
Zookeeper是一個分散式應用程式協調服務,功能包含:配置管理、名字服務、分散式鎖、集群管理等,適合使用在讀多於寫的操作。 1. 配置管理 分散式系統都有好多機器,比如我在搭建hadoop的HDFS的時候,需要在一個主機器上(Master節點)配置好HDFS需要的各種配置文件,然後通過scp命令 ...
Zookeeper是一個分散式應用程式協調服務,功能包含:配置管理、統一命名、共用鎖、集群管理、隊列管理等,適合使用在讀多於寫的操作。
1. 配置管理
配置的管理在分散式應用環境中很常見,例如同一個應用系統需要多台 PC Server 運行,但是它們運行的應用系統的某些配置項是相同的,如果要修改這些相同的配置項,那麼就必須同時修改每台運行這個應用系統的 PC Server,這樣非常麻煩而且容易出錯。
像這樣的配置信息完全可以交給 Zookeeper 來管理,將配置信息保存在 Zookeeper 的某個目錄節點中,然後將所有需要修改的應用機器監控配置信息的狀態,一旦配置信息發生變化,每台應用機器就會收到 Zookeeper 的通知,然後從 Zookeeper 獲取新的配置信息應用到系統中。

2.統一命名
分散式應用中,通常需要有一套完整的命名規則,既能夠產生唯一的名稱又便於人識別和記住,通常情況下用樹形的名稱結構是一個理想的選擇,樹形的名稱結構是一個有層次的目錄結構,既對人友好又不會重覆。說到這裡你可能想到了 JNDI,沒錯 Zookeeper 的 Name Service 與 JNDI 能夠完成的功能是差不多的,它們都是將有層次的目錄結構關聯到一定資源上,但是 Zookeeper 的 Name Service 更加是廣泛意義上的關聯,也許你並不需要將名稱關聯到特定資源上,你可能只需要一個不會重覆名稱,就像資料庫中產生一個唯一的數字主鍵一樣。
3.共用鎖
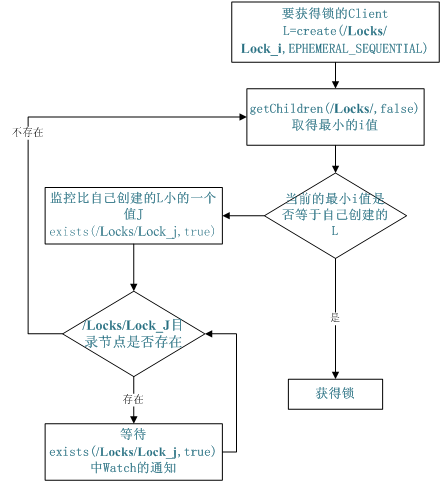
不同的系統或是同一個系統的不同主機之間共用了一個或一組資源,那麼訪問這些資源的時候,往往需要互斥來防止彼此干擾來保證一致性,在這種情況下,便需要使用到分散式鎖。共用鎖在同一個進程中很容易實現,但是在跨進程或者在不同 Server 之間就不好實現了。Zookeeper 卻很容易實現這個功能,實現方式也是需要獲得鎖的 Server 創建一個 EPHEMERAL_SEQUENTIAL 目錄節點,然後調用 getChildren方法獲取當前的目錄節點列表中最小的目錄節點是不是就是自己創建的目錄節點,如果正是自己創建的,那麼它就獲得了這個鎖,如果不是那麼它就調用 exists(String path, boolean watch) 方法並監控 Zookeeper 上目錄節點列表的變化,一直到自己創建的節點是列表中最小編號的目錄節點,從而獲得鎖,釋放鎖很簡單,只要刪除前面它自己所創建的目錄節點就行了。
4.集群管理
在分散式的集群中,經常會由於各種原因,比如硬體故障,軟體故障,網路問題,有些節點會進進出出。有新的節點加入進來,也有老的節點退出集群。這個時候,集群中有些機器需要感知到這種變化,然後根據這種變化做出對應的決策。Zookeeper 能夠很容易的實現集群管理的功能,如有多台 Server 組成一個服務集群,那麼必須要一個“總管”知道當前集群中每台機器的服務狀態,一旦有機器不能提供服務,集群中其它集群必須知道,從而做出調整重新分配服務策略。同樣當增加集群的服務能力時,就會增加一臺或多台 Server,同樣也必須讓“總管”知道。
Zookeeper 不僅能夠幫你維護當前的集群中機器的服務狀態,而且能夠幫你選出一個“總管”,讓這個總管來管理集群,這就是 Zookeeper 的另一個功能 Leader Election。
它們的實現方式都是在 Zookeeper 上創建一個 EPHEMERAL 類型的目錄節點,然後每個 Server 在它們創建目錄節點的父目錄節點上調用 getClildren方法並設置 watch 為 true,由於是 EPHEMERAL 目錄節點,當創建它的 Server 死去,這個目錄節點也隨之被刪除,所以 Children 將會變化,這時 getClildren上的 Watch 將會被調用,所以其它 Server 就知道已經有某台 Server 死去了。新增 Server 也是同樣的原理。
Zookeeper 如何實現 Leader Election,也就是選出一個 Master Server。和前面的一樣每台 Server 創建一個 EPHEMERAL 目錄節點,不同的是它還是一個 SEQUENTIAL 目錄節點,所以它是個 EPHEMERAL_SEQUENTIAL 目錄節點。之所以它是 EPHEMERAL_SEQUENTIAL 目錄節點,是因為我們可以給每台 Server 編號,我們可以選擇當前是最小編號的 Server 為 Master,假如這個最小編號的 Server 死去,由於是 EPHEMERAL 節點,死去的 Server 對應的節點也被刪除,所以當前的節點列表中又出現一個最小編號的節點,我們就選擇這個節點為當前 Master。這樣就實現了動態選擇 Master,避免了傳統意義上單 Master 容易出現單點故障的問題。

5.隊列管理
Zookeeper 可以處理兩種類型的隊列:
- 當一個隊列的成員都聚齊時,這個隊列才可用,否則一直等待所有成員到達,這種是同步隊列。
- 隊列按照 FIFO 方式進行入隊和出隊操作,例如實現生產者和消費者模型。
Zookeeper特性
1.最終一致性
2.順序性
3.高可用
4.原子性
5.實時性
Zookeeper基本架構

角色:
leader:負責進行投票的發起和決議,更新系統狀態
follower:用於接收客戶端請求並向客戶端返回結果,在選舉過程中參與投票。
observer:可以接收客戶端的連接,將寫請求轉發給leader節點,但是observer不參加投票,只同步leader的狀態。observer目的是擴展系統,提高讀取速度。
節點數目:
Zookeeper Server數目一般為奇數,Leader選舉演算法採用了Paxos協議;Paxos核心思想:當多數(一半以上)Server寫成功,則任務數據寫成功。
Zookeeper數據模型:
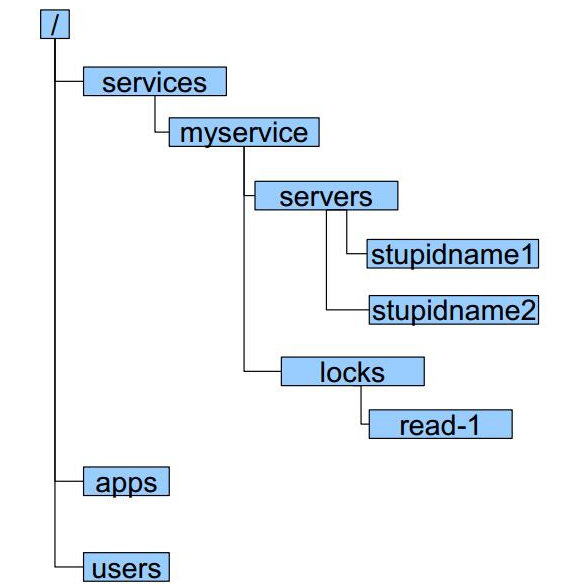
zookeeper採用層次化的目錄結構,命名符合常規文件系統規範;每個目錄在zookeeper中叫做znode,並且其有一個唯一的路徑標識。
znode可以包含數據和子znode(ephemeral類型的節點不能有子znode); znode中的數據可以有多個版本,比如某一個znode下存有多個數據版本,那麼查詢這個路徑下的數據需帶上版本; 客戶端應用可以在znode上設置監視器(Watcher) znode不支持部分讀寫,而是一次性完整讀寫。
znode有兩種類型,短暫的(ephemeral)和持久的(persistent); znode的類型在創建時確定並且之後不能再修改; ephemeral znode的客戶端會話結束時,zookeeper會將該ephemeral znode刪除,ephemeral znode不可以有子節點; persistent znode不依賴於客戶端會話,只有當客戶端明確要刪除該persistent znode時才會被刪除。
znode有四種形式的目錄節點,PERSISTENT、PERSISTENT_SEQUENTIAL、EPHEMERAL、PHEMERAL_SEQUENTIAL。
參考文章: http://debugo.com/zookeeper-api/

