
這是spark1.5及以前堆記憶體分配圖 下邊對上圖進行更近一步的標註,紅線開始到結尾就是這部分的開始到結尾 spark 預設分配512MB JVM堆記憶體。出於安全考慮和避免記憶體溢出,Spark只允許我們使用堆記憶體的90%,這在spark的spark.storage.safetyFraction 參數 ...
這是spark1.5及以前堆記憶體分配圖

 下邊對上圖進行更近一步的標註,紅線開始到結尾就是這部分的開始到結尾
下邊對上圖進行更近一步的標註,紅線開始到結尾就是這部分的開始到結尾
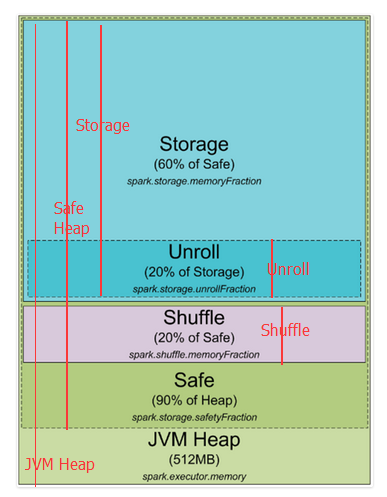
 spark 預設分配512MB JVM堆記憶體。出於安全考慮和避免記憶體溢出,Spark只允許我們使用堆記憶體的90%,這在spark的spark.storage.safetyFraction 參數中配置著。也許你聽說的spark是一個記憶體工具,Spark允許你存儲數據在記憶體。其實,Spark不是真正的記憶體工具,它只是允許你使用記憶體的LRU(最近最少使用)緩存 。所以,一部分記憶體要被用來緩存你要處理的數據,這部分記憶體占可用安全堆記憶體的60%,這個值在spark.storage.memoryFraction參數中配置。所以如果你想知道你可以存多少數據在spark中,spark.storage.safetyFraction 預設值為0.9,spark.storage.memoryFraction的預設值為0.6,
Storage=總堆記憶體*0.9*0.6,所以你有54%的堆記憶體用來存儲數據。
shuffle記憶體:
spark.shuffle.safetyFraction * spark.shuffle.memoryFraction
spark.shuffle.safetyFraction預設為0.8或80%,spark.shuffle.memoryFraction預設為0.2或20%,則你最終可以使用0.8*0.2=0.16或16%的JVM 堆記憶體用於shuffle。
Unroll記憶體:
spark允許數據以序列化或非序列化的形式存儲,序列化的數據不能拿過來直接使用,所以就需要先反序列化,即unroll。
Heap Size*spark.storage.safetyFraction*spark.storage.memoryFraction*spark.storage.unrollFraction=Heap Size *0.9*0.6*0.2=Heap Size * 0.108或10.8%的JVM 堆記憶體。
到此為止,你應該就知道Spark是如何使用jvm記憶體的了,下邊是集群模式,以yarn為例,其它類似。
spark 預設分配512MB JVM堆記憶體。出於安全考慮和避免記憶體溢出,Spark只允許我們使用堆記憶體的90%,這在spark的spark.storage.safetyFraction 參數中配置著。也許你聽說的spark是一個記憶體工具,Spark允許你存儲數據在記憶體。其實,Spark不是真正的記憶體工具,它只是允許你使用記憶體的LRU(最近最少使用)緩存 。所以,一部分記憶體要被用來緩存你要處理的數據,這部分記憶體占可用安全堆記憶體的60%,這個值在spark.storage.memoryFraction參數中配置。所以如果你想知道你可以存多少數據在spark中,spark.storage.safetyFraction 預設值為0.9,spark.storage.memoryFraction的預設值為0.6,
Storage=總堆記憶體*0.9*0.6,所以你有54%的堆記憶體用來存儲數據。
shuffle記憶體:
spark.shuffle.safetyFraction * spark.shuffle.memoryFraction
spark.shuffle.safetyFraction預設為0.8或80%,spark.shuffle.memoryFraction預設為0.2或20%,則你最終可以使用0.8*0.2=0.16或16%的JVM 堆記憶體用於shuffle。
Unroll記憶體:
spark允許數據以序列化或非序列化的形式存儲,序列化的數據不能拿過來直接使用,所以就需要先反序列化,即unroll。
Heap Size*spark.storage.safetyFraction*spark.storage.memoryFraction*spark.storage.unrollFraction=Heap Size *0.9*0.6*0.2=Heap Size * 0.108或10.8%的JVM 堆記憶體。
到此為止,你應該就知道Spark是如何使用jvm記憶體的了,下邊是集群模式,以yarn為例,其它類似。

 在Yarn集群中,Yarn Resource Manager管理集群的資源(實際就是記憶體)和一系列運行在集群Node上yarn resource manager及集群Nodes資源的使用。從YARN的角度,每一個 Node都代表了一個可控制的記憶體資源,當你向Yarn Resource Manager申請資源時,它會反饋給你哪個yarn node manager 可以連接並啟動一個execution container給你。每一個execution container都是一個可以提供堆記憶體的JVM,JVM的位置是由Yarn Resource manager選擇的。
當你在Yarn上啟動Spark時,你可以指定executor的數量(–num-executors flag or spark.executor.instances parameter)、每個executor的記憶體大小(–executor-memory flag or spark.executor.memory parameter)、每個executor的內核數量(–executor-cores flag of spark.executor.coresparameter)、每個task執行的內核數量(spark.task.cpusparameter),你也可以指定driver的記憶體大小(–driver-memory flag or spark.driver.memory parameter)。
當你在集群中執行某項任務時,一個job會被切分成stages,每個stage會被分成多個task,每個task會被單獨分配,你可以把這些executor看成一個個執行task的槽池(a pool of tasks execution slots)。如下看一個例子:一個集群有12個節點(yarn node manager),每個節點有64G記憶體、32核的CPU(16個物理內核,一個物理內核可以虛擬成兩個)。每個節點你可以啟動兩個executors、每個executor分配26G記憶體(留一部分用於system process、yarn NM、DataNode).所以集群一共可以處理 12 machines * 2 executors per machine * 12 cores per executor / 1 core for each task = 288 task slots。這意味著該集群可以並行運行288個task,充分利用集群的所有資源。你可以用來存儲數據的記憶體為= 0.9 spark.storage.safetyFraction * 0.6 spark.storage.memoryFraction * 12 machines * 2 executors per machine * 26 GB per executor = 336.96 GB。沒有那麼多,但是也足夠了。
到此,你已經知道spark如何分配 jvm記憶體,在集群中可以有多少個execution slots。那麼什麼是task,你可以把他想像成executor的某個線程,executor是一個進程 ,它可以多線程的執行task.
下邊來解釋一下另一個抽象概念"Partition",你用來分析的所有數據都將被切分成partitions,那麼何為一個partition,它又是由什麼決定的?partition的大小是由你使用的數據源決定的,在spark中你可以使用的所有讀取數據的方式,大多你可以指定你的RDD中有多少個partitions。當你從HDFS中讀取一個文件時,hadoop的InputFormat決定partition。通常由InputFormat輸入的每一個 split對應於RDD中的一個partition,而每一個split通常相當於hdfs中的一個block(還有一些其它情況,暫不解釋,如text file壓縮後傳過一整個partition不能直接使用)。
一個partition產生一個task,併在數據所在的節點task slot執行(數據本地性)
參考譯自:https://0x0fff.com/spark-architecture/
語言組織不是特別好,請見諒,如有失誤之處,還請多提寶貴意見。
在Yarn集群中,Yarn Resource Manager管理集群的資源(實際就是記憶體)和一系列運行在集群Node上yarn resource manager及集群Nodes資源的使用。從YARN的角度,每一個 Node都代表了一個可控制的記憶體資源,當你向Yarn Resource Manager申請資源時,它會反饋給你哪個yarn node manager 可以連接並啟動一個execution container給你。每一個execution container都是一個可以提供堆記憶體的JVM,JVM的位置是由Yarn Resource manager選擇的。
當你在Yarn上啟動Spark時,你可以指定executor的數量(–num-executors flag or spark.executor.instances parameter)、每個executor的記憶體大小(–executor-memory flag or spark.executor.memory parameter)、每個executor的內核數量(–executor-cores flag of spark.executor.coresparameter)、每個task執行的內核數量(spark.task.cpusparameter),你也可以指定driver的記憶體大小(–driver-memory flag or spark.driver.memory parameter)。
當你在集群中執行某項任務時,一個job會被切分成stages,每個stage會被分成多個task,每個task會被單獨分配,你可以把這些executor看成一個個執行task的槽池(a pool of tasks execution slots)。如下看一個例子:一個集群有12個節點(yarn node manager),每個節點有64G記憶體、32核的CPU(16個物理內核,一個物理內核可以虛擬成兩個)。每個節點你可以啟動兩個executors、每個executor分配26G記憶體(留一部分用於system process、yarn NM、DataNode).所以集群一共可以處理 12 machines * 2 executors per machine * 12 cores per executor / 1 core for each task = 288 task slots。這意味著該集群可以並行運行288個task,充分利用集群的所有資源。你可以用來存儲數據的記憶體為= 0.9 spark.storage.safetyFraction * 0.6 spark.storage.memoryFraction * 12 machines * 2 executors per machine * 26 GB per executor = 336.96 GB。沒有那麼多,但是也足夠了。
到此,你已經知道spark如何分配 jvm記憶體,在集群中可以有多少個execution slots。那麼什麼是task,你可以把他想像成executor的某個線程,executor是一個進程 ,它可以多線程的執行task.
下邊來解釋一下另一個抽象概念"Partition",你用來分析的所有數據都將被切分成partitions,那麼何為一個partition,它又是由什麼決定的?partition的大小是由你使用的數據源決定的,在spark中你可以使用的所有讀取數據的方式,大多你可以指定你的RDD中有多少個partitions。當你從HDFS中讀取一個文件時,hadoop的InputFormat決定partition。通常由InputFormat輸入的每一個 split對應於RDD中的一個partition,而每一個split通常相當於hdfs中的一個block(還有一些其它情況,暫不解釋,如text file壓縮後傳過一整個partition不能直接使用)。
一個partition產生一個task,併在數據所在的節點task slot執行(數據本地性)
參考譯自:https://0x0fff.com/spark-architecture/
語言組織不是特別好,請見諒,如有失誤之處,還請多提寶貴意見。


