
理解reduceByKey操作,有助於理解Shuffle reduceByKey reduceByKey操作將map中的有相同key的value值進行合併,但是map中的數據鍵值對,並不一定分佈在相同的partition中,甚至相同的機器中。 所以需要將數據取到相同的主機進行計算-同地協作。 單一t ...
理解reduceByKey操作,有助於理解Shuffle
reduceByKey
reduceByKey操作將map中的有相同key的value值進行合併,但是map中的數據鍵值對,並不一定分佈在相同的partition中,甚至相同的機器中。
所以需要將數據取到相同的主機進行計算-同地協作。
單一task操作在單一partition上,為了組織所有數據進行單一的redueceByKey reduce 任務執行,Spark需要完成all-to-all(多對多)操作,所以必須在所有partitions中尋找所有values為了所有keys。
然後將每一個key對應的值從不同的partitions中放到一起進行最終的計算。這就是Shuffle.
Shuffle
1、數據完整性
2、網路IO消耗
3、磁碟IO消耗
回顧MapReduce的shuffle
MapReduce的shuffle操作

Shuffle階段在map函數的輸出到reduce函數的輸入,都是shuffle階段,
Split與block的對應關係可能是多對一,預設是一對一。每個map任務會處理一個split,如果block大和split相同,有多少個block就有多少個map任務,hadoop的2.*版本中一個block預設128M。

Map階段的shuffle操作:

得到map的輸出,然後進行分區,預設的分區規則:key值計算hash然後對應reduce個數取模;分區個數與reduce個數一致
map分區後的結果會放入到記憶體的環形緩衝區,它的預設大小是100M,配置信息是mapreduce.task.io.sort.mb,當緩衝區的大小使用超過一定的閥值(mapred-site.xml:mapreduce.map.sort.spill.percent,預設80%),一個後臺的線程就會啟動把緩衝區中的數據溢寫(spill)到本地磁碟中(mapred-site.xml:mapreduce.cluster.local.dir),與此同時Mapper繼續向環形緩衝區中寫入數據。
環形緩衝區將數據溢寫到磁碟,在溢寫過程中對數據進行sort和Combiner,排序預設是針對key進行排序,combiner如果指定是優化的一種,類似將reduce的操作在map端進行,避免多餘數據的傳輸,比如在分區中有3個("Hadoop",1),可將數據進行合併("Hadoop",3)。溢寫到磁碟小文件大小為80M。
然後將多個小文件合併成一個大文件,在這個過程中,還是會進行sort和combiner,因為即使小文件的內容是已經排序的,合併以後數據也還是需要排序的。不然數據還是無序的。
Reduce階段的shuffle操作:
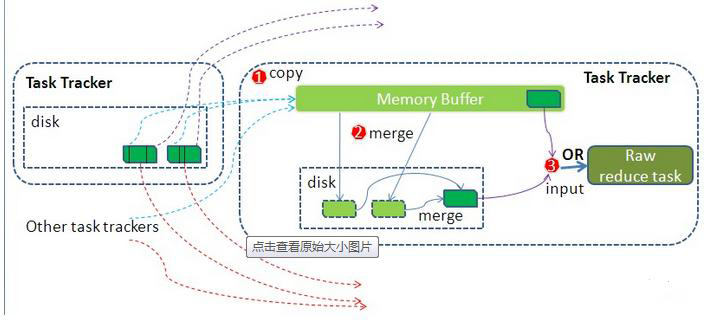
Reduce從Task Tracker中取數據,使用http協議取數據,copy過來的數據放入到記憶體緩存區中,這裡的記憶體緩衝區的大小為JVM的heap大小。
然後對數據進行merge,這裡的merge也會進行sort和combiner,如果設置了combiner。merge也會進行預設的分組,將key進行分組。
Spark Shuffle
HashBaseShuffle
缺點:小文件過多,數量為task*reduce的數量
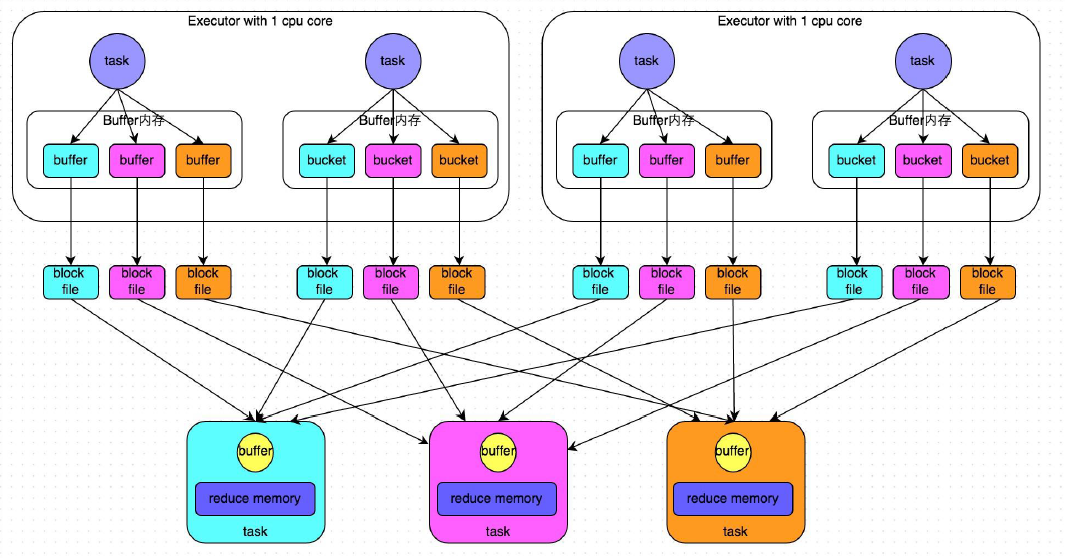
數據到記憶體buffer是進行partition操作,對key求hash然後根據reduce數量取模。buffer的大小不大32k,不是很大,buffer的數據會隨時寫到block file,這個過程沒有sort。
reduce端通過netty傳輸來取數據,然後將數據放到記憶體。通過hashmap存儲。
優化:使用spark.shuffle.consolidateFiles機制,修改值為true,預設為false,沒有啟用。
文件數量為:reduce*core
在一個core裡面並行運行的task其中生成的文件數為reduce的個數。一個core裡面並行運行的task,將數據都追加到一起。

SortBaseShuffle
現在預設的shuflle為SortBaseShuffle
自帶consolidateFiles機制
自帶sort

不用sort排序可以通過配置實現
1、spark.shuffle.sort.bypassMergeThreshold 預設值為200 ,如果shuffle read task的數量小於這個閥值200,則不會進行排序。
2、或者使用hashbasedshuffle + consolidateFiles 機制
修改shuffle方法:
spark.shuffle.manager 預設值:sort
有三個可選項:hash、sort和tungsten-sort。HashShuffleManager是Spark 1.2以前的預設選項,但是Spark 1.2以及之後的版本預設都是SortShuffleManager了。tungsten-sort與sort類似,但是使用了tungsten計劃中的堆外記憶體管理機制,記憶體使用效率更高。tungsten-sort慎用,存在bug.

參考:http://langyu.iteye.com/blog/992916

