
SQL Server 2016支持哈希查找,用戶可以在記憶體優化表(Memory-Optimized Table)上創建Hash Index,使用Hash 查找演算法,實現數據的極速查找。在使用上,Hash Index 和B-Tree索引的區別是:Hash Index 是無序查找,Index Key必須 ...
SQL Server 2016支持哈希查找,用戶可以在記憶體優化表(Memory-Optimized Table)上創建Hash Index,使用Hash 查找演算法,實現數據的極速查找。在使用上,Hash Index 和B-Tree索引的區別是:Hash Index 是無序查找,Index Key必須全部作為Filter,而B-Tree索引是有序查找,不需要Index Key都作為Filter,只需要前序欄位存在即可;在存儲結構上,Hash Index使用Hash Table實現,存在Hash 衝突,而B-Tree索引的結構是平衡樹,存在頁拆分,碎片問題。
一,Hash 查找演算法
在《數據結構》課程中,Hash查找的演算法是:以關鍵字k為自變數,通過一個映射函數h,計算出對應的函數值y=h(k)(y稱作哈希值,或哈希地址),根據函數值y,將關鍵字k存儲在數組(bucket數組)所指向的鏈表中。在進行哈希查找時,根據關鍵字,使用相同的函數h計算哈希地址h(k),然後直接定址相應的Hash bucket,直接到對應的鏈表中取出數據。因此,Hash 查找演算法的數據結構由Hash Bucket數組,映射函數f和數據鏈表組成,通常將Bucket數組和數據鏈表稱作Hash Table,如圖,Hash Table由5個buckets和7個數據結點組成:

哈希查找的時間複雜度是O(n/m),n是指數據結點的數量,m是bucket的數量,在理想情況下,Hash Bucket足夠多,Hash函數不產生重覆的Hash Value,哈希查找的時間複雜度最優到達O(1),但是,在實際應用中,哈希函數有一定的幾率出現重覆的哈希地址,產生哈希衝突,時間複雜度會低於O(n/m);在最差的情況下,時間複雜度是O(n)。
二,Hash Index的結構
Hash Index使用Hash查找演算法實現,SQL Server內置Hash函數,用於所有的Hash Index,因此,Hash Index就是Hash Table,由Hash Buckets數組和數據行鏈表組成。創建Hash Index時,通過Hash函數計算Index Key的Hash地址,Hash地址不同的數據行指向不同的Bucket,Hash地址相同的數據行指向相同的Bucket,如果多個數據行的Hash地址相同,都指向同一個Bucket,那麼將這些數據行鏈接在一起,組成一個鏈表。
A hash index consists of an array of pointers, and each element of the array is called a hash bucket. The index key column in each row has a hash function applied to it, and the result of the function determines which bucket is used for that row. All key values that hash to the same value (have the same result from the hash function) are accessed from the same pointer in the hash index and are linked together in a chain. When a row is added to the table, the hash function is applied to the index key value in the row. If there is duplication of key values, the duplicates will always generate the same function result and thus will always be in the same chain.
舉例說明,假定哈希函數是h(k)=Length(k),用於計算Index Key的字元個數,在記憶體優化表(Name,City)上創建Hash Index,Index ptr指向鏈表中的下一個數據行,如果沒有下一個數據行,那麼該指針為NULL:

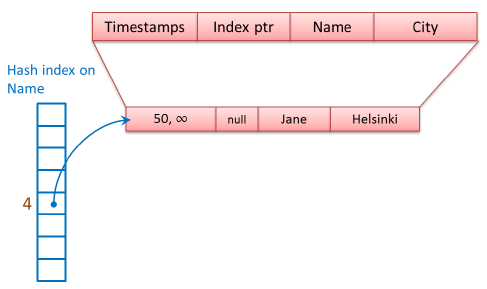
1,以Name為Index Key創建Hash Index
第一個數據行的Name是“Jane”,HashValue是4,將該行數據映射到下標為4的Bucket中(Bucket數組的第五個元素),由於該數據行是第一個數據結點,Index ptr為NULL。
第二個數據行,Name值是“Greg”,HashValue是4,映射到下標為4的Bucket中,和第一個數據行鏈接在一起,組成一個鏈表(Chain),插入數據結點時,使用頭部插入法,新的數據節點作為頭結點,將頭節點的Index ptr(next pointer)指針指向數據鏈表的第一個數據結點,如圖,新的頭結點“Greg”的Index ptr指向第一個數據行“Jane”。
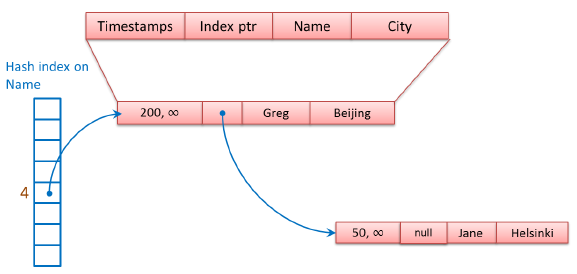
2,創建第二個Hash Index,以City為Index Key
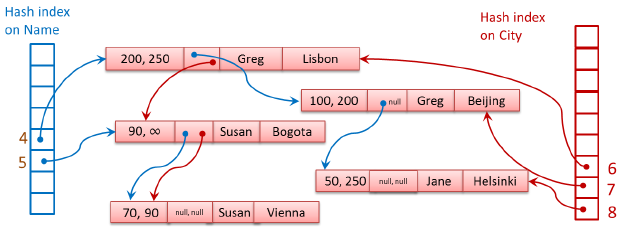
當創建第二個Hash Index時,每個數據行結構中包含兩個Index ptr指針,都用於指向下一個數據節點(Next Pointer):第一個Index ptr用於Index Key為Name的Hash Index,當出現相同的Hash Value時,該指針指向鏈表中下一個數據行,使數據行鏈接到一起組成鏈表;第二個Index ptr用於Index Key為City的Hash Index,指向鏈表中下一個數據行。
因此,當創建一個新的Hash Index時,在數據結構上,SQL Server需要創建Hash Buckets數組,併在每個數據行中增加一個Index ptr欄位,根據Index Key為Index ptr賦值,組成一個新數據行鏈表,但是數據行的數量保持不變。
3,Hash 函數
在創建Hash Index時,不需要編寫Hash 函數,SQL Server內置Hash函數:
- 內置的Hash函數產生的HashValue是隨機和不可預測的,適用於所有的Hash Index;
- 內置的Hash函數是確定性的,相同的Index Key總是映射到相同的Bucket;
- 有一定的幾率,多個Index Key會映射到相同的bucket中;
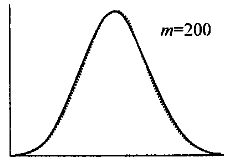
- 哈希函數是均衡的,產生的Hash Value服從泊松分佈;
泊松分佈不是均勻分佈,Index Key不是均勻地分佈在Hash bucket數組中。例如,有n個Hash Bucket,n個不同的Index Key,泊松分佈產生的結果是:大約有1/3的Hash Bucket是空的,大約1/3的Hash bucket存儲一個Index Key,剩下1/3的Hash Buckets存儲2個Index Key。
4,Hash Index的鏈表長度
不同的Index Key,經過hash函數映射之後,可能生成相同的Hash Value,映射到相同的bucket中,產生 Hash 衝突。Hash演算法,將映射到相同Bucket的多個Index Key組成一個鏈表,鏈表越長,Hash Index查找性能越差。
在DMV:sys.dm_db_xtp_hash_index_stats (Transact-SQL)中,表示Hash Index鏈長的欄位有:avg_chain_length 和 max_chain_length ,鏈長應保持在2左右;鏈長過大,表明太多的數據行被映射到相同的Bucket中,這會顯著影響Hash Index的查詢性能,導致鏈長過大的原因是:
- 總的Bucket數量少,導致不同的Index Key映射到相同的Bucket上;
- 如果空的Bucket數量大,但鏈長過大,這說明,Hash Index存在大量重覆的Index Key;相同的Index Key被映射到相同的bucket;
三,創建Hash Index
在記憶體優化表上創建Index,不能使用Create Index命令,SQL Server 2016支持兩種方式創建索引:
1,在創建記憶體優化表時創建Hash Index
創建Hash Index的語法是:
INDEX index_name [ NONCLUSTERED ] HASH WITH (BUCKET_COUNT = bucket_count)
創建Hash Index的示例:


--create memory optimized table create table [dbo].[products] ( [ProductID] [bigint] not null, [Name] [varchar](64) not null, [Price] decimal(10,2) not null, [Unit] varchar(16) not null, [Description] [varchar](max) null, constraint [PK__Products_ProductID] primary key nonclustered hash ([ProductID])with (bucket_count=2000000) ,index idx_Products_Price nonclustered([Price] desc) ,index idx_Products_Unit nonclustered hash(Unit) with(bucket_count=40000) ) with(memory_optimized=on,durability= schema_and_data) goView Code
2,使用Alter Table命令創建Hash Index
alter table [dbo].[products] add index hash_idx_Products_Name nonclustered hash(name)with(bucket_count=40000);
四,Hash Index的特點
總結Hash Index的特點:
- Hash Index使用Hash Table組織Index 結構,每一個數據節點都包含一個指針,指向數據行的記憶體地址;
- Hash Index是無序的,適合做單個數據行的Index Seek;
- 只有當Hash Index Key全部出現在Filter中,SQL Server才會使用Hash Index Seek操作查找相應的數據行,如果缺失任意一個Index Column,那麼SQL Server都會執行Full Table Scan以獲取符合條件的數據行。例如,創建Hash Index時指定N個column,那麼SQL Server對這N個column計算Hash Value,映射到相應的bucket上,所以,只有當這N個Column都存在時,才能定位到對應的bucket,進而查找相應的數據結點;
參考文檔:
Guidelines for Using Indexes on Memory-Optimized Tables
Troubleshooting Common Performance Problems with Memory-Optimized Hash Indexes


