
聲明:此文章轉載自 http://my.oschina.net/goldenshaw/blog/304493 許多時候,字元集與編碼這兩個概念常被混為一談,但兩者是有差別的,作為深入理解的第一步,首先要明確: 字元集與字元集編碼是兩個不同層面的概念 charset是character set的簡寫, ...
聲明:此文章轉載自 http://my.oschina.net/goldenshaw/blog/304493
許多時候,字元集與編碼這兩個概念常被混為一談,但兩者是有差別的,作為深入理解的第一步,首先要明確:
字元集與字元集編碼是兩個不同層面的概念
charset是character set的簡寫,即字元集。
encoding是charset encoding的簡寫,即字元集編碼,簡稱編碼。
與介面及介面實現的對比
可以把這兩者與介面及介面實現做個對比:
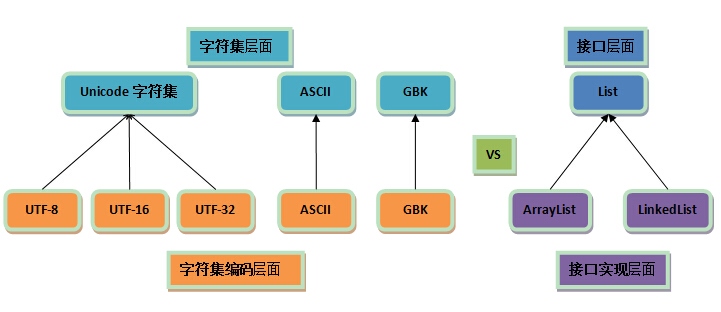
從這裡可以很清楚地看到,
編碼是依賴於字元集的,就像代碼中的介面實現依賴於介面一樣;
一個字元集可以有多個編碼實現,就像一個介面可以有多個實現類一樣。
具體例子及規範用法
可以簡單看兩個例子,一個自於html文件,用的是charset:
<meta http-equiv="content-type" content="text/html;charset=utf-8">另一個來自於xml文件,用的是encoding:
<?xml version="1.0" encoding="UTF-8"?>哪一種用法更規範呢?顯然是後者,它更加準確地區分了字元集與編碼的概念。
“charset=utf-8”容易讓人誤解為存在一種叫“UTF-8”的字元集,但實際上,無論是UTF-8還是UTF-16,UTF-32都是對同一種字元集的不同編碼實現而已。
為什麼要嚴格區分字元集與編碼這兩個概念?
字元集與編碼一對一的情形
有很多的字元編碼方案,一個字元集只有唯一一個編碼實現,兩者是一一對應的。比如GB2312,這種情況,無論你怎麼去稱呼它們,比如“GB2312編碼”,“GB2312字元集”,說來說去其實都是一個東西,可能它本身就沒有特意去做什麼區分,所以無論怎麼說都不會錯。
為什麼一對一是一種普遍的情況呢?
我們以GB2312為例,GB=Guo Biao=國標=國家標準,標準出來本來就為了統一,你一個標準弄出N個編碼實現來,你讓人家用哪個呢?
字元集與編碼一對多的情形
事情到了Unicode這裡,變得不一樣了,唯一的Unicode字元集對應了三種編碼:UTF-8,UTF-16,UTF-32。如果還是這麼籠統地去稱呼,就很容易搞混了。
為什麼Unicode這麼特殊?
人們弄出新的字元集標準,驅動力無外乎是舊的字元集里的字元不夠用了。
Unicode的目標是統一所有的字元集,囊括所有的字元,所以字元集發展到它這裡就到頭了,再去整什麼新的字元集就沒必要也不應該了。
但如果覺得它現有的編碼方案不太好呢?在不能弄出新的字元集情況下,只能在編碼方面做文章了,於是就有了多個實現,這樣一來傳統的一一對應關係就打破了。
我們嚴格地區分字元集與編碼兩個概念,理由就在這裡。
指定了編碼,它所對應的字元集自然就指定了,編碼才是我們最終要關心的。
Unicode早期與現在的對比
讓我們來看一個圖,它展現了Unicode早期與現在的一些差別:
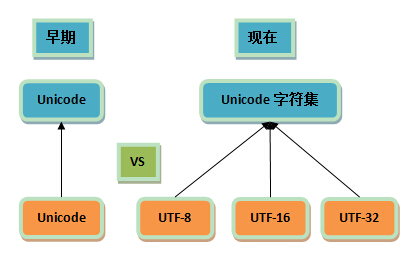
註:由於歷史方面的原因,你還會在不少地方看到把Unicode和UTF-8混在一塊的情況,這種情況下的Unicode通常就是UTF-16或者是更早的UCS-2編碼,在後面的篇章中我們會進一步分析。
下麵是“記事本程式”保存時的一個截圖,是Unicode的一個不規範使用,這裡的Unicode就是指UTF-16:

我們現在說了不少Unicode,由於各種原因,必須承認,在不同的語境下,“Unicode”這個詞有著不同的含義,它可能指:
-
Unicode標準
-
Unicode字元集
-
Unicode的抽象編碼(編號),也即碼點(code point)
-
Unicode的一個具體編碼實現,通常即為變長的UTF-16(16或32位),又或者是更早期的定長16位的UCS-2
關於這些話題在後面的篇章里會做進一步探討。


