
資源組是由一個或多個資源組成的組,WSFC的故障轉移是以資源組為單位的,資源組中的資源是相互依賴的,相互關聯。一個資源所依賴的其他資源必須和該資源處於同一個資源組,跨資源組的依賴關係是不存在的。在任何時候,每個資源組都僅屬於集群中的一個結點,該結點就是資源組的活躍結點,由活躍結點為應用程式提供服務。 ...
資源組是由一個或多個資源組成的組,WSFC的故障轉移是以資源組為單位的,資源組中的資源是相互依賴的,相互關聯。一個資源所依賴的其他資源必須和該資源處於同一個資源組,跨資源組的依賴關係是不存在的。在任何時候,每個資源組都僅屬於集群中的一個結點,該結點就是資源組的活躍結點,由活躍結點為應用程式提供服務。AlwaysOn的故障轉移特性建立在WSFC的健康檢測和故障轉移的特性之上,因此,AlwaysOn和故障轉移集群有了不可分割的關係,理解他們的關係,有助於維護更好的維護AlwaysOn。
一,AlwaysOn的可用性組是集群的資源組
AlwaysOn的可用性組(Availability Group)是集群的資源組,其資源類型是“SQL Server Availability Group”,由於,WSFC的故障轉移是以資源組為單位的,因此,AlwaysOn的每次故障轉移都會將整個可用性組裡的資料庫一起轉移。
1,查看集群的資源組
打開故障轉移集群管理器(Failover Cluster Manager),選中集群結點,點開Roles,集群的每個角色就是一個資源組,在右邊的資源組監控器面板中,能夠看到創建成功的可用性組 TestAG,角色類型(Type)是Other;

2,資源組的故障轉移屬性
右擊角色的屬性,在Failover Tab中,查看集群的故障轉移屬性的設置,預設設置如下圖:
- 故障轉移(Failover)屬性:設置集群在指定的時間區間內執行故障轉移的次數;
- 故障恢復(Failback)屬性:設置集群在發生故障轉移之後,把資源組移回到最優先節點;
兩者的區別是:
- 故障轉移(Failover)是指:出現故障後轉移,集群把故障結點擁有的資源組轉移到另一個可用的結點上;
- 故障恢復(Failback)是指:出現故障後恢復,在發生故障轉移之後,如果最優先結點恢復正常,把資源組移回到最優先節點;
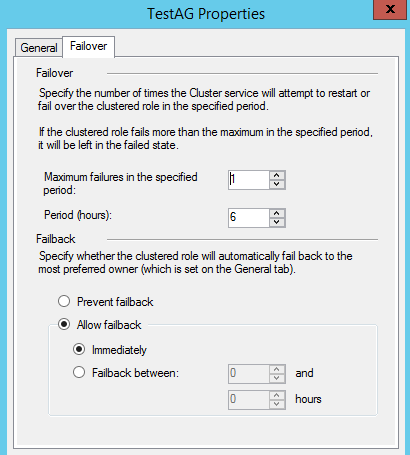
3,切換到General Tab
首選結點(Preferred Owners)選項的預設設置是勾選集群中的所有結點,優先順序是從上到下,第一個勾選的結點是最優先結點(Most Preferred Owners)。
在發生故障轉移之後,如果最優先結點恢復健康,那麼故障恢復(Failback)將資源組移回到最優先選結點;

二,集群資源的屬性
由於AlwaysOn 可用性組建立在故障轉移集群之上,Windows 集群負責監控AlwaysOn 可用性組的健康狀況。點擊角色TestAG下方面板Resource選項卡,能夠看到該資源組擁有兩個資源:可用性組TestAG和Listener。每個資源,都有Status標識該資源的健康狀態。
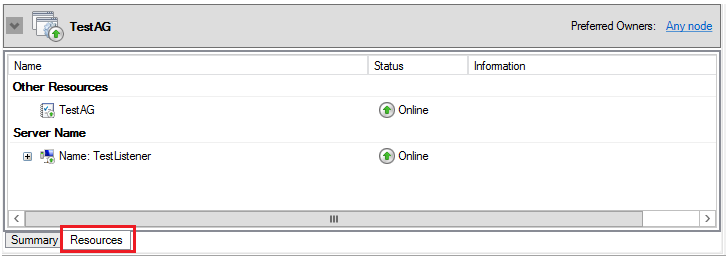
1,SQL Server 可用性組資源的屬性
TestAG資源的類型是SQL Server Availability Group,狀態是Online
2,切換到Dependencies Tab,查看資源的依賴關係
資源組中的資源是相互依賴的,一個資源所依賴的其他資源必須和該資源處於同一個資源組,跨資源組的依賴關係是不存在的。資源TestAG 和 資源Server Name之間是“and”的關係,這就是說,只有這兩個資源都處於Online狀態之後,整個資源組才處於可用的Online狀態。
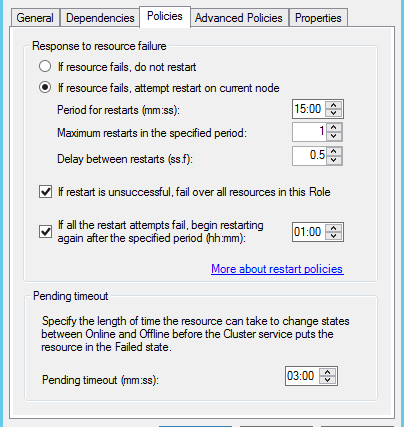
3,切換到Policies Tab,查看資源出現故障時,集群監控器的響應策略
該選項卡的選項決定了資源發生故障轉移時的行為,建議保留其預設設置,預設設置是當資源出現故障時,會在15分鐘內嘗試在當前結點重啟(一般是立即嘗試重啟,不需要等待15分鐘),第一次嘗試重啟失敗,就會將整個資源組轉移到其他的結點上。
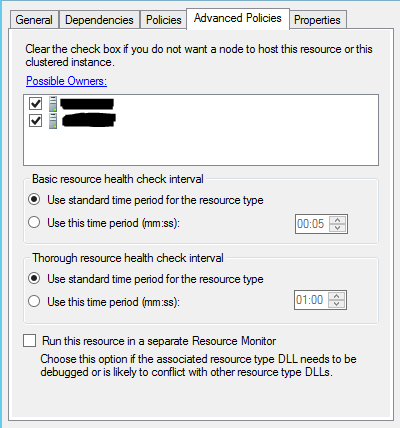
4,切換到Advanced Policies Tab
配置持有資源的集群結點,配置資源監控器(Resource Monitor)檢測資源健康的時間間隔,WSFC為了檢測每個資源是否工作正常,會使用不同的時間間隔來做兩種不同程度的檢查,對於SQL Server可用組資源類型:
- “Basic resource health check interval” 稱作“Looksalive check”,預設的時間間隔是5s;
- “Thorough resource health check interval”稱作“Isalive check”,預設的時間間隔是30s;
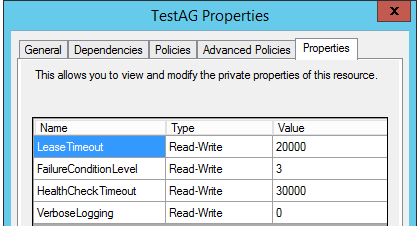
5,切換到Properties Tab,查看和配置資源的私有屬性
HealthCheckTimeout屬性:預設設置是30000ms,這就是說,每30s,資源監控器都會對資源進行一次健康檢測;
FailureConditionLevel屬性:設置資源出現故障的閾值,WSFC連接到可用性主副本上的SQL Server實例,並執行存儲過程 sp_server_diagnostics獲得可用性組的診斷信息,藉此評估可用組的健康狀況。WSFC將存儲過程 sp_server_diagnostics的評估結果和FailureConditionLevel屬性值相比較,如果滿足條件,那麼WSFC判定當前的主副本出現故障,WSFC將可用性組切換到新的可用性副本上;
三,集群資源的健康檢測
集群中的每個資源都有一個資源類型,WSFC根據不同類型的資源,使用不同的方式進行Isalive和Looksalive檢查,一般會把SQL Server Availability Group資源類型配置成“If resource fails, attempt restart on current node” 和 “If restart is unsuccessufll, fail over all resources in this service or application”模式,即在資源的Policies 選項卡中勾選相應的選項:
Looksalive檢查:WSFC檢查活躍結點的SQL Server服務(Service Name 是 MSSQLServer)是否處於“啟動狀態”,根據SQL Server Availability Group資源的Advance Polices 選項卡中的設置,這個檢查預設每5s做一次;
Isalive檢查:WSFC連接活躍結點,併在活躍結點中執行TSQL查詢語句(select @@ServerName),如果活躍結點返回查詢的結果,那麼Isalive檢查成功;如果活躍結點的SQL Server實例連接不上,或沒有返回查詢結果,那麼Isalive檢查失敗,根據SQL Server Availability Group資源的Advance Polices選項卡中的設置,這個檢查預設每30s做一次。
每執行6次Looksalive檢查,就會執行一次Isalive檢查,WSFC之所以需要對SQL Server 可用性組執行Isalive檢查,是因為即使SQL Server 服務處於正在運行(Running)狀態,也不能說明SQL Server 可以響應應用程式的請求,有時,可能整個SQL Server實例已經掛起,但是SQL Server服務的狀態還是Running,所以需要Isalive 檢查深入檢查SQL Server的狀態。此外,一旦looksalive檢查失敗,WSFC就會立即執行Isalive檢查。
如果Isalive檢查失敗,WSFC會根據設置,重試3~5次Isalive檢查。如果這些檢查都失敗了,WSFC就根據Polices選項卡中的設置進行故障轉移,由集群仲裁選舉出新的主副本(Primary Replica),Listener將SQL Server實例名和IP地址指向集群中新的主副本,由其該結點為應用程式繼續提供服務,切換的過程是透明的。根據故障轉移模式的不同,分為自動故障轉移,手動故障轉移和強制故障轉移,詳細信息請閱讀《部署AlwaysOn第二步:配置AlwaysOn,創建可用性組》。
四,資源組的故障轉移
故障轉移完成之後,故障轉移的目標輔助副本轉換成為主副本,其資料庫轉換成主資料庫,新的主副本重做已經固化的事務日誌,回滾尚未提交的事務,使主資料庫恢復到原主副本發生故障時的事務一致性的狀態;如果原先的主副本從故障中恢復而重新運行,它會發現集群中已經存在新的主副本,於是它就把自己轉換為輔助副本,其資料庫轉為輔助數據。當心的輔助資料庫連接上主資料庫之後,輔助資料庫就開始進行同步操作,執行日誌的固化和重做。
1,自動故障轉移
在主副本出現故障之後,AlwaysOn迅速將資源組轉移到其他輔助副本,使資料庫再次變為可用,要發生自動故障轉移,必須滿足:
- 當前主副本和一個輔助副本都設置為同步提交模式和自動故障轉移模式;
- 輔助副本必須和主副本同步,即輔助副本處於SYNCHRONIZED狀態;
- 主副本變得不可用,此時將發生自動故障轉移;
2,手動故障轉移
當主副本和輔助副本可用,並且輔助資料庫處於SYNCHRONIZED狀態時,可以執行手動故障轉移,但是,在手動轉移的過程中,如果主副本停止運行,那麼輔助副本將進入“RESOLVING”角色,此時,該副本既不是輔助副本,也不是主副本,但可以執行強制故障轉移把輔助副本升級為主副本,但是,可能會丟失數據。
通過故障轉移集群管理器(Failover Cluster Manager),能夠手動執行資源組的轉移操作,但是,建議始終通過SSMS執行任意模式的故障轉移操作,能夠避免操作錯誤和數據丟失。
3,強制故障轉移
一旦執行強制故障轉移,主副本尚未發送到原來的輔助副本上的事務日誌都會丟失,這意味著,新的主資料庫可能會缺少一些最近提交的數據更新,在強制故障轉移之後,剩餘的輔助副本上的輔助資料庫都將處於掛起狀態,要重新恢復輔助副本的配置,必須以某個副本上的數據為基礎,重新配置可用性組。
五,監控AlwaysOn的健康狀態
AlwaysOn的健康狀態可以從故障轉移集群管理器(Failover Cluster Manager)和SSMS來監控,建議通過SSMS來手動故障轉移和監控,配置故障轉移集群控制器來對AlwaysOn的異常進行故障排除。
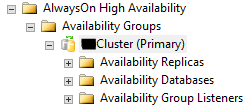
打開SSMS,連接到主副本(Primary Replica)上,點擊“AlwaysOn High Availability”能夠看到與該SQL Server 實例相關聯的可用性組(Availability Group),右擊可用性組,打開Dashboard,能夠查看可用性組的詳細信息,並對可用性組執行手動故障轉移操作。
參考文檔:
《SQL Server 2012 實施與管理實戰指南》第二章

