
最近由於公司慢慢往spark方面開始轉型,本人也開始學習,今後陸續會更新一些spark學習的新的體會,希望能夠和大家一起分享和進步。 Spark是什麼? Apache Spark™ is a fast and general engine for large-scale data processin ...
最近由於公司慢慢往spark方面開始轉型,本人也開始學習,今後陸續會更新一些spark學習的新的體會,希望能夠和大家一起分享和進步。
Spark是什麼?
Apache Spark™ is a fast and general engine for large-scale data processing.(官方說法)
Spark,簡單的說是一種通用的大數據計算框架。
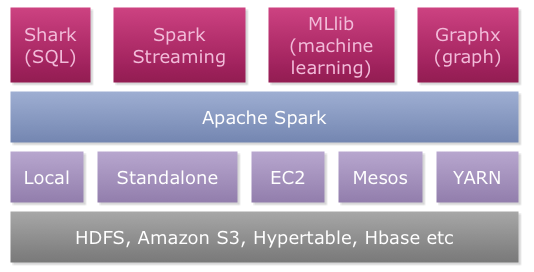
包含了常見領域的各種框架:核心組件-Spark Core、互動式查詢-Spark SQL、準實時流式計算-Spark Streaming、機器學習-Spark MLlib、圖計算-Spark GraphX。
Spark與Hadoop的關係
很多人說Spark可以替換Hadoop,這顯然是錯的。Spark是基於Hadoop的,即Spark主要用於大數據的計算,而Hadoop由於計算方面採用MapReduce的方式,多次反覆讀寫磁碟,使得速度遠遠不如Spark快,所以Hadoop以後會用於大數據的存儲(HDFS、Hive、HBase等)和資源調度(Yarn)。
Spark本身不具備存儲功能,未來Spark+Hadoop的組合是一套完整的解決方案。
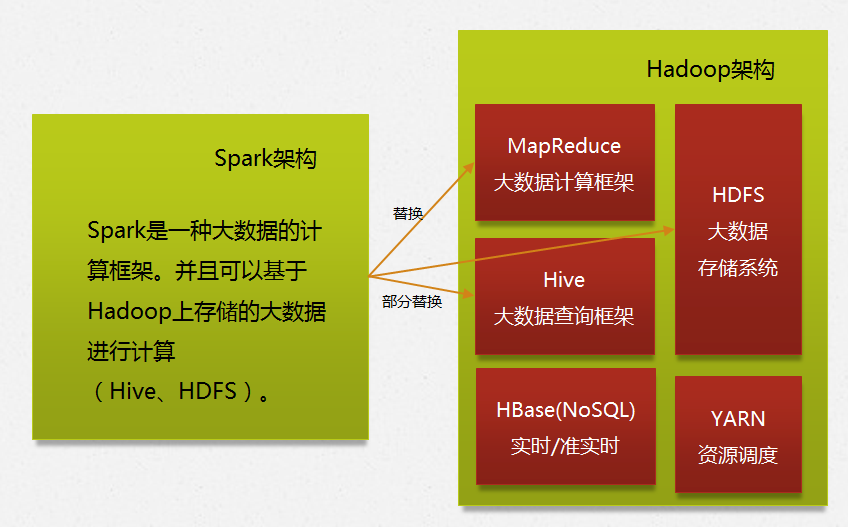
Spark可以替換MapReduce的計算框架、Spark SQL可以替換Hive的查詢框架,但並沒有Hive作為數據倉庫的功能,所以只是部分替換。


