
Sqlserver 高併發和大數據存儲方案 隨著用戶的日益遞增,日活和峰值的暴漲,資料庫處理性能面臨著巨大的挑戰。下麵分享下對實際10萬+峰值的平臺的資料庫優化方案。與大家一起討論,互相學習提高! 案例:游戲平臺. 1、解決高併發 當客戶端連接數達到峰值的時候,服務端對連接的維護與處理這裡暫時不做討 ...
Sqlserver 高併發和大數據存儲方案
隨著用戶的日益遞增,日活和峰值的暴漲,資料庫處理性能面臨著巨大的挑戰。下麵分享下對實際10萬+峰值的平臺的資料庫優化方案。與大家一起討論,互相學習提高!
案例:游戲平臺.
1、解決高併發
當客戶端連接數達到峰值的時候,服務端對連接的維護與處理這裡暫時不做討論。當多個寫請求到資料庫的時候,這時候需要對多張表進行插入,尤其一些表 達到每天千萬+的存儲,隨著時間的積累,傳統的同步寫入數據的方式顯然不可取,經過試驗,通過非同步插入的方式改善了許多,但與此同時,對讀取數據的實時性也需要做一定的犧牲。
非同步的方式有很多,目前採取的方式是通過作業每隔一段時間(5min、10min..看需求設定)將臨時表的數據轉到真實表。
1.已有原始表A 也是在讀取的時候真正用到的表。
2.建立與原始表A同結構的B和C,用來作數據的中轉處理,同步流程是C->B->A。
3.建立同步數據的作業Job1和記錄Job1運行狀態的表,在同步的時候比較關鍵的是需要檢查Job1的當前狀態,如果當前正在將B的數據同步到A,則把服務端過來的數據存到C,然後再把數據導入到B,等到下一次Job執行的時候再將這批數據轉到A。如圖1:
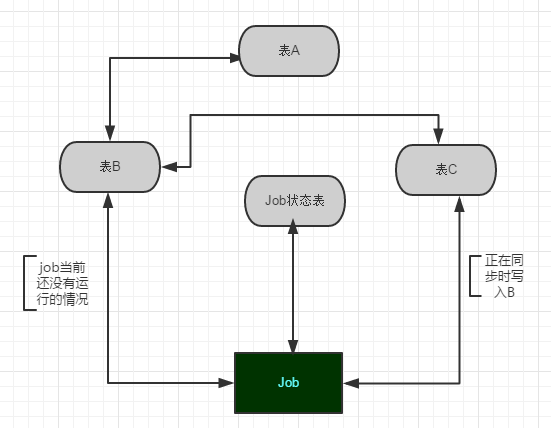 圖1
圖1
同時,為保萬無一失和便於排查問題,應該用一個記錄整個資料庫實例的存儲過程,在較短的時間檢查作業執行結果,如果遇到異常失敗的,應該及時通過其他方式通知到相關人員。如寫入到發郵件和簡訊表,讓一個Tcp的通知程式定時讀取發送等等。
註:如果一天的數據達到幾十個G,如果又對這個表有查詢要求(分區下麵會提到),下策之一:
可將B同時同步到多台伺服器分擔下查詢壓力,減少資源的競爭。因為整個資料庫的資源是有限的,如插入操作,會先獲得一個共用鎖,然後通過聚集索引定位到某一行數據,再升級為意向鎖,而sqlserver對鎖的維護根據數據的大小需要申請不同的記憶體,造成了資源的競爭。所以應該儘可能的將讀和寫分開,可根據業務模型分,可根據設定的規則分;在平臺性的項目中應該優先保證數據能有效的插入。
在不可避免的查詢大數據肯定會耗用大量的資源,如遇到批量刪除的時候,可以換成以迴圈分批次(如一次2000條)的方式,這樣不至於這個進程導致整個庫掛掉,衍生出一些無法預計的bug。經實踐,有效可行,只是犧牲了存儲空間。也可根據查詢需求將表裡數據量大的欄位拆分出來到新表,當然這些也要根據每個業務場景結合需求來設定,設計出適合而並不需要華麗的方案即可。
2、解決存儲問題
如果每天單表的數據都達到了幾十個G,改善存儲方案自然迫不及待了。現分享下自有的方案,在暴漲的數據摧殘之下,仍堅守在一線!現舉例對自有環境分享拙見:
現有數據表A,單表每天新增數據30G,在存儲的時候採用非同步將數據同步的方式,有的不能清除數據的表,在分區後還可分文件組,將文件組分配到不同的磁碟中,減少IO資源的競爭,保障現有資源的正常運行。現結合需求保留歷史數據5天:
1這時需要通過作業job根據分區函數去生成分區方案,如根據userid或者時間欄位來分區;
· 2.將表分區後,查詢可以通過對應的索引,快速定位到某一段分區;
3通過作業合併分區將不要的分區數據轉移到相同結構和索引的表,然後清除這個表的數據。
如圖2:
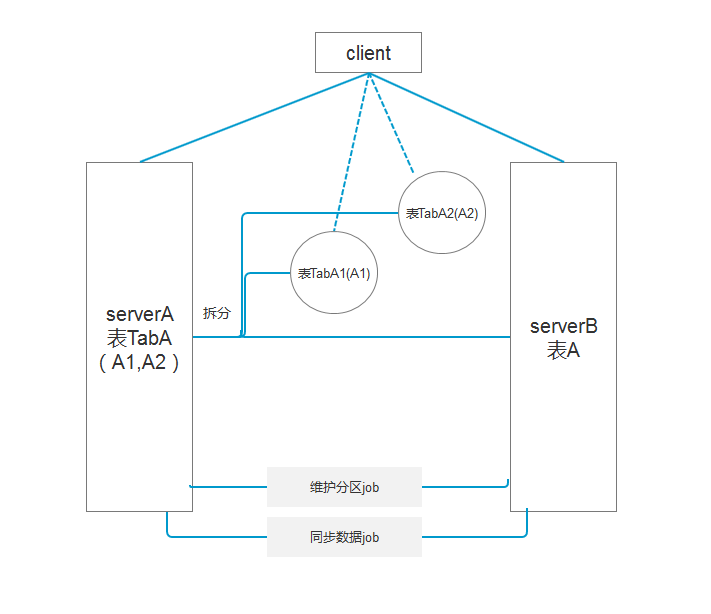
圖2
通過sql查詢跟蹤捕捉到查詢耗時長的,以及通過sql自帶的存儲過程sp_lock或視圖dm_tran_locks、dblockinfo查看當前實例存在的鎖的類型和粒度。
定位到具體的查詢語句或者存儲過程之後,對症下藥!藥到病除!
當然,仁者見仁,智者見智-_-

