只把metadata,即元數據,只有定義,沒有data導入了dump文件。實際的data 我們在第一步已經copy 過去了。
(3)import 我們的數據。 如:
impdp hr directory=dpump_dir1 dumpfile=tts.dmp transport_datafiles='/user01/data/workers.dat'
(4)將表空間改成read write:
SQL>alter tablespace dave read write ;
SQL>select * from dba_tablespaces ;
SQL>select * from dba_data_files ;
元數據(metadata)從我們的dump文件導入,Data Pump將實際的data從我們指定的workers.dat 導入。 這裡必須寫絕對路勁。
我們看個實例:
(1)先對錶空間Dave 添加一個數據文件:
SQL> alter tablespace dave add datafile '/u01/dave02.dbf' size 20m;
Tablespace altered.
(2)copy 到其他實例的對應位置
在移動之前先將表空間改成read only 狀態:
SQL> alter tablespace dave read only;
將表空間下的所有數據文件移動到其他的實例上。可以進行重命令。 我這裡是同一個實例。 因為我這裡是一個實例。 我將我們剛纔添加的數據文件dave02.dbf 移動到/u01/app/oracle/oradata/dave下。 待expdp 完成後,我們將表空間drop掉,在import進來。
$ cp /u01/dave02.dbf /u01/app/oracle/oradata/dave/bl02.dbf
將dave01.dbf 複製成bl03.dbf. 等會刪除表空間,不然會被刪除掉。
$ cp dave01.dbf bl03.dbf
(3)expdp 導出元數據
$expdp /'/ as sysdba /' directory=backup dumpfile=tts.dmp transport_tablespaces=dave
(4)import 數據
先把表空間drop掉在import:
SQL> drop tablespace dave including contents and datafiles;
Tablespace dropped.
$ impdp /'/ as sysdba /' directory=backup dumpfile=tts.dmp transport_datafiles='/u01/app/oracle/oradata/dave/bl02.dbf', '/u01/app/oracle/oradata/dave/bl03.dbf'
註意一點: 這裡transport 的表空間,在另一個實例上是不可以存在的。 不然不能導入。
如果文件很多,也可以寫入個配置文件里。 導入時通過PARFILE參數來指定。
(5)將表空間改成read write模式:
SQL> select tablespace_name,status from dba_tablespaces;
TABLESPACE_NAME STATUS
------------------------------ ---------
SYSTEM ONLINE
UNDOTBS1 ONLINE
SYSAUX ONLINE
TEMP ONLINE
USERS ONLINE
DAVE READ ONLY
BL ONLINE
7 rows selected.
SQL> alter tablespace dave read write;
Tablespace altered.
SQL> select tablespace_name,status from dba_tablespaces;
TABLESPACE_NAME STATUS
------------------------------ ---------
SYSTEM ONLINE
UNDOTBS1 ONLINE
SYSAUX ONLINE
TEMP ONLINE
USERS ONLINE
DAVE ONLINE
BL ONLINE
7 rows selected.
transport_datafiles 註意的幾點:
(1)表空間所有的數據文件都要copy到目標庫。
(2)copy 之間,將表空間改成read only 狀態。
(3)copy之後可以對數據文件進行重命名。 所以,transport_datafiles 也可以用來對數據文件進行重命名和移動位置。
(4)transport_datafiles 完成之後,不要忘記將表空間改成讀寫模式。
3、全庫模式
全庫模式導出的是非SYS的用戶。
把db從unix導入到win下,全庫導出時裡面有create tablespace的語法,這樣就有datafile的語法,裡面就有路徑,
導入到win時創建tablespace時的路徑就不能是unix下的路徑了,此時可以通過該參數REMAP_DATAFILE一下路徑:
remap_datafile=/oradata/orcl/dave01.dbf:e:/oradata/orcl/dave01.dbf
全庫導出:
$expdp /'/ as sysdba/' directory=backup full=y dumpfile=fullexp3.dmp logfile=fullexp3.log parallel=2 job_name=daveJob;
全庫導入:
$impdp /'/ as sysdba/' directory=backup dumpfile=fullexp3.dmp logfile=tbs.log full=y remap_datafile='/u01/app/oracle/oradata/dave/dave01.dbf':'/u01/app/oracle/oradata/dave/tianlesoftware01.dbf';
如果這裡的remap 文件比較多,可以把這部分單獨拿出來,放到一個文件里。
$impdp /'/ as sysdba/' directory=backup dumpfile=fullexp3.dmp logfile=tbs.log full=y parfile=payroll.par
payroll.par 內容:
remap_datafile='/oradata/orcl/system01.dbf':'/u01/oradata/orcl/system01.dbf'
remap_datafile='/oradata/orcl/sysaux01.dbf':'/u01/oradata/orcl/sysaux01.dbf'
remap_datafile='/oradata/orcl/undotbs4.dbf':'/u01/oradata/orcl/undotbs4.dbf'
remap_datafile='/oradata/orcl/test02.dbf':'/u01/oradata/orcl/test02.dbf'
如果是windows系統,需要加雙引號:
remap_datafile="'d:/orcl/system01.dbf':'e:/orcl/system01.dbf'"
八、影響數據泵性能的相關參數
對下列參數建議如下設置
disk_asynch_io=true
db_block_checking=false
db_block_checksum=false
對下列參數建議設置更高的值來提高併發
processes
sessions
parallel_max_servers
對下列參數應儘可能的調大空間大小
shared_pool_size
undo_tablespace
九、實例講解
1、導出導入表
Expdp mid_gis_0306/mid_gis DIRECTORY=DATA_PUMP_DIR DUMPFILE=GISMID_150820.dmp logfile=GISMID_150820.log TABLES=TRANSCIRCUITSUPPLY,LVCUSTOMERSUPPLY,LOCATION,TERMINAL
impdp drm_pfm/drm_pfm DIRECTORY=DATA_PUMP_DIR DUMPFILE=GISMID_150820.DMP logfile=GISMID_150820.log tables=mid_gis_0306.TRANSCIRCUITSUPPLY,mid_gis_0306.LVCUSTOMERSUPPLY REMAP_SCHEMA=mid_gis_0306:mid transform=segment_attributes:n table_exists_action=replace
2.導出導入方案
expdp scott/tiger directory=DATA_PUMP_DIR dumpfile=schema.dmp logfile=schema.log schemas=scott,system
--將dump_scott目錄下的schema.dmp抽方案scott導入到scott方案中
impdp scott/tiger directory=DATA_PUMP_DIR dumpfile=schema.dmp schemas=scott
--將scott方案中的所有對象轉移到system方案中
impdp system/redhat directory=DATA_PUMP_DIR dumpfile=schema.dmp schemas=scott remap_schema=scott:system
3.導出導入表空間
expdp scott/tiger directory=DATA_PUMP_DIR dumpfile=tablespace.dmp logfile=tb.log tablespaces=user01,user02
impdp system/redhat directory=DATA_PUMP_DIR dumpfile=tablespace.dmp tablespaces=user01
impdp \"/ as sysdba\" schemas=user1,user2 remap_schema=user1:user3,user2:user4 directory=EXPDUMP dumpfile=test.dump logfile=test_schemas_impdp.log PARALLEL=20
4.導出導入資料庫
Expdp system/manager DIRECTORY=DATA_PUMP_DIR DUMPFILE=full.dmp FULL=Y
Expdp scott/tiger DIRECTORY=DATA_PUMP_DIR DUMPFILE=full.dmp FULL=Y --(grant exp_full_database to scott;--imp_full_database)
impdp system/redhat directory=DATA_PUMP_DIR dumpfile=full.dmp full=y
impdp \"/ as sysdba\" schemas=user1,user2 remap_tablespace=tp1:tp3,tp2:tp4 directory=EXPDUMP dumpfile=test.dump logfile=test_schemas_impdp.log PARALLEL=20
5.使用remap_datafile參數轉移到不同的數據文件(用於不同平臺之間存在不同命名方式時)
下麵的示例首先創建了一個參數文件,參數文件名為payroll.par
directory=pump_scott
full=y
dumpfile=datafile.dmp
remap_datafile='db$:[hrdata.payroll]tbs2.f':'/db/hrdata/payroll/tbs2.f' --指明重新映射數據文件
impdp scott/tiger PARFILE=payroll.par
6.使用remap_tablespace參數轉移到不同的表空間
impdp scott/scott remap_tablespace=users:tbs1 directory=dpump_scott dumpfile=users.dmp
7.並行導入導出:
expdp e/e directory=DATA_PUMP_DIR dumpfile=a_%u.dmp schemas=e parallel=3
impdp e/e directory=DATA_PUMP_DIR dumpfile=a_%u.dmp schemas=e parallel=3 table_exists_action=replace
參考文獻:
http://blog.csdn.net/jojo52013145/article/details/7966047
http://blog.csdn.net/leshami/article/details/5926276
http://blog.csdn.net/tianlesoftware/article/details/6260138


