
Performance Counter 是量化系統狀態或活動的一個數值,Windows Performance Monitor在一定時間間隔內(預設的取樣間隔是15s)獲取Performance Counter的當前值,並記錄在Data Collections中,通過Performance Moni ...
Performance Counter 是量化系統狀態或活動的一個數值,Windows Performance Monitor在一定時間間隔內(預設的取樣間隔是15s)獲取Performance Counter的當前值,並記錄在Data Collections中,通過Performance Monitor能夠查看系統的性能數據,是故障排除的極佳工具。Performance Counter數量很多,如果不瞭解計數器的功能,在選擇計數器時,往往不知所措。由於SQL Server 是IO密集型的應用程式,經常需要進行大量的讀寫操作,從Disk讀取數據到記憶體,將記憶體中的數據寫入到Disk,因此,Disk和記憶體是SQL Server的生命線,監控SQL Server 的性能,經常用到的性能計數器是Disk和記憶體。
一,Disk性能監控
1,Disk的結構
典型的機械Disk的結構主要有:磁頭(head),磁軌(track),扇區(sector),盤面(Platter),柱面(cylinder)和簇(cluster)。如圖,
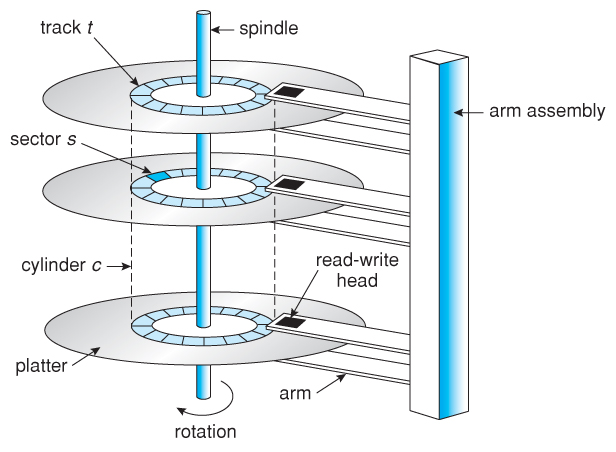
當磁碟旋轉時,若磁頭保持在一個位置上,則每個磁頭都會在磁碟錶面划出一個圓形軌跡,這些圓形軌跡叫做磁軌。磁碟上的每個磁軌被等分為若幹個弧段,這些弧段是磁碟的扇區,每個磁軌上的扇區數量是相等的,每個扇區存放512個位元組的信息,磁碟驅動器在向磁碟讀取和寫入數據時,以扇區為單位。若幹個連續的扇區組合為一個簇,文件存取是以簇為單位的。
硬碟通常由重疊的一組碟片構成,每個盤面都被劃分為數目相等的磁軌,並從外緣的"0"向中心開始編號,具有相同編號的磁軌形成一個圓柱,稱之為磁碟的柱面。磁碟的柱面數與一個盤面上的磁軌數是相等的。由於每個盤面都有自己的磁頭,因此,盤面數等於總的磁頭數。所謂硬碟的CHS,是指Cylinder(柱面)、Head(磁頭)、Sector(扇區),硬碟的容量=柱面數×磁頭數×扇區數×512B。
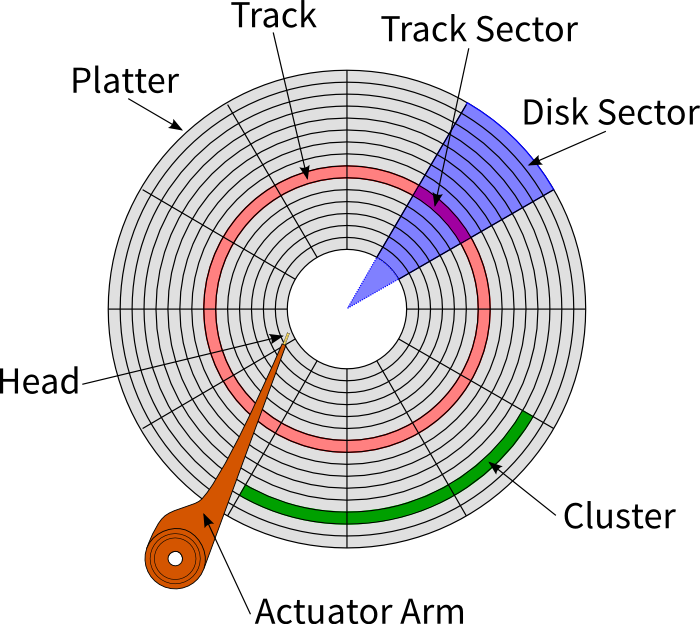
扇區是能獨立定址的最小單位,簇是資源分配的最小單位。Disk的一次讀寫操作,由尋道,旋轉延遲和數據傳輸組成,由於尋道和旋轉延遲占用了讀寫操作的大部分時間,Disk在執行每次讀寫操作時,採取就近原則,讀寫連續的N個扇區,讀寫的數據量是4KB的整數倍。
2,硬碟性能計數器
在OS Level上,Windows在一塊物理硬碟上分成多個邏輯分區,每一個邏輯分區叫做一個Logical Disk,通過盤符標識,運行在Windows上的Application使用盤符來定址。對於分配在同一塊物理硬碟上的邏輯分區,共用物理硬碟的讀寫帶寬,相當於在一塊物理硬碟上工作。因此,Disk計數器分為兩組:PhysicalDisk 和 LogicalDisk,LogcialDisk計數器記錄每個邏輯分區的讀寫計數,用於分析特定的Application在不同的邏輯分區上的Disk IO活動和性能參數;PhysicalDisk計數器記錄整個物理Disk的性能指標,用於瞭解Disk的響應速度,主要使用PhysicalDisk計數器,分析Disk的性能問題。
系統級經常用到的Disk性能計數器是PhysicalDisk計數器,LogcialDisk僅供參考:
- %Disk Time :表示Disk的忙碌程度,是Disk處理讀寫請求的時間的百分比,經常大於100%,建議使用%IdleTime反推出Disk處於讀寫狀態的百分比
- Disk Reads/sec :每秒向Disk請求讀操作的次數
- Disk Transfers/sec:Disk執行讀寫操作的次數
- Disk Reads Bytes/sec :但Disk執行讀操作時,每秒從Disk讀取的位元組數量
- Disk Bytes/sec:當Disk執行讀寫操作時,每秒從Disk讀取到記憶體的,或從記憶體寫入到Disk的位元組數量,好的Disk,其值在20-40MB之間,差的Disk,其值在20MB以下。
- Avg. Disk Queue Length :提供Disk阻塞程度的主要度量值,表示在 sample interval期間,Disk等待處理的IO請求隊列的平均長度,即等待被Disk處理的IO請求的數量
- Avg. Disk sec/Transfer:Disk每一次讀寫操作所用的平均時間
- Avg. Disk sec/Read:Disk每一次讀寫操作所用的平均時間
- Avg. Disk sec/Write:Disk每一次讀寫操作所用的平均時間
avg.Disk sec/(Transfer,Read,Write),能夠很好的反應Disk的IO速度,所以這三個值經常用來衡量Disk的IO速度:
- 很好:<10ms
- 一般:10-20ms
- 有點慢:20-50ms
- 非常慢:>50ms
二,系統物理記憶體性能計數器
SQL Server在運行的過程中,會持續地向記憶體中載入大量數據,如果數據長期駐留在記憶體中,那麼SQL Server 不需要申請Disk IO請求,就能直接訪問數據,快速響應用戶的請求。如果SQL Server訪問的數據不在記憶體中,將會產生一個Hard Page Fault,那麼SQL Server首先指示存儲引擎將數據頁從Disk載入到記憶體中,產生PageIOLatch等待,等到數據被載入到記憶體之後,SQL Server在記憶體中訪問數據,處理用戶請求,由於Disk 的IO速度較慢,延遲高,大量的Hard Page Fault將嚴重影響SQL Server響應用戶請求的速度,因此,常用的系統級記憶體計數器跟缺頁中斷有關:
- Page Faults/sec :每秒發生的Page Fault的數量,Page Fault包括Hard Fault 和 Soft Fault,Hard fault表示需要從Disk中讀取數據頁,Soft fault表示需要從Physical Memory中讀取數據頁,Soft Fault不會影響性能,由於Hard Fault需要訪問Disk,會產生顯著的延遲。
- Pages Input/sec:每秒發生的Hard Fault的數量,用於計算Hard Fault的百分比: Pages Input / Page Faults = % Hard Page Faults,如果百分比經常大於40%,說明系統需要經常訪問Disk獲取數據,在一定程度上說明系統存在記憶體壓力。
- Pages/sec:每秒從Disk讀取或寫入Disk的Page數量,表示記憶體和Disk交互的Page的數量:將Page存儲到Disk或從Disk讀取數據到記憶體的Page的數量。
三,SQL Server的Buffer Manager計數器
Buffer Manager計數器用於監視SQL Server如何使用記憶體數據頁和計劃緩存,讀取和寫入數據頁時的Disk IO。由於Buffer Pool是SQL Server記憶體最活躍,使用最多的部分,所以也是最容易出現性能瓶頸的部分,計數值尤其重要:
- Buffer Cache hit ration:從Buffer Pool中直接讀取,不需要從Disk中讀取的數據頁的百分比,也叫命中率。如果命中率低於95%,通常說明系統記憶體不足。
- Lazy Writes/sec:被LazyWriter寫入的buffer數量
- Page Life Expectancy:數據頁駐留在記憶體中的時間。如果SQL Server沒有新的記憶體需求,或有空閑的記憶體來完成新的記憶體需求,那麼Lazy Writer不會被處罰,Page會一直駐留在Buffer Pool中,那麼Page Life Expectancy會維持在一個比較高的水平;如果Page Life總是高高低低,表明SQL Server存在記憶體壓力。
- Page Reads/sec:每秒從Disk讀取的數據頁數,如果用戶訪問的數據都緩存在記憶體中,那麼SQL Server不需要從物理Disk上讀取頁面。由於物理IO的開銷大,Page Reads操作一定會影響SQL Server的性能。
- CheckPoint Pages/sec:將數據刷新到Disk的Dirty Pages的數量,跟用戶修改的數據量有關,如果用戶對資料庫做了很多修改操作,那麼記憶體中修改過的數據臟頁就會比較多,每次刷新的臟頁數量就會比較大
- Page Writes/sec:每秒寫入到Disk的數據頁數,和記憶體使用關係不大,跟用戶修改的數據量有關
四,SQL Server的Memory Manager計數器
Memory Manager計數器用於監控伺服器記憶體總體使用情況,在一個非常繁忙的系統中,Lock記憶體和授予記憶體是常用的計數器:
- Total Server Memory (KB):SQL Server當前使用的記憶體總量
- Target Server Memory (KB):SQL Server能夠使用的記憶體總量
- Lock Memory (KB):SQL Server用於鎖的記憶體總量
- Grant Workspace Memory (KB):授予記憶體,SQL Server用於執行hash,排序和創建Index操作而消耗的記憶體總量
- Memory Grants Pending (KB):等待記憶體授予的進程數量,如果進程不能獲得指定數量的記憶體,那麼進程將不會開始執行
五,使用Performance Counter監控SQL Server資料庫系統的整體性能
創建兩個Data Set:Disk Activity,用於監控物理磁碟的活動;Memory Activity ,用於監控系統記憶體的Hard Fault和SQL Server的記憶體使用。

下文摘抄自《硬碟的讀寫原理》,作者是真實的歸宿,寫的非常詳細:
訪盤請求完成過程
當需要從磁碟讀取數據時,系統會將數據邏輯地址傳給磁碟,磁碟的控制電路按照定址邏輯將邏輯地址翻譯成物理地址,即確定要讀的數據在哪個磁軌,哪個扇區。 為了讀取這個扇區的數據,需要將磁頭放到這個扇區上方,為了實現這一點,磁頭需要移動對準相應磁軌,這個過程叫做尋道,所耗費時間叫做尋道時間,然後磁碟 旋轉將目標扇區旋轉到磁頭下,這個過程耗費的時間叫做旋轉時間。
即一次訪盤請求(讀/寫)完成過程由三個動作組成:
- 尋道(時間):磁頭移動定位到指定磁軌
- 旋轉延遲(時間):等待指定扇區從磁頭下旋轉經過
- 數據傳輸(時間):數據在磁碟與記憶體之間的實際傳輸
因此在磁碟上讀取扇區數據(一塊數據)所需時間:Ti/o=尋道時間 +旋轉時間 + n *傳輸時間
磁碟的讀寫原理
系統將文件存儲到磁碟上時,按柱面、磁頭、扇區的方式進行,即最先是第1磁軌的第一磁頭下(也就是第1盤面的第一磁軌)的所有扇區,然後,是同一柱面的下一磁頭,……,一個柱面存儲滿後就推進到下一個柱面,直到把文件內容全部寫入磁碟。系統也以相同的順序讀出數據。讀出數據時通過告訴磁碟控制器要讀出扇區所在的柱面號、磁頭號和扇區號(物理地址的三個組成部分)進行。磁碟控制器則直接使磁頭部件移動到相應的柱面,選通相應的磁頭,等待要求的扇區移動到磁頭下。在扇區到來時,磁碟控制器對扇區進行讀寫操作。
局部性原理與磁碟預讀
由於存儲介質的特性,磁碟本身存取就比主存慢很多,再加上機械運動耗費,磁碟的存取速度往往是主存的幾百分分之一,因此為了提高效率,要儘量減少磁碟I/O。為了達到這個目的,磁碟往往不是嚴格按需讀取,而是每次都會預讀,即使只需要一個位元組,磁碟也會從這個位置開始,順序向後讀取一定長度的數據放入記憶體。這樣做的理論依據是電腦科學中著名的局部性原理:
- 當一個數據被用到時,其附近的數據也通常會馬上被使用。
- 程式運行期間所需要的數據通常比較集中。
- 由於磁碟順序讀取的效率很高(不需要尋道時間,只需很少的旋轉時間),因此對於具有局部性的程式來說,預讀可以提高I/O效率。
預讀的長度一般為頁(page)的整倍數,頁是電腦管理存儲器的邏輯塊,硬體及操作系統往往將主存和磁碟存儲區分割為連續的大小相等的塊,每個存儲塊稱為一頁(在許多操作系統中,頁得大小通常為4k),主存和磁碟以頁為單位交換數據。當程式要讀取的數據不在主存中時,會觸發一個缺頁異常,此時系統會向磁碟發出讀盤信號,磁碟會找到數據的起始位置並向後連續讀取一頁或幾頁載入記憶體中,然後異常返回,程式繼續運行。
拓展閱讀:常用的系統記憶體性能計數器的描述
Page Faults/sec is the average number of pages faulted per second. It is measured in number of pages faulted per second because only one page is faulted in each fault operation, hence this is also equal to the number of page fault operations. This counter includes both hard faults (those that require disk access) and soft faults (where the faulted page is found elsewhere in physical memory.) Most processors can handle large numbers of soft faults without significant consequence. However, hard faults, which require disk access, can cause significant delays.
Page Reads/sec is the rate at which the disk was read to resolve hard page faults. It shows the number of reads operations, without regard to the number of pages retrieved in each operation. Hard page faults occur when a process references a page in virtual memory that is not in working set or elsewhere in physical memory, and must be retrieved from disk. This counter is a primary indicator of the kinds of faults that cause system-wide delays. It includes read operations to satisfy faults in the file system cache (usually requested by applications) and in non-cached mapped memory files. Compare the value of Memory\\Pages Reads/sec to the value of Memory\\Pages Input/sec to determine the average number of pages read during each operation.
Pages Input/sec is the rate at which pages are read from disk to resolve hard page faults. Hard page faults occur when a process refers to a page in virtual memory that is not in its working set or elsewhere in physical memory, and must be retrieved from disk. When a page is faulted, the system tries to read multiple contiguous pages into memory to maximize the benefit of the read operation. Compare the value of Memory\\Pages Input/sec to the value of Memory\\Page Reads/sec to determine the average number of pages read into memory during each read operation.
Pages/sec is the rate at which pages are read from or written to disk to resolve hard page faults. This counter is a primary indicator of the kinds of faults that cause system-wide delays. It is the sum of Memory\\Pages Input/sec and Memory\\Pages Output/sec. It is counted in numbers of pages, so it can be compared to other counts of pages, such as Memory\\Page Faults/sec, without conversion. It includes pages retrieved to satisfy faults in the file system cache (usually requested by applications) non-cached mapped memory files.
參考文檔:
Measuring Disk Latency with Windows Performance Monitor (Perfmon)
SQL Server disk performance metrics – Part 1 – the most important disk performance metrics


