
介紹 經常會有人問profile工具該怎麼使用?有沒有方法獲取性能差的sql的問題。自從轉mysql我自己也差不多2年沒有使用profile,忽然profile變得有點生疏不得不重新熟悉一下。這篇文章主要對profile工具做一個詳細的介紹;包括工具的用途和使用方法等。profile是SQLServ ...
介紹
經常會有人問profile工具該怎麼使用?有沒有方法獲取性能差的sql的問題。自從轉mysql我自己也差不多2年沒有使用profile,忽然profile變得有點生疏不得不重新熟悉一下。這篇文章主要對profile工具做一個詳細的介紹;包括工具的用途和使用方法等。profile是SQLServer自帶的一個性能分析監控工具,它也可以生成資料庫引擎優化顧問分析需要的負載數據,比如開發對功能進行調試需要收集執行sql使用profile就是一個非常好的辦法,profile主要用於線上實時監控和收集數據用於後期的分析使用,它可以將收集的數據保存成文件和插入到表。
跟蹤屬性
一、常規
將跟蹤的記錄保存到指定的文件。
1.最大文件大小
指定最大文件大小的跟蹤在達到最大文件大小時,會停止將跟蹤信息保存到該文件。使用此選項可將事件分組成更小、更容易管理的文件。此外,限制文件大小使得無人參與的跟蹤運行起來更加安全,因為跟蹤會在達到最大文件大小後停止。可以為通過 Transact-SQL 存儲過程或使用 SQL Server Profiler創建的跟蹤設置最大文件大小。
最大文件大小選項的上限為 1 GB。預設最大文件大小為 5 MB
註意:最大文件的大小建議不要設的太大,特別是需要用於資料庫引擎優化顧問使用的文件,太大的跟蹤文件需要很長的分析的時間而且由於資料庫引擎優化顧問也是把收集的負載文件執行一遍有時候可能會導致負載過大分析失敗,同時對伺服器的壓力持續的時間過長對業務影響也會比較大,一般設置幾兆或者幾十兆即可,同時啟動文件滾動更新,多次分析。
2.啟用文件滾動更新
如果使用文件滾動更新選項,則在達到最大文件大小時,SQL Server 會關閉當前文件並創建一個新文件。新文件與原文件同名,但是文件名後將追加一個整數以表示其序列。例如,如果原始跟蹤文件命名為 filename_1.trc,則下一跟蹤文件為 filename_2.trc,依此類推。如果指定給新滾動更新文件的名稱已經被現有文件使用,則將覆蓋現有文件,除非現有文件為只讀文件。預設情況下,將跟蹤數據保存到文件時,會啟用文件滾動更新選項。
3.伺服器處理跟蹤數據
確保伺服器記錄每個跟蹤事件,如果記錄事件會顯著降低性能,可以清除伺服器處理跟蹤數據,這樣伺服器不會再記錄事件。4.最大行數
指定有最大行數的跟蹤在達到最大行數時,會停止將跟蹤信息保存到表。每個事件構成一行,因此該參數可設置收集的事件數的範圍。設置最大行數使得無人參與的跟蹤運行起來更加方便。例如,如果需要啟動一個將跟蹤數據保存到表的跟蹤,同時希望在該表變得過大時停止跟蹤,則可以使其自動停止。
如果已指定並且達到了最大行數,將在運行 SQL Server Profiler的同時繼續運行跟蹤,但不再記錄跟蹤信息。SQL Server Profiler將繼續顯示跟蹤結果,直到跟蹤停止
5.啟用跟蹤停止時間
啟用跟蹤停止時間之後,到了指定的時間跟蹤自動停止。每一次跟蹤建議都必須得設置一個跟蹤停止時間防止忘記關閉跟蹤導致伺服器空間被占滿,預設跟蹤1小時。
註意:
- 從 SQL Server 2005 開始,伺服器以微秒(百萬分之一秒或 10-6 秒)為單位報告事件的持續時間,以毫秒(千分之一秒或 10-3 秒)為單位報告事件使用的 CPU 時間。
- 在 SQL Server 2000 中,伺服器以毫秒為單位報告持續時間和 CPU 時間。
- 在 SQL Server 2005 及更高版本中,SQL Server Profiler圖形用戶界面預設以毫秒為單位顯示“持續時間”列,但是當跟蹤保存到文件或資料庫表中之後,將以微秒為單位在“持續時間”列中寫入值。
二、事件選擇
對於不同跟蹤選擇不同的跟蹤事件;通過勾選“顯示所有跟蹤事件”可以看到所有的跟蹤事件,總共有21個事件分類。用得最多的兩個分類就是存儲過程和TSQL這兩個分類主要用來記錄執行的存儲過程和SQL語句,把滑鼠移動到具體的事件上面會顯示該事件和事件列的具體說明,接下來就分析幾個常用的事件和常用的事件列。
1.顯示所有跟蹤事件
勾選之後會將所有的事件都顯示出來
2.顯示所有列
勾選之後會將所有的列顯示出來
3.列篩選
對列增加一些條件,其實可以將它理解在TSQL語句的WHERE後面添加條件,對於整形列直接輸入數值即可,對於字元串列就相當於like一樣使用不帶引號的%%模糊匹配方法。通過勾選“排除不包含值的行”之後跟蹤結果就會篩選掉不滿足條件的記錄。
4.列組織
列組織可以理解成TSQL語句裡面做GROUP BY操作,可以將相同的條件放在一起去重。
事件
1.SQL:Stmt*******
[SQL:StmtStarting]:啟動TSQL語句時記錄
[SQL:StmtCompleted]:完成TSQL語句時記錄

這兩事件的區別也同單詞的意思一樣,StmtStarting是記錄事件的開始不關註這個事件在接下來會做什麼,StmtCompleted是記錄事件結束之後在開始和結束這個過程中做的一些操作比如一些常用的列"Duration","Cpu","Reads","Writes","EndTime"這些列就會出現在StmtCompleted事件中。所以如果你需要收集的記錄不關心整個事件過程中的操作只需要收集數量那麼可以使用Starting事件比如記錄某個語句或者存儲過程執行的次數等。
2.SQL:Batch******
[SQL:BatchStarting]:啟動TSQL批處理時記錄
[SQL:BatchCompleted]:完成TSQL批處理時記錄
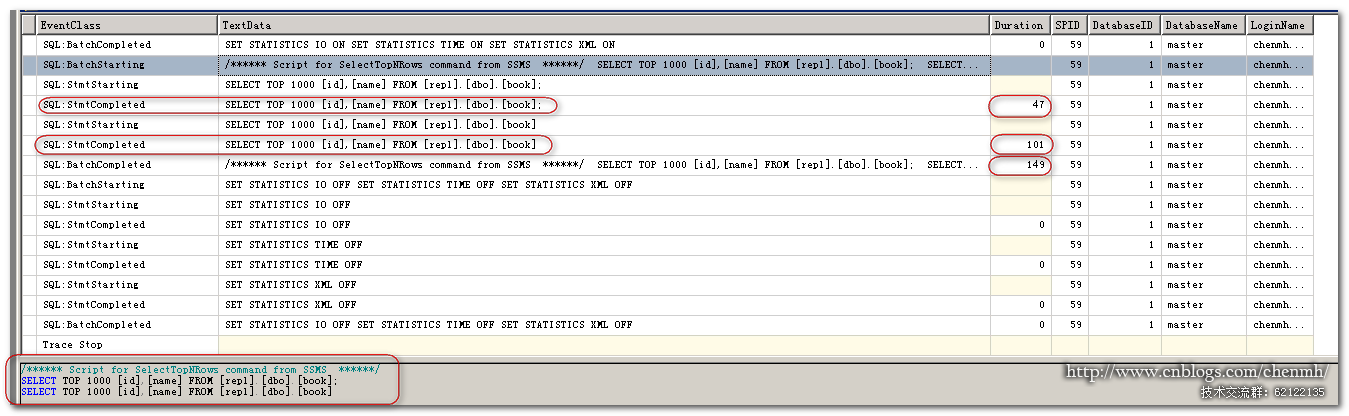

這次我把兩個select語句放在一起來執行,可以從batch事件中可以看到它記錄的整個批處理的SQL同時還包括相關註釋,同時整個批處理兩個TSQL作為一條事件記錄,而stmt事件記錄具體的TSQL語句把兩個TSQL語句作為兩條記錄來記錄。同時還可以發現兩個TSQL的Duration相加是小於整個批處理的duration的,這也是正常的整個批處理在sql編譯分析執行這塊肯定比單個TSQL需要耗費更多的時間,但是相差也是非常的小。
batchcompleted事件多用於引擎優化顧問,而stmtcompleted事用於分析單個TSQL語句。同樣Stored分類裡面的starting事件和completed事件和TSQL裡面的是一樣的意思。
事件列
列舉常用的事件列
TextData:文本詳細信息,比如詳細的執行SQL語句等等。
ApplicationName:連接SQLSever的客戶端應用程式名稱。
NTUserName:windows用戶名
LoginName:SQLServer登入用戶名。
CPU:事件占用的CPU時間,在圖形化界面但是是毫秒(千分之一秒或 10-3 秒),在文本文件或者資料庫表中單位是微妙(百萬分之一秒或 10-6 秒)。
Reads:執行邏輯讀的次數。
Writes:物理磁碟寫入的次數。
Duration:事件的持續時間,也就是統計信息裡面顯示的占用時間,在圖形化界面但是是毫秒(千分之一秒或 10-3 秒),在文本文件或者資料庫表中單位是微妙(百萬分之一秒或 10-6 秒)
ClientProcessID:調用SQLServer的應用程式進程ID。
SPID:SQLServer為連接分配的資料庫進程ID,也就是sys.processes裡面記錄的進程ID。
StartTime:事件的開始時間。
EndTime:事件的結束時間。
DBUserName:客戶端的sqlserver用戶名。
DatabaseID:如果指定了USE database就是指定的資料庫id,否則就是預設的資料庫id(也就是master的資料庫id)。所以該列的作用不是很大。
Error:事件的錯誤號,通常是sysmessage中存儲的錯誤號。
ObjectName:正在引用的對象名稱。
三、自帶跟蹤模板
工具自帶了幾個比較實用的跟蹤模板,一般的跟蹤都可以直接使用自帶的跟蹤模板解決,同時自己也可以創建自定義的跟蹤事件和跟蹤屬性保存成模板供以後使用。
SP_Counts:計算已運行的存儲過程數,並且按存儲過程的名稱進行分組統計,此模板可以分析某時間段存儲過程的行為。
Standard:記錄所有存儲過程和T-SQL語句批處理運行的時間,當你想要監視常規資料庫伺服器活動時即可使用該模板,一般的跟蹤需要使用該模板就可以解決,這也是預設的模板。
TSQL:記錄客戶端提交給sqlserver的所有T-SQL語句的的內容和開始時間,通常使用該模板用於程式調試。
TSQL_Duration:記錄客戶端提交給sqlserver的所有T-SQL語句批處理信息以及執行這些語句所需的時間(毫秒),並按時間進行分組,使用該模板可以分析執行慢的查詢,此模板的跟蹤記錄可以用於資料庫引擎優化顧問分析使用。
TSQL_Grouped:按提交客戶端和登入用戶進行分組記錄所有提交給SQLServer的T-SQL批處理語句及其開始時間,此模板用於分析某個客戶或者用戶執行的查詢。
TSQL_Locks:記錄所有開始和完成的存儲過程和T-SQL語句,同時記錄死鎖信息,此模板用於跟蹤死鎖。
TSQL_Replay:記錄有關已發出的T-SQL語句的詳細信息,此模板記錄重播跟蹤所需的信息,此模板可執行跌到優化,例如基準測試。
TSQL_SPs:記錄有關執行的所有存儲過程的詳細信息,此模板可以分析存儲過程的組成步驟。如果你懷疑正在重新編譯存儲過程,請添加SP:Recomple事件
Tuning:記錄有關存儲和T-SQL語句批處理的信息以及執行這些語句所需的時間(毫秒),使用此模板生產跟蹤輸出可用於資料庫引擎優化顧問工作負載來優化索引、優化性能。此模板和TSQL_Druation相似後者是做了時間分組。
資料庫引擎優化顧問
1.如果需要用資料庫引擎優化顧問分析跟蹤事件記錄必須捕獲了以下跟蹤事件:
-
RPC:Completed
-
SQL:BatchCompleted
-
SP:StmtCompleted
也可以使用這些跟蹤事件的 Starting 版本。 例如,SQL:BatchStarting。 但是,這些跟蹤事件的 Completed 版本包括 Duration 列,它能使資料庫引擎優化顧問更有效地優化工作負荷。 資料庫引擎優化顧問不優化其他類型的跟蹤事件。
2.包含 LoginName列
資料庫引擎優化顧問在優化過程中提交顯示計劃請求。 當包含 LoginName 數據列的跟蹤表或跟蹤文件被用作工作負荷時,資料庫引擎優化顧問將模擬 LoginName 中指定的用戶。 如果沒有為此用戶授予 SHOWPLAN 許可權(該許可權使用戶能夠為跟蹤中包含的語句執行和生成顯示計劃),資料庫引擎優化顧問將不會優化這些語句。
避免為跟蹤的 LoginName 列中指定的每個用戶授予 SHOWPLAN 許可權
-
通過從未優化的事件中刪除 LoginName 列來創建新的工作負荷,然後只將未優化的事件保存到新的跟蹤文件或跟蹤表中。
-
將不帶 LoginName 列的新工作負荷重新提交到資料庫引擎優化顧問。
資料庫引擎優化顧問將優化新的工作負荷,因為跟蹤中未指定登錄信息。 如果某個語句沒有相應的 LoginName,資料庫引擎優化顧問將通過模擬啟動優化會話的用戶(sysadmin 固定伺服器角色或 db_owner 固定資料庫角色的成員)來優化該語句。
3.資料庫引擎優化顧問不能執行下列操作:
- 建議對系統表建立索引。
- 添加或刪除唯一索引或強制 PRIMARY KEY 或 UNIQUE 約束的索引。
- 優化單用戶資料庫。
4.資料庫引擎優化顧問具有下列限制:
- 資料庫引擎優化顧問通過數據採樣收集統計信息。因此,在相同的工作負荷上重覆運行該工具可能生成不同的結果。
- 資料庫引擎優化顧問不能用於優化 Microsoft SQL Server 7.0 或更早版本的資料庫中的索引。
- 如果為優化建議指定的最大磁碟空間超過了可用空間,資料庫引擎優化顧問將使用指定的值。但是,當您執行建議腳本來實施它時,如果未先添加更多磁碟空間,則腳本會失敗。可以使用
dta 實用工具的 -B
選項指定最大磁碟空間,也可以通過在“高級優化選項”對話框中輸入值來指定最大磁碟空間。
- 為了安全起見,資料庫引擎優化顧問不能優化駐留在遠程伺服器上的跟蹤表中的工作負荷。若要解除此限制,可以選擇以下選項之一:
- 使用跟蹤文件而不使用跟蹤表。
- 將跟蹤表複製到遠程伺服器。
- 使用跟蹤文件而不使用跟蹤表。
- 當強制實施約束時,例如為優化建議指定最大磁碟空間時強制的約束(通過使用 -B
選項或“高級優化選項”對話框),資料庫引擎優化顧問可能會被迫刪除某些現有的索引。在此情況下,生成的資料庫引擎優化顧問建議可能生成負的預期提高值。
- 指定限制優化時間的約束時(通過使用 dta 實用工具的 -A 選項或通過選擇“優化選項”選項卡上的“限制優化時間”),資料庫引擎優化顧問可能超過該時間限制,以便針對到當時為止已處理的工作負荷,生成精確預期的提高值和分析報告。
5.資料庫引擎優化顧問可能在下列情況下不提供建議:
- 正在優化的表所包含的數據頁數少於 10。
- 建議的索引對當前物理資料庫設計的查詢性能預計帶來的提高值不夠。
- 運行資料庫引擎優化顧問的用戶不是 db_owner 資料庫角色或 sysadmin 固定伺服器角色的成員。工作負荷中的查詢在運行資料庫引擎優化顧問的用戶的安全上下文中進行分析。該用戶必須是 db_owner 資料庫角色的成員。
6.資料庫引擎優化顧問可能在下列情況下不提供分區建議:
- 未啟用 xp_msver 擴展存儲過程。此擴展存儲過程用於提取要優化的資料庫所在伺服器上的處理器數目以及可用記憶體。請註意,安裝 SQL Server 後,預設情況下,此擴展存儲過程處於打開狀態。有關詳細信息,請參閱瞭解外圍應用配置器和 xp_msver (Transact-SQL)。
7.性能註意事項
在分析過程中,資料庫引擎優化顧問可能占用相當多的處理器及記憶體資源。若要避免降低生產伺服器速度,請採用下列策略之一:
- 在伺服器空閑時優化資料庫。資料庫引擎優化顧問可能影響維護任務性能。
- 使用測試伺服器/生產伺服器功能。有關詳細信息,請參閱減輕生產伺服器優化負荷。
- 指定資料庫引擎優化顧問僅分析物理資料庫設計結構。資料庫引擎優化顧問提供許多選項,但是請僅指定所需選項。
註意:由於資料庫引擎優化顧問進行性能優化時也是將負載記錄中的語句執行一篇查詢分析執行計劃的操作,所以對伺服器同樣存在壓力。特別是對於大的負載分析可能需要分析一個小時甚至更長,這樣可能會持續對伺服器造成壓力,所以避免在業務高峰期進行使用引擎優化顧問進行負載分析。
實例
接下來就列舉三個案例,使用資料庫引擎優化顧問來分析跟蹤記錄優化索引的案例、監控死鎖的案例、創建自定義跟蹤模板案例。
案例1:優化索引
1.創建測試數據
--創建測試表 CREATE TABLE [dbo].[book]( [id] [int] NOT NULL PRIMARY KEY, [name] [varchar](50) NULL); --插入10W條測試數據 DECLARE @id int SET @id=1 WHILE @id<100000 BEGIN INSERT INTO book values(@id,CONVERT(varchar(20),@id)) SET @id=@id+1 END;
2.創建跟蹤
這裡使用預設的跟蹤模板“tuning”
1.創建好跟蹤後點擊運行即可,事件選擇這裡保持預設


2.執行SQL
SELECT * FROM book WHERE name='10001';
由於name欄位沒有建索引所以該查詢執行計劃分析過後會返回創建name欄位的索引,通過引擎優化顧問分析同樣如此
3.停止跟蹤
在使用資料庫引擎優化顧問分析負載跟蹤之前必須先停止跟蹤。
4.打開資料庫引擎優化顧問
可以直接在profile的工具欄選擇打開,“文件”選擇剛纔的跟蹤文件,“負載資料庫”選擇需要進行優化的資料庫,“選擇要優化的資料庫和表”也就需要優化的資料庫的相關表。優化選項沒有特別的需求選擇預設即可,然後點擊“開始分析”。


引擎優化顧問會自動生成創建索引的腳步,同時還給出了創建該索引之後預計性能可以提供的百分比,如果同時存在很多表的索引建議可以勾選需要保存的建議保存成sql文件在“開始分析”欄旁邊有一個保存建議的按鈕可以將建議保存成sql文件。
建議:
1.資料庫引擎優化顧問給出的建議不是每一個都是對的,自己對比該SQL的執行頻率來判斷是否需要創建該索引,比如我當前這個SQL如果我這個SQL只執行了一次後面就不會再執行了那麼這個索引就沒必要創建了。
2.修改引擎優化顧問給出的索引名,資料庫引擎優化顧問給出的創建索引的索引名不夠直觀,建議自己手動更改,比如改成“ix_book_name”,“索引標示_表名_欄位描述”的規則。
3.用來分析的文件不要太大否則可能會分析不完成,不要在業務高峰期進行分析。
案例2:監控死鎖
1.創建跟蹤
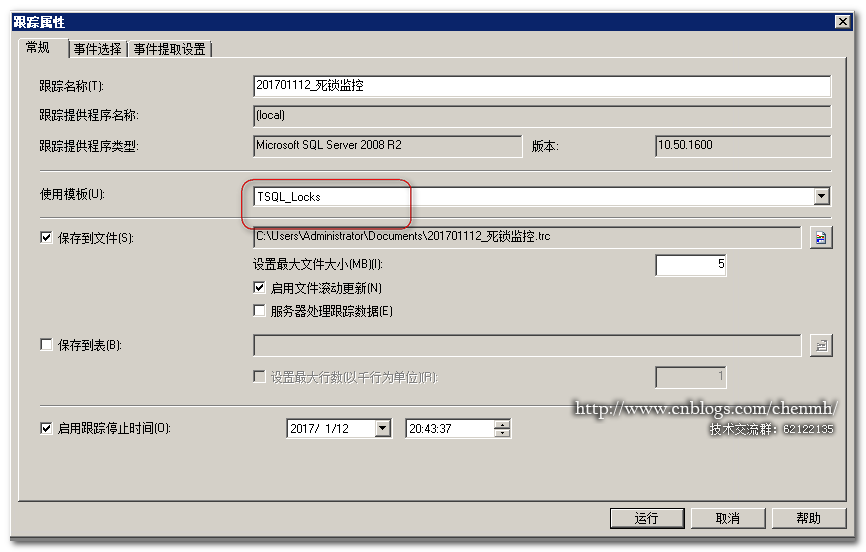
模板選擇自帶的“TSQL_Locks”模板,運行跟蹤。
2.執行SQL
打開兩個會話視窗分表執行如下SQL,先在會話1執行然後在10S內在會話2中執行,兩個會話擁有各自的排他鎖同時又去申請對方擁有的排他鎖造成死鎖。
會話1執行:當前會話1是62
BEGIN TRANSACTION UPDATE book SET name='a' WHERE ID=10 --延時10s執行 waitfor delay '0:0:10' UPDATE book SET name='a' WHERE ID=100
會話2執行:當前會話2是
BEGIN TRANSACTION UPDATE book SET name='b' WHERE ID=100 --延時20執行 waitfor delay '0:0:20' UPDATE book SET name='b' WHERE ID=10
msms客戶端返回的錯誤消息顯示當前62會話作為死鎖的犧牲品。

3.跟蹤分析死鎖
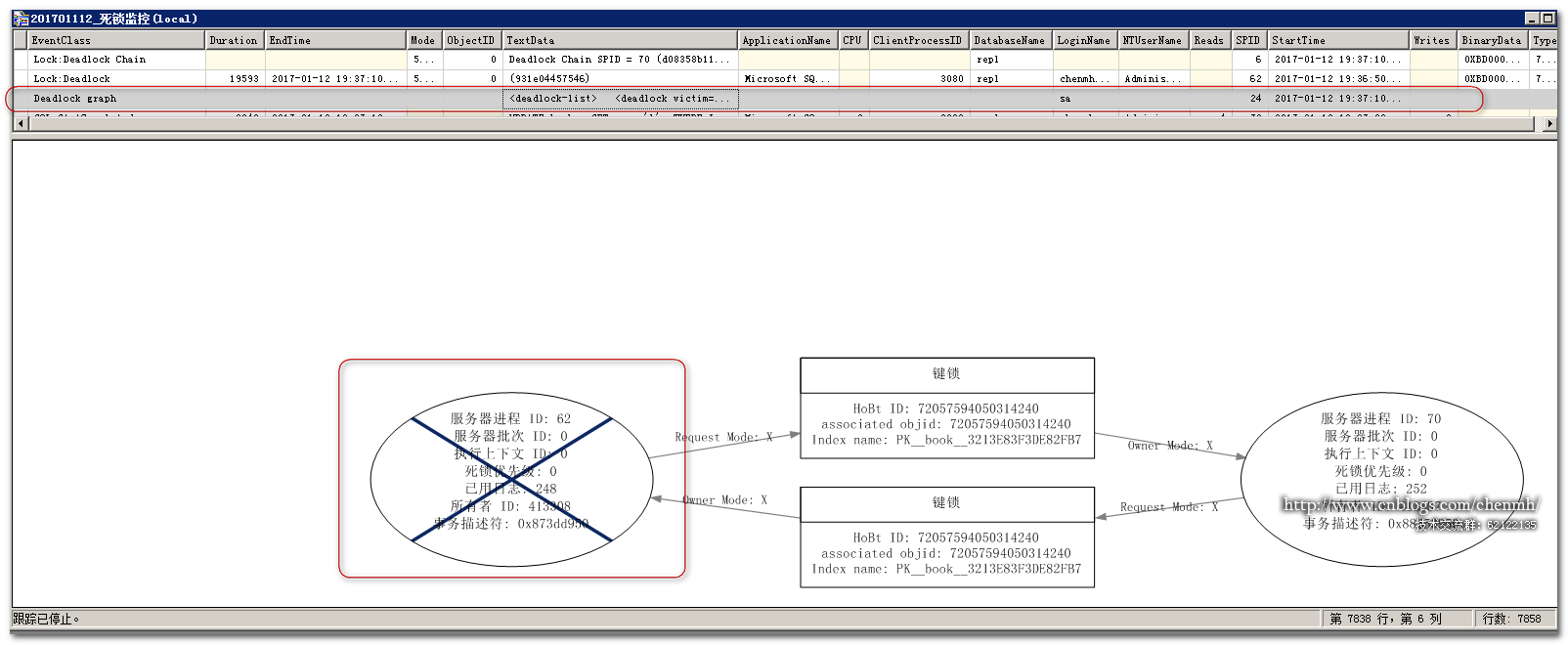
死鎖跟蹤事件使用圖形和直觀的返回了兩個會話的死鎖,其中62會話用了一個×表示當前的會話是死鎖的犧牲品。
案例三:創建自定義跟蹤模板
標準模板就是一個比較好的參考模板,比如我們對執行語句進行監控就可以參考標準模板在其基礎上修改保存成自己的模板。
1.創建TSQL語句跟蹤



2.創建跟蹤模板
停止當前的TSQL跟蹤,選擇“文件”-“另存為跟蹤模板”就可以保存成自己的跟蹤模板。
3.列篩選
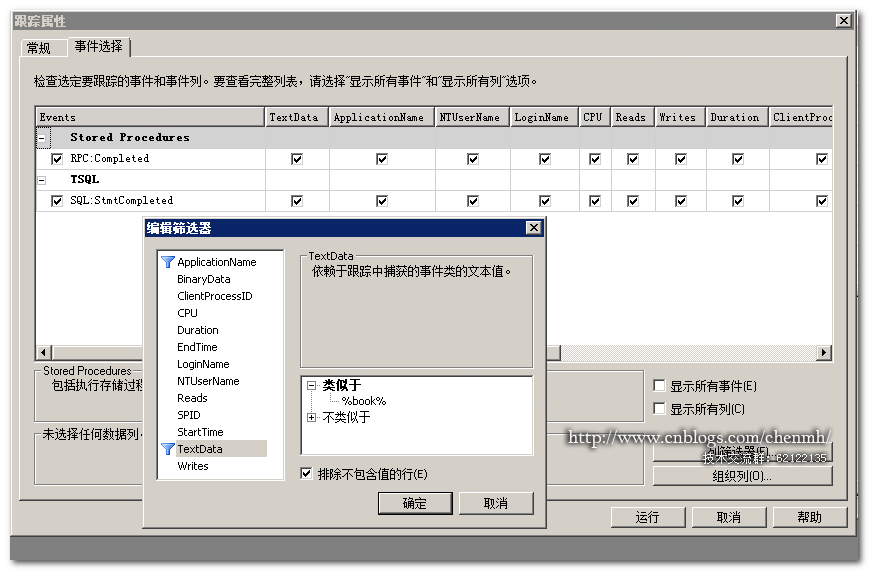
當前是篩選跟蹤的TSQL語句中包含book,這裡的列篩選這執行 where like 的語法類似。
整形列的話就不需要帶模糊條件:
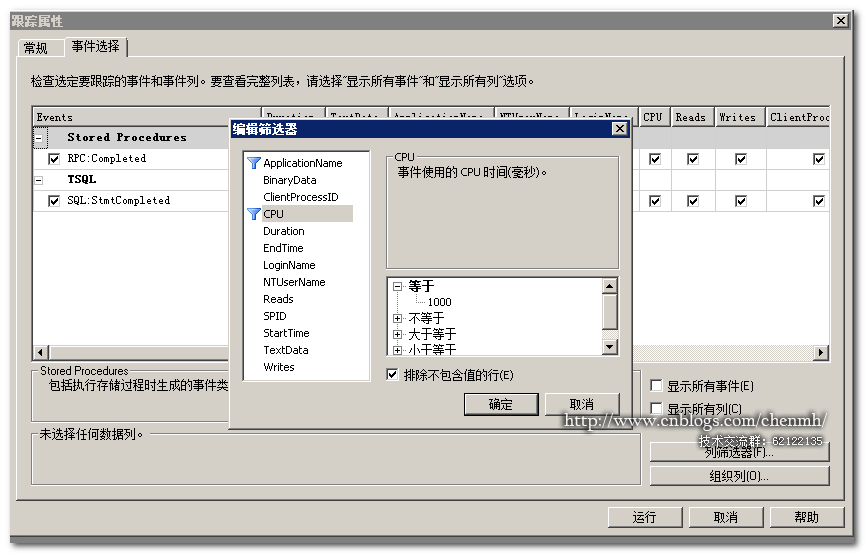
註意:如果要取消列篩選記得把剛纔的篩選條件刪除同時把“排除不包含值的行” 的勾選也去除,記得兩者都要去掉否則跟蹤還是包含篩選的跟蹤。
4.列組織
列組織其實就是按某列進行分組顯示跟蹤,類似select查詢裡面的group by操作。比如我當前按持續時間進行分組跟蹤。

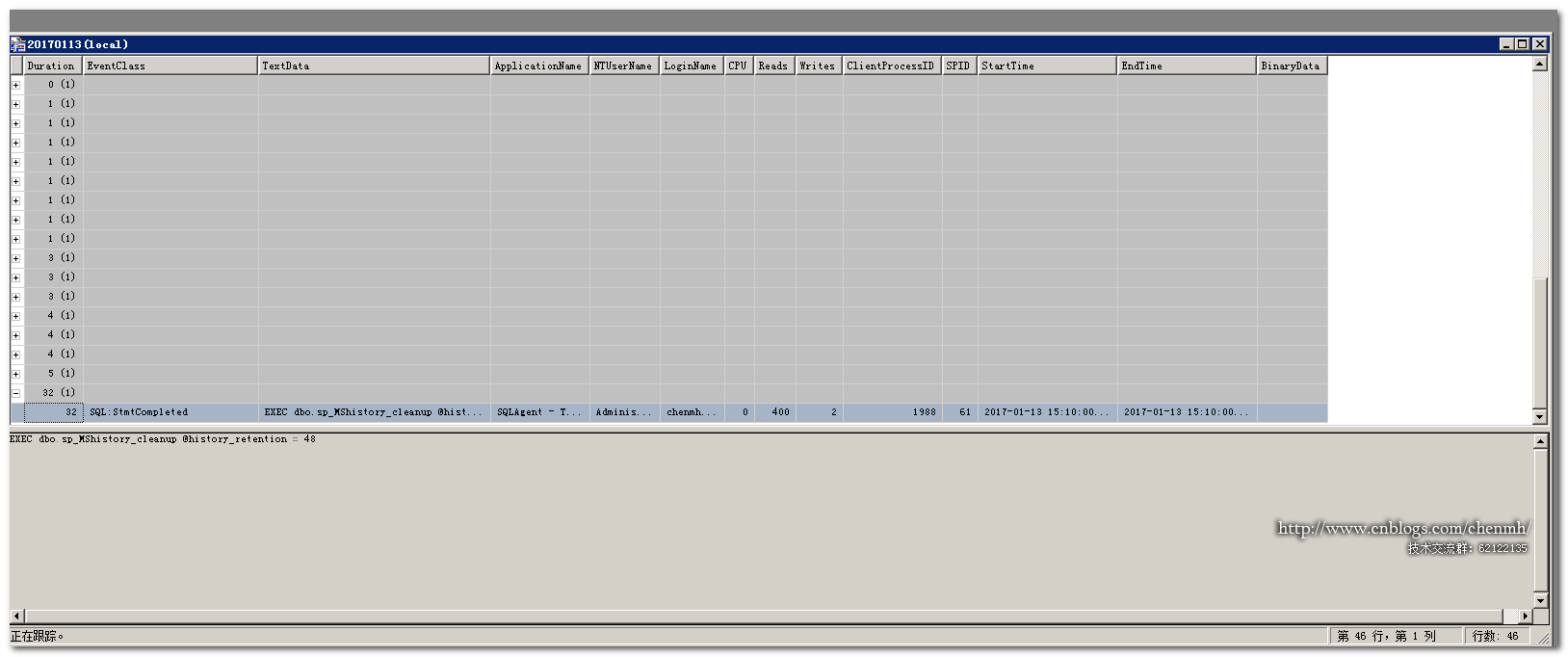
通過對持續時間進行分組,相同的持續時間會放在一個分組裡。
總結
由於篇幅有限列舉了一些簡單常用的操作,其它的分類監控的方法類似有興趣可以多去研究,profile是非常實用且界面化很好的監控工具這也是SQLServer獨特的條件,應該熟練運用。
如果覺得文章對你有幫助麻煩把文章推薦上去讓更多的人看到
|
備註: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須註明文章來源,且在文章開頭明顯處給明鏈接。 《歡迎交流討論》 |


