我這裡集成好了一個自帶IK的版本,下載即用, https://github.com/xlb378917466/elasticsearch5.2.include_IK 添加了IK插件意味著你可以使用ik_smart(最粗粒度的拆分)和ik_max_word(最細粒度的拆分)兩種analyzer。 你也 ...
我這裡集成好了一個自帶IK的版本,下載即用,
https://github.com/xlb378917466/elasticsearch5.2.include_IK
添加了IK插件意味著你可以使用ik_smart(最粗粒度的拆分)和ik_max_word(最細粒度的拆分)兩種analyzer。
你也可以從下麵這個地址獲取最新的IK源碼,自己集成,
https://github.com/medcl/elasticsearch-analysis-ik,
裡面還提供了使用說明,可以很快上手。
一般使用elasticsearch-head測試比較方便。
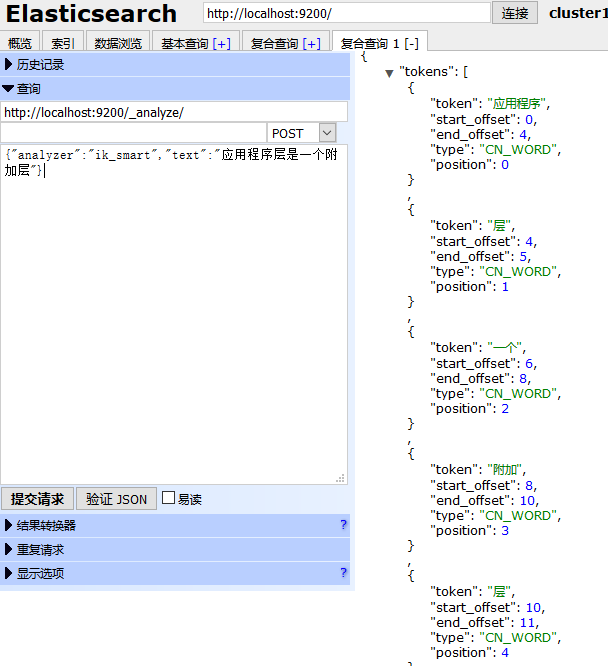
這個IK分詞插件挺好用的,支持自定義分詞,更重要的是支持熱更新。
比如上面這個應用程式層是被分成了兩個詞,如果你把應用程式層作為一個詞添加到你的自定義詞典中,那麼結果就會發生微妙的變化,通過這樣不斷的完善詞庫,相信搜索的體驗會越來越好。
現在IK分詞插件也算集成好了,如何使用?
首先新建一個索引,並且給這個索引下的文檔類型設置Mapping關係
這裡還是繼續使用昨天新建的索引twitter作例子,所以只需要給文檔類型tweet 新建一個欄位Content,並設置這一個欄位的Mapping來舉例:
http://localhost:9200/twitter/_mapping/tweet/
{
"properties": {
"content": {
"type": "text",
"store": "no",
"term_vector": "with_positions_offsets",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"include_in_all": "true",
"boost": 8
}
}
}
這樣一來,後面添加的Content就會使用ik_smart來分詞,
添加一條測試數據:
http://localhost:9200/twitter/tweet/1/ 選擇Put Method
{
"content": "應用程式層是一個附加層"
}
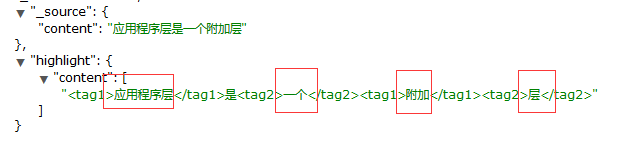
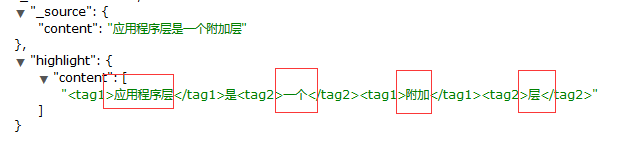
查詢測試:
http://localhost:9200/twitter/_search/
使用POST Method,因為我使用ElasticSearch Head 在Get的情況下不返回highlight信息,
{
"query" : { "match" : { "content" : "應用程式層是一個附加層" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
返回如下:
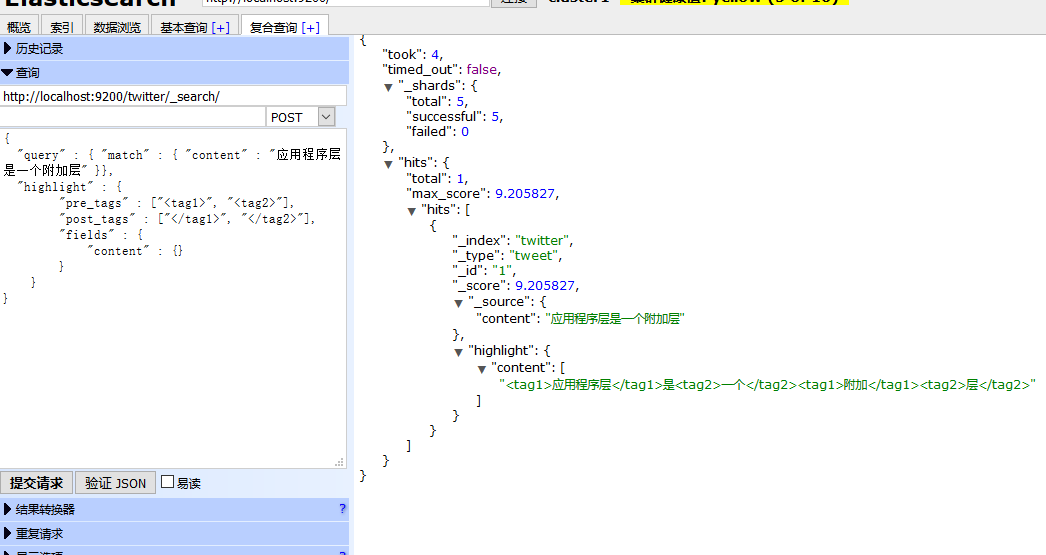
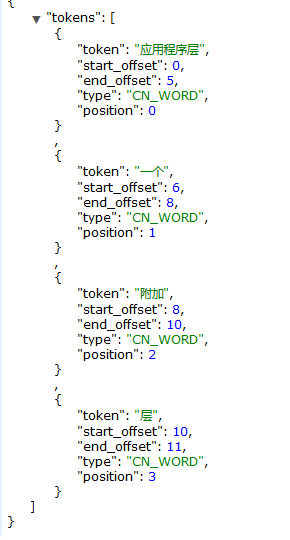
使用應用程式關鍵詞是搜不到內容的,因為分詞器不識別 這個詞,就是說你要用被你拆分之後的詞來搜索,才有匹配的記錄。
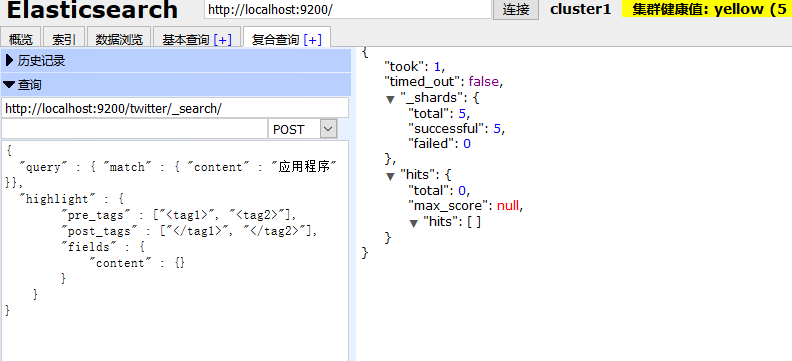
比如下麵幾個就是被拆分出來的詞