Laxcus是Laxcus大數據實驗室歷時五年,全體系自主設計研發的國內首套大數據管理系統。能夠支撐百萬台級電腦節點,提供EB量級存儲和計算能力,相容SQL和關係資料庫。最新的2.x版本已經完整覆蓋和集成大數據主流技術和功能,並投入到國內多個超算項目中使用。部署laxcus集群很簡單,一個普通用戶... ...
Laxcus是Laxcus大數據實驗室歷時五年,全體系自主設計研發的國內首套大數據管理系統。能夠支撐百萬台級電腦節點,提供EB量級存儲和計算能力,相容SQL和關係資料庫。最新的2.x版本已經實現對當前大數據主流技術和功能的完整覆蓋和集成,並投入到國內多個超算項目中使用。Laxcus同時保持了使用和部署的極簡性,這將使所有人都能很容易學習和掌握它。下麵演示在一臺Linux電腦上部署Laxcus demo系統的過程。根據我們的測試,這個部署過程大約需要三分鐘,或者您熟悉Linux系統 ,也許不需要這個時間。關於Laxcus的介紹,詳見產品論文:《Laxcus大數據管理系統》。
在實際部署前,請確定已經滿足已下條件:
<1> 保證這台Linux電腦是處於獨立且沒有聯網狀態(因為配置預設使用自迴路地址:127.0.0.1)。
<2> 用戶能夠以root身份登錄Linux系統(Laxcus分佈節點需要在root狀態下工作)。
<3> 運行Laxcus需要Java環境支持,請首先安裝一個JRE,Laxcus的最低版本要求是JRE1.6。
以下進入部署狀態:
<1> 用戶以root身份登錄Linux電腦,然後打開一個終端視窗。
<2> 在根目錄建立一個Laxcus目錄,命令是:"mkdir laxcus"(註意是全小寫,Linux對大小寫敏感)。
<3> 將laxcus demo包從其它目錄複製到這個目錄下麵。
<4> 將Laxcus demo包解壓,命令是:“tar -xzf laxcus_demo_2.0.06_x32.tar.gz”,然後鍵入命令:"ls -ltr",可以看到它的下麵分別出現了“top、home、log、aid、archive、data、work、call、build、watch、console、terminal”一系列目錄及文件。見圖1所示。

圖1 Laxcus demo包(Linux 32位版本)
<5> 在“laxcus”目錄下有一個"java.sh"文件,用vim或者其它文本編輯工具打開它,設置自己的JAVA_HOME目錄(註意這裡是大寫)。圖中是" JAVA_HOME=/home/jdk1.6.0_18"。然後鍵入“wq!”保存退出。見圖2所示。

圖2 修改JAVA_HOME目錄
<6> 將“java.sh”文件複製到“/etc/profile.d”目錄下,命令是:"cp java.sh /etc/profile.d/java.sh"。見圖3所示。

圖3 複製java.sh文件
<7> 在終端上鍵入命令:"echo $JAVA_HOME"查看,如果java.sh被啟用,會顯示JAVA_HOME目錄的實際指向。如果沒有,請重新啟動電腦,再次以root身份登錄查看。見圖4所示。

圖4 顯示JAVA_HOME目錄
<8> 將laxcus目錄下麵的全部".sh"尾碼文件設為可執行,命令是:"chmod +x *.sh"。見圖5所示。

圖5 修改*.sh文件屬性
<9> 進入“laxcus”目錄下麵的所有子目錄,將這些目錄下麵的"bin"目錄中的全部".sh"尾碼文件設為可執行,命令同上。
<10> 以上操作完成後,鍵入命令:“cd /laxcus”回到laxcus目錄,再鍵入命令:“./runbatch.sh”,laxcus節點將按命令順序依次啟動 。見圖6所示。Laxcus已經在多地部署,為客戶提供分佈計算API介面,與用戶合作開發了很多分佈任務組件(基於Laxcus分佈演算法的中間件)。為保證軟體運行過程中的安全,防止出現惡意破壞的情況,Laxcus提供了沙箱服務,對第三方發佈、在Laxcus集群上運行的分佈任務組件進行安全限制和檢查。開啟沙箱模式是在啟動時,在“./runbatch.sh”後面加上“-sandbox”,這表示laxcus集群將在沙箱模式下運行。
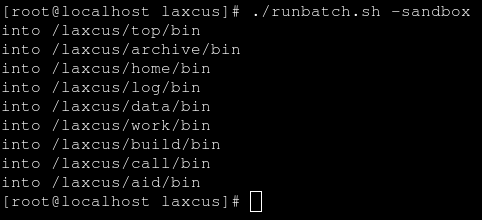
圖6 以“沙箱”模式啟動laxcus集群節點(分佈任務組件被限制在沙箱中運行)
<10> 以上操作完成後,可以使用命令:"ps -ef | grep java" 查看,這裡Laxcus各節點已經在Linux系統後臺運行。
<11> 至此,Laxcus demo系統啟動完畢。如果停止Laxcus集群節點,請回到laxcus根目錄下鍵入命令:"./stopbatch.sh"。見圖7所示。使用過程中如有任意問題和建議,請通過郵箱或者微博我們聯繫。聯繫郵箱:[email protected] 或者微博:http://weibo.com/laxcus

圖7 停止laxcus集群節點
Laxcus 圖形終端/字元控制台
用戶可以使用圖形終端和字元控制台兩種方式登錄到Laxcus集群,通過在視窗中輸入命令,來驅動集群工作。因為只是單機模式,laxcus demo集群的登錄地址是:“localhost”,或者“127.0.0.1”,預設埠號是:5000(參數見conf/local.xml文件中配置)。系統管理員登錄用戶名是:“admin”,密碼是:“laxcus”(密碼區分大小寫)。字元控制台啟動命令是:“./console.sh”,圖形終端啟動命令是:“./terminal.sh”。見圖8、圖9、圖10。進入登錄狀態後,鍵入"help"可以查看Laxcus支持的全部命令。 退出時,字元控制台使用"exit"或者"quit"命令退出,圖形終端點擊菜單或者關閉按紐退出。
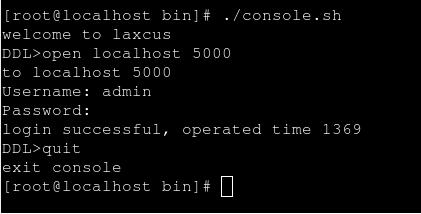
圖8 字元控制台
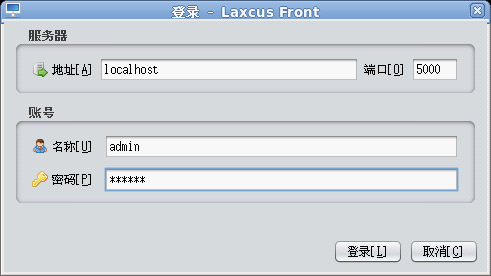
圖9 圖形終端登錄視窗
圖10 圖形終端主操作界面
建立用戶賬號
Laxcus是多用戶多集群的大數據管理系統,這意味著每個用戶在操作數據前,必須擁有一個屬於自己的賬號。建立用戶賬號的過程由系統管理員來完成,並對這個賬號的操作範圍進行授權。在賬號建立成功後,管理員將賬號轉交給用戶,用戶可以修改自己的賬號密碼,然後執行以後的數據操作,如建立資料庫、建表、寫入數據、查詢等操作。這些操作和關係資料庫的基本一致。在Laxcus demo系統里,已經內置了一個“demo”賬號相關的分佈計算服務。成功建立demo賬號後,即可獲得相關的業務操作能力。
圖11 系統管理員建立demo賬號

圖12 系統管理員對demo賬號授權
demo用戶操作
用戶獲得demo賬號後,以“demo/demo”登錄到localhost:7600。執行修改賬號密碼、建立資料庫、建立數據表的操作。
圖13 demo用戶登錄到:localhost 7600 主機

圖14 demo用戶修改自己的登錄密碼

圖15 建立資料庫

圖16 建立數據表
分佈計算
Laxcus大數據管理系統的分佈計算基於DIFFUSE/CONVERGE演算法。關於演算法和分佈任務組件(中間件)的介紹詳見《Laxcus大數據管理系統》一文,這裡不再贅述。圖11演示了一個在demo賬號下,隨機數的產生、排序、顯示、保存的過程。
視窗文字解釋:
<1>“conduct”,Laxcus系統命令,是diffuse/converge分佈演算法的語句化描述。
<2>“demo_sort”,分佈計算的中間件命名(不區分大小寫)。這個中間件已經集成在Laxcus demo系統中。
<3>“from、to、put”,conduct命令關鍵字,是diffuse/converge分佈計算的階段。
<4>“sites”,conduct命令關鍵字,要求的節點數目(節點是一臺邏輯電腦)。
<5>“writeto”,conduct命令關鍵字,指示數據寫入的磁碟文件。
<6> “begin、end、total、orderby”,自定義關鍵字,格式是“名稱(數據類型)=參數”。這些關鍵字由用戶定義,然後在自己的中間件中解析和處理。
命令說明:
這個命令遵循DIFFUSE/CONVERGE分佈演算法,通過操縱一個名為“demo_sort”的分佈任務組件,由多個data節點產生隨機數,然後把它們分散到多個work節點上,進行排序計算和輸出的過程。在from階段,要求系統啟動6個data節點,每個節點平均分配2000(total)個數中的六分之一,產生從0到99999之間的隨機數。to階段要求3個work節點,它承接from階段產生的數字,每個work節點平均分配2000(total)個數中的三分之一,並對分配到的數字進行排序,排序採用降序方式。數據結果在終端上顯示,並寫入一個名為"/tracking/rnd.bin"的本地文件中(Linux文件名,如果終端運行在Windows系統,需要改為對應的目錄結構)。另:在demo_sort分佈任務組件執行過程中,會對參數中要求的節點數進行檢查,如果達不到指定要求,將自動降為實際可用數目。實際上,由於data、work節點達不到要求,demo_sort在執行過程中已經對此做了處理。
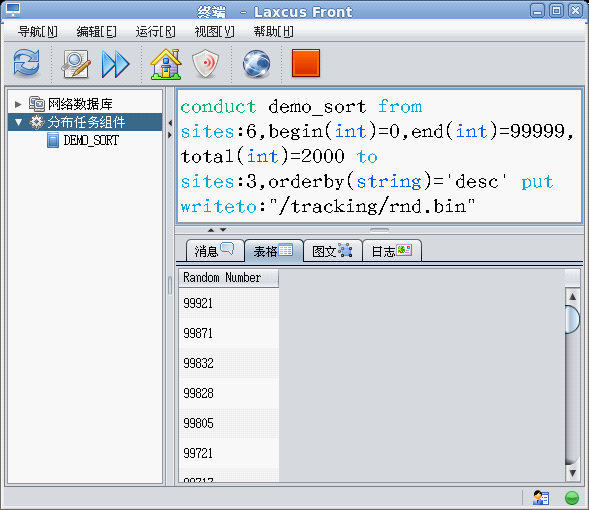
圖17 conduct命令
SQL查詢
Laxcus 2.x已經完全相容SQL,包括SQL四個操縱語句:INSERT、DELETE、UPDATE、SELECT,以及對SQL函數、GROUP BY、ORDER BY、嵌套查詢(Sub Select)、連接查詢(Join)的支持。這些操作在內部都遵循Diffuse/Converge演算法執行計算。在圖形視窗上, 則與關係資料庫表現完全一致。
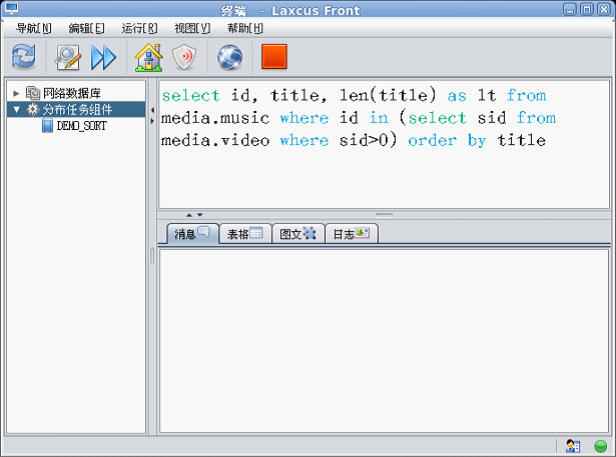
圖18 嵌套查詢(支持SQL函數)

圖19 group by 、order by 查詢(支持SQL函數)
數據構建
數據構造對各種數據再處理業務的綜合。同分佈計算一樣,數據可以通過視窗命令進行。關於數據構建的詳見介紹,還是請見《Laxcus大數據管理系統》一文。在laxcus 2.x版本中,系統提供了兩個數據構建命令“regulate、modulate”,它們分別是對一個節點或者幾個節點的數據,以及一個Laxcus集群的數據進行數據優化和重新整理。同分佈計算一樣,laxcus也提供了數據構建的API介面,幫助用戶實現自己的數據構建業務。
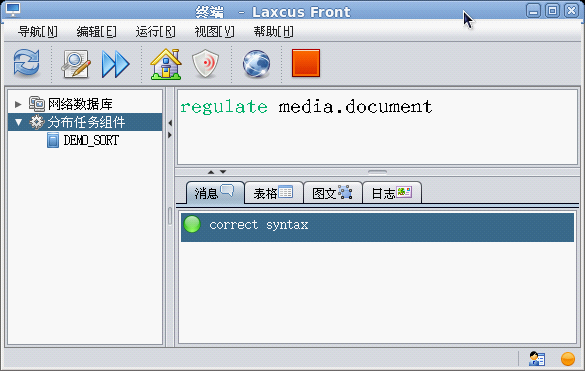
圖20 regulate命令
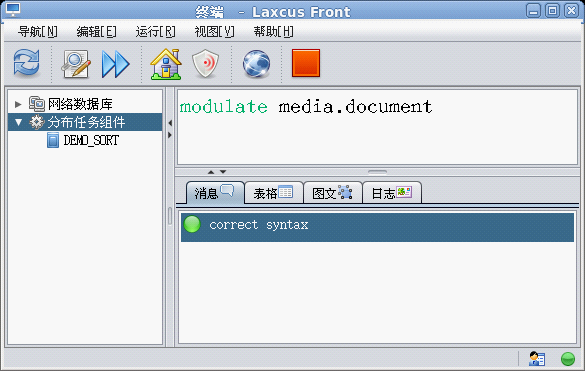
圖21 modulate 命令
流式處理
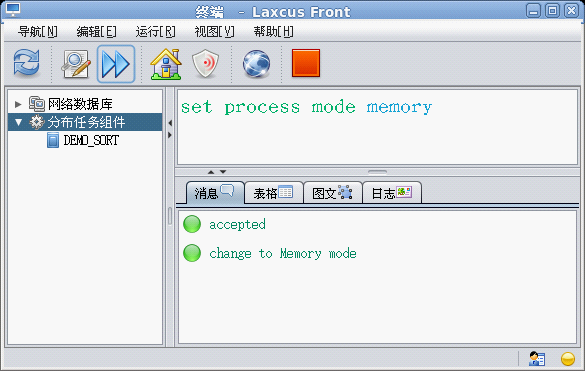
流式處理是laxcus 2.x版本一項新的功能。它將原來基於硬碟的數據處理過程,轉移到記憶體上進行,能夠獲得了數十倍的效率提升。Laxcus流式處理很簡單,只要在圖形視窗上設置這個命令,以後所有的命令操作,都將預設為流式處理方式。反之,如果將命令改為“set process mode disk”, 以後的命令處理,都將是磁碟處理模式。