
HBase定義 HBase 是一個高可靠、高性能、面向列、可伸縮的分散式存儲系統,利用Hbase技術可在廉價PC Server上搭建 大規模結構化存儲集群。 HBase 是Google Bigtable 的開源實現,與Google Bigtable 利用GFS作為其文件存儲系統類似, HBase 利 ...
HBase定義
HBase 是一個高可靠、高性能、面向列、可伸縮的分散式存儲系統,利用Hbase技術可在廉價PC Server上搭建 大規模結構化存儲集群。
HBase 是Google Bigtable 的開源實現,與Google Bigtable 利用GFS作為其文件存儲系統類似, HBase 利用Hadoop HDFS 作為其文件存儲系統;Google 運行MapReduce 來處理Bigtable中的海量數據, HBase 同樣利用Hadoop MapReduce來處理HBase中的海量數據;Google Bigtable 利用Chubby作為協同服務, HBase 利用Zookeeper作為對應。
HBase 的特點
HBase 中的表一般有以下特點。
1)大:一個表可以有上億行,上百萬列。
2)面向列:面向列表(簇)的存儲和許可權控制,列(簇)獨立檢索。
3)稀疏:對於為空(NULL)的列,並不占用存儲空間,因此,表可以設計的非常稀疏。
HBase 訪問介面
HBase 支持很多種訪問,訪問HBase的常見介面如下。
1、Native Java API,最常規和高效的訪問方式,適合Hadoop MapReduce Job並行批處理HBase表數據。
2、HBase Shell,HBase的命令行工具,最簡單的介面,適合HBase管理使用。
3、Thrift Gateway,利用Thrift序列化技術,支持C++,PHP,Python等多種語言,適合其他異構系統線上訪問HBase表數據。
4、REST Gateway,支持REST 風格的Http API訪問HBase, 解除了語言限制。
5、Pig,可以使用Pig Latin流式編程語言來操作HBase中的數據,和Hive類似,本質最終也是編譯成MapReduce Job來處理HBase表數據,適合做數據統計。
6、Hive,當前Hive的Release版本尚沒有加入對HBase的支持,但在下一個版本Hive 0.7.0中將會支持HBase,可以使用類似SQL語言來訪問HBase。
HBase 存儲結構
從HBase的架構圖上可以看出,HBase中的存儲包括HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等,本課程統一介紹他們的作用即存儲結構。 以下是 HBase 存儲架構圖:
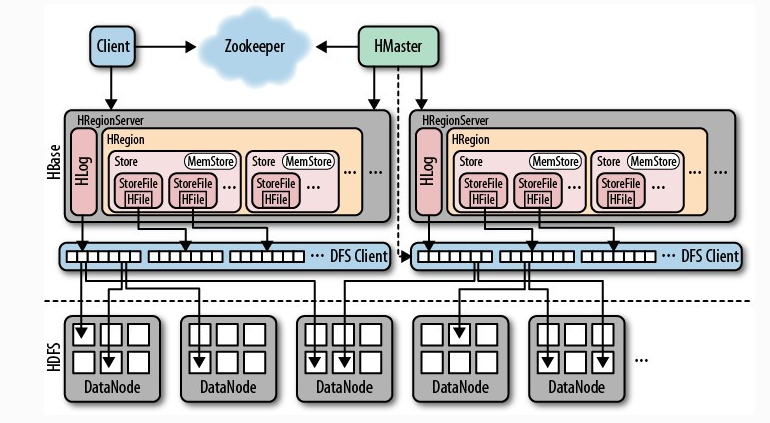
HBase中的每張表都通過行鍵按照一定的範圍被分割成多個子表(HRegion),預設一個HRegion超過256M就要被分割成兩個,這個過程由HRegionServer管理,而HRegion的分配由HMaster管理。
HMaster
1、 為Region server分配region。
2、 負責Region server的負載均衡。
3、發現失效的Region server並重新分配其上的region。
4、 HDFS上的垃圾文件回收。
5、 處理schema更新請求。
HRegionServer
1、 維護master分配給他的region,處理對這些region的io請求。
2、 負責切分正在運行過程中變的過大的region。
可以看到,client訪問hbase上的數據並不需要master參與(定址訪問zookeeper和region server,數據讀寫訪問region server),master僅僅維護table和region的元數據信息(table的元數據信息保存在zookeeper上),負載很低。 HRegionServer存取一個子表時,會創建一個HRegion對象,然後對錶的每個列族創建一個Store實例,每個Store都會有一個MemStore和0個或多個StoreFile與之對應,每個StoreFile都會對應一個HFile, HFile就是實際的存儲文件。因此,一個HRegion有多少個列族就有多少個Store。 一個HRegionServer會有多個HRegion和一個HLog。
HRegion
table在行的方向上分隔為多個Region。Region是HBase中分散式存儲和負載均衡的最小單元,即不同的region可以分別在不同的Region Server上,但同一個Region是不會拆分到多個server上。
Region按大小分隔,每個表一般是只有一個region。隨著數據不斷插入表,region不斷增大,當region的某個列族達到一個閾值(預設256M)時就會分成兩個新的region。
每個region由以下信息標識:
1、< 表名,startRowkey,創建時間>
2、由目錄表(-ROOT-和.META.)記錄該region的endRowkey
HRegion定位:Region被分配給哪個Region Server是完全動態的,所以需要機制來定位Region具體在哪個region server。
HBase使用三層結構來定位region:
1、 通過zk里的文件/hbase/rs得到-ROOT-表的位置。-ROOT-表只有一個region。
2、通過-ROOT-表查找.META.表的第一個表中相應的region的位置。其實-ROOT-表是.META.表的第一個region;.META.表中的每一個region在-ROOT-表中都是一行記錄。
3、通過.META.表找到所要的用戶表region的位置。用戶表中的每個region在.META.表中都是一行記錄。
-ROOT-表永遠不會被分隔為多個region,保證了最多需要三次跳轉,就能定位到任意的region。client會將查詢的位置信息保存緩存起來,緩存不會主動失效,因此如果client上的緩存全部失效,則需要進行6次網路來回,才能定位到正確的region,其中三次用來發現緩存失效,另外三次用來獲取位置信息。
Store
每一個region由一個或多個store組成,至少是一個store,hbase會把一起訪問的數據放在一個store裡面,即為每個ColumnFamily建一個store,如果有幾個ColumnFamily,也就有幾個Store。一個Store由一個memStore和0或者多個StoreFile組成。 HBase以store的大小來判斷是否需要切分region。
MemStore
memStore 是放在記憶體里的。保存修改的數據即keyValues。當memStore的大小達到一個閥值(預設64MB)時,memStore會被flush到文件,即生成一個快照。目前hbase 會有一個線程來負責memStore的flush操作。
StoreFile
memStore記憶體中的數據寫到文件後就是StoreFile,StoreFile底層是以HFile的格式保存。
HFile
HBase中KeyValue數據的存儲格式,是hadoop的二進位格式文件。 首先HFile文件是不定長的,長度固定的只有其中的兩塊:Trailer和FileInfo。Trailer中有指針指向其他數據塊的起始點,FileInfo記錄了文件的一些meta信息。 Data Block是hbase io的基本單元,為了提高效率,HRegionServer中有基於LRU的block cache機制。每個Data塊的大小可以在創建一個Table的時候通過參數指定(預設塊大小64KB),大號的Block有利於順序Scan,小號的Block利於隨機查詢。每個Data塊除了開頭的Magic以外就是一個個KeyValue對拼接而成,Magic內容就是一些隨機數字,目的是防止數據損壞,結構如下。

HFile結構圖如下:
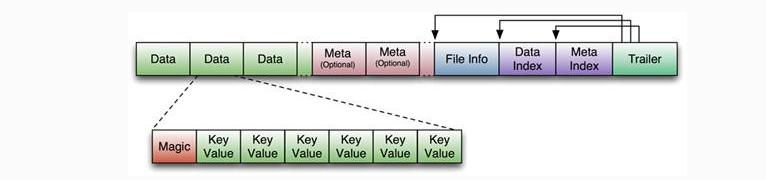
Data Block段用來保存表中的數據,這部分可以被壓縮。 Meta Block段(可選的)用來保存用戶自定義的kv段,可以被壓縮。 FileInfo段用來保存HFile的元信息,不能被壓縮,用戶也可以在這一部分添加自己的元信息。 Data Block Index段(可選的)用來保存Meta Blcok的索引。 Trailer這一段是定長的。保存了每一段的偏移量,讀取一個HFile時,會首先讀取Trailer,Trailer保存了每個段的起始位置(段的Magic Number用來做安全check),然後,DataBlock Index會被讀取到記憶體中,這樣,當檢索某個key時,不需要掃描整個HFile,而只需從記憶體中找到key所在的block,通過一次磁碟io將整個 block讀取到記憶體中,再找到需要的key。DataBlock Index採用LRU機制淘汰。 HFile的Data Block,Meta Block通常採用壓縮方式存儲,壓縮之後可以大大減少網路IO和磁碟IO,隨之而來的開銷當然是需要花費cpu進行壓縮和解壓縮。目標HFile的壓縮支持兩種方式:gzip、lzo。

另外,針對目前針對現有HFile的兩個主要缺陷:
a) 占用過多記憶體
b) 啟動載入時間緩慢
基於此缺陷,提出了HFile Version2設計。
HLog
其實HLog文件就是一個普通的Hadoop Sequence File, Sequence File的value是key時HLogKey對象,其中記錄了寫入數據的歸屬信息,除了table和region名字外,還同時包括sequence number和timestamp,timestamp是寫入時間,sequence number的起始值為0,或者是最近一次存入文件系統中的sequence number。 Sequence File的value是HBase的KeyValue對象,即對應HFile中的KeyValue。
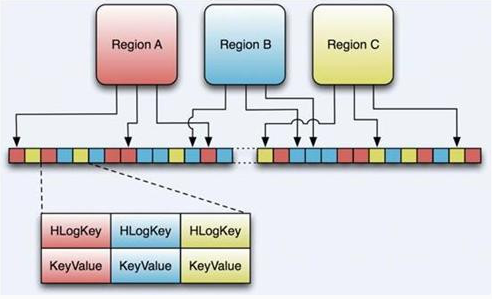
HLog(WAL log):WAL意為write ahead log,用來做災難恢復使用,HLog記錄數據的所有變更,一旦region server 宕機,就可以從log中進行恢復。
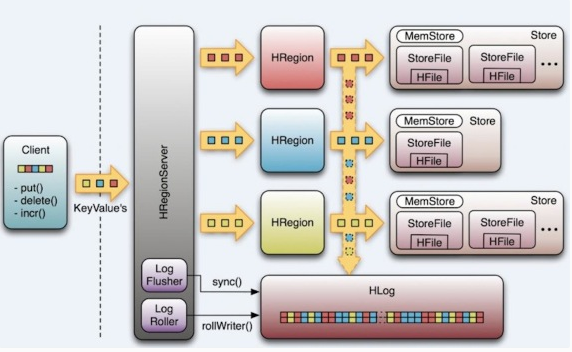
LogFlusher
前面提到,數據以KeyValue形式到達HRegionServer,將寫入WAL之後,寫入一個SequenceFile。看過去沒問題,但是因為數據流在寫入文件系統時,經常會緩存以提高性能。這樣,有些本以為在日誌文件中的數據實際在記憶體中。這裡,我們提供了一個LogFlusher的類。它調用HLog.optionalSync(),後者根據 hbase.regionserver.optionallogflushinterval (預設是10秒),定期調用Hlog.sync()。另外,HLog.doWrite()也會根據 hbase.regionserver.flushlogentries (預設100秒)定期調用Hlog.sync()。Sync() 本身調用HLog.Writer.sync(),它由SequenceFileLogWriter實現。
LogRoller
Log的大小通過$HBASE_HOME/conf/hbase-site.xml 的 hbase.regionserver.logroll.period 限制,預設是一個小時。所以每60分鐘,會打開一個新的log文件。久而久之,會有一大堆的文件需要維護。首先,LogRoller調用HLog.rollWriter(),定時滾動日誌,之後,利用HLog.cleanOldLogs()可以清除舊的日誌。它首先取得存儲文件中的最大的sequence number,之後檢查是否存在一個log所有的條目的“sequence number”均低於這個值,如果存在,將刪除這個log。 每個region server維護一個HLog,而不是每一個region一個,這樣不同region(來自不同的table)的日誌會混在一起,這樣做的目的是不斷追加單個文件相對於同時寫多個文件而言,可以減少磁碟定址次數,因此可以提高table的寫性能。帶來麻煩的時,如果一個region server下線,為了恢復其上的region,需要將region server上的log進行拆分,然後分發到其他region server上進行恢復。
HBase 設計
HBase 中的每一張表就是所謂的 BigTable。BigTable 會存儲一系列的行記錄,行記錄有三個基本類型的定義:Row Key、Time Stamp、Column。
1、Row Key 是行在 BigTable 中的唯一標識。
2、Time Stamp 是每次數據操作對應關聯的時間戳,可以看做 SVN 的版本。
3、Column 定義為< family>:< label>,通過這兩部分可以指定唯一的數據的存儲列,family 的定義和修改需要 對 HBase 進行類似於 DB 的 DDL 操作,而 label ,不需要定義直接可以使用,這也為動態定製列提供了一種手段 。family 另一個作用體現在物理存儲優化讀寫操作上,同 family 的數據物理上保存的會比較臨近,因此在業務設計的過程中可以利用這個特性。
數據模型
HBase 以表的形式存儲數據。表由行和列組成。列劃分為若幹個列族(row family),如下圖所示。

1、 Row Key
與 NoSQL 資料庫一樣,Row Key 是用來檢索記錄的主鍵。訪問 HBase table 中的行,只有三種方式:
1)通過單個 Row Key 訪問。
2)通過 Row Key 的 range 全表掃描。
3)Row Key 可以使任意字元串(最大長度是64KB,實際應用中長度一般為 10 ~ 100bytes),在HBase 內部,Row Key 保存為位元組數組。
在存儲時,數據按照 Row Key 的字典序(byte order)排序存儲。設計 Key 時,要充分排序存儲這個特性,將經常一起讀取的行存儲到一起(位置相關性)。
註意 字典序對 int 排序的結果是 1,10,100,11,12,13,14,15,16,17,18,19,20,21,..., 9,91,92,93,94,95,96,97,98,99。要保存整形的自然序,Row Key 必須用 0 進行左填充。行的一次讀寫是原子操作(不論一次讀寫多少列)。這個設計決策能夠使用戶很容易理解程式在對同一個行進行併發更新操作時的行為。
2、 列族
HBase 表中的每個列都歸屬於某個列族。列族是表的 Schema 的一部分(而列不是),必須在使用表之前定義。列名都以列族作為首碼,例如 courses:history、courses:math 都屬於 courses 這個列族。
訪問控制、磁碟和記憶體的使用統計都是在列族層面進行的。在實際應用中,列族上的控制許可權能幫助我們管理不同類型的應用, 例如,允許一些應用可以添加新的基本數據、一些應用可以讀取基本數據並創建繼承的列族、一些應用則只允許瀏覽數據(甚至可能因為隱私的原因不能瀏覽所有數據)。
3、 時間戳
HBase 中通過 Row 和 Columns 確定的一個存儲單元稱為 Cell。每個 Cell 都保存著同一份數據的多個版本。 版本通過時間戳來索引,時間戳的類型是 64 位整型。時間戳可以由HBase(在數據寫入時自動)賦值,此時時間戳是精確到毫秒的當前系統時間。時間戳也 可以由客戶顯示賦值。如果應用程式要避免數據版本衝突,就必須自己生成具有唯一性的時間戳。每個 Cell 中,不同版本的數據按照時間倒序排序,即最新的數據排在最前面。
為了避免數據存在過多版本造成的管理(包括存儲和索引)負擔,HBase 提供了兩種數據版本回收方式。 一是保存數據的最後 n 個版本,二是保存最近一段時間內的版本(比如最近七天)。用戶可以針對每個列族進行設置。
4、 Cell
Cell 是由 {row key,column(=< family> + < label>),version} 唯一確定的單元。Cell 中的數據是沒有類型的,全部是位元組碼形式存儲。
物理存儲
Table 在行的方向上分割為多個HRegion,每個HRegion分散在不同的RegionServer中。
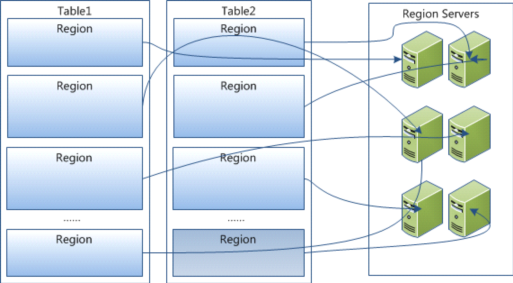
每個HRegion由多個Store構成,每個Store由一個memStore和0或多個StoreFile組成,每個Store保存一個Columns Family

StoreFile以HFile格式存儲在HDFS中。


