
本文出處:http://www.cnblogs.com/wy123/p/6082338.html 現實中遇到過到這麼一種情況: 在某些特殊場景下:進行查詢的時候,加了TOP 1比不加TOP 1要慢(而且是慢很多)的情況, 也就是說對於符合條件的某種的數據,查詢1條(複合該條件)數據比查詢所有(符合該 ...
本文出處:http://www.cnblogs.com/wy123/p/6082338.html
現實中遇到過到這麼一種情況:
在某些特殊場景下:進行查詢的時候,加了TOP 1比不加TOP 1要慢(而且是慢很多)的情況,
也就是說對於符合條件的某種的數據,查詢1條(複合該條件)數據比查詢所有(符合該條件)數據慢的情況,
這種情況往往只有在某些特殊條件下會出現,那麼,就有兩個問題:為什麼加了TOP 1 會比不加TOP 1慢?這種“特殊條件”是什麼條件?
本文將對此情況進行演示和原理分析,以及針對此種情況採用什麼方法來解決。
按照一貫風格,先造一個測試環境:1000W+的數據
數據的特點為:
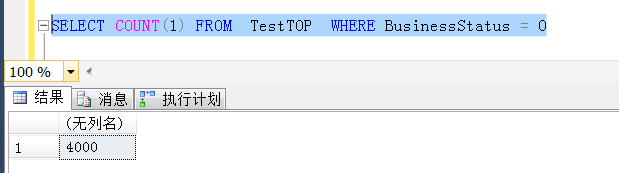
1,表中有一個狀態列BusinessStatus ,這個列的分佈為1,2,3,4,5
2,表中有一個 業務ID列BusinessId , BusinessId列是呈遞增趨勢
CREATE TABLE TestTOP ( Id INT IDENTITY(1,1) primary key, BusinessColumn VARCHAR(50), BusinessId INT, BusinessStatus TINYINT, CreateDate DATETIME ) GO
--5年的時間,一分鐘六條數據的數據頻率 DECLARE @i int = 0 WHILE @i<24*60*365*5 BEGIN INSERT INTO TestTOP VALUES (NEWID(),@i,RAND()*5+1, DATEADD(SS,@i,DATEADD(YEAR,-5,GETDATE()))) INSERT INTO TestTOP VALUES (NEWID(),@i,RAND()*5+1, DATEADD(SS,@i,DATEADD(YEAR,-5,GETDATE()))) INSERT INTO TestTOP VALUES (NEWID(),@i,RAND()*5+1, DATEADD(SS,@i,DATEADD(YEAR,-5,GETDATE()))) INSERT INTO TestTOP VALUES (NEWID(),@i,RAND()*5+1, DATEADD(SS,@i,DATEADD(YEAR,-5,GETDATE()))) INSERT INTO TestTOP VALUES (NEWID(),@i,RAND()*5+1, DATEADD(SS,@i,DATEADD(YEAR,-5,GETDATE()))) INSERT INTO TestTOP VALUES (NEWID(),@i,RAND()*5+1, DATEADD(SS,@i,DATEADD(YEAR,-5,GETDATE()))) SET @i=@i+1 END
另外,在此表中查詢一小部分BusinessStatus=0的分佈較少的數據,且分佈在最大的BusinessId上,這裡暫定為5000行,利用如下腳本生成
DECLARE @i int = 15768000 WHILE @i<15768000+5000 BEGIN INSERT INTO TestTOP VALUES (NEWID(),@i,0, DATEADD(SS,@i,GETDATE())) SET @i=@i+1 END
現在這個測試環境已經搭建完成,現在創建兩個非聚集索引,一個是在BusinessStatus上,一個是在BusinessId
CREATE INDEX idx_BusinessStatus ON TestTOP(BusinessStatus) CREATE INDEX idx_BusinessId on TestTOP(BusinessId)
下麵開始測試:
說明:1,以下測試,不用考慮緩存之類的因素,本機測試,記憶體也足夠大,全部緩存這麼點數據還是夠的。也暫不分析IO具體值,粗看執行時間已經很明顯了
2,讀者要對SQL Server索引結構,統計信息,執行計劃,執行計劃預估等知識有一定的認識,否則很多理論上的東西就看的雲里霧裡
3,本文測試資料庫為SQL Server 2012,SQL Server每個版本的預估演算法可能都不一樣,具體環境具體分析
SELECT TOP 1 比不加 TOP 1慢
1,首先執行TOP 1 *的查詢,耗時13秒

2,然後執行不加TOP 1 *的查詢,也即SELECT * ,如下,耗時0秒(當然不是0秒,意思是很快就可以完成這個查詢)

3,上面兩個查詢就可以重現第一個問題了,也就是說在當前這種查詢條件下,TOP 1要比不加TOP 1慢很多
分析兩者的執行計劃:
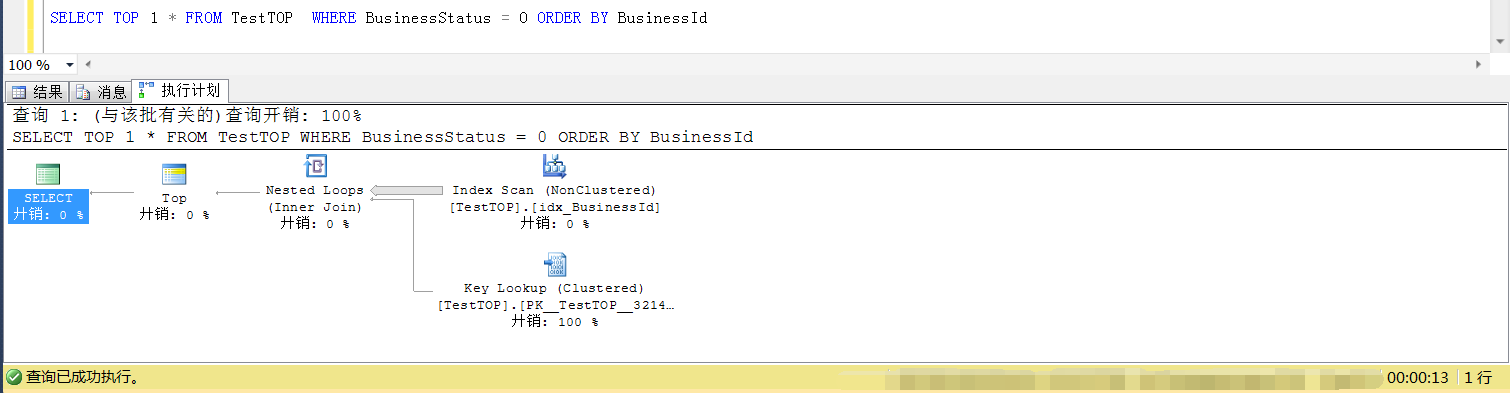
首先看加了 TOP 1 的執行計劃:可以看到走的是idx_BusinessId的索引掃描
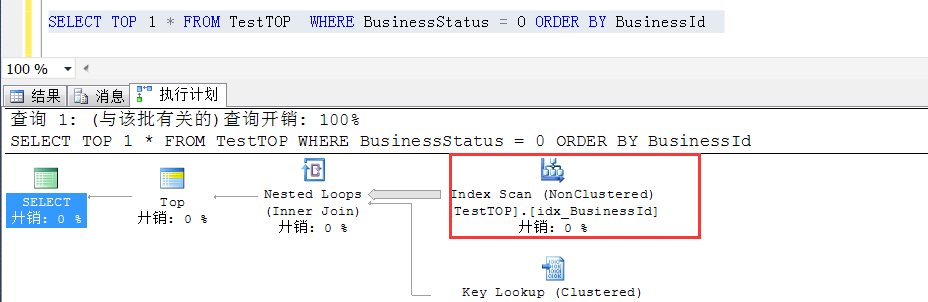
接著看不加TOP 1 的執行計劃:可以看到走的是idx_BusinessStatus這個索引的索引查找

原因分析:
那麼為什麼加了TOP 1就走BusinessId列上的索引掃描,不加TOP 1就走BusinessStatus上的索引掃描?
因為在加了TOP 1之後,只要求返回一條數據,
優化器認為(應該說是誤認為)可以很快找到符合條件的那條記錄,採用了idx_BusinessId列上的索引掃描
由於數據的分佈可知,符合BusinessStatus=0的BusinessId,是分佈在BusinessId值最大的一小部分數據中,而BusinessId又是遞增的,
也就是說複合條件的數據是集中分佈在idx_BusinessId索引樹的一個很小的特定區域,
採用的是與idx_BusinessId順序一致的(ForWard順序)索引掃描,有數據分佈特點可知,一開始找到的絕大多數的BusinessId,都不是符合BusinessStatus=0的
以至於幾乎要掃描整個idx_BusinessId索引樹才能找到符合BusinessStatus=0條件的數據,因此效率就會很低
反觀不加TOP 1的時候,因為是要找所有符合BusinessStatus=0的數據,優化器就索引採取了idx_BusinessStatus索引查找的方式,至此,原因大概是這樣的。
問題到這裡才剛剛開始
如果說上述推斷不足以說明問題,那麼我們繼續看在加了TOP 1的時候,執行計劃是怎麼預估的?
繼續觀察加了TOP 1的時候的預估,發現此時走idx_BusinessId的索引掃描,預估行數為3154.6行,這個數字是怎麼得到的?
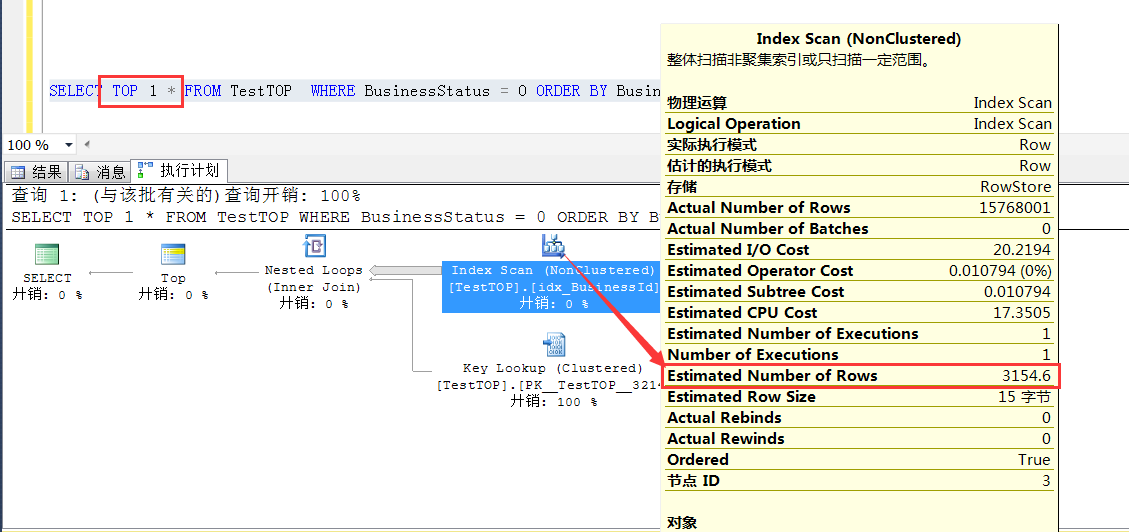
現在觀察idx_BusinessStatus列上的統計信息,統計信息是100%取樣的,先不考慮統計信息不准確的問題
因為在加了TOP 1的時候,優化器認為複合條件的數據是平均分佈在整個表中的,
也就是說BusinessStatus=0的5000行數據是平均分佈在15773000行數據中,查詢條件又要求按照BusinessId正向排序,
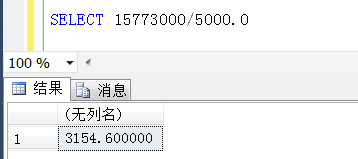
那麼乾脆走BusinessId列上的索引掃描,(誤以為)平均找15773000/5000 行數據,就可以找到一條(TOP 1)符合條件的數據
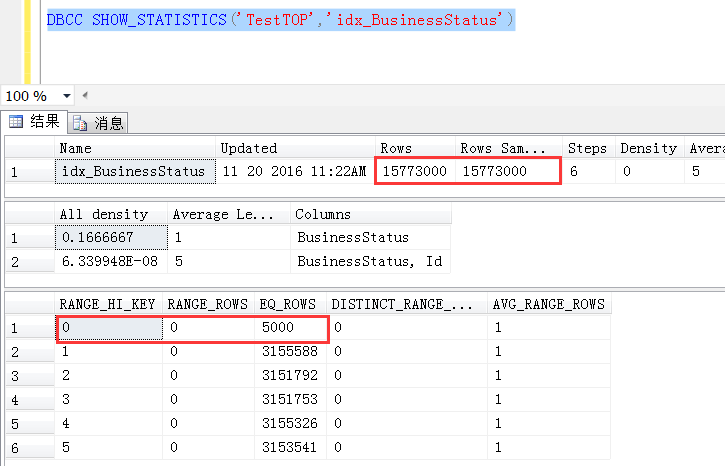
實際上是不是這樣子呢?用總行數處於BusinessStatus=0的行數,與預估的值比較,都是3154.6呢?那麼上面的推斷也就是成立的
這裡查詢加了TOP 1比不加TOP 1慢的根本原因就是如下:
事實情況下是複合條件的數據分佈是不均勻的,而優化器誤以為符合條件的數據分佈(在整張表中)是均勻的,
正是因為有了這麼一個矛盾,所以在加了TOP 1 的時候,優化器採用非最優化的方式造成的。
什麼情況下才會發生TOP 1要比不加TOP 1慢(或者慢很多)
事實上,類似結構的數據分佈,並非所有的情況下都會出現TOP 1比不加TOP 1慢的情況
那麼什麼時候TOP 1 可以選擇正確的執行計劃,而非採用低效的執行計劃(排序列上的索引掃描)?
當然是跟符合條件的數據BusinessStatus=0的數據行數有關,只有符合條件的數據(BusinessStatus=0)達到一定數量之後才會發生(TOP 1比不加TOP 1慢)
上面說了,優化器誤以為符合條件的數據(BusinessStatus=0)分佈是均勻的,採用了排序列上的索引掃描的執行方式,
即便是優化器誤以為符合條件的數據(BusinessStatus=0)分佈是均勻的,
採用一開始的預估演算法(平均分佈:總行數/符合條件的數據行數)得到一個值,與符合條件的數據的行數本身對比,如果前者較大,就不會採用排序列上的索引掃描
這裡太拗口了也很難表達清楚,直接上例子吧。
首先我改變符合條件(BusinessStatus=0)的數據的行數,讓複合條件的數據變的少一些,
這裡刪除原來的BusinessStatus=0的5000行數據,插入符合條件的數據為1000行,然後重建索引,試試看TOP 1 的效果
(插入之後註意重建一下BusinessStatus上的索引,得到最準確的統計信息)
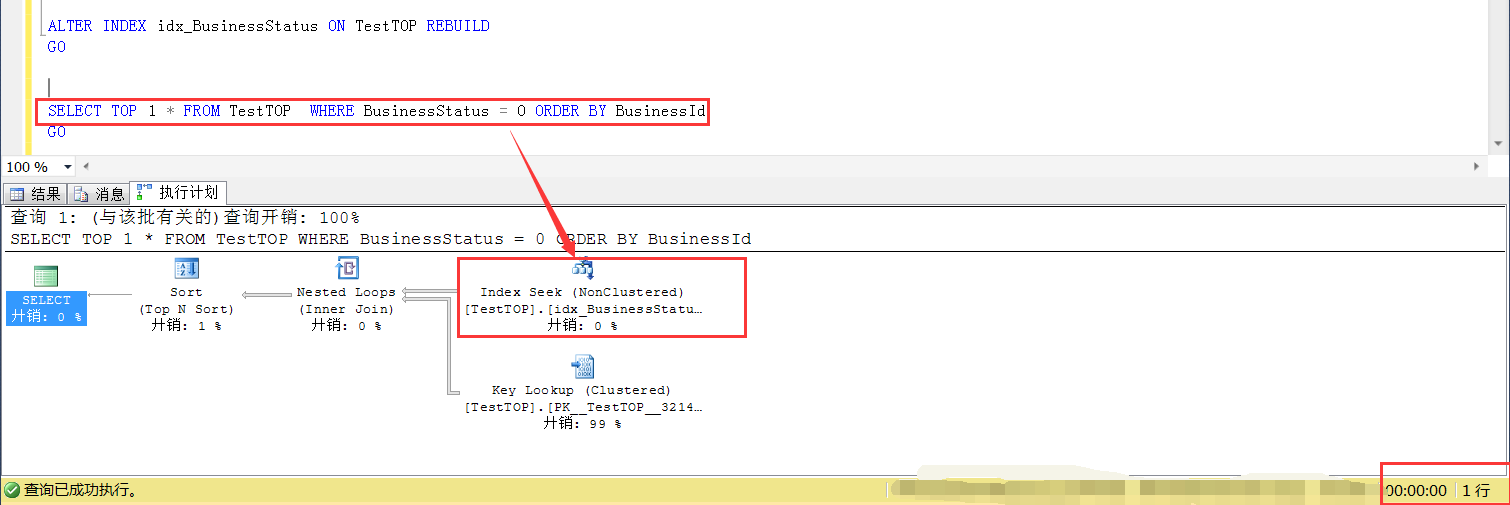
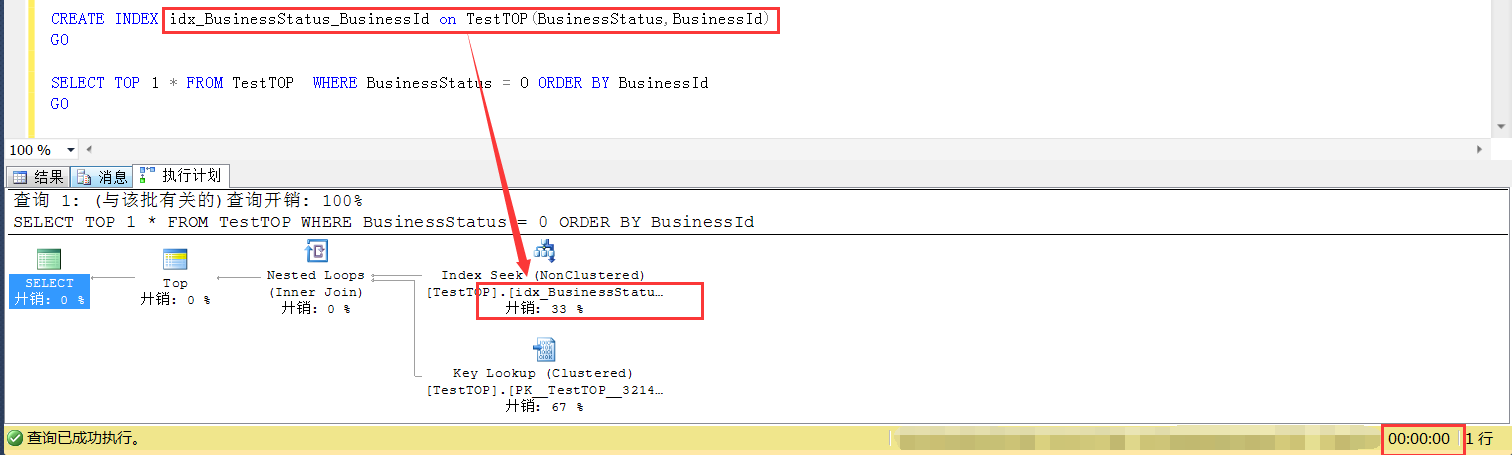
此時再看SELECT TOP 1的查詢方式,不會走排序列上的索引掃描了,走了查詢條件列(idx_BusinessStatus)的索引查找,效率也上來了。
事實上我這裡說了這麼多,一直在想引出一個問題,那麼符合條件(BusinessStatus=0)這個數據分佈多少,SELECT TOP 1不會引起問題(比不加TOP 1慢)?
根據上述推論,這個值是動態的,大概如下:
假如:X=總行數/符合條件數據行數,Y = 符合條件數據行數
在統計信息完全準確的請下
如果X>Y,也即:總行數/符合條件數據行數>符合條件數據行數,則會導致在SELECT TOP 1的時候使用排序列的索引掃描替代查詢列的索引查找。
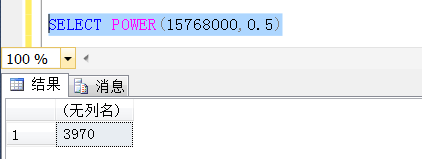
那麼這個閾值是多少?按照這種演算法推論,理論上講,就是符合條件的數據的行數等於總行數的平方根,數學推到也很簡單,事實上下麵也測試了。
這個閾值在理論上是:3970行左右,
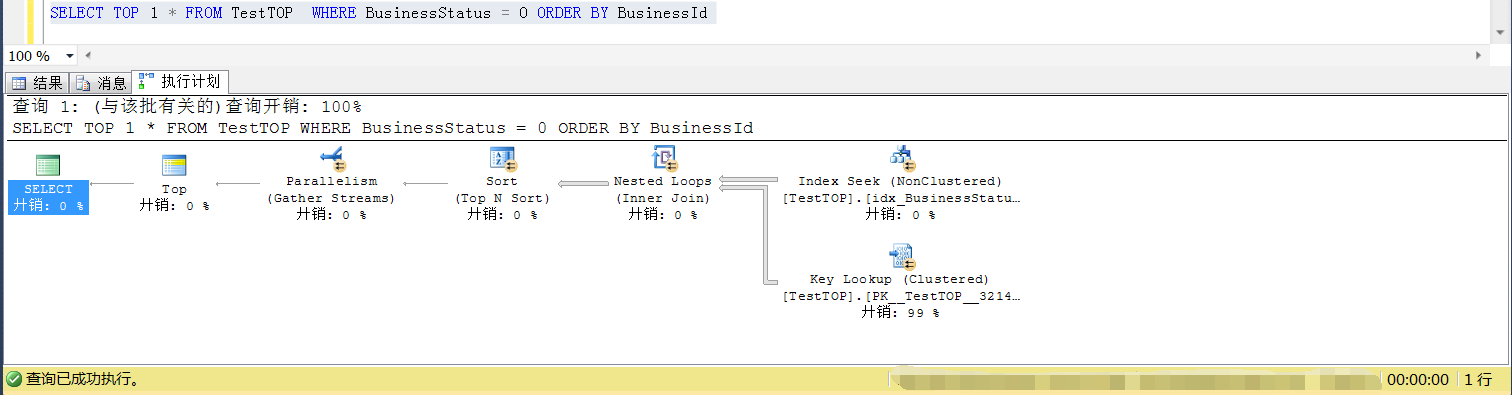
那麼插入符合條件的數據為3900的時候(小於閾值,也即小於總行數的平方根),SELECT TOP 1是可以走索引的,如下兩個截圖

修改符合條件(BusinessStatus=0)的數據分佈
而符合條件的數據大於閾值(大於閾值,也即大於總行數的平方根,)的時候,SELECT TOP 1 就開始走排序列的索引掃描,效率開始變慢
事實上導致SELECT TOP 1執行計劃發生變化的這個閾值,具體的數值可以弄得更加精確,可以做到大於總行數的平方根一行,或者小於總行數的平方根一行。
但實際上測試發現,這個誤差在三行左右,也就是說閾值具體的值為總行數的平方根加減三條:POWER(TableRowCount,0.5)±3左右。
當然也不是說“SELECT TOP 1的時候使用排序列的索引掃描替代查詢列的索引查找”永遠是低效的,
想象一下,整個表中絕大多數數據是複合條件的(BusinessStatus=0)的條件下,SELECT TOP 1可以很快地找到符合條件的一條數據
只是說,在某個閾值區間內,SQL Server查詢引擎在生成執行計劃的時候有一個盲區,此時查詢引擎無法做出最明智的決定。
實際條件是千變萬化的,規律是可尋的,不能認死了規律而不考慮實際情況。
如何解決SELECT TOP 1比不加TOP 1慢的情況:
上文中說了,查詢加了TOP 1比不加TOP 1慢的根本原因就是如下:
事實情況下是複合條件的數據分佈是不均勻的,而優化器誤以為符合條件的數據分佈(在整張表中)是均勻的,
正是因為有了這麼一個矛盾,所以在加了TOP 1 的時候,優化器採用非最優化的方式造成的。
此時複合條件(BusinessStatus=0)為一開始的5000行,大於上述閾值
如果此時將查詢條件列和排序列做成一個複合索引,就可以避免這種情況,
具體原因,就不多說了,非要說的話,就是讓優化器更加清楚地弄清楚數據分佈,可以做出更加明智的選擇。
當然也有其他辦法,比如強制索引等,但是一旦加了強制索引就屏蔽掉優化器的作用了,如果沒辦法保證索引實在任何時候都是比較高效的情況下,不建議加強制索引。
總結:
本文分析了在某些特定的場景下,重現了SELCET TOP 1比不加TOP 1慢的場景,導致的原因分析以及解決辦法。
事實上為了簡明期間,還有非常多有意思的問題尚未展開,怕是寫的越多,本文的主題就凸顯不出來,有機會再對此尚未展開的問題繼續進行分析。
補充一點:事實上真要是測試的話,任何一點點小小的改變,
比如查詢語句中BusinessId排序改為DESC,甚至沒有BusinessId上的索引,或者聚集索引建立在其他列上
都可以避免TOP 1比不加TOP 1慢的問題,這裡的目的是為了重現TOP 1比不加TOP 1慢的現象條件和原因,以及不改變外因的情況下如何解決這一問題
謝謝。


