
一、python介紹 Python 的創始人為Guido van Rossum。Guido為了打發聖誕節的無趣,於1989年發明,在荷蘭國家數學和電腦科學研究所設計出來的(作為ABC 語言的一種繼承),之所以起名Python,是因他是Monty Python的喜劇團體的愛好者。Python第一個公 ...
一、python介紹
Python 的創始人為Guido van Rossum。Guido為了打發聖誕節的無趣,於1989年發明,在荷蘭國家數學和電腦科學研究所設計出來的(作為ABC 語言的一種繼承),之所以起名Python,是因他是Monty Python的喜劇團體的愛好者。Python第一個公開發行版發行於1991年。現在,全世界差不多有600多種編程語言,但流行的編程語言也就那麼20來種。如果聽說過TIOBE排行榜,那就一定可以知道編程語言的大致流行程度。下圖是2017年最新發佈的編程語言排行榜 TOP20 榜單,可以很明顯的看出python已經越來越得到開發人員的認可。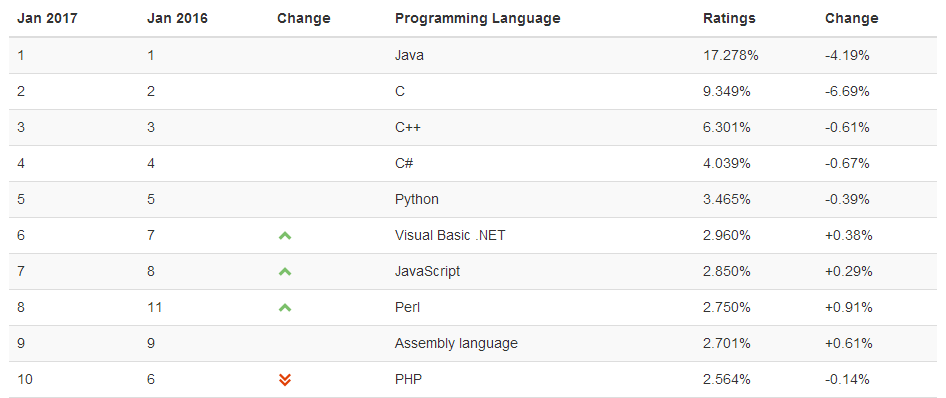
上圖中排名前五的語言中,C、C++、C#都是編譯型語言,python與java則都是解釋型語言,那麼什麼是編譯型語言,什麼是解釋型語言?
編譯型語言:程式在執行之前需要一個專門的編譯過程,把程式編譯成為機器語言的文件,運行時不需要重新翻譯,直接使用編譯的結果就行了。
優點是只需要編譯一次,運行時不需要編譯,所以程式執行效率高,缺點相對就很明顯,跨平臺性差,要針對不同平臺生成不同的執行文件。
解釋型語言:程式不需要編譯,程式在運行時才翻譯成機器語言,每執行一次都要翻譯一次。
優點是有良好的平臺相容性,直接修改代碼後快速部署就可以直接運行,缺點是由於每次運行都需要編譯一次,性能上相對編譯型語言自然就會差一些。
二、python的優缺點
python的優點:
1、簡單:Python是一種代表簡單主義思想的語言。閱讀一個良好的Python程式就感覺像是在讀英語一樣。它使你能夠專註於解決問題而不是去搞明白語言本身。
2、易學:Python極其容易上手,因為Python有極其簡單的說明文檔。
3、速度快:Python 的底層是用 C 語言寫的,很多標準庫和第三方庫也都是用 C 寫的,運行速度非常快。
4、免費、開源:Python是FLOSS(自由/開放源碼軟體)之一。使用者可以自由地發佈這個軟體的拷貝、閱讀它的源代碼、對它做改動、把它的一部分用於新的自由軟體中。FLOSS是基於一個團體分享知識的概念。
5、高層語言:用Python語言編寫程式的時候無需考慮諸如如何管理你的程式使用的記憶體一類的底層細節。
6、可移植性:由於它的開源本質,Python已經被移植在許多平臺上(經過改動使它能夠工作在不同平臺上)。
7、解釋性:一個用編譯性語言比如C或C++寫的程式可以從源文件(即C或C++語言)轉換到一個你的電腦使用的語言(二進位代碼,即0和1)。這個過程通過編譯器和不同的標記、選項完成。
8、面向對象:Python既支持面向過程的編程也支持面向對象的編程。
9、可擴展性:如果需要一段關鍵代碼運行得更快或者希望某些演算法不公開,可以部分程式用C或C++編寫,然後在Python程式中使用它們。
10、可嵌入性:可以把Python嵌入C/C++程式,從而向程式用戶提供腳本功能。
11、規範的代碼:Python採用強制縮進的方式使得代碼具有較好可讀性。而Python語言寫的程式不需要編譯成二進位代碼。
python的缺點:
1、單行語句和命令行輸出問題:很多時候不能將程式連寫成一行,如import sys;for i in sys.path:print i。而perl和awk就無此限制,可以較為方便的在shell下完成簡單程式,不需要如Python一樣,必須將程式寫入一個.py文件。
2、運行速度慢:這裡是指與C和C++相比。
3、代碼無法加密。
三、python2.7 or python3.x
其實對於python的版本選擇,由於以前工作的時候做的工作都是和python2.7打交道所以一直使用的是python2.7;選擇3.x的原因主要有幾點,首先2.7版本於2020年將停止更新服務,再者3.x的相容性、編碼等原因。
四、安裝python
windows下安裝python
下載安裝包:
https://www.python.org/downloads/
安裝:
預設安裝路徑:
C:\PYTHON35
配置環境變數:
1. 右鍵電腦;
2. 屬性;
3. 高級系統設置;
4. 高級;
5. 環境變數;
6. 在第二個框中找到Path雙擊;
7. 將python安裝目錄追加到值中,用;分隔。
五、Hello World!
新建一個hello.py 文件,並輸入:
print("Hello World")
在命令行中執行命令:
python hello.py
即可看到系統返回:
E:\>python hello.py
Hello World!
六、變數
1、變數的作用:
變數是只不過保留的記憶體位置用來存儲值。這意味著,當創建一個變數,那麼它在記憶體中保留一些空間。
根據一個變數的數據類型,解釋器分配記憶體,並決定如何可以被存儲在所保留的記憶體中。因此,通過分配不同的數據類型的變數,你可以存儲整數,小數或字元在這些變數中。
2、變數賦值:
Python的變數不必顯式地聲明保留的存儲器空間。當分配一個值給一個變數的聲明將自動發生。等號(=)來賦值給變數。
操作數=操作符的左邊是變數,操作數=操作符的右側的名稱在變數中存儲的值。例如:
counter = 100 miles = 1000.0 name = "John"
3、命名規則:
變數名只能是字母、數字或者下劃線的任意組合,並且首字母不能是數字,同時也不可以使用以下關鍵字聲明變數:
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import','in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
七、編碼格式
1. ASCII
ASCII(American Standard Code for Information Interchange),是一種單位元組的編碼。電腦世界里一開始只有英文,而單位元組可以表示256個不同的字元,可以表示所有的英文字元和許多的控制 符號。不過ASCII只用到了其中的一半(\x80以下),這也是MBCS得以實現的基礎。
2. MBCS
然而電腦世界里很快就有了其他語言,單位元組的ASCII已無法滿足需求。後來每個語言就制定了一套自己的編碼,由於單位元組能表示的字元太少,而且同時也需要與ASCII編碼保持相容,所以這些編碼紛紛使用了多位元組來表示字元,如GBxxx、BIGxxx等等,他們的規則是,如果第一個位元組是\x80以下,則仍然表示ASCII字元;而如果是\x80以上,則跟下一個位元組一起(共兩個位元組)表示一個字元,然後跳過下一個位元組,繼續往下判斷。
這裡,IBM發明瞭一個叫Code Page的概念,將這些編碼都收入囊中並分配頁碼,GBK是第936頁,也就是CP936。所以,也可以使用CP936表示GBK。
MBCS(Multi-Byte Character Set)是這些編碼的統稱。目前為止大家都是用了雙位元組,所以有時候也叫做DBCS(Double-Byte Character Set)。必須明確的是,MBCS並不是某一種特定的編碼,Windows里根據你設定的區域不同,MBCS指代不同的編碼,而Linux里無法使用 MBCS作為編碼。在Windows中你看不到MBCS這幾個字元,因為微軟為了更加洋氣,使用了ANSI來嚇唬人,記事本的另存為對話框里編碼ANSI就是MBCS。同時,在簡體中文Windows預設的區域設定里,指代GBK。
3. Unicode
後來,有人開始覺得太多編碼導致世界變得過於複雜了,讓人腦袋疼,於是大家坐在一起拍腦袋想出來一個方法:所有語言的字元都用同一種字元集來表示,這就是Unicode。
最初的Unicode標準UCS-2使用兩個位元組表示一個字元,所以你常常可以聽到Unicode使用兩個位元組表示一個字元的說法。但過了不久有人覺得256*256太少了,還是不夠用,於是出現了UCS-4標準,它使用4個位元組表示一個字元,不過我們用的最多的仍然是UCS-2。
UCS(Unicode Character Set)還僅僅是字元對應碼位的一張表而已,比如"漢"這個字的碼位是6C49。字元具體如何傳輸和儲存則是由UTF(UCS Transformation Format)來負責。
一開始這事很簡單,直接使用UCS的碼位來保存,這就是UTF-16,比如,"漢"直接使用\x6C\x49保存(UTF-16-BE),或是倒過來使用\x49\x6C保存(UTF-16-LE)。但用著用著美國人覺得自己吃了大虧,以前英文字母只需要一個位元組就能保存了,現在大鍋飯一吃變成了兩個位元組,空間消耗大了一倍……於是UTF-8橫空出世。
UTF-8是一種很彆扭的編碼,具體表現在他是變長的,並且相容ASCII,ASCII字元使用1位元組表示。然而這裡省了的必定是從別的地方摳出來 的,你肯定也聽說過UTF-8里中文字元使用3個位元組來保存吧?4個位元組保存的字元更是在淚奔……(具體UCS-2是怎麼變成UTF-8的請自行搜索)
另外值得一提的是BOM(Byte Order Mark)。我們在儲存文件時,文件使用的編碼並沒有保存,打開時則需要我們記住原先保存時使用的編碼並使用這個編碼打開,這樣一來就產生了許多麻煩。 (你可能想說記事本打開文件時並沒有讓選編碼?不妨先打開記事本再使用文件 -> 打開看看)而UTF則引入了BOM來表示自身編碼,如果一開始讀入的幾個位元組是其中之一,則代表接下來要讀取的文字使用的編碼是相應的編碼:
BOM_UTF8 '\xef\xbb\xbf' BOM_UTF16_LE '\xff\xfe' BOM_UTF16_BE '\xfe\xff'
並不是所有的編輯器都會寫入BOM,但即使沒有BOM,Unicode還是可以讀取的,只是像MBCS的編碼一樣,需要另行指定具體的編碼,否則解碼將會失敗。
八、數據類型:
1、數字
int(整型):
在32位機器上,整數的位數為32位,取值的範圍為-2**31 ~2**31-1,即-2147483648~2147483648
在64位機器上,整數的位數為64位,取值的範圍為-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(長整型):
和C語言不通,python的長整數沒有指定位寬,即:Python沒有限制長整數數值的大小,但實際上由於機器記憶體有限,我們使用的長整數數值不可能無限大。
在Python2.2開始,如果整數發生溢出,Python會自動將整數數據轉換為長整數,所以如今在長整數數字後面不加字母L也不會導致嚴重後果。
float(浮點型):
浮點數用於處理實數,也就是帶有小數的數字,占用8個位元組(64位),其中52位表示低,11位表示指數,剩下的一位表示符號。
complex(複數):
複數是由實數部分和虛數部分組成,一般形式為x+yj,其中x是複數的實數部分,y是複數的虛數部分,這裡的x和y都是實數。
2、布爾值
真或假 True False
3、字元串
Python中最常用的數據類型,可以使用引號('或“)來創建字元串。
var1 = 'Hello World' var2 = "Python"
下麵介紹一下字元串常用的幾個功能:
(1)移除空白
strip()方法可以移除字元串中頭尾指定的字元,當括弧中為空的時候預設為空格,如下所示:
>>> s = ' abc'
>>> s.strip()
'abc'
也可以在括弧中指定一個值,如下所示:
>>> str = "0000000this is string example....wow!!!0000000";
>>> str.strip('0')
'this is string example....wow!!!'
(2)分割
split()方法通過制定分隔符,對字元串進行切片,如果參數num有置頂值,則只分隔num個字元串
split()的語法:
str.split(str="", num=string.count(str)).
實例:
>>> str = "Line1-abcdef \nLine2-abc \nLine4-abcd"
>>>
>>> str.split()
['Line1-abcdef', 'Line2-abc', 'Line4-abcd']
>>>
>>> str.split(' ',1)
['Line1-abcdef', '\nLine2-abc \nLine4-abcd']
(3)長度
len()可以輸出字元串的長度
>>> str = "Line1-abcdef \nLine2-abc \nLine4-abcd"
>>> len(str)
35
(4)索引
索引獲取特定偏移的元素:
字元串中第一個元素的偏移為0,字元串中最後一個元素的偏移為-1,str[0]獲取第一個元素,str[-2]獲取倒數第二個元素。
>>> str='abcd' >>> str[0] 'a'
>>> str[-1]
'd'
>>> str[-2]
'c'
(5)切片
通常上邊界不包括在提取字元串內,如果沒有指定值,則分片的邊界預設為0和序列的長度
str[1:3]獲取從偏移為1的字元一直到偏移為3的字元串,不包括偏移為3的字元串 “tr”
str[1:] 獲取從偏移為1的字元一直到字元串的最後一個字元(包括最後一個字元) “tring”
str[:3] 獲取從偏移為0的字元一直到偏移為3的字元串,不包括偏移為3的字元串 “str”
str[:-1] 獲取從偏移為0的字元一直到最後一個字元(不包括最後一個字元串) “strin”
str[:] 獲取字元串從開始到結尾的所有元素 “string”
str[-3:-1] 獲取偏移為-3到偏移為-1的字元,不包括偏移為-1的字元 “in”
str[-1:-3]和str[2:0] 獲取的為空字元,系統不提示錯誤 “”
分片的時候還可以增加一個步長,str[::2] 輸出的結果為 “srn”
(6)格式化輸出
1. 列印字元串
>>> print ("His name is %s"%("Aviad"))
His name is Aviad
2.列印整數
>>> print ("He is %d years old"%(25))
He is 25 years old
3.列印浮點數
>>> print ("His height is %f m"%(1.83))
His height is 1.830000 m
4.列印浮點數(指定保留小數點位數)
>>> print ("His height is %.2f m"%(1.83))
His height is 1.83 m
5.指定占位符寬度
>>> print ("Name:%10s Age:%8d Height:%8.2f"%("Aviad",25,1.83))
Name: Aviad Age: 25 Height: 1.83
6.指定占位符寬度(左對齊)
>>> print ("Name:%-10s Age:%-8d Height:%-8.2f"%("Aviad",25,1.83))
Name:Aviad Age:25 Height:1.83
7.指定占位符(只能用0當占位符?)
>>> print ("Name:%-10s Age:%08d Height:%08.2f"%("Aviad",25,1.83))
Name:Aviad Age:00000025 Height:00001.83
8.科學計數法
>>> format(0.0015,'.2e') '1.50e-03'


