
Spark存儲管理(讀書筆記) 轉載請註明出處: "http://www.cnblogs.com/BYRans/" Spark的存儲管理 RDD的存放和管理都是由Spark的存儲管理模塊實現和管理的。本文從架構和功能兩個角度對Spark的存儲管理模塊進行介紹。 架構角度 從架構角度,存儲管理模塊主要 ...
Spark存儲管理(讀書筆記)
轉載請註明出處:http://www.cnblogs.com/BYRans/
Spark的存儲管理
RDD的存放和管理都是由Spark的存儲管理模塊實現和管理的。本文從架構和功能兩個角度對Spark的存儲管理模塊進行介紹。
架構角度
從架構角度,存儲管理模塊主要分為以下兩層:
- 通信層:存儲管理模塊採用的是主從結構來實現通信層,主節點和從節點之間傳輸控制信息、狀態信息。
- 存儲層:存儲管理模塊需要把數據存儲到硬碟或者記憶體中,必要時還需要複製到遠端,這些操作由存儲層來實現和提供相應介面。
通信層消息傳遞
在存儲管理模塊的通信層,每個Executor上的BlockManager只負責管理其自身Executor所擁有的數據塊原信息,而不會管理其他Executor上的數據塊元信息;而Driver端的BlockManager擁有所有已註冊的BlockManager信息和數據塊元信息,因此Executor的BlockManager往往是通過向Driver發送信息來獲得所需要的非本地數據的。
存儲層架構
RDD是由不同的分區組成的,我們所進行的轉換和執行操作都是在每一塊獨立的分區上各自進行的。而在存儲管理模塊內部,RDD又被視為由不同的數據塊組成,對於RDD的存取是以數據塊為單位的,本質上分區(partition)和數據塊(block)是等價的,只是看待的角度不同。同時,在Spark存儲管理模塊中存取數據的最小單位是數據塊,所有的操作都是以數據塊為單位的。
數據塊(Block)
前面章節已經提到:存儲管理模塊以數據塊為單位進行數據管理,數據塊是存儲管理模塊中最小的操作單位。在存儲管理模塊中管理著各種不同的數據塊,這些數據塊為Spark框架提供了不同的功能,Spark存儲管理模塊中所管理的幾種主要數據塊為:
- RDD數據塊:用來存儲所緩存的RDD數據。
- Shuffle數據塊:用來存儲持久化的Shuffle數據。
- 廣播變數數據塊:用來存儲所存儲的廣播變數數據。
- 任務返回結果數據塊:用來存儲在存儲管理模塊內部的任務返回結果。通常情況下任務返回結果隨任務一起通過Akka返回到Driver端。但是當任務返回結果很大時,會引起Akka幀溢出,這時的另一種方案是將返回結果以塊的形式放入存儲管理模塊,然後在Driver端獲取該數據塊即可,因為存儲管理模塊內部數據塊的傳輸是通過Socket連接的,因此就不會出現Akka幀溢出了。
- 流式數據塊:只用在Spark Streaming中,用來存儲所接收到的流式數據塊。
從功能角度
從功能角度,存儲管理模塊可以分為以下兩個主要部分:
- RDD緩存:整個存儲管理模塊主要的工作是作為RDD的緩存,包括基於記憶體和磁碟的緩存。
- Shuffle數據的持久化:Shuffle中間結果的數據也是交由存儲管理模塊進行管理的。Shuffle性能的好壞直接影響了Spark應用程式整體的性能,因此存儲管理模塊中對於Shuffle數據的處理有別於傳統的RDD緩存。
RDD持久化
存儲管理模塊可以分為兩大塊,一是RDD的緩存,二是Shuffle數據的持久化。接下來將介紹存儲管理模塊如何從記憶體和磁碟兩個方面對RDD進行緩存。
RDD分區和數據塊的關係
對於RDD的各種操作,如轉換操作、執行操作,我們將操作函數施行於RDD之上,而最終這些操作都將施行於每一個分區之上,因此可以這麼說,在RDD上的所有運算都是基於分區的。而在存儲管理模塊內,我們所接觸到的往往是數據塊這個概念,在存儲管理模塊中對於數據的存取都是以數據塊為單位進行的。分區是一個邏輯上的概念,而數據塊是物理上的數據實體,我們操作的分區和數據塊,它們兩者之間有什麼關係呢?本小節我們將介紹分區與數據塊的關係。
在Spark中,分區和數據塊是一一對應的,一個RDD中的一個分區對應著存儲管理模塊中的一個數據塊,存儲管理模塊接觸不到也並不關心RDD,它只關心數據塊,對於數據塊和分區之間的映射則是通過名稱上的約定進行的。
這種名稱上的約定是按如下方式建立的:Spark為每一個RDD在其內部維護了獨立的ID號,同時,對於RDD的每一個分區也有一個獨立的索引號,因此只要知道ID號和索引號我們就能找到RDD中的相應分區,也就是說“ID號+索引號”就能全局唯一地確定這個分區。這樣以“ID號+索引號”作為塊的名稱就自然地建立起了分區和塊的映射。
在顯示調用調用函數緩存我們所需的RDD時,Spark在其內部就建立了RDD分區和數據塊之間的映射,而當我們需要讀取緩存的RDD時,根據上面所提到的映射關係,就能從存儲管理模塊中取得分區對應的數據塊。下圖展示了RDD分區與數據塊之間的映射關係。
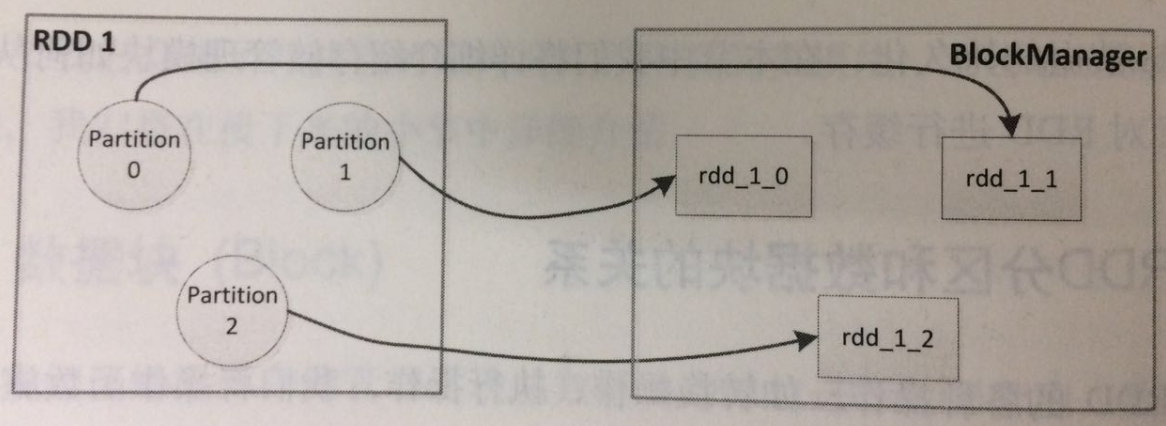
內部緩存
當以預設或者基於記憶體的持久化方式緩存RDD時,RDD中的每一分區所對應的數據塊是會被存儲管理模塊中的記憶體緩存(Memory Store)所管理的。記憶體緩存在其內部維護了一個以數據塊名為鍵,塊內容為值的哈希表。
在記憶體緩存中有一個重要的問題是,當記憶體不是或是已經到達所設置的閾值時應如何處理。在Spark中對於記憶體緩存可使用的記憶體閾值有這樣一個配置:spark.storage.memoryFraction。預設情況下是0.6,也就是說JVM記憶體的60%可被記憶體緩存用來存儲塊內容。當我們存儲的數據塊所占用的記憶體大於60%時,Spark會採取一些策略釋放記憶體緩存空間:丟棄一些數據塊,或是將一些數據塊存儲到磁碟上以釋放記憶體緩存空間。是丟棄還是存儲到磁碟上,依賴於進行操作的這些數據塊的持久化選項,若持久化選項中包含了磁碟緩存,則會將這些塊已入磁碟進行緩存,反之則直接刪除。
那麼直接刪除是否會影響Spark程式的錯誤恢復機制呢?這取決於依賴關係的可回溯性,若該RDD所依賴的祖先RDD是可被回溯並可用的,那麼該RDD所對應的塊被刪除是不會影響錯誤恢復的。反之,若該RDD已經是祖先RDD,且數據已無法被回溯到,那麼程式就會出錯。lost executor錯誤是不是就是這個原因?
從上面的介紹可以看出,記憶體緩存對於數據塊的管理是非常簡單的,本質上就是一個哈希表加上一些存取策略。
磁碟緩存
磁碟緩存管理數據塊的方式為,首先,這些數據塊會被存放到磁碟中的特定目錄下。當我們配置spark.local.dir時,我們就配置了存儲管理模塊磁碟緩存存放數據的目錄。磁碟緩存初始化時會在這些目錄下創建Spark磁碟緩存文件夾,文件夾的命名方式是:spark-local-yyyyMMddHHmmss-xxxx,其中xxxx是一隨機數。伺候所有的塊內容都將存儲到這些創建的目錄中。
其次,在磁碟緩存中,一個數據塊對應著文件系統中的一個文件,文件名和塊名稱的映射關係是通過哈希演算法計算所得的。
總而言之,數據塊對應的文件路徑為:dirId/subDirId/block_id。這樣我們就建立了塊和文件之間的對應關係,而存取塊內容就變成了寫入和讀取相應的文件了。
持久化選項
被緩存的數據塊是可容錯恢復的,若RDD的某一分區丟失,他會通過繼承關係自動重新獲得。
對於RDD的持久化,Spark為我們提供了不同的選項,使我們能將RDD持久化到記憶體、磁碟,或是以序列化的方式持久化到記憶體中,設置可以在集群的不同節點之間存儲多份拷貝。所有這些不同的存儲策略都是通過不同的持久化選項來決定的。
Shuffle數據持久化
存儲管理模塊可以分為兩大塊,一是RDD的緩存,二是Shuffle數據的持久化。介紹完RDD緩存,接下來介紹Shuffle數據持久化。
下圖為Spark中Shuffle操作的流程示意圖
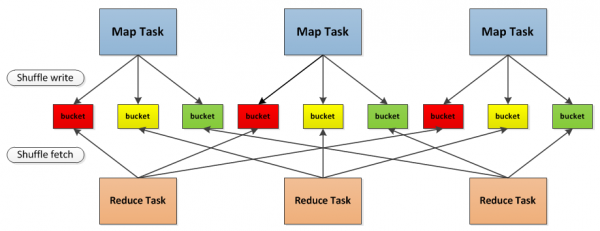
首先,每一個Map任務會根據Reduce任務的數據量創建出相應的桶,桶的數量是M*R,其中M是Map任務的個數,R是Reduce任務的個數。
其次,Map任務產生的結果會根據所設置的分區演算法填充到每個桶中。這裡的分區演算法是可自定義的,當然預設的演算法是根據鍵哈希到不同的桶中。
當Reduce任務啟動時,它會根據自己任務的ID和所依賴的Map任務的ID從遠端或本地的存儲管理模塊中取得相應的桶作為任務的輸入進行處理。
Shuffle數據與RDD持久化的不同之處在於:
- Shuffle數據塊必須是在磁碟上進行緩存的,而不能選擇在記憶體中緩存;
- 在RDD基於磁碟的持久化中,每一個數據塊對應著一個文件,而在Shuffle數據塊持久化中,Shuffle數據塊的存儲有兩種方式:
- 一種是將Shuffle數據塊映射成文件,這是預設的方式;
- 另一種是將Shuffle數據塊映射成文件中的一段,這種方式需要將spark.shuffle.consolidateFiles設置為true。
預設的方式會產生大量的文件,如1000個Map任務和1000個Reduce任務,會產生1000000個Shuffle文件,這會對磁碟和文件系統的性能造成極大的影響,因此有了第二種是實現方式,將分時運行的Map任務所產生的Shuffle數據塊合併到同一個文件中,以減少Shuffle文件的總數。對於第二種存儲方式,示意圖如下:
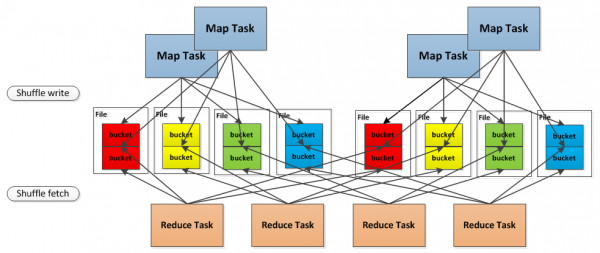
前面介紹了Shuffle數據塊的存取,下麵我們來介紹Shuffle數據塊的讀取和傳輸。Shuffle是將一組任務的輸出結果重新組合作為下一組任務的輸入這樣的一個過程,由於任務分佈在不同的節點上,因此為了將重組結果作為輸入,必然涉及Shuffle數據的讀取和傳輸。
在Spark存儲管理模塊中,Shuffle數據的讀取和傳輸有兩種方式:
- 一種是基於NIO以socket連接去獲取數據;
- 另一種是基於OIO通過Netty服務端獲取數據。
前者是預設的獲取方式,通過配置spark.shuffle.use.netty為true,可以啟用第二種獲取方式。之所以有兩種Shuffle數據的獲取方式,是因為預設的方式在一些情況下無法充分利用網路帶寬,用戶可以通過比較兩種方式在性能上的差異來自行決定選用哪種Shuffle數據獲取方式。
總的來說,Spark存儲管理模塊為Shuffle數據的持久化做了許多有別於RDD持久化的工作,包括存取Shuffle數據塊的方式,以及讀取和傳輸Shuffle數據塊的方式,所有這些實現都是為了使Shuffle獲得更好的性能和容錯。

